Методологія оцінювання економічної ефективності паралельних обчислень - Економічна ефективність розподілених систем і паралельних обчислень
Основна ідея розпаралелювання обчислень - мінімізація часу виконання задачі за рахунок розподілу навантаження між декількома обчислювальними пристроями. Цими "обчислювальними пристроями" можуть бути як процесори одного суперкомп'ютера, так і кілька комп'ютерів рангом нижче, об'єднаних за допомогою комунікаційної мережі в єдину обчислювальну структуру - кластер.
Найпоширенішими способами паралельної обробки є чистий паралелізм і конвеєризація.
Чистий паралелізм характеризується повторним використанням однакових елементів, об'єктів, модулів і дає прямо пропорційне зростання використаним елементам продуктивності.
Конвеєризація. Якщо кожну мікро-операцію задачі виділити в окремий пристрій і розташувати їх у порядку виконання, причому вхід п-ного мікро-пристрою пов'язаний з виходом n - 1 , то такий спосіб організації обчислень носить назву конвеєрної обробки. Кожен мікро-пристрій називається кроком конвеєра, а загальне число кроків визначає довжину конвеєра.
Якщо конвеєр містить n кроків і кожен з них спрацьовує за одиницю часу, то час обробки n незалежних операцій складе < L + n - 1.
Всі операції бувають двох типів: векторні і скалярні.
Якщо хоча б один елемент операції є вектором, то операція називається векторною. Тоді кількість операцій визначається: L + (n - 1) + , де - час ініціалізації вектора. Векторні операції ефективні тоді, коли n >> , в протилежному випадку вектори перетворюються в скаляри, тобто, оскільки ні, ні L не залежать від n, то із збільшенням довжини вхідних векторів, ефективність конвеєрної обробки зростає. Звідси отримаємо таку форму оцінювання ефективності:
E = n/t = n /( + L + n - 1) = 1 /((/n) + (L/n) + - (/n)) = 1 / + (( + L - 1)/n),
При n E 1/

Для формування паралельного алгоритму необхідно:
Ідентифікувати частини роботи, які можуть бути виконані одночасно
Відобразити зазначені частини на множину одночасно застосовуваних процесорів
Розподілити вхідні, вихідні і проміжні дані між процесами відповідно до поставленої задачі
Керувати доступом до спільно використовуваних даних
Синхронізувати процеси на різних стадіях виконання програми
Процес розподілу обчислень на менші частини, деякі або всі з яких можуть бути виконані паралельно, називається декомпозицією.
Задачі - це визначені програмістом модулі обчислень, на які поділяється основне завдання за допомогою декомпозиції. Задачі можуть мати довільний розмір, однак ті, що вже визначені, розуміються як неподільні.
Частіше за все декомпозиція розбиває завдання на множину взаємозалежних задач. Абстракція, яка відображає зв'язок між задачами і власний порядок їх виконання називається ГЗЗ.
ГЗЗ - це направлений, ациклічний граф, вузли якого є виконуваними задачами, а дуги вказують на залежність між ними. Якщо задачі є незалежними, то ГЗЗ буде незв'язаним.
Число і розмір задач визначає ступінь деталізації паралельного алгоритму. Декомпозицію на велику кількість малих задач називають мілкомодульною, а на велику кількість крупних задач - крупномодульною. Поняття, пов'язане із ступенем деталізації - ступінь паралелізму. Максимальне число задач, які в паралельній програмі можуть бути виконані одночасно, носять назву максимальний ступінь паралелізму.
В більшості випадків максимальний ступінь паралелізму є меншим за загальну кількість задач через взаємодію задач.
Середній ступінь паралелізму - це відношення загальної кількості задач до висоти паралельної форми алгоритму (кількості тактів).
Ступінь паралелізму також залежить від форми ГЗЗ. Одна і та сама ступінь деталізації не визначає один і той самий ступінь паралелізму. Число і розмір задач визначає ступінь деталізації паралельного алгоритму. Декомпозицію на велику кількість малих задач називають мілкомодульною, а на велику кількість крупних задач - крупномодульною. Поняття, пов'язане із ступенем деталізації - ступінь паралелізму. Максимальне число задач, які в паралельній програмі можуть бути виконані одночасно, носять назву максимальний ступінь паралелізму.
В більшості випадків максимальний ступінь паралелізму є меншим за загальну кількість задач через взаємодію задач.
Середній ступінь паралелізму - це відношення загальної кількості задач до висоти паралельної форми алгоритму (кількості тактів).
Крім зернистості і ступеня паралелізму є ще один чинник, який не дає отримати максимальне прискорення від застосування паралельного алгоритму, а саме взаємодія між задачами, що виконуються на різних процесорах. Модель взаємодії задач характеризується ГВЗ. Вершинам і ребрам ГВЗ можуть бути представлені ваги, відповідно до кількості обчислень і числа взаємодій, що передаються вздовж ребра. Ребра в ГВЗ частіше за все неорієнтовані, але вони можуть вказувати на напрям, якщо потік даних однонаправлений. Масив ребер ГВЗ зазвичай надмножина масиву ребер ГЗЗ.
Будь-яка обчислювальна система (ОС) є сукупністю функціональних пристроїв (ФП), що працюють паралельно в часі. Оцінимо роботу ОС за допомогою спеціальних характеристик. Для цього введемо ряд понять.
Назвемо ФП простим, якщо жодна наступна операція не може почати виконуватись раніше, ніж закінчиться попередня. Основна риса такого пристрою - монопольне використання свого обладнання для виконання кожної окремої операції. На відміну від простого ФП, конвеєрний ФП розподіляє своє обладнання для одночасної реалізації декількох операцій. Простий ФП завжди можна вважати конвеєрним з довжиною конвеєра, рівною 1.
Назвемо вартістю операції час її реалізації, а вартістю роботи -- суму вартостей всіх виконаних операцій. Тобто, вартість роботи -- це час послідовної реалізації всіх даних операцій на простих ФП з аналогічними періодами спрацьовувань. Завантаженістю пристрою на даному відрізку часу називатимемо відношення вартості реально виконаної роботи до максимально можливої вартості. Ясно, що завантаженість р завжди задовольняє умовам 0 ? р ? 1. За визначених умов оцінювання сформулюємо деякі твердження.
ТВЕРДЖЕННЯ 1
Максимальна вартість роботи, яку можна виконати за час Т, рівна Т для простого ФП і nТ для конвейєрного ФП довжини n.
Називатимемо реальною продуктивністю системи пристроїв кількість операцій, реально виконаних в середньому за одиницю часу. Піковою продуктивністю називатимемо максимальну кількість операцій, яка може бути виконана тією ж системою за одиницю часу за відсутності зв'язків між ФП. З визначень витікає, що як реальна, так і пікова продуктивності системи є сумами відповідно реальних і пікових продуктивностей всіх складових системи пристроїв.
ТВЕРДЖЕННЯ 2
Нехай система складається з s пристроїв, в загальному випадку простих або конвеєрних. Якщо пристрої мають пікові продуктивності р1,...рs і працюють із завантаженостями р1,...,рs, то реальна продуктивність системи виражається формулою
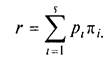
Введемо поняття "прискорення":
Нехай алгоритм реалізується за час Т на обчислювальній системі з s пристроїв, що мають пікові продуктивності 1,....,s, які зв'язані співвідношенням 1?2?....?s. Прискоренням реалізації алгоритму в такій ОС або просто прискоренням R будемо називати відношення R=r/s. Беручи до уваги вищенаведене, маємо
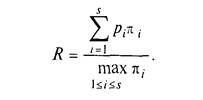
Розглянемо систему з s пристроїв. Оскільки будь-який конвеєрний ФП завжди можна представити як лінійний ланцюжок простих пристроїв, то вважатимемо всі пристрої простими. Допустимо, що між пристроями встановлені направлені зв'язки, і вони не міняються в процесі функціонування системи. Побудуємо орієнтований мультиграф, в якому вершини символізують пристрої, а дуги -- зв'язки між ними. Назвемо цей мультиграф графом системи.
Дослідимо максимальну продуктивність системи, тобто її максимально можливу реальну продуктивність при достатньо великому часі функціонування.
ТВЕРДЖЕННЯ 3
Нехай система складається з s простих пристроїв з піковими продуктивностями 1,....,s. Якщо граф системи зв'язний, то максимальна продуктивність rmax системи виражається формулою:
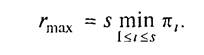
Майже дослівне повторенням твердження 3 носить назву:
НАСЛІДОК (1-ИЙ ЗАКОН АМДАЛА)
Продуктивність обчислювальної системи, що складається із зв'язаних між собою пристроїв, в загальному випадку визначається найменш продуктивним її пристроєм.
Припустимо, що всі пристрої, до того ж, прості і універсальні, тобто на них можна виконувати різні операції. Хай на такій системі реалізується деякий алгоритм, а сама реалізація відповідає якійсь його паралельній формі. Допустимо, що висота паралельної форми рівна m, ширина рівна q і всього в алгоритмі виконується N операцій.
НАСЛІДОК (2-ИЙ ТА 3-ИЙ ЗАКОНИ АМДАЛА)
Мінімальне число пристроїв системи, при якому може бути досягнуто максимально можливе прискорення, рівне ширині алгоритму.
Припустимо, що з яких-небудь причин n операцій з N ми вимушені виконувати послідовно. Причини можуть бути різними. Наприклад, операції можуть бути послідовно зв'язані інформаційно. І тоді без зміни алгоритму їх не можна реалізувати інакше. Відношення = n/N назвемо часткою послідовних обчислень.
НАСЛІДОК (2-Й ЗАКОН АМДАЛА)
Нехай система складається з s однакових простих універсальних пристроїв. Припустимо, що при виконанні паралельної частини алгоритму всі s пристроїв завантажені повністю. Тоді максимально можливе прискорення рівне:
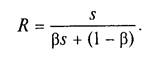
Позначимо через пікову продуктивність окремого ФП. Оскільки якщо система складається з s пристроїв однакової пікової продуктивності, то прискорення системи дорівнює сумі завантаженості всіх пристроїв:
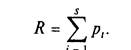
Якщо всього виконується N операцій, то серед них N операцій виконується послідовно і (1 - )N паралельно на s пристроях по (1 - )N/s операцій на кожному. Можна вважати, що всі послідовні операції виконуються на першому ФП. Всього алгоритм реалізується за час:
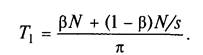
На паралельній частині алгоритму працюють як перший, так і вся решта пристроїв, витрачаючи на це час:
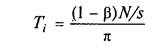
Для 2 ? і ? n. Тому p1 = 1 і
Отже,
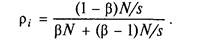
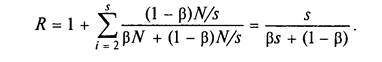
НАСЛІДОК (3-Й ЗАКОН АМДАЛА)
Нехай система складається з простих однакових універсальних пристроїв. При будь-якому режимі роботи її прискорення не може перевершити зворотню величину частки послідовних обчислень.
Потоки - це об'єкти, які отримують час процесора. Час звичайно виділяється квантами. Квант часу - це інтервал, що є у розпорядженні потоку до тих пір, поки час не буде у нього відібрано і передано в розпорядження іншого потоку. Потрібно мати на увазі, що кванти виділяються не програмам або процесам, а породженим ними потокам. Як мінімум, кожен процес має хоча б один потік, але Windows 95 і Windows NT дозволяють запустити в рамках процесу скільки завгодно потоків.
Два головні типи потоків -- асиметричні і симетричні. Частіше всього на персональних комп'ютерах використовують асиметричні потоки. Асиметричні потоки (Asymmetric threads) -- це потоки, що вирішують різні задачі і, як правило, не розділяють ресурси. Один з таких потоків відповідає за друк; інший обробляє повідомлення від клавіатури і миші; третій завідує автоматичним збереженням документа користувача. Симетричні потоки (Symmetric threads) виконують одну і ту ж роботу, розділяють одні ресурси і виконують один код.
Похожие статьи
-
Координація процесів - Економічна ефективність розподілених систем і паралельних обчислень
Очевидно, що при програмуванні для однопотокового середовища в будь-який момент часу звертається до об'єкту лише 1 потік, то є гарантія що кожний метод...
-
Операційна система планує час процесора відповідно до пріоритету потоків. Коли потік створюється, йому призначається пріоритет, відповідний пріоритету...
-
Элементы матричного анализа - Методы решения системы линейных уравнений
Вектором, как на плоскости, так и в пространстве, называется направленный Отрезок , то есть такой Отрезок , один из концов которого выделен и называется...
-
В настоящее время нельзя назвать область человеческой деятельности, в которой в той или иной степени не использовались бы методы моделирования. Особенно...
-
Характеристика існуючої системи управління обіговими коштами Системи управління обіговими коштами базується на системі обліку, яка є джерелом інформації....
-
Применение нейронных сетей в финансовой сфере - Прогнозирующие системы
Характерный пример успешного применения нейронных вычислений в финансовой сфере - управление кредитными рисками. Как известно, до выдачи кредита банки...
-
Анализ эффективности систем массового обслуживания с ожиданием - Теория массового обслуживания
Система с ограниченной длиной очереди. Рассмотрим n - канальную СМО с ожиданием, на которую поступает поток заявок с интенсивностью л=14/час;...
-
В данном случае анализируемые системы характеризуются не одним набором показателей эффективности, а несколькими: (18) Где - группа показателей...
-
Отсутствие моделей и количественных методик, позволяющих оценить эффект от намеченных интеграционных процессов и степень их влияния на экономическую...
-
Разработка алгоритма нахождения входного потока заявок в имитационной модели контрольно-пропускной системы на основе статистических данных В наши дни...
-
Принципы декомпозиционного анализа экономической системы
Принципы декомпозиции Декомпозиция исходной системы или глобальной задачи производится путем применения принципов декомпозиции и координации. Первые...
-
Основные понятия теории экономико-математического моделирования Кибернетический подход к исследованию экономико-математических систем Обычно...
-
Заключение - Моделирование систем массового обслуживания с использованием метода Монте-Карло
Метод Монте-Карло можно определить как метод моделирования случайных величин с целью вычисления характеристик их распределений. Возникновение идеи...
-
Например, если изучается модель спроса как соотношение цен и количества потребляемых товаров, то одновременно для прогнозирования спроса необходима...
-
Проблема идентифицируемости - Системы эконометрических уравнений, их применение в эконометрике
Идентификация - это единственность соответствия между приведенной и структурной формами модели. При переходе от приведенной формы модели к структурной...
-
СПОСОБЫ ОПИСАНИЯ СТРУКТУР. МОРФОЛОГИЯ СОЦИАЛЬНО-ПОЛИТИЧЕСКОЙ И ЭКОНОМИЧЕСКОЙ СФЕР Структурное моделирование. Структурный анализ Основная цель...
-
Розвиток будь-якого підприємства потребує визначення його реального планування та ефективності його фінансово-господарської діяльності, у зв'язку з чим...
-
Введение - Одноканальные системы массового обслуживания
Во многих областях практической деятельности человека мы сталкиваемся с необходимостью пребывания в состоянии ожидания. Подобные ситуации возникают в...
-
ВСТУП - Основні аспекти імітаційного моделювання
Імітаційне моделювання застосовується у всіх сферах діяльності людини починаючи від моделей технічних, технологічних та організаційних систем і...
-
СТРУКТУРЫ УПРАВЛЕНИЯ ЛОГИСТИЧЕСКИМИ СИСТЕМАМИ - Понятие и виды логистической системы
Объектом логистическими системами, как известно является сквозной материальный поток, тем не менее на отдельных участках управление им имеет известную...
-
Построение, или моделирование, конечной факторной системы для анализируемого экономического показателя хозяйственной деятельности можно осуществить как...
-
Метод Монте-Карло используют для вычисления интегралов, в особенности многомерных, для решения систем алгебраических уравнений высокого порядка, для...
-
Система "Диспетчер" апробирована на реальных исходных данных двух регионов Нефтяной Компании "Юкос" (Липецкая и Воронежская области) и показала свою...
-
ВОСЬМЕРИЧНАЯ И ШЕСТНАДЦАТИРИЧНАЯ СИСТЕМЫ СЧИСЛЕНИЯ - Системы счисления
С точки зрения изучения принципов представления и обработки информации в компьютере, обсуждаемые в этом пункте системы представляют большой интерес. Хотя...
-
ДВОИЧНАЯ СИСТЕМА СЧИСЛЕНИЯ - Системы счисления
Особая значимость двоичной системы счисления в информатике определяется тем, что внутреннее представление любой информации в компьютере является...
-
Моделирование динамики рыночной системы
Введение В современных условиях динамичного развития рыночной системы экономика, испытывающая многочленные подъемы и спады, требует внешнего воздействия,...
-
Моделирование процессов управления предполагает последовательное осуществление трех этапов исследования. Первый - от исходной практической проблемы до...
-
Модель сети с обратным распространением - Прогнозирующие системы
Способом обратного распространения (back propogation) называется способ обучения многослойных НС. В таких НС связи между собой имеют только соседние...
-
Визначення : Сукупність лінійно незалежних векторів, по яких відбувається розкладання інших векторів, називається Базисом . Отже, у площині можуть...
-
Оптимізація діяльності в ARIS зводиться до виділення, формалізації і структурування бізнес - процесів з метою формування на їх основі "наскрізного"...
-
В работе рассматривается задача нахождения маршрутов развоза товаров на объекты заданного региона, возникающая у компаний, желающих сократить...
-
Кредитна система Російської Федерації - Еволюція грошово-кредитної системи Росії
Традиційне уявлення про банк тільки як про кредитний і розрахунково-платіжний інститут нині суттєво змінилося. Сучасний комерційний банк -- це...
-
Системы уравнений используемые в экономике - Эконометрика как наука
Объектом статистического изучения в социальных науках являются сложные системы. Измерение тесноты связей между переменными, построение изолированных...
-
В состав системы эконометрических уравнений входят множество зависимых или эндогенных переменных и множество предопределенных переменных (лаговые и...
-
Исследования, проводимые в последние годы, указывают на перспективность использования систем, для которых характерна фотоинициируемая валентная...
-
Так як підприємство має інвестиційні ресурси, що можуть бути вкладені тільки в один з проектів, то для дослідження ефективності розподілу інвестиційних...
-
Теоретическое обоснование математического моделирования - Математические методы и модели в экономике
Коммерческая деятельность в том или ином виде сводится к решению таких задач: как распорядиться имеющимися ресурсами для достижения наибольшей выгоды или...
-
В настоящей работе предлагается классификация задач многокритериальной оценки эффективности систем различного назначения. В качестве факторов...
-
Наиболее ранним способом формализации экономико-математических и ТС является представление физических явлений с помощью систем дифференциальных...
-
Функциональные свойства систем - Системная революция и принцип дуального управления
Функциональная полнота системы определяет степень соответствия системы функций, выполняемых системой, множеству функций, выполнение которых необходимо с...
Методологія оцінювання економічної ефективності паралельних обчислень - Економічна ефективність розподілених систем і паралельних обчислень