Уменьшение времени построение дерева решений для задач линейного программирования с помощью параллельных вычислений
Аннотация
В статье рассматриваются два способа уменьшения времени вычисления дерева решений для задач линейного параметрического программирования с помощью параллельных вычислений. Основным отличием второго способа от первого является более мелкое разбиение на подзадачи. Изучаются и сравниваются результаты применения обоих способов, делается вывод о направлении дальнейших исследований: повышение мелкости подзадач.
Ключевые слова: дерево решений, диспетчер задач, закон Амдала, линейное параметрического программирование, линейное программирование, параллельные вычисления, симплекс-метод, система поддержки истинности
Параллельный вычисление программирование
Построение дерева решений в задачах линейного параметрического программирования, при большой размерности задачи или при большом количестве параметров, нередко занимает значительное время. Ввиду комбинаторной природы задачи и используемого переборного алгоритма, а также текущего направления развития вычислительной техники, наиболее актуальным способом сократить общее время построения дерева решений является использование параллельных вычислений [1, с. 99].
Рассмотрим подробнее один из этапов алгоритма построения дерева решении? [2, с. 119; 3, с. 321], заключающийся в генерации таблиц. В основу алгоритма генерации таблиц заложена процедура симплекс-метода. Основная задача алгоритма генерации таблиц, заключается в получении всех пар: (возможная таблица, набор предположении?). При этом набор предположении?, в общем случае, состоит из сложной системы предположении?, которая тем не менее приводится к конъюнктивной нормальной форме. На входе алгоритма дана симплекс-таблица для задачи линейного параметрического программирования. Параметры задачи выраженные символами записываются в ячейки симплекс-таблицы так, как будто они являются численными.
Изложение алгоритма будет приводится поэтапно "сверху-вниз", сначала будет рассмотрен основной алгоритм, а затем отдельно будет рассмотрен один из его этапов.
Алгоритм перебора всех возможных коэффициентов критерия оптимизации (алгоритм I):
Из всех коэффициентов критерия оптимизации необходимо выделить набор таких коэффициентов, которые могут быть неположительными. Если полученный набор непустой, то это фиксируется в виде истинного значения специального флага, в противном случае, в этот флаг помещается значения "ложь".
Для каждого коэффициента полученного на предыдущем шаге создается набор предположении?, необходимых для того, чтобы столбец соответствующий этому коэффициенту вошел в новый базис.
Для каждой пары (коэффициент критерия оптимизации, набор предположений) вызывается процедура генерации таблиц для каждой из оптимизируемых переменных, которые являются кандидатами на исключения из базиса. Результатом это процедуры может стать нуль или более пар (таблица, набор предположении?). Каждая таблица в таких парах является возможной таблицей для перехода.
Если значение специального флага, заданного на этапе 1 является "ложь", то рассматривается случаи?, когда все коэффициенты критерия оптимизации больше нуля. Это равносильно тому, что текущая таблица не предполагает дальнейших переходов и представляет оптимальное решение. В этом случае текущая таблица с набором предположении?, что все коэффициенты критерия оптимизации больше нуля добавляется к результату полученному на предыдущем шаге.
Приведенная процедура сначала проводится для начальной таблицы, полученные в ее результате таблицы формируют первый уровень дерева решении?. Затем процедура проводится для каждой из таблиц первого уровня, а полученные результаты сформируют второй уровень, и т. д. На определенном этапе таблицы процедура перестанет выдавать новые таблицы, поскольку предположения, принятые на предыдущих этапах, будут противоречить предположениям, которые необходимо принять на данном. Это будет означать, что было достигнуто одно из решении?. Таблица, являющаяся листом дерева представляет собой оптимальное решение при некоторых принятых предположениях, т. е. при определенных значениях переменных величин, входящих в описание задачи.
Рассмотрим подробнее алгоритм генерации всех таблиц для некоторой оптимизируемой переменной c учетом того, что для этой переменой у нас имеется набор предположении?, необходимый для ее рассмотрения (алгоритм II):
Выбор коэффициента критерия оптимизации сужает выбор разрешающего элемента до коэффициентов матрицы ограничений, находящихся в одном столбце. На первом этапе из всего таких коэффициентов отбрасываются заведомо неположительные.
Для каждого коэффициента из оставшихся на предыдущем шаге, составляется набор предположении?, необходимых, чтобы этот коэффициент был разрешающим элементом. Чтобы составить набор предположений для некоторого текущего коэффициента, необходимо для всех остальных коэффициентов получить два типа предположений. Первый тип предположений заключается в том, что другой коэффициент является отрицательным, поэтому разрешающим быть не может. Второй тип предположений заключается в том, что другой коэффициент положительный, но его выбор приводит к менее выигрышному переходу. Поскольку обычно оба типа предположений являются допустимыми, необходимо рассмотреть их все.
После формирования набора предположении? для каждого коэффициента из предыдущего этапа, согласно правилам симплекс-метода формируется новая таблица. Получаемая в итоге таблица и набор предположении? формируют результат процедуры.
Итогом работы процедуры является набор пар (таблица, набор предположении?).
Таким образом, осуществляется перебор всех возможных решении?, получаемых при помощи симплекс-метода.
Переборная основа алгоритма открывает сразу несколько возможностей для использования параллельных вычислении?. Одной из таких возможностей является параллельная обработка в ходе алгоритма генерации возможных таблиц. Генерация возможных таблиц является независимым процессом, и после генерации такая таблица может быть проанализирована независимо от остальных.
Рассмотрим модель параллельных вычислении? в программе для построения дерева решении?. Модель состоит из компонентов двух типов: диспетчер задач и рабочий процесс. Назначение диспетчера задач заключается в распределении задач между рабочими процессами и в аккумуляции результатов вычислении?. Назначением рабочего процесса является получение задачи от диспетчера задач, проведение вычислении? и выдача результата диспетчеру задач. Количество рабочих процессов может варьироваться в широких пределах, но обычно их количество примерно совпадает с количеством независимых вычислительных ядер, участвующих в вычислениях. Рабочие процессы между собой не взаимодействуют, а для взаимодействия между рабочими процессами и диспетчером задач используются очереди. Одна общая очередь с задачами, ожидающими решения, и одна общая очередь результатов решения. Диспетчер задач заполняет первую очередь и считывает результаты из второй. Рабочие процессы, наоборот, считывают задачи из первой очереди и складывают результаты во вторую.
Применительно к построению дерева решении? в качестве задачи в рабочих процессах выступает применение алгоритма генерации возможных таблиц. В связи с этим в очередь задач для решения складываются таблицы, для которых необходимо применить этот алгоритм. В качестве результатов применения также выступают таблицы, для которых необходимо применить этот алгоритм. При получении этих таблиц через очередь результатов они попадают в очередь задач, ожидающих решения. При этом в рамках рабочего процесса, при получении новых таблиц для обработки, они отправляются диспетчеру задач. Таким образом, обеспечивается своевременное появление новых задач в очереди для решения и ликвидируется простаивание рабочих процессов.
Испытание приведенного выше алгоритма (в дальнейшем он будет обозначаться как "версия 1") привело к следующим результатам: увеличение количества рабочих процессов сверх 4 не приводит к уменьшению времени работы. Анализ ситуации показал, основное время рабочие процессы затрачивают на генерацию всех дочерних таблиц и проверку непротиворечивости каждой из них, по мере готовности отправляя готовые для дальнейшей обработки задачи диспетчеру. При этом время обработки полностью одной таблицы либо достаточно велико, либо очень мало. Что приводит к тому, что все работа разбивается на сравнительно небольшое число крупных задач, которые выполняются последовательно каждым вычислительным процессом.
Чтобы избежать подобной ситуации?, был разработан второй вариант алгоритма (в дальнейшем он будет обозначаться как "версия 2"). Новый вариант алгоритма предполагает выполнения рабочими процессами 3 видов работ, обусловленных этапом решения задачи. Как и прежде рабочий процесс извлекает новую задачу из очереди. В зависимости от того, какую задачу он извлек, он выполняет соответствующую работу.
К первому виду работ относится выявление возможных вводимых в базис оптимизируемых переменных, для чего выполняется алгоритм I за исключением пункта 3. Вместо выполнения пункта 3, происходит добавление информация о полученной паре в очередь задач. Таким образом, формируются задачи, обработка которых относится ко второму виду работ.
Второй вид работы предполагает выполнение пункта 2 алгоритма II. Результатом выполнения этого алгоритма является набор пар (таблица, набор предположении?), каждая из которых по мере поступления добавляется в очередь задач для дальнейшей обработки. Каждая пара (таблица, набор предположении?) формирует задачу, обработка которой относится к третьему виду работ.
Третий вид работ предполагает проверку истинности составленных предположении?, и в случае, если предположения совместны между собой и предположениями исходной таблицы, формируется новая дочерняя таблица. Диспетчеру отправляется информация о новой дочерней таблице, тот в свою очередь добавляет эту дочернюю таблицу для обработки в очередь, формируя тем самым работы, обработка которых относится к первому виду работ.
Таким образом, задача обработки одной таблицы была разбита на 3 этапа, каждый из которых может быть выполнен независимо от других.
При этом теоретически оценить возможный прирост производительности согласно закону Амдала [4, c. 483] или закону Густавсона--Барсиса [5, c.532] не представляется возможным, ввиду того, что прирост для приведенного способа распараллеливания зависит от распределения нагрузки на процессы-вычислители, а не от доли параллельных и последовательных этапов алгоритма.
Для реализации описанного процесса вычислении? использовался входящий в стандартную поставку комплекта для разработки на языке программирования Python модуль "multiprocessing". При этом использовалась возможность распараллеливания вычислении? между процессами, а не потоками операционной системы. Это вызвано особенностями реализации языка программирования Python: она не предусматривает одновременное выполнение нескольких потоков и использует для синхронизации глобальную блокировку "GlobalInterpreterLock". Блокировкой сопровождается любое обращение к переменным текущего процесса интерпретатора, что приводит к тому, что даже при наличии нескольких вычислительных потоков, вычисления могут происходить только в одном из них. Использование процессов для распараллеливания вычислении? приводит к значительным накладным расходам на передачу данных, в то время как потоки могут разделять данные между собой, т. к. находятся в одном адресном пространстве. Припередачи данных между процессами используется модуль "pickle".
Для исследования быстродействия варианта программы использующей параллельные вычисления использовался следующий подход. Поскольку время, необходимое для построения дерева, достаточно большое, для измерения времени построения дерева использовался измеритель времени доступный в среде Python. После считывания задачи и перед началом построения запоминалось время полученное с помощью метода time. time(). Аналогично, после построения дерева, до его записи в файл, проводилось считывания текущего значения времени. Разница между двумя значениями составляла время построения дерева. Для каждого испытания построение дерева проводилось не менее 10 раз, после чего вычислялось среднее и погрешность измерения по методу Стьюдента.
В таблицах 1 и 2 приведены результаты испытания для соответственно "версии 1" и "версии 2" вариантов распараллеливания.
Таблица 1 -- Результаты испытания распараллеленного варианта (версия 1)
|
Количество вычислителей |
Время построения дерева, c |
Время относительно №1 |
Прирост производительности относительно №1 |
|
1 |
(200 ± 2) ? 10 |
1.000 |
-- |
|
2 |
(104 ± 3) ? 10 |
0.52 |
1.92 |
|
3 |
852 ± 12 |
0.427 |
2.35 |
|
4 |
652 ± 17 |
0.327 |
3.07 |
|
5 |
641 ± 19 |
0.321 |
3.12 |
|
6 |
632 ± 14 |
0.317 |
3.16 |
Таблица 2 -- Результаты испытания распараллеленного варианта (версия 2)
|
Количество вычислителей |
Время построения дерева, c |
Время относительно №1 |
Прирост производительности относительно №1 |
|
1 |
(203 ± 5) ? 10 |
1.000 |
-- |
|
2 |
1046 ± 19 |
0.52 |
1.94 |
|
3 |
747 ± 5 |
0.367 |
2.72 |
|
4 |
644 ± 6 |
0.317 |
3.16 |
|
5 |
576 ± 12 |
0.284 |
3.53 |
|
6 |
533 ± 6 |
0.262 |
3.82 |
Согласно полученным данным были построены два графика. Первый график иллюстрирует зависимость времени построения дерева от количества процессов - вычислителей (см. рис. 1). На нем представлено убывание времени построения дерева в зависимости от количества процессов-вычислителей для "версии 1" и "версии 2", а также для идеального случая помеченного "линейное", когда время убывает пропорционально количеству процессов. На графике видно, что разница между временем построения для количества процессов-вычислителей 4, 5 и 6 практически отсутствует для "версии 1" в отличие от "версии 2".
График на рис. 2 иллюстрирует зависимость прироста производительности от количества процессов-вычислителей. На графике представлено прирост производительности в зависимости от количества процессов-вычислителей для "версии 1" и "версии 2", а также для идеального случая помеченного "линейный", когда прирост производительности зависит от количества процессов линейно.
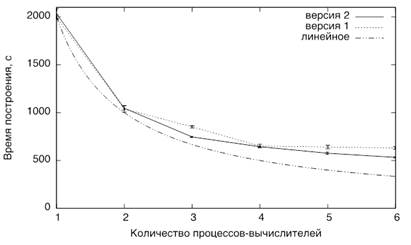
Рисунок 1 -- График зависимости времени построения от количества процессов - вычислителей.
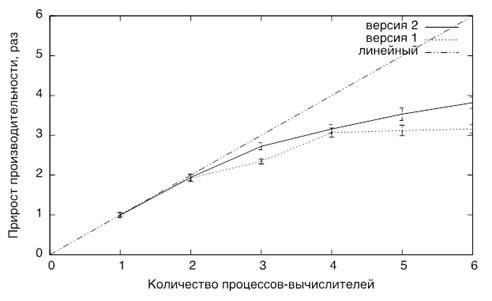
Рисунок 2 -- График зависимости прироста производительности от количества процессов-вычислителей.
График на рис. 1 имеет характерное сходство с графиками, построенными для аналогичных систем при исследовании влияния количества процессов-вычислителей на прирост производительности [6; 7]. Однако, если в случае "версии 1" максимальное значение прироста производительности практически достигнуто, то в случае "версии 2" максимальное значение еще не достигнуто и для его нахождения необходимо увеличить количество процессов-вычислителей.
Результаты испытании? подтверждают то, что прирост производительности при построении дерева в случае использования распараллеленного варианта программы зависит от распределения нагрузки на процессы-вычислители. Увеличение прироста производительности в случае "версии 2" обусловлен более мелким разбиением задач на части, что позволяет разделить крупные подзадачи на еще более мелкие подзадачи и выполнять их параллельно. При этом приведенный алгоритм построения дерева может быть разбит на еще более мелкие подзадачи. В частности, наиболее перспективной, в смысле использования параллельных вычислений, частью алгоритма, является система поддержки истинности, т. к. ее основной алгоритм представляет собой практически независимое друг от друга исследование различных альтернатив методами символьной алгебры. Использование этого потенциала позволило бы ценой увеличения накладных расходов на передачу данных между процессами, увеличить эластичность распараллеливания, и тем самым увеличить прирост производительности в случае использования большого числа процессов-исполнителей.
Исследование выполнено при финансовои? поддержке РФФИ в рамках научного проекта No 13-07-00465
Библиографический список
Немнюгин С. А., Стесик О. Л. Параллельное программирование для многопроцессорных вычислительных систем. - СПб. : БХВ-Петербург, 2002. - 400 с.
Кокуев А. А., Ктитров С. В. Построение дерева решении? в задачах линейного программирования // Вестник Национального исследовательского ядерного университета "МИФИ". - 2014. - Т. 3, №1.
Кокуев А. А., Ктитров С. В. Построение дерева решении? в задачах линейного программирования // Тезисы докладов XX международного научно-технического семинара "Современные технологии в задачах управления, автоматики и обработки информации". - М. : Изд-во ПГУ, 2011.
AmdahlGene M. ValidityoftheSingleProcessorApproachtoAchievingLargeScaleComputingCapabilities // ProceedingsoftheApril 18-20, 1967, SpringJointComputerConference. - AFIPS '67 (Spring). - NewYork, NY, USA: ACM, 1967. - URL: http://doi. acm. org/10.1145/1465482.1465560.
GustafsonJohn L. ReevaluatingAmdahl'sLaw // Communicationsofthe ACM. - 1988. - Vol. 31.
BrownRobert G. MaximizingBeowulfPerformance. - 2000. - URL: http://www. phy. duke. edu/~rgb/brahma/brahma_old/als. pdf (online; accessed: 10.04.2015).
AnderssonKarl-Johan, AronssonDaniel, KarlssonPatrick. Anevaluationofthesystemperformanceof a beowulfcluster. - 2001. - URL: http://www. it. uu. se/edu/course/homepage/projektF/vt01/rapporter/grupp2/grendel. pdf (online; accessed: 10.04.2014).
Похожие статьи
-
"РЕШЕНИЕ ЗАДАЧ ЛИНЕЙНОГО ПРОГРАММИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ MICROSOFT EXCEL" Цель работы Приобретение навыков решения задач линейного программирования...
-
Варианты - Решение задач линейного программирования с использованием Microsoft Excel
Используя MS Excel, найти решение для модели ЛП, соответствующей заданному варианту (табл. 1.5). Таблица 1.5 Варианты задач к лабораторной работе № 1 №...
-
Транспортная задача - Линейное программирование
Одна из наиболее распространенных задач математического программирования -- транспортная задача. В общем виде ее можно представить так: требуется найти...
-
Методика решения задач ЛП графическим методом - Линейное программирование
I. В ограничениях задачи (1.2) заменить знаки неравенств знаками точных равенств и построить соответствующие прямые. II. Найти и заштриховать...
-
Математический аппарат Для понимания всего дальнейшего полезно знать и представлять себе геометрическую интерпретацию задач линейного программирования,...
-
Необходимо исследовать зависимость влияния различных факторов на параметр, характеризующий производство. В качестве такого параметра было выбрано...
-
Языки и методы параллельного программирования - Администрирование параллельных процессов
Применение параллельных архитектур повышает производительность при решении задач, явно сводимых к обработке векторов. Автоматическое распараллеливание...
-
Деревья решений - это способ представления иерархической, последовательной структуры организованной по определенным правилам, где каждому объекту...
-
Язык программирования R - Технологии больших данных: анализ и выбор решения для реализации проекта
Язык программирования R является универсальным и разработан для применения в следующих областях: разведочный анализ данных, классические статистические...
-
Построение дерева - Деревья решений
Пусть нам задано некоторое множество T, содержащее объекты, каждый из которых характеризуется m атрибутами, причем один из них указывает на...
-
Для упрощения работы с трехмерной моделью на любом этапе проектирования и повышения ее наглядности в SolidWorks используется Дерево Построений (Feature...
-
Постановка задачи: Для заданных функций необходимо: 1. Построить электронную таблицу (одну для обеих функций) для вычисления значений функций в заданном...
-
Формы и характеристики параллелизма Параллелизм -- это возможность одновременного выполнения нескольких арифметико-логических или служебных операций. На...
-
1. Каковы основные этапы решения задач ЛП в MS Excel? 2. Каков вид и способы задания формул для целевой ячейки и ячеек левых частей ограничений? 3. В чем...
-
На рисунке 1 представлен фрагмент электронной таблицы, в которой содержаться исходные данные для решения задачи. Рисунок 1 - Фрагмент электронной...
-
, Алгоритм обратного хода: Шаг 1. Вычислим Шаг 2. Вычислим: , Рис. 1. Основной алгоритм решения СЛУ методом исключения Гаусса. Для контроля правильности...
-
Для вычисления цвета могут быть использованы различные подходы. Вычисление цвета может проводиться одновременно с геометрической реконструкцией,...
-
Введение. - Приложения технологии системы электронных таблиц Excel к решению задач механики
История развития программ обработки электронных таблиц насчитывает немногим более десяти лет, но налицо значительный прогресс в области разработки такого...
-
Распределение задач между процессами - Администрирование параллельных процессов
Распределение подзадач между процессорами является завершающим этапом разработки параллельного метода. Надо отметить, что управление распределением...
-
Разделение вычислений на независимые части - Администрирование параллельных процессов
Выбор способа разделения вычислений на независимые части основывается на анализе вычислительной схемы решения исходной задачи. Требования, которым должен...
-
Предлагаемая библиотека хранит все данные в отдельных таблицах, таким образом он не обязан использовать ту же СУБД, что и основное приложение. В качестве...
-
Датчики Pt1000 (TSQ* и TSH*) прекрасно подходят для любых климатических систем, где необходимо измерять температуры в диапазоне от -50 до 250 °C с...
-
Входная информация разделяется на условно-постоянную и оперативно-учетную информацию. - Условно-постоянная информация включает в себя справочные данные о...
-
Программная модель данных, получившая название "MapReduce", была создана несколько лет назад в компании Google, и там же была осуществлена первая...
-
Решение задач линейного программирования - Основы информатики
Имеются n пунктов производства и m пунктов распределения продукции. Стоимость перевозки единицы продукции с i-го пункта производства в j-ый центр...
-
Параллельная виртуальная машина кластера кафедры АИС - Администрирование параллельных процессов
Так как в основе кластера АИС лежит параллельная система Beowulf, в качестве основы его вычислительной среды используем коммуникационную библиотеку PVM...
-
Табличный процессор Excel фирмы Microsoft предназначен для ввода, хранения, обработки и выдачи больших объемов, данных в виде, удобном для анализа и...
-
Широкое распространение в операционной системе Windows имеет множество стандартных программ обеспечивающих работу устройств компьютера и служащих для...
-
При разработке практически всех инструментальных средств за основу принимается методология автоматизации проектирования на базе использования прототипов....
-
Расчет таблицы - Программа построения равновесных стратегий для игры
В ходе разработки программы, для эффективной работы основного алгоритма программы будет понадобилось рассчитать некоторые предрасчетные данные. Для этого...
-
Предложенный подход к решению задач исследования Используя в качестве основы присутствующее в наличии программное обеспечение, которое применимо к...
-
Аналитический способ решения задачи №3 представляет собой проверку вычислений: - для лица Лушников В. В. сумма налога на дарение составит 0, т. к. сумма...
-
Для решения задачи №3 необходимо ввести исходные данные в электронную таблицу, т. е. таблицы 1,2 (рисунок 16). Рисунок 16 - Ввод исходных данных в...
-
Операционная система Windows XP была разработана и выпущена на смену операционной системе DOS фирмой Microsoft XP в 2002 году. Именно поэтому она и...
-
Введение - Программные и аналитические решения финансовых и экономических задач
Табличные процессоры - одно из важнейших средств для решения задач широкого назначения. Табличные процессоры в силу своей наполненности включены в пакет...
-
Подход NoSQL - Технологии больших данных: анализ и выбор решения для реализации проекта
Понятие NoSQL означает "Не только SQL" или "Не SQL". Термин получил известность, начиная с 2009 год, когда развитие интернет-технологий и социальных...
-
Взаимодействие задач с PVM - Администрирование параллельных процессов
В системе PVM каждая задача, запущенная на некотором процессоре, идентифицируется целым числом, которое называется идентификатором задачи (TID) и по...
-
МАТЕМАТИЧЕСКАЯ ПОСТАНОВКА ЗАДАЧИ - Анализ потерь рабочего времени сорудников предприятия
Постановка задачи Имеется смета на выполнение проекта монтажа охранной сигнализации, в которой расписаны этапы выполнения работ, подбор специалистов на...
-
Выполнения проекта монтажа охранной сигнализации состоит из множества операций, которые складываются в этапы работ проекта. Схематично структура этапов...
-
Ожидается, что предлагаемая библиотека даст большой прирост в производительности операций чтения, заполнив собственную нишу среди решений проблем...
Уменьшение времени построение дерева решений для задач линейного программирования с помощью параллельных вычислений