Вычисление сходства между текстами о космических достижениях и о бизнесе - Освещение космической индустрии в американских медиа
Второй метод проверки метод, который сравнивает тексты как также, как поисковые машины. Согласно такому способу можно вычислить условное расстояние между текстами. Для того, чтобы определить тренд схожести между статьями о космосе и бизнесе, все тексты о космосе последовательно сравнивались с одним текстом о бизнесе. Подробнее о способе формирования всех анализируемых текстов написано далее
Метод поиска "схожести" (similarity) между текстами описан в совместной работе Салтона, Вонга и Янга. В рамках этой модели текст представляет собой вектор в многомерном пространстве. Размерность этого пространства задает количество слов в словаре языка. Координаты вектора в таком пространстве -- это частоты употребления каждого слова текста.
Для простоты рассмотрим два текста -- "the dog" и "the cat". Для того, чтобы определить расстояние между ними не обязательно рассматривать пространство всего англоязычного словаря. Достаточно рассмотреть трехмерное пространство с координатами the, dog и cat. В таком пространстве у наших текстов будут координаты:
|
The |
Dog |
Cat | |
|
The dog |
1 |
1 |
0 |
|
The cat |
1 |
0 |
1 |
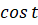
Математическая запись с общем виде будет иметь вид: (), (). В нашем случае вектор "the dog" -- это (1,1,0), а вектор "the cat" (1,0,1). Сходство между векторами определяет косинус угла между ними -- . Чем больше косинус, тем больше сходство. Косинус изменяется в границах от -1 до 1. Формула вычисления косинуса:
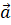
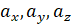
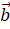
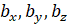
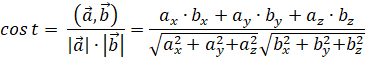
В нашем случае:
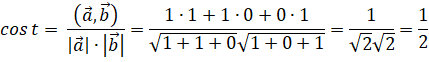
Если бы векторы (тексты) полностью совпадали, то косинус между ними был бы равен единице. Такой принцип поиска сходства между векторами распространяется на многомерное пространство любой размерности.
Стоит отметить, что несмотря на то, что технически функция косинуса может изменяться от -1 до 1, в случае с анализом текстов она будет изменяться в диапазоне от 0 до 1. Чтобы увидеть это рассмотрим два предельных случая. Пример полностью совпадающий текстов:
|
The |
Dog | |
|
The dog |
1 |
1 |
|
The dog |
1 |
1 |
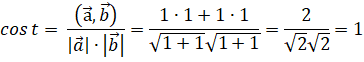
Пример полностью несовпадающих текстов:
|
The |
Dog |
A |
Cat | |
|
The dog |
1 |
1 |
0 |
0 |
|
A cat |
0 |
0 |
1 |
1 |
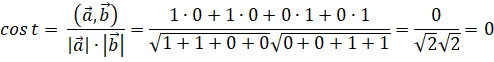
Важно понимать, что такая модель не учитывает порядок слов в тексте и синтаксическую связь между ними. Как следствие, в рамках этого подхода омонимы будут считаться одним и тем же словом. Пример разных текстов, которые будут считаться идентичными: "the dog and the cat", "the cat and the dog".
Чем больше текст и чем больше в нем слов, тем сложнее посчитать размерность нашего пространства и координаты каждого слова вручную. Для вычисления этих значений, как и в случае с анализом слов из COCA, я воспользовалась программой, написанной специально для исследования.
Как и в рассмотренном примере, не было смысла рассматривать тексты в пространстве, размерность которого задает количество слов в словаре английского языка. Это усложнило бы вычисление и скорость получения результатов несмотря на то, что они обрабатываются с помощью программы.
Первый шаг обработки текстов для поиска схожести текстов о космосе с текстами из бизнеса -- выгрузка еще одного массива текстов, соответствующих бизнес-тематике. Для этого я снова обратилась к базе Factiva. Аналогично с выгрузкой текстов о космосе, я использовала только настройки источника (The New York Times) и объекта текстов. В отличие от случая со статьями о космосе, когда выбор из тегов был небольшой, тегов, соответствующих бизнес-тематике, в системе было субъективно много. Для формирования корпуса я выбрала следующие метки в поле Subject: Business/Economic/Investor Sentiment (обзор исследований в области бизнеса, экономики и инвестиций), Business-to-Employee (B2E) (управление сотрудниками компании через Интернет и другие технологии управления), Small Business Lending (кредитование малого и среднего бизнеса), Small Business Start-up Capital (финансирование малого и среднего бизнеса, поиск инвестиций, бизнес-инкубаторы) и Small/Medium Businesses (новости корпораций). Некоторые слишком узкие (например, Outsourcing) или наоборот слишком широкие темы (Plans/Strategy) пришлось отбросить, чтобы корпус не был слишком большим и это не затрудняло анализ.
Второй шаг анализа сходства -- это создание "мега текстов". Программа не анализирует по вышеизложенному алгоритму каждый текст The New York Times с каждым, иначе анализ был бы слишком объемным и сложным для интерпретации. Вместо этого предварительно я составляю "мега тексты" -- сшитые один за одним в единый текст анализируемые статьи космический и бизнес-тематики. Длину "мега текста" определяет хронология. Каждый текст соответствует году публикации включенных в него частей. Таким образом у меня получилось 14 массивов текстов о космосе и еще 14 -- о бизнесе (по одному на каждый год периода 2003-2016).
Еще один вариант "мега текста", который я использую в анализе, -- это объединенные в один массив материалы о бизнесе. Такой текст нужен для фиксации темы: таким образом получилась постоянная сущность, с которой я сравниваю другие тексты.
После объединения текстов начинается стадия анализа. Изложенная методика применялась в четырех вариациях:
- 1) Сравнение каждого мега текста о космосе с единым текстом о бизнесе. Размерность пространства определяют все слова этих текстов. 2) Сравнение каждого мега текста о космосе с единым текстом о бизнесе. Размерность пространства определяют только те слова, которые встречаются в обоих текстах (размерность для каждого года разная, всего 14). 3) Сравнение каждого мега текста о космосе с мега текстом о бизнесе, соответствующем ему по году. Размерность пространства определяют все слова этих текстов (размерность для каждого года разная, всего 14). 4) Сравнение каждого мега текста о космосе с мега текстом о бизнесе, соответствующем ему по году. Размерность пространства определяют только те слова, которые встречаются в обоих текстах (размерность для каждого года разная, всего 14).
В вариантах 2 и 4 сходство между текстами заведомо больше по сравнению с вариантами 1 и 3 соответственно. Несмотря на это такой вариант исключал из выборки "аномальные" статьи, которые мало характерны для каждой из групп текстов.
Анализы 1 и 2 позволяют показать, что тексты о космосе и бизнесе не просто становятся более похожими, но что изменяются именно тексты о космосе, так как в этих случаях "мега тексты" мы сравниваем с одной и той же величиной. По этим причинам проводить только один вид анализа несообразно. Для уточнения некоторый результатов и их подтверждения нужны все четыре вида анализа.
Во всех четырех случаях сходство между текстами увеличивалось:
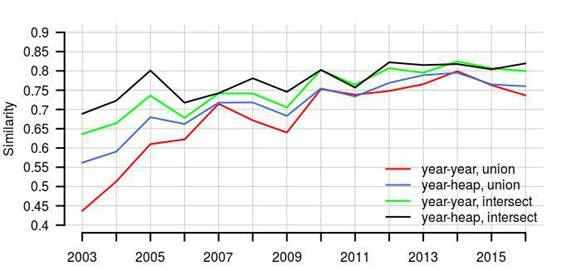
Рис. 4. Значение cost в анализах 1-4. Синий -- анализ 1, черный -- анализ 2, красный -- анализ 3, зеленый -- анализ 4.
Это подтверждает гипотезу о том, что на уровне лексики тексты о космосе в The New York Times становятся более похожими на тексты о бизнесе в этом же издании. Анализ на основе ключевых слов COCA не мог показать это, так как ключевые слова выделялись из текстов разных газет.
Интересные результаты также дает анализ размерностей пространства, в котором вычислялось сходство мега текстов. Скачок размерности между 2005 и 2006 годом. Исходя из методов 2 и 4 видно, что увеличилось количество общих слов в текстах о бизнесе и текстах о космических исследованиях. Во втором методе мы использовали постоянный текст о бизнесе, поэтому скачок там может быть обоснован только расширением лексики в текстах о космосе в 2006 году. Причем пополнение обосновано в том числе добавлением слов, которые чаще употребляются в статьях о бизнесе. Также видно, что в 2012 году размерность пространств анализа сократилась на один год. Но так как общее отклонение от среднего значения не такое сильное, как в 2006 году, эта аномалия представляет меньший интерес.
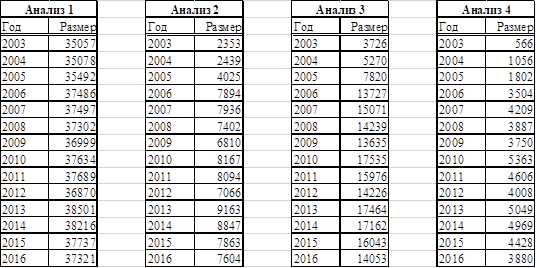
Таблицы 4-7. Размерность пространства в анализах 1-4.
На всех графиках виден скачок размерности между 2005 и 2006 годом. Исходя из методов 2 и 4 видно, что увеличилось количество общих слов в текстах о бизнесе и текстах о космических исследованиях. Во втором методе мы использовали постоянный текст о бизнесе, поэтому скачок там может быть обоснован только расширением лексики в текстах о космосе в 2006 году. Причем пополнение обосновано в том числе добавлением слов, которые чаще употребляются в статьях о бизнесе.
Также видно, что в 2012 году размерность пространств анализа сократилась на один год. Но так как общее отклонение от среднего значения не такое сильное, как в 2006 году, эта аномалия представляет меньший интерес.
Для объяснения "аномалии" 2006 года я обратилась к анализу распределение материалов The New York Times по рубрикам.
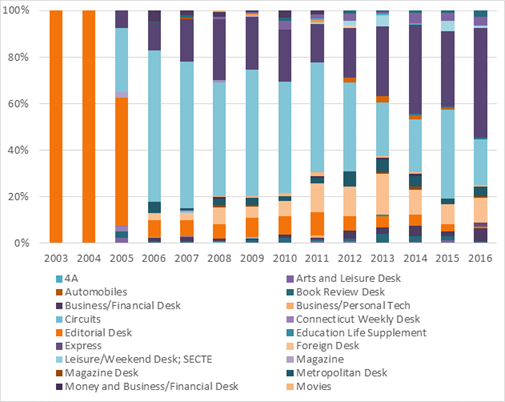
Рис. 5. Распределение текстов NYT о космических достижениях по рубрикам в процентном соотношении.
В 2003 и 2004 годах в базе содержались тексты только под рубрикой Editorial. Это раздел The New York Times, в котором выходят авторские колонки журналистов издания. Такой формат написания текстов подразумевает менее формальное изложение материала. Более того, в колонке автор обычно излагает свое мнение о событии. Это тоже отражается в языке. Таким образом, скачкообразное изменение лексики материалов о космосе связано не столько с коммерциализацией космических исследований, сколько с использованием новых жанров. В моем случае "новыми" стали информационные жанры, свойственные рубрике National.
Начиная с 2006 года колонки перестали быть достаточно представительными. Рубрика Editorial отошла на второй план и по количеству материалов о космосе сопоставима с разделами Week in Review, Foreign и Business/Financial.
В другой вариации графика видно не только распределение по рубрикам, но и изменение количества материалов, отмеченных тегом Space Exploration/Travel в базе Factiva.
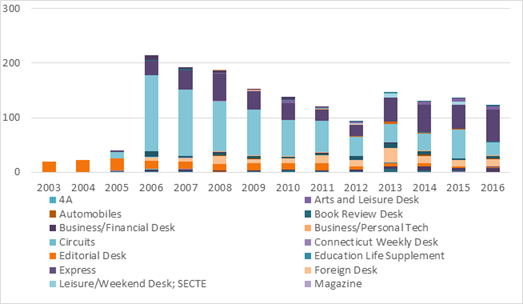
Рис. 6. Распределение текстов NYT о космических достижениях по рубрикам. Абсолютные показатели.
Представление данных в таком разрезе вызывает вопросы к качеству разметки текстов в базе Factiva в 2003-2005 годах. Вероятно, что она неверна, так как в 2003 году в The New York Times должны были появиться тексты с новостями и взрыве шаттла "Колумбия", а такие тексты выходят в рубрике National Desk. В выборке не представлены тексты из этой рубрики в 2003 и 2004 году. Это значит, что результаты количественного исследования относительно этих годов надо интерпретировать с некоторыми оговорками.
Если судить по количеству материалов о космических достижениях, то можно сказать, что интерес к теме падал с 2006 по 2012 год. С 2013 года интерес немного вырос и оставался стабильным.
Примечательно также то, что увеличивается количество рубрик, в которых затронута космическая тема. Она начинает фигурировать не только в новостном блоке National и научной рубрике Science, но и в разделах, традиционно описывающих культуру: Book Review, Leisure/Weekend, Travel, Style. C 2010 года в наборе рубрик появилась The Arts/Cultural Desk.
Следующий вопрос возникает после исторического обзора освещения космических достижений. Все время вплоть до 2000 года NASA было почти единственным источником американского медиапространства, который предоставляет информацию об исследованиях внеземного. Вопрос заключается в том, сохраняет ли агентство информационную гегемонию на космос. Для того, чтобы оценить это в общем случае, я рассмотрела процент статей, в которых упоминается NASA. Получился следующий результат:
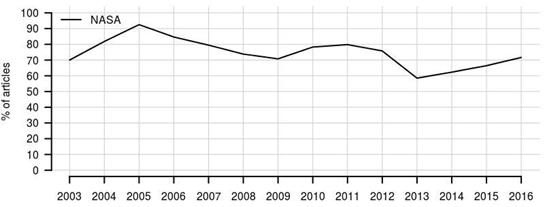
Рис. 7. Процент статей, содержащих упоминание слова "NASA"
Четко выраженный убывающий тренд упоминаемости NASA в текстах наблюдается только в период с 2005 по 2013 год. Самым кризисным с точки зрения коммуникации агентства оказался 2013 год. Тогда NASA было упомянуто только в 60% статей о космосе. После этого частота упоминания агентства снова начала расти. Это показывает, что NASA остается одним из главных источников новостей о космических достижениях, несмотря на коммерциализацию отрасли.
Одно из предположений исследования состояло в том, что активность частных космических исследовательских компаний потеснит NASA в медиапространстве. Для проверки этой гипотезы я рассмотрела процент статей, в который упоминаются наиболее крупные коммерческие организации, занимающиеся космическими полетами -- SpaceX и Virgin Galactic.
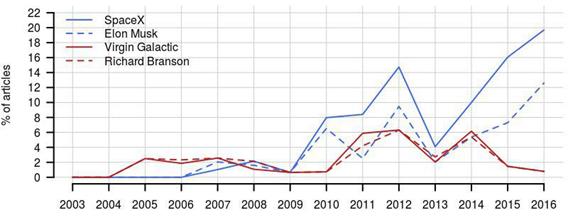
Рис. 8. Процент статей, в которых упоминаются Ричард Брэнсон, Илон Маск, а также компании Virgin Galactic и SpaceX.
Частота упоминания этих компаний действительно возросла. Примечательно, что, хотя компания Илона Маска основана в 2002 году, но впервые на страницах The New York Times она появляется только в 2007 году. Это можно интерпретировать двояко: с одной стороны, в первые годы существования компания не демонстрировала значимых результатов в области космических разработок и поэтому не удостаивалась внимания прессы. С другой стороны, такая задержка может свидетельствовать о "слепоте" непрофильных изданий.
В отличие от SpaceX, о Virgin Galactic в The New York Times начинают писать уже на следующий год после основания. Вероятно, внимание к компании привлек ее владелец Ричард Брэнсон, которого пресса знала по другим проектам. Несмотря на это о компании миллионера почти перестают писать к 2016 году.
Несмотря на рост упоминаемости, значимость SpaceX в медиапространстве значительно меньше, чем у NASA (20% против 70%). Но резкий рост заинтересованности в компании Маска, вероятно, продолжится. Тогда можно будет говорить о конкуренции между NASA и SpaceX за внимание медиа.
Похожие статьи
-
Введение - Освещение космической индустрии в американских медиа
Актуальность. 1 сентября 2016 года взорвалась ракета Falcon 9 при тестовом прожиге на стартовой площадке мыса Канаверал. Испытание пусковой системы...
-
"В продолжающейся Космической гонке частные компании играют важную роль" (In the Continuing Space Race, Private Firms Play a Big Role) Тема. Анализ роли...
-
Лексические особенности текстов о космических достижениях Подготовка к количественному анализу Для анализа я использовала материалы газеты The New York...
-
Прежде чем приступить к собственному исследованию, я изучила не только литературу, которая в общих чертах касается моей работы, но и статью, которое...
-
Работа PR-служб NASA в 1960-х годах - Освещение космической индустрии в американских медиа
Вместе с новым агентством заработали PR-службы, организовывавшие распространение информации о космических миссиях, полетах и прочей деятельности NASA....
-
Для проверки гипотезы исследования, согласно которой тексты о космических достижениях стали больше похожи на тексты о бизнесе на уровне лексики...
-
Заключение - Освещение космической индустрии в американских медиа
В работе представлено исследование материалов о космосе, опубликованных в газете The New York Times с 2003 по 2016 год. Исследование предваряет...
-
Принцип нарративного анализа тестов о космических достижениях Как видно из предыдущего анализа, основанного только на количественных данных о текстах The...
-
В монографии The Heavens and the Earth Макдугал подробно описывает условия, в которых было основано NASA. Анализируя сообщения медиа в 1957 году, автор...
-
Нарративный анализ 1. Риторика статей о NASA - Освещение космической индустрии в американских медиа
1. "Азартные игры, которые стоят за двумя трагедиями шаттлов" (The Gambles and Gaffes Behind Two Tragic Space Shuttle Disasters). Тема. Автор анализирует...
-
" Предстоящий вызов космоса" (The Challenge Ahead in Space) Тема. Анализ аварии шаттла "Колумбия" до публикации финального отчета расследования ситуации....
-
Героизация первых космонавтов - Освещение космической индустрии в американских медиа
Возникшая космическая отрасль обеспечила новый источник поставки звезд в американскую культуру -- астронавтов. Одновременно с этим механизмы продвижения...
-
Освещение запуска "Спутник-1" в СМИ США "Невидимые ракеты, обрушивающиеся ядерной смертью на американцев, казались реальностью" "The possibility of...
-
Работа PR-служб NASA в кризисных ситуациях - Освещение космической индустрии в американских медиа
Несмотря на то, что общественный интерес к космическим программам стал утихать после согласования совместной советско-американской космической программы...
-
Литература - Освещение космической индустрии в американских медиа
1. Alexander L. Space Flight News: NASA's Press Relations and Media Reaction //Journalism Quarterly. - 1966. - Т. 43. - №. 4. - С. 722-728. 2. Boot W....
-
После анализа макетов сайтов был проведен следующий этап работы - сравнение особенностей оформления текстовых публикаций на сайтах. Адаптирование текста...
-
Очень часто, можно сказать, практически всегда, прямое выражение позиции журналиста заменяется на скрытое. При этом пишущим даются какие-либо аргументы...
-
Потенциал метафоры в средствах массовой информации сложно переоценить. Являясь традиционным средством выразительности, в умелых руках она превращается в...
-
Лексическая и грамматическая завершенность, заголовок может функционировать самостоятельно, без обращения к тесту. Позиция в издании. Заголовки, не...
-
Рубрикация Рубриками называют заголовки частей издания (заглавия произведений, внутренние заголовки их подразделов, заголовки элементов аппарата), а...
-
Очень часто, можно сказать, практически всегда, прямое выражение позиции журналиста заменяется на скрытое. При этом пишущим даются какие-либо аргументы...
-
Функции кавычек в газетном тексте - Кавычки в печатных средствах массовой информации
Для полного и детального раскрытия интересующего вопроса в данной курсовой работе был проведен анализ таких газет, как "Аргументы и факты", "Известия",...
-
Термины в публицистическом тексте - Редакторский анализ текста публицистического стиля
Для термина в данном тексте, как и любом другом, основной характерной функцией является Функция определения , называемая дефинитивной, а само...
-
Архитектоника номера - Университетская газета в системе корпоративных медиа
Поговорим немного о дизайне Одна из важнейших особенностей газетного номера считается его дизайн (от англ, design - чертеж, набросок, план). Эти понятие...
-
Структура журналистского текста Заголовок (хэдлайн) - обыгрывание ситуации, коламбур и т. д. краткий и емкий (3-5 слов). Иногда это яркие цитаты....
-
Заголовок - " целостная единица речи, стоящая перед текстом, являющаяся названием текста, указывающая на содержание этого текста и отделяющая данный...
-
Мы живем в мире диалогов сообщений. Текст представляет собой Стандартизированный и отфильтрованный культурой или временем тип сообщения Почепцов Г. Г....
-
Определение понятий Прежде чем охарактеризовать отечественные электронные медиа, необходимо дать точное определение всем составным частям этого понятия....
-
Соц аргументация жур текста - Журналистика и социология: сходства и различия
В реальности проникновение социологических данных в ткань журналистских текстов осуществляется постоянно, поскольку в наше время без исследований...
-
Категория дистанционности в журналистских текстах
Феномен дистанционности. Понятие дистанции по своей сути неотделимо от осязаемого нами пространства и времени, т. е. к нему по определению приложима...
-
Репрезентация религиозной символики в текстовых сообщениях современных интернет-СМИ Рассмотрим на наличие религиозной символики несколько подборок...
-
Понятие "новые медиа" и их особенности Понятие "web 2.0" в наш мир принес американский издатель и сторонник движения за свободное программное обеспечение...
-
Газетный текст - Стилистические и лингвистические особенности газетного текста
Газетный текст представляет собой интерпретацию фрагментов общественной жизни: фактов, событий, явлений, личностей - мотивированную и целенаправленную...
-
Введение, Рубрики и рубрикация - Оформление заголовков книжных изданий
Как обложка и титульный лист служат "лицом" всего издания, так заголовки служат "лицом" каждого произведения и каждого раздела, включенного в книгу. По...
-
Тенденции и перспективы развития медиа - Медиасистема Индии
Индия, страна с ежегодно увеличивающимся ВВП, сегодня наравне с такими экономически успешными странами как Китай, Япония, интегрировалась в процесс...
-
"ГРАФИЧЕСКАЯ ИГРА", "ГРАФИЧЕСКАЯ ИГРА И ЕЕ РОЛЬ В ГАЗЕТНОМ ТЕКСТЕ." - Языковая игра в журналистике
"ГРАФИЧЕСКАЯ ИГРА И ЕЕ РОЛЬ В ГАЗЕТНОМ ТЕКСТЕ." В известной монографии "Русский язык в зеркале языковой игры" приводится несколько типов нарушения...
-
Заголовок - неотъемлемый компонент газетного текста, входящий в него и связанный с другими компонентами целостного произведения. Опережая текст,...
-
Для обработки введенного текста применяются компьютерные издательские системы (DTP) (DTP -- Desktop Publishing). DTP -- это технология подготовки...
-
Жанрообразующая функция "Жанр [французское - genre, латинское - genus, немецкое - Gattung] - одно из важнейших понятий литературоведения, обозначающее...
-
Помимо реакции российской прессы на случившееся, не менее интересным остается мнение блоггера Сергея Никифорова о катастрофе, как о спланированной...
Вычисление сходства между текстами о космических достижениях и о бизнесе - Освещение космической индустрии в американских медиа