Тестовые прогоны на модели ОА-архитектуры dataflow-ВС задач бенчмарка GRAPH500 на основе алгоритмов решения теоретико-графовых задач - Преимущества применения dataflow-парадигмы в вычислительных системах
При прогонах тестовой программы, написанной на ПЯ, для алгоритма бенчмарка Graph500, изменялись значения входных параметров, таких как:
- - N - число ИУ суперкомпьютерной системы при моделировании; - 2M - число вершин графа - K - число вершин графа, которое обрабатывает одно функциональное устройство
На следующих графиках результаты тестовых прогонов задачи бенчмарка Graph500 при различных значениях параметров N, M и K. Графики показывают зависимость коэффициента параллелизма вычислительной системы от времени выполнения теста.
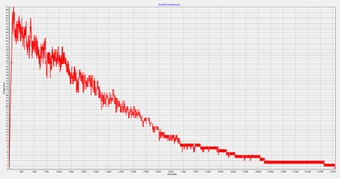
Рисунок 26 - Результаты моделирования теста Graph500 при N = 100 (максимально 57 ИУ задействовано), T = 13102, D = 228,768176408621.
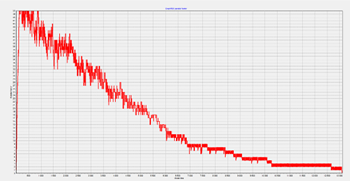
Рисунок 27 - Результаты моделирования теста Graph500 при N = 50, T = 13110, D = 227,085797409818
По результатам моделирования могут быть построены графики зависимости времени выполнения теста и дисперсии от числа ядер в dataflow-ВС (см. Таблица 29 и Рисунок 86).
Таблица 4. Зависимость времени выполнения и дисперсии теста Graph500 от числа ядер
|
N |
T |
D |
|
1 |
221747 |
0 |
|
2 |
111097 |
0,004007322 |
|
5 |
46383 |
0,592867836 |
|
10 |
25890 |
7,814802056 |
|
15 |
19586 |
27,15531038 |
|
20 |
16642 |
58,18736677 |
|
30 |
14162 |
135,1538952 |
|
40 |
13302 |
200,9084474 |
|
50 |
13110 |
227,0857974 |
|
100 |
13102 |
228,7681764 |
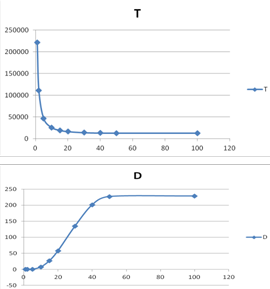
Рисунок 28, 29 - Время выполнения и дисперсия от числа задействованных в ВП ИУ для теста Graph500
На рисунках ниже приведен расчет выходных характеристик моделируемой вычислительной системы:
- - зависимость модельного времени (T) выполнения теста от числа исполнительных ядер и от числа функциональных устройств - зависимость среднего коэффициента параллелизма (P) от числа исполнительных ядер и от числа функциональных устройств - зависимость дисперсии среднего коэффициента параллелизма (D) от числа исполнительных ядер и от числа функциональных устройств - зависимость коэффициента использования аппаратуры (A) от числа исполнительных ядер и от числа функциональных устройств
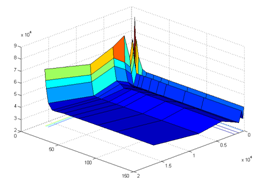
Рисунок 30. Зависимость времени выполнения (T) от числа исполнительных (Rd) и виртуальных устройств (Fu).
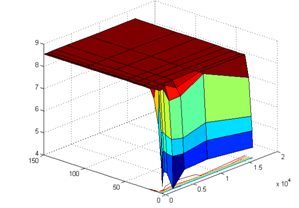
Рисунок 31. Зависимость коэффициента параллелизма P от числа исполнительных (Rd) и виртуальных устройств (Fu).
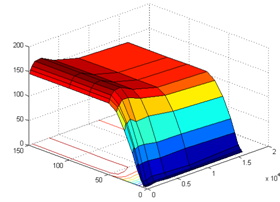
Рисунок 32. Зависимость дисперсии (D) среднего коэффициента параллелизма P от числа исполнительных (Rd) и виртуальных устройств (Fu).
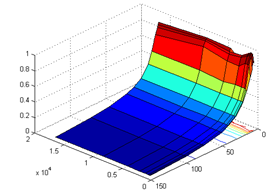
Рисунок 33. Зависимость коэффициента использования оборудования (A) от числа исполнительных (Rd) и виртуальных устройств (Fu).
Наиболее оптимальное число ядер для данных параметров моделирования - 10-20 шт. По критерию "время исполнения (T)" оптимальное число - 15. По критерию "дисперсия (D)" - 20. После 20 ИУ время выполнения тестового набора Graph500 изменяется незначительно.
Похожие статьи
-
Все проводимые ниже тесты были проведены для получения характеристик производительности моделируемой системы, описанных в разделе №2. Для каждого теста...
-
Данный тест моделирует работу интернет-ресурсов социальных сетей. Социальная сеть представляется в виде графа, где узлы обозначают людей, а ребра - связи...
-
Ядром вычислительной dataflow-системы будем называть совокупность оборудования, которое осуществляет сбор данных для формирования исполняемого пакета. В...
-
Выбор и обоснование критериев оценки моделируемой системы Основными критериями оценки созданной вычислительной системы с управлением потоком данных по...
-
Моделирование различных вычислительных систем можно разделить на два главенствующих класса: матечатическое моделировании и имитационное. Математическое...
-
В реалиазации милликомандного типа управления вычислительной системой основную роль играет функциональное устройство "Автомат". Это устройство отвечает...
-
ОА-архитектура - Преимущества применения dataflow-парадигмы в вычислительных системах
В данной работе предлагается использование объектно-атрибутной архитектуры ВС (или ОА-архитектуры). В отличие от классической ВС, ОА-архитектура работает...
-
Grep - хорошо известная утилита командной строки различных операционных систем. С ее помощью можно производить поиск по тексту строк, соответствующих...
-
Оценка моделируемой ВС осуществляется на основе анализа функционирования ВС на тестовых задачах по следующему набору параметров: - общее число ИУ в ВС; -...
-
В предыдущем разделе был приведен необходимый для получения набор выходных характеристик моделируемой вычислительной системы, требуемый от тестирования....
-
По Р. Шеннону (Robert E . Shannon - профессор университета в Хантсвилле, штат Алабама, США ), "имитационное моделирование - Есть процесс конструирования...
-
Для проверки соответствия требованиям ТЗ, была поставлена задача разработки 3-D модели корпуса Kyocera KD-PB1D79 при помощи системы AutoCAD. В этой части...
-
Программный алгоритм визуальный гаусс В программу включены следующие процедуры: "gauss1", "gaussj", "New1Click", "Button1Click", "Button2Click",...
-
Основные этапы имитационного моделирования - Имитационные модели информационных систем
Как уже отмечалось, имитационное моделирование применяют для исследования сложных экономических систем. Естественно, что и имитационные модели...
-
Тепловое моделирование было проведено в системе ANSYS Icepak. При заданных условиях окружающей среды (температура +40 ОС), температура на корпусе...
-
3.1 Алгоритм функционирования СУ технологического объекта Рисунок 8 - Общий алгоритм функционирования 3.2 Алгоритм запуска технологического объекта...
-
Аннотация В статье рассматриваются два способа уменьшения времени вычисления дерева решений для задач линейного параметрического программирования с...
-
Расчет надежности системы, Завершенность - Моделирование беспроводных сенсорных сетей
Для разрабатываемого программного обеспечения необходимо определение следующих свойств: - завершенность; - устойчивость; - восстанавливаемость; -...
-
Вычислительные эксперименты для оценки эффективности параллельного варианта метода Гаусса для решения систем линейных уравнений проводились при следующих...
-
Для того, чтобы вынести решение об оправданности или неоправданности внедрения автоматизированного тестирования вместо ручного, необходимо...
-
Введение - Преимущества применения dataflow-парадигмы в вычислительных системах
Dataflow-парадигма В архитектурах вычислительных сетей на сегодняшний день преобладающую роль играют ВС, управляемые потоком команд - Control Flow. Такая...
-
Введем начальные условия, необходимые для реализации метода Рунге-Кутта 4-го порядка: S(0)=100, E(0)=1, I(0)=0,R(0)=0, t=[0,30]. Параметры Sigma = 0.5 ;...
-
Постановка задачи Необходимо разработать программу для поиска автобусных маршрутов. В качестве среды разработки должна использоваться Delphi 7. В...
-
Широкое распространение в операционной системе Windows имеет множество стандартных программ обеспечивающих работу устройств компьютера и служащих для...
-
Заключение. - Приложения технологии системы электронных таблиц Excel к решению задач механики
Целью курсовой работы являлось изучение полного спектра функциональных возможностей технологии системы электронных таблиц Excel. - Задачами данной работы...
-
СХЕМА АЛГОРИТМА РАБОТЫ ПРОГРАММЫ, ЗАКЛЮЧЕНИЕ - Основы программирования в операционной системе Unix
Блок-схема главной функции программы (main) изображена на рисунке 4. Рисунок 4 - блок-схема main. cpp Блок-схема модуля (Math. cpp) изображена на рисунке...
-
Математическое обеспечение позволяет использовать методы автоматизированного поиска оптимальных вариантов при проектировании системы. Часто при решении...
-
Рассмотрим решение системы дифференциальных уравнений построенной по вероятностной модели предприятия УП "Проектный институт Гродногипрозем". Данная...
-
Функционально-структурная организация персонального компьютера. Персональные компьютеры используют в домашних условиях. Их основное назначение:...
-
По заданному значению выбираем длину линии и удельное сопротивление линии. = 50 км; Марка провода ЛЭП: АС - 240 1.2 Расчет параметров модели...
-
Нахождение ожидаемых доходов в центральной системе Рассмотрим замкнутую сеть массового обслуживания с разнотипными заявками, которая является...
-
Задача многокритериальной оптимизации формально представляется как задача нелинейного программирования, включающая: процедуру анализа, выбор управляемых...
-
Рассмотрим замкнутую сеть массового обслуживания с разнотипными заявками, которая является вероятностной моделью обслуживания заявок в УП "Проектный...
-
Устойчивость элементов и устройств к внешним воздействиям. Характеристики климатических воздействий. Механическая прочность. Радиационная стойкость...
-
На рисунке 1 представлен фрагмент электронной таблицы, в которой содержаться исходные данные для решения задачи. Рисунок 1 - Фрагмент электронной...
-
Для анализа производственных систем, которые очень сложны, разноплановы, не имеют исчерпывающего математического описания, а также проходят ряд этапов...
-
Классификация математических моделей - Теоретические основы информационных технологий
К классификации математических моделей можно подходить по-разному, положив в основу классификации различные принципы. 1) Классификация моделей по...
-
Классификация имитационных моделей - Имитационные модели информационных систем
Имитационные модели принято классифицировать по четырем наиболее распространенным признакам: Типу используемой ЭВМ; Способу взаимодействия с...
-
Необходимо исследовать зависимость влияния различных факторов на параметр, характеризующий производство. В качестве такого параметра было выбрано...
-
- Подключение к исходной базе данных пользователей внешних информационных систем; - Отказ в доступе к желаемому ресурсу, если пользователем не пройдена...
Тестовые прогоны на модели ОА-архитектуры dataflow-ВС задач бенчмарка GRAPH500 на основе алгоритмов решения теоретико-графовых задач - Преимущества применения dataflow-парадигмы в вычислительных системах