Подготовка данных для построения модели и статистический отбор объясняющих переменных - Уровень конкурентоспособности строительных компаний
Для анализа был выбран временной диапазон с 2004 года по 2014 год. В целях построения прогнозной модели собранные годовые данные были разделены на две выборки: обучающую (2004 - 2013 гг.) и тестовую (2014 год). При построении модели вероятности дефолта компании и дальнейшем тестировании качества полученной модели использовался годовой временной лаг, что соответствует рекомендациям БКБН. В рамках обучающей выборки для анализа были выбраны 1505 строительных непубличных компании, не имеющих пропусков в бухгалтерской и финансовой отчетности (из них 301 компания, допустившая дефолт). Тестовую выборку составляют 805 строительных компаний (из них 161 компания, допустившая дефолт в 2014 году). Для построения logit-модели используются панельные данные. Сразу стоит обратить внимание на вопрос полноты панели, которая заключается в наблюдении одних и тех же объектов в течение одного и того же времени. Так как по ходу анализа исследуемой выборки, каждый год "вылетают" дефолтные организации, то появилась проблема несбалансированности панели. Решение этой проблемы было достигнуто рассмотрением панели с замещением, впервые предложенной Biorn E. (1981). Смысл данного метода заключается в поддержании постоянного размера анализируемой выборки. Выбывающие из дальнейшего анализа из-за дефолта компании на каждом этапе (в каждом году) заменяются таким же количеством соразмерных организаций до этого не участвовавших в анализе. Таким образом, в ходе анализа дополнительно был реализован алгоритм в R, который сразу зарезервировал 301 аналог для дефолтных организаций обучающей выборки и по мере анализа данных каждого последующего года включал в дальнейший анализ ровно то количество компаний, которые допустили дефолт в анализируемом году. Данный подход препятствует истощению выборки (Ратникова, 2006). Так как logit-модель очень чувствительна к мультиколлинерности начнем анализ данных с ее анализа. Определим допустимый уровень парных корреляций (связанности) переменных 0,3 (см. табл.5), такой же, как был предложен в работе по моделированию вероятности дефолта российских банков при помощи логистической модели с панельной структурой данных (Карминский, 2012). Стоит отметить, что в ходе исследования будут построены модели двумя способами. Первый - отбор объясняющих переменных с помощью статистического анализа (отсутствие сильной корреляции между переменными, их сильная разделяющая способность и значимость), второй - включение объясняющих переменных в модель по одной из каждой группы (размер компании, рентабельность, ликвидность, деловая активность, финансовая устойчивость), также учитывая отсутствие сильной корреляции между переменными. Также для каждой из полученных такими подходами моделей будет проведен анализ значимости макроэкономических и институциональных переменных, а также проверка функциональной зависимости включенных переменных (квадратичная форма). Итак, для формирования первых спецификаций моделей по принципу статистического отбора переменных проведем тест на разделяющую способность между двумя группами (в данном случае - дефолтные и устойчивые компании) для каждой финансовой и институциональной переменной, чтобы в дальнейший анализ включать только те, значения которых имеют значимые различия между двумя группами. Для этих целей проведем дисперсионный анализ на разделяющую способность переменных, с помощью ANOVA-теста. Нулевая гипотеза H0: разделяющей способности между показателями нет, если P-value близко к нулю, то гипотеза Н0 отвергается и принимается альтернативная гипотеза о разделительной способности. Перед проведением анализа на разделение классов были отброшены статистические выбросы у относительных переменных не дефолтных компаний. Полученные результаты отражены в таблице 4 и будут использоваться для дальнейшего построения модели.
Таблица 4. Разделяющая способность отобранных переменных
|
Переменные |
Вывод |
|
Goldrule |
Гипотеза о равенстве средних отвергается |
|
Ln_Netassets |
Гипотеза о равенстве средних отвергается |
|
Ln_rev |
Гипотеза о равенстве средних отвергается |
|
Liab_assets |
Гипотеза о равенстве средних отвергается |
|
Rev_cur_assets |
Гипотеза о равенстве средних отвергается |
|
Portion_fix_liab |
Гипотеза о равенстве средних НЕ отвергается |
|
Turn_assets |
Гипотеза о равенстве средних отвергается |
|
Turn_ac_rec |
Гипотеза о равенстве средних отвергается |
|
Turn_ac_pay |
Гипотеза о равенстве средних отвергается |
|
ROA |
Гипотеза о равенстве средних отвергается |
|
CF_liab |
Гипотеза о равенстве средних НЕ отвергается |
|
Turn_reserv |
Гипотеза о равенстве средних отвергается |
|
Ac_rec_assets |
Гипотеза о равенстве средних НЕ отвергается |
|
Property _status |
Гипотеза о равенстве средних отвергается |
|
Capital_product |
Гипотеза о равенстве средних отвергается |
|
Work_cap_assets |
Гипотеза о равенстве средних отвергается |
|
Prevent_bank |
Гипотеза о равенстве средних отвергается |
|
ROE |
Гипотеза о равенстве средних отвергается |
|
Abs_liq |
Гипотеза о равенстве средних НЕ отвергается |
|
Ac_recpay |
Гипотеза о равенстве средних НЕ отвергается |
|
Cur_liq |
Гипотеза о равенстве средних НЕ отвергается |
|
Autonomy |
Гипотеза о равенстве средних отвергается |
|
ROS |
Гипотеза о равенстве средних НЕ отвергается |
|
Location |
Гипотеза о равенстве средних НЕ отвергается |
|
Co-owners |
Гипотеза о равенстве средних НЕ отвергается |
|
Black_list |
Гипотеза о равенстве средних НЕ отвергается |
|
Tax_arrears |
Гипотеза о равенстве средних отвергается |
Таблица 5. Парные корреляции финансовых и институциональных переменных
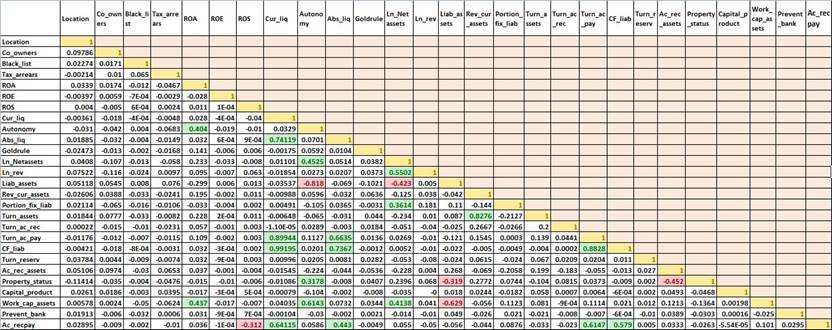
Далее опишем примененный алгоритм отбора объясняющих переменных с учетом парных корреляций и разделяющей способности в ходе реализации первого метода построения модели. Исключаем отношение дебиторской задолженности к кредиторской задолженности (Ac_recpay) из-за сильной корреляции с 5 из 26 переменных, в том числе данная переменная не показала сильной разделяющей способности при ANOVA-тесте. Далее осуществляем выбор между коэффициентом автономии (Autonomy) и натуральным логарифмом чистых активов (Ln_Netassets), которые имеют сильную корреляцию с 5 переменными, но Ln_Netassets имеют одну из сильных корреляций с долей долгосрочных обязательств (Portion_fix_liab), которая не показала сильной разделяющей способности, а значит все равно не значима для модели и не будет в нее включена, в свою очередь Autonomy имеет сильные зависимости с переменными с хорошей разделяющей способностью. Значит, исключаем Autonomy. Далее выбираем между Ln_Netassets (4 сильных корреляции - одна из них с плохо разделяющей переменной), коэффициент абсолютной ликвидности (Abs_liq) (3 сильных корреляции), коэффициент текущей ликвидности (Cur_liq) (3 сильных корреляции). При этом Abs_liq и Cur_liq сами по себе обладают слабой разделяющей способностью между дефолтными и состоятельными компаниями и сильно зависимы между собой, включать в модель их не имеет практического смысла. Поэтому на данном шаге последовательно исключаем Abs_liq и Cur_liq. Далее выбираем между Ln_Netassets (4 сильных зависимости - одна из с плохо разделяющей переменной), Liab_assets (3 сильных зависимости), Work_cap_assets (3 сильных зависимости), причем все три довольно сильно зависят друг от друга. Получается, оставить нужно только один, чтобы избежать мультиколлинеарности. Так как отношение рабочего капитала к активам (Work_cap_assets) имеет сильную зависимость с рентабельностью активов (ROA), которая по проведенному нами анализу хорошо разделяет обе группы между собой и в том числе выделяется международными исследователями, как одна из наиболее значимых для предсказания вероятности дефолта компаний, то удаляем именно Work_cap_assets. Между оставшимися переменными Ln_rev и Ln_Netassets, которые сильно зависят друг от друга, было принято решение оставить показатель Ln_Netassets, целесообразность применения которого подтверждается исследованиями отечественных исследователей (Peresetsky et al., 2011).
Итак, если оставляем Ln_Netassets, то остается сделать выбор между Turn_assets и Rev_cur_assets, которые будут включаться поочередно. Таким образом, в этом случае определены две модели для дальнейшего анализа:
Модель 1: Default ~ Location +Tax_arrears + ROA + ROE + Goldrule + Ln_Netassets + Rev_cur_assets + Turn_ac_rec + Turn_ac_pay + Turn_reserv + Property_status + Capital_product + Prevent_bank
Модель 2: Default ~ Location +Tax_arrears + ROA + ROE + Goldrule + Ln_Netassets + Turn_assets + Turn_ac_rec + Turn_ac_pay + Turn_reserv + Property_status + Capital_product + Prevent_bank
НО если вернуться к выбору между Ln_Netassets и Ln_rev, которые зависят друг от друга, то можно попробовать включить в модель либо Ln_rev и Liab_assets, либо Ln_rev и Property_status. В этом случае также нужно сделать выбор между Turn_assets и Rev_cur_assets, которые сильно зависят друг от друга и только. Получаем следующие модели, полученные также как и первые две на основе статистического отбора переменных (уровня парных корреляций и разделяющей способности переменных):
Модель 3: Default~ Location +Tax_arrears + ROA + ROE + Goldrule + Ln_rev + Liab_assets + Rev_cur_assets + Turn_ac_rec + Turn_ac_pay + Turn_reserv + Capital_product + Prevent_bank
Модель 4: Default~ Location +Tax_arrears + ROA + ROE + Goldrule + Ln_rev + Liab_assets + Turn_assets + Turn_ac_rec + Turn_ac_pay + Turn_reserv + Capital_product + Prevent_bank
Модель 5: Default~ Location +Tax_arrears + ROA + ROE + Goldrule + Ln_rev + Property_status + Rev_cur_assets + Turn_ac_rec + Turn_ac_pay + Turn_reserv + Capital_product + Prevent_bank
Модель 6: Default~ Location +Tax_arrears + ROA + ROE + Goldrule + Ln_rev + Property_status + Turn_assets + Turn_ac_rec + Turn_ac_pay + Turn_reserv + Capital_product + Prevent_bank
Макроэкономические переменные также прошли проверку на парную корреляцию, полученные результаты отражены в таблице 6, а возможные комбинации их использования в модели определены следующим образом:
- - Инвестиции и Торговый баланс; - Торговый баланс, Уровень безработицы и Уровень инфляции; - Безработица, кризисная дамми-переменная и пост-кризисная дамми-переменная; - ВВП; - кризисная дамми-переменная и пост-кризисная дамми-переменная.
Таблица 6. Парные корреляции отобранных макроэкономических переменных
Похожие статьи
-
Отбор и классификация объясняющих переменных Для всесторонней оценки строительной компании в ходе анализа будут использоваться финансовые,...
-
Итак, модели, которые будут дальше анализироваться, и получены с помощью Первого метода - проведения теста для выделения наиболее дескриптивных...
-
Существует целый ряд классификаций моделей используемых для прогнозирования финансовой несостоятельности заемщиков. В своей работе Григорьева Т. И....
-
Определение критериев события дефолт Строительная отрасль является одним из главных двигателей экономики. В России количество компаний, работающих на...
-
Поэтапное построение индекса - Уровень конкурентоспособности строительных компаний
Как показывает практика, чтобы любой инструмент стал широко используемым, он должен либо пройти через сито мнений экспертов отрасли, для анализа которой...
-
Предсказательная сила финальной модели - Уровень конкурентоспособности строительных компаний
Итак, будем тестировать модель с наилучшими характеристиками. Прогноз вне выборки проводился на основе тестовой выборки с 805 наблюдениями. В ней...
-
Введение - Уровень конкурентоспособности строительных компаний
Актуальность темы исследования. Строительная отрасль характеризуется огромным количеством потенциальных исполнителей. Полный цикл возведения любого...
-
Тест на переобучаемость финальной модели - Уровень конкурентоспособности строительных компаний
Как отмечалось в ходе исследования, logit-модель может характеризоваться сильной зависимостью от обучающей выборки. Поэтому чтобы быть уверенным в...
-
Теперь, когда в рамках данного исследования была получена модель с наилучшими характеристиками для непубличных строительных компаний, полученные...
-
Интерпретация финальной модели - Уровень конкурентоспособности строительных компаний
Перейдем к интерпретации построенной модели для непубличных строительных компаний, так как она представляет не меньший интерес, чем прогнозное качество...
-
При дальнейшем построении модели воспользуемся таким ограничением, как на каждую объясняющую переменную должно приходиться не менее тридцати наблюдений...
-
Проблема прогнозирования вероятности банкротства существует уже несколько десятков лет - все началось с работ Ramser, Foster (1931), Fitzpatrick (1932) и...
-
Заключение - Уровень конкурентоспособности строительных компаний
В ходе проведенного исследования была построена logit-модель вероятности дефолта для непубличных компаний строительного комплекса. Данная модель поможет...
-
Для дополнительной наглядности полученных результатов предлагается подготовить рейтинговую шкалу, которая отмечала бы, какие значения вероятности дефолта...
-
Предпосылки построения индекса Строительная отрасль России характеризуется очень большим объемом строительных компаний и объемом работ, выполненных по...
-
Проверим значимость квадратичной формы переменных для двух полученных моделей. Сначала рассмотрим значимость данных преобразований для первой модели...
-
Построение модели с помощью логистической регрессии Прежде чем строить логистическую регрессию, необходимо выбрать конечный набор финансовых и...
-
Переход к порядковым и нормированным шкалам - Уровень конкурентоспособности строительных компаний
Далее предпримем попытки улучшить качество полученных моделей с помощью поочередного перехода к порядковой шкале и нормированной шкале. Полученные...
-
Для целей проверки гипотезы о значимости рассматриваемых нами институциональных показателей (место нахождения, задолженность по уплате налогов), в...
-
Применим аппарат. Результаты приведены ниже Таблица 6. индексный анализ Рисунок 4. График сглаженного признака Полиномиальная регрессия Приведем массив...
-
Динамическая модель кассовых сборов неплохо описывает динамику кассовых сборов фильмов. Но она еще не приспособлена для прогнозирования, значения части...
-
На основе данных таблицы 1 приложения А построим предварительную регрессионную модель: Модель 1: МНК, использованы наблюдения 2005:01-2007:12 (T = 36)....
-
Построение и анализ эконометрической модели - Построение экономических моделей
На основе данных таблицы 1 приложения А построим предварительную регрессионную модель: Модель 1: МНК, использованы наблюдения 2005:01-2007:12 (T = 36)...
-
Разработка алгоритма нахождения входного потока заявок в имитационной модели контрольно-пропускной системы на основе статистических данных В наши дни...
-
Искусственные нейронные сети (ИНС) рассматриваются исследователями как возможная альтернатива статистическим методам. Исследования, использующие ИНС, как...
-
На следующем этапе в модель были добавлены дамми-переменные годов и отраслей. Таблицы соотношения переменных и данных приведены ниже. Кроме дамми...
-
Явления общественной жизни складываются под воздействием целого ряда факторов, то есть являются многофакторными. Между факторами существуют сложные...
-
Современные экономические теории и исследования опираются в значительной степени на использование математических моделей и методов анализа. Постоянно...
-
Тадии парного регрессионного анализа можно представить на следующем рисунке ПОЛЕ КОРРЕЛЯЦИИ Это графическое изображение точек с координатами, которые...
-
Построение многофакторной корреляционно-регрессионной модели производительности труда
Построение многофакторной корреляционно-регрессионной модели производительности труда Данная работа направлена на выявление факторов, от которых зависит...
-
Введение - Построение экономических моделей
Современные экономические теории и исследования опираются в значительной степени на использование математических моделей и методов анализа. Постоянно...
-
Основной целью исследования является сравнение предсказательной силы моделей, построенных на основе различных методов. В условиях несбалансированности...
-
ФАКТОРНАЯ МОДЕЛЬ ПРИ НОРМИРОВАННЫХ ПЕРЕМЕННЫХ - Многомерный статистический анализ
С математической точки зрения факторный анализ аналогичен множественному регрессионному анализу в том смысле, что каждая переменная выражена как линейная...
-
Построение модели на реальных данных - Ранговый метод оценивания параметров регрессионной модели
Для построения линейной регрессионной модели на основе реальных данных при помощи рангового метода оценивания параметров был выбран достаточно известный...
-
Построим показательный тренд ВВП. Используем данные таблицы (в млрд. руб) [14]. Таблица 1. Данные к работе Год Квартал Номер квартала ВВП 2001 I 1 1900,9...
-
Возьмем данные об инвестициях в основной капитал (млрд. руб.) Год Квартал Номер квартала Значение 2003 I 1 330 II 2 470,4 III 3 608,8 IV 4 773,7 2004 I 5...
-
В первоначальном выборе объясняющих переменных существует две стратегии. Часть авторов осуществляют подбор переменных, опираясь на собственные...
-
Элементы корреляционного анализа Зависимость между случайными величинами (СВ) X и Y в теории вероятностей и математической статистике описывается, в...
-
КОВАРИАЦИОННЫЙ АНАЛИЗ, ПАРНАЯ КОРРЕЛЯЦИЯ - Многомерный статистический анализ
По сути дела эта дисперсионный анализ, который включает, по крайней мере, одну категориальную независимую переменную и одну интервальную или метрическую...
-
Динамика индекса конкурентоспособности - Уровень конкурентоспособности строительных компаний
Ниже можно ознакомиться с первыми результатами расчета всего "семейства" индексов (см. табл. 33 и рис.7): Таблица 33. Значения ИКСО по федеральным...
Подготовка данных для построения модели и статистический отбор объясняющих переменных - Уровень конкурентоспособности строительных компаний