Побудова та аналіз простої лінійної економетричної моделі
Мета - закріплення теоретичного матеріалу та здобуття практичних навичок побудови та аналізу однофакторної економетричної моделі й перевірки її адекватності та статистичної значущості, використання побудованої моделі для прогнозування та економічного аналізу.
Завдання - визначити ступінь взаємозв'язку між показниками діяльності банків України, виходячи з припущення про лінійний зв'язок між факторами, оцінити параметри лінійної моделі, дослідити її адекватність за допомогою коефіцієнтів детермінації та корреляції, перевірити статистичну значущість параметрів моделі і коефіцієнта кореляції за допомогою критерію Стьюдента, та моделі в цілому за допомогою критерію Фішера. Здійснити розрахунок прогнозного значення доходу банку на основі відомого значення факторної ознаки. Побудувати графік лінійної функції. Зробити висновки щодо економічної інтерпретації отриманої моделі та можливості її практичного застосування.
Хід роботи
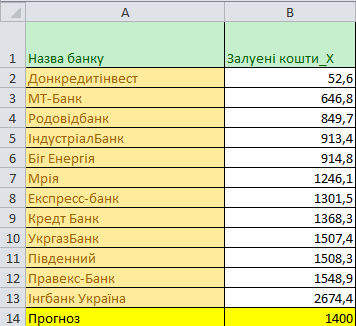
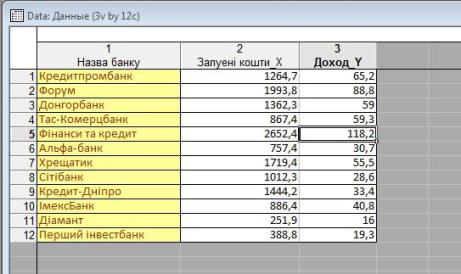
Вводимо вхідні дані ?рис. 1). Виконаємо сортування для наочності.
Лінійний модель кореляція стьюдент
Проводимо аналіз даних за допомогою регресії. Результати представленні на рис.2.1-.2.3?
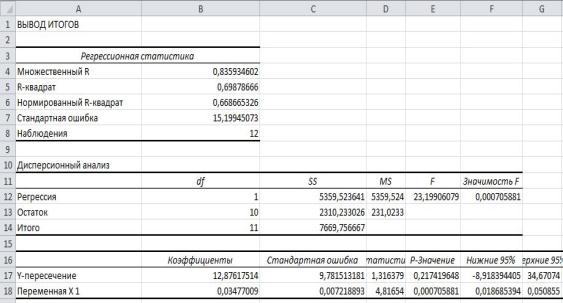
Результати з наведених даних?
1) теоретична модель буде приймати наступний вигляд?
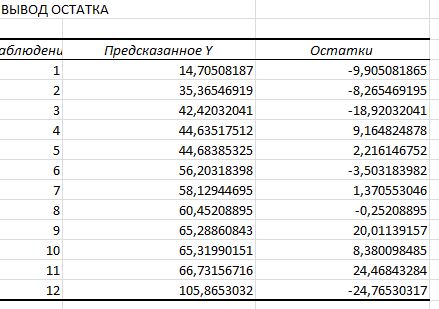
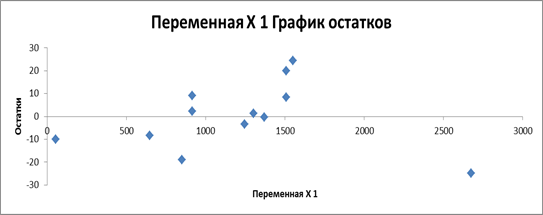
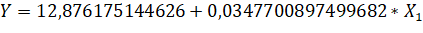
- 2) t - статистика и p-значение - відповідні значення критерію Ст'юдента для кожного параметру та рівень вірогідності помилки прийняття гіпотези. Значення останніх коефіцієнтів рівні відповідно ta0 = 1,31637865290922 і ta1 = 4,81654033406292. tтабл= 2,228. Перше значення не перевищує табличне значення коеф. Ст'юдента, що свідчить про його статичну незначущість. 3) У другій таблиці представленні данні дисперсійного аналізу. У даній таблиці наведено суму квадратів (SS) та дисперсію (MS) відхилень за регресією та за похибками, та критерій Фішера. Розрахункове значення критерію Фішера F =23.199 значно перевищує його табличне значення =FРАСПОБР(0,05;1;10) = 4,964, що свідчить про статистичну значущість моделі в цілому. 4) Проаналізувавши показник кореляції R= 0,835 можна зробити висновок, що зв'язок між ознаками є сильним. 5) Коефіцієнт детермінації R2=0,698. Він вказує на те, що 69.8% варіації рівня доходу в досліджуваних банках зумовлено варіацією залучених коштів. Коефіцієнт залишкової детермінації (1-0,698) вказує на те, що 30,2% варіації рівня доходу банків пояснюється дією інших причин. 3. Проводимо аналіз помилок. Теоретичні значення залежної змінної й помилки моделі зображено на рис. 2.2. Графічне зображення розсіву помилок моделі зображено на рис. 2.3.
Проводимо групування помилок ?рис. 3.1)?

Далі будуємо гістограму розподілу частот помилок ?рис. 3.2)?
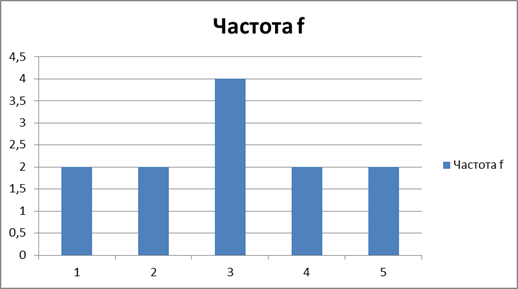
Візуальний аналіз отриманої гістограми свідчить про розподіл помилок за нормальним законом розподілу.
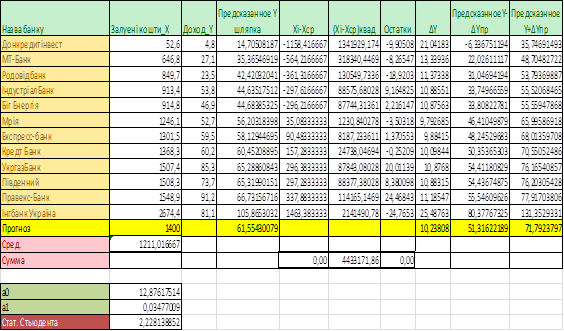
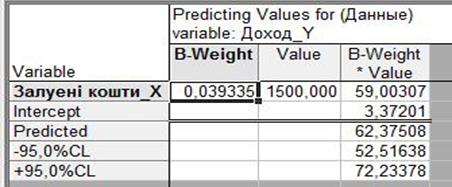
4. Розрахунок прогнозу значень залежної змінної та довірчих інтервалів зміни. Оскільки модель є адекватною, її параметри значимі, то за моделлю можна скласти прогноз. Щоб розрахувати прогнозні значення залежної змінної необхідно додати до вихідних даних додатковий рядок з прогнозним значенням X, а розрахувати точкове теоретичне (прогнозне) значення Y за моделлю з точковими значеннями параметрів, ?Yпр. Результати представленні на рис.4.1
DY - розраховується за формулою:
=Лист5!$B$7*$B$20*КОРЕНЬ(1/12+(B3-$B$15)^2/$F$16)
Таким чином, для Хпр = 1400 отримаємо, що з імовірністю 95% прогнозне значення доходу буде в таких інтервалах:
51,31622189Ј Yпр Ј 71,7923797
Графік лінійної функції з довірчими інтервалами. Отримання усіх необхідних результатів дає можливість перейти безпосередньо до побудови графіку. Після обрання необхідного типу графіку - График с маркерами, переходимо до визначення рядів даних, серед яких: фактичне значення Y, теоретичне (прогнозне) значення Y, теоретичне (прогнозне) значення Y-?Yпр, теоретичне (прогнозне) значення Y+?Yпр. У якості значень горизонтальної осі необхідно обрати значення змінної Х ?рис.4.2).
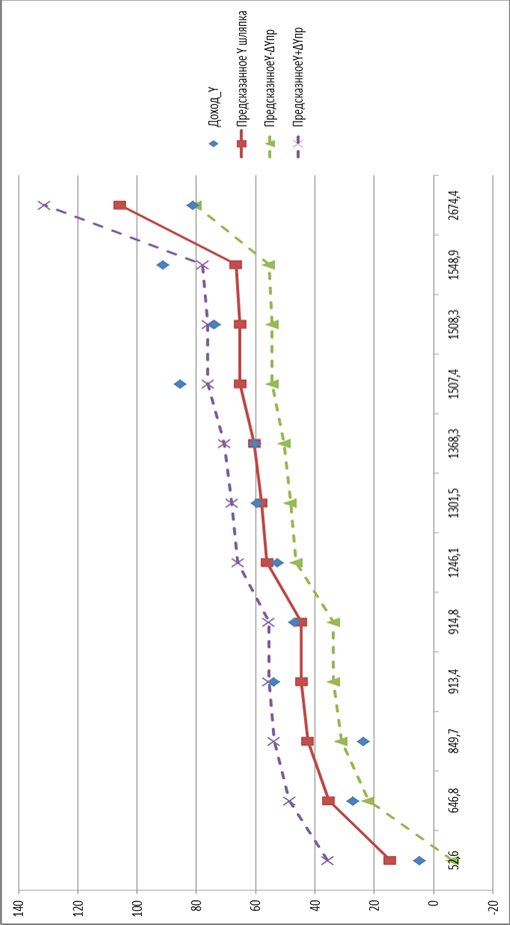
Висновок : коефіцієнт детермінації R2=0,698 не є чітким показником для перевірки адекватності моделі, тому потрібно використовувати коефіцієнт Фішера для перевірки адекватності.
Дана модель є адекватною, так як фактичне значення F =23.199 статистики Фішера є більше ніж табличне F = 4,964.
Коефіцієнт кореляції R= 0,835, показує що зв'язок між признаками є прямим та сильним.
Перевіряємо значимість коефіцієнт кореляції для цього потрібно
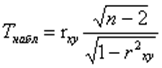
Порівняти Тнабл и Ттабл. Тнабл розраховується за формулою?
Тнабл = 4,816. Що є більше табличного значення. tтабл= 2,228
Проаналізувавши гістограму частоти помилок можна, що помилки розподіляться за нормальним законом. Тобто більше всього значень біля 0.
Так як коефіцієнт tа1 більше табличного значення статистики Ст?юдента, він є статистично значущим, tа0 менше табличного значення статистики Ст?юдента, тому він не є статистично значимим.
Проаналізувавши отримані дані можна сказати, що дана модель є адекватною, та те що дохід банків значно мірою залежить від залучених ними коштів. Враховуючи отримані дані, можна зрозуміти закономірність в отриманні прибутку банками. Чим більше має банк залучених коштів, тим більшим є його дохід. Отриману модель, так як вона є адекватною, можна використовувати для прогнозування отримання прибутку банку в залежності від активів якими вони оперують.
Проведемо ті самі розрахунки в модулі Multiple Regression ППП Statistica. Виконаємо сортування для наочності.
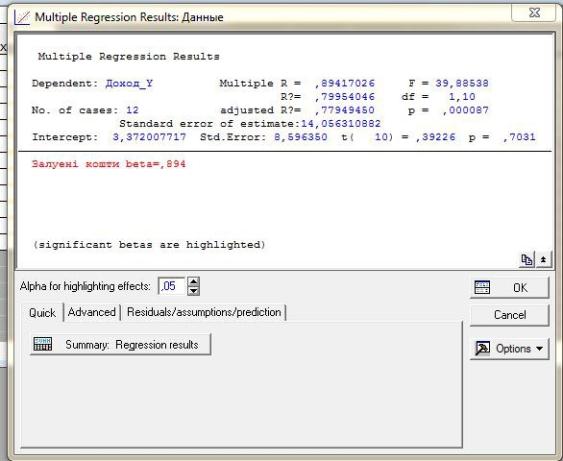
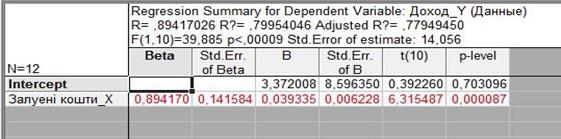
Проводимо розрахунки. За допомогою позиції меню Statistics/Multiple Regression. Результати приведенні на рис. 5.2 и 5.3
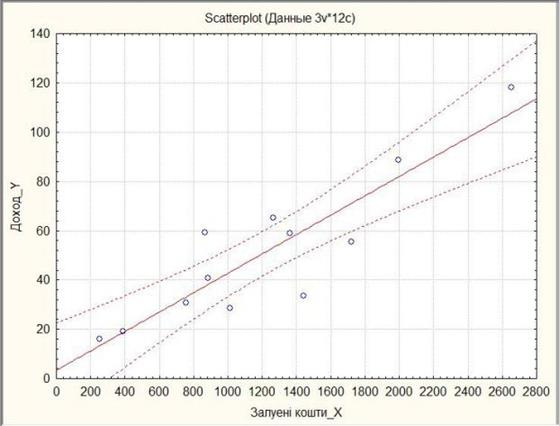
Далі будуємо графік лінійної функції з довірчим інтервалом.
Результати приведенні на рис. 5.4
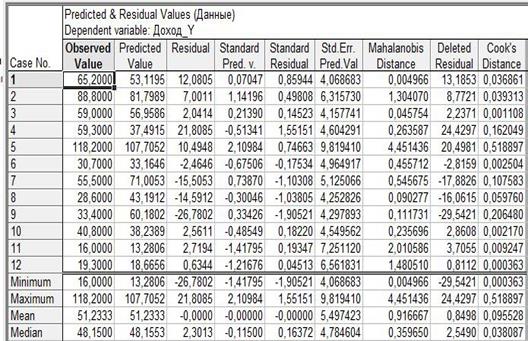
Далі проводимо аналіз помилок. Результати приведенні на рис. 5.5
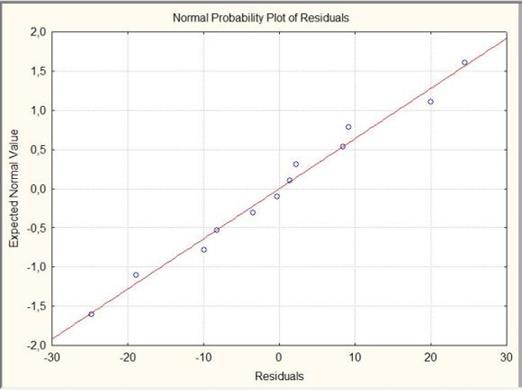
Графік розподілу помилок на нормальному імовірнісному папері. Представлений на рис. 5.6.
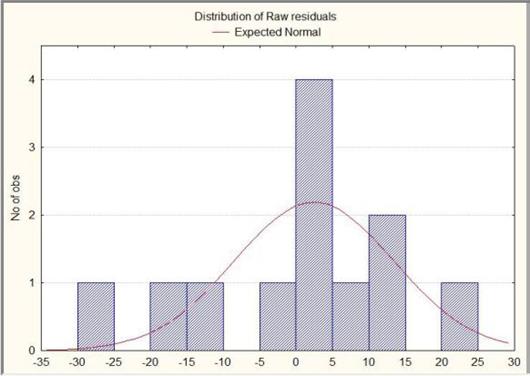
Гістограма розподілу помилок ?рис. 5.7)?
Результати прогнозу ?рис. 5.8)?
---------------------------
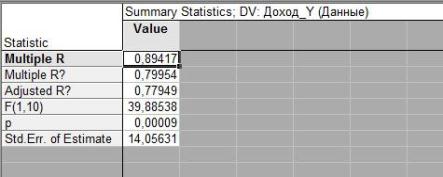
Множественный R - коефіцієнт множинної кореляції (у випадку простої лінійної регресії дорівнює коефіцієнту парної кореляції між Х та Y); R-квадрат - коефіцієнт детермінації моделі; Нормированный R-квадрат - скорегований коефіцієнт детермінації на число спостережень і число параметрів моделі; Стандартная ошибка - середнє квадратичне відхилення помилок моделі; ця статистика - міра розсіву досліджуваних значень відносно регресійної прямої (уe); Наблюдения - кількість вихідних спостережень.
Похожие статьи
-
Кореляційно-регресивний аналіз - це класичний метод стохастичного моделювання господарської діяльності. Він вивчає взаємозв'язки показників господарської...
-
Документування організаційної структури Організаційна структура найбільш легко піддається перенесенню на ARIS, оскільки вона, як правило, чітко визначена...
-
Впровадженню ARIS обов'язково повинна передувати серйозна "ручна" проектно - аналітична робота. У методології ARIS все розподілено, розмежовано і...
-
Висновок - Економетричні моделі
Економетрична модель може являти собою як дуже складну систему так і просту формулу, що може бути легко підрахована на калькуляторі. У будь-якому випадку...
-
Оцінка адекватності моделі - Основні аспекти імітаційного моделювання
Якою б складною і повною не була модель, вона тим не менш є наближеним відображенням реального об'єкта і відображає його за певних прийнятих припущеннях....
-
Статистичний аналіз використання паливно енергетичних ресурсів Запорізької області за 2012-2016 рр
Статистичний аналіз використання паливно енергетичних ресурсів Запорізької області за 2012-2016 рр. Енергетика - одна з найголовніших сфер економіки, від...
-
Оптимізація діяльності в ARIS зводиться до виділення, формалізації і структурування бізнес - процесів з метою формування на їх основі "наскрізного"...
-
Доцільність використання імітаційної моделі - Основні аспекти імітаційного моделювання
Переваги застосування імітаційного моделювання найбільш помітно виявляються у разі моделювання виробничих і технологічних процесів, процесів...
-
Методологія ARIS - Побудова архітектури підприємства з використанням методології ARIS
Методологія ARIS є досить рафінованою. Організація в ARIS розглядається з чотирьох точок зору: - організаційної структури, - функціональної структури, -...
-
Застосування парної лінійної регресії до прогнозування економічних показників Прогноз - це ймовірностне, науково обгрунтоване судження щодо перспектив,...
-
Застосування парної лінійної регресії в економічних дослідженнях Зв'язок між різними явищами в економіці складний і різноманітний. На рівень розвитку...
-
Розглядаючи моделі для аналізу фінансового стану можна зробити висновок, що вони дуже подібні між собою, але їхнім недоліком є те, що вони розраховують...
-
Структура дослідження інтеракційного та трансакційного полів розподілу доходів в моделі одиничної економіки агрегованого ринку Інституційний аспект...
-
Модуль ARIS ABS реалізує аналіз вартості процесів, при якому структура витрат повністю прозора, на відміну від методу встановлених нормативами...
-
Кристали сульфіду цинку, активовані іонами Мn2+, досліджуються вже досить давно. Будь-яке дослідження спектрів ФЛ кристалів, буде далеко не повним без...
-
Постановка задачі - Економетричні моделі
Задача. Для виготовлення чотирьох видів продукції використовують три види сировини. Запаси сировини, норми його витрати і прибуток від реалізації...
-
Даний підхід являє собою прогнозування попиту на продукцію вугільної промисловості регіону на основі показників, що випереджують його в часі. Найбільш...
-
Організаційна структура підприємства ЗАТ "Годинникар" є юридичною особою і діє на підставі статуту і законодавства України. Підприємство створено...
-
На цьому етапі виконуються роботи, пов'язані з підготовкою та реалізацією імітаційної моделі на комп'ютері. Розробляється логічна схема моделі, яка...
-
Абсолютні та відносні характеристики інтенсивності динаміки - Аналіз інтенсивності динаміки
Абсолютний приріст (зменшення) T - це показник ряду динаміки, який характеризує на скільки одиниць змінився поточний рівень показника порівняно з рівнем...
-
Розвиток будь-якого підприємства потребує визначення його реального планування та ефективності його фінансово-господарської діяльності, у зв'язку з чим...
-
Існує досить багато різноманітних методик оцінки фінансового планування підприємства. Найчастіше застосовуються методики на основі фінансових...
-
Для кращого розуміння і аналізу зміни досліджуваних явищ у часі статистичні дані, що їх характеризують, необхідно систематизувати у хронологічному...
-
У системі управління реальними інвестиціями оцінка ефективності інвестиційних проектів є одним з найбільш відповідальних етапів. Від того, наскільки...
-
Графіки, що ілюструють зміну статистичних явищ у часі, називаються Динамічними . Для зображення динаміки явищ використовують лінійні, стовпчикові,...
-
В основі методології фінансово-економічного аналізу лежить діалектичний метод, тобто економічні явища, що вивчаються, аналізуються, розглядаються у...
-
Іонізація через автоіонізаційний стан. - Лазерний атомно-фотоіонізаційний спектральний аналіз
Ще однією можливістю підвищення зрізу фотоіонізації атома є збудження на останній стадії в автоіонізаційний стан. Автоіонізаційний стан (АС)- це стани...
-
Модуль імітаційного моделювання ARIS Simulation використовується в тих випадках, коли необхідно проаналізувати поведінку в часі розроблених моделей...
-
Якщо аргумент і функція задані, то для введення графіка треба обрати з меню Графіки (Graphics) Декартовий графік (X-Y Plot) або клавішу @. У документі...
-
Функцією у = f(x) називається така відповідність між множинами D і Е, при якій кожному значенню змінної х відповідає одне й тільки одне значення змінної...
-
Вихідними продуктами для виробництва полівінілхлориду є рідкий вінілхлорид і вода. Вінілхлорид (CH2 = CHCl) - білі пластинки, легкорозчинні у воді....
-
Оцінка на момент закінчення терміну дії опціону Припустимо, що нас цікавить вартість опціону "код" (далі просто "опціон") на момент закінчення його дії....
-
Аналіз біологічних об'єктів. - Лазерний атомно-фотоіонізаційний спектральний аналіз
Виявлення "слідових" кількостей металів в біологічних об'єктах є на сьогодні однією з актуальних аналітичних задач, важливих як для біології так і...
-
Розробка математичного забезпечення інформаційної системи Характеристика моделей і методів рішення економічної задачі Фінансовий аналіз здійснюється за...
-
Технічний аналіз Технічний аналіз являє собою вивчення минулих змін ціни з метою передбачення її майбутніх змін. Ціна є найважливішим статистичним...
-
Ще однією можливістю підвищення зрізу фотоіонізації атома є збудження на останній стадії в автоіонізаційний стан. Автоіонізаційний стан (АС)- це стани...
-
При такому способі збуджений атом іонізується допоміжним лазерним випромінюванням або випромінюванням, що використовується в на одному з ступінів...
-
Аналіз фінансового стану підприємства - Модель розподілу інвестиційних ресурсів підприємства
Основою для аналізу стали наступні форми звітності підприємства: Баланс, Звіт про фінансові результати і їхнє використання, Звіт про фінансові...
-
В цьму методі, атом з проміжного стану збудження під границю іонізації в рідберговський стан і потім іонізується імпульсом електричного поля. Дослідження...
-
Використання системи наскрізного моделювання при вирішенні фінансово-економічних задач
Використання системи наскрізного моделювання при вирішенні фінансово-економічних задач Постановка проблеми. Вирішення складних фінансово-економічних...
Побудова та аналіз простої лінійної економетричної моделі