Введение - Преимущества применения dataflow-парадигмы в вычислительных системах
Dataflow-парадигма
В архитектурах вычислительных сетей на сегодняшний день преобладающую роль играют ВС, управляемые потоком команд - Control Flow. Такая парадигма вычислений ориентирована на последовательные вычисления. Она основывается на понятии программного счетчика, который хранит адрес ячейки памяти, из которой считывается выполняемая на текущий момент времени команда. Признаки control-flow-архитектуры видны также и на программном уровне: в настоящее время наиболее популярными языками программирования являются императивные языки (Pascal, С, C++, Java и др). Было предпринято множество попыток создания аппаратных систем, управляемых потоком данных, однако особых успехов они не принесли, т. к. ядром подобных систем являлся вычислитель фон-неймановской архитектуры.
Одним из перспективных способов оптимизации вычислительного процесса является применение dataflow-парадигмы, т. е. метода управления вычислительным процессом потоком данных. Данная парадигма известна уже более тридцати лет. Работы по аппаратной и программной реализаций этой концепции проводились различных исследовательских центрах. Например, в Массачусетском технологическом институте (процессор Tagget Token), лабораториях корпорации Tеxas Instruments (США), в Манчестерском университете (Англия). Но все же наивысшим успехом данных проектов было создание экспериментальных прототипов.
В dataflow-системах очередность выполнения вычислительных задач зависит от готовности операндов. Как только необходимое число операндов приходит на исполнительное устройство, оно тут же начиняет выполнять свою вычислительную задачу. Стоит отметить, что очередность исполнения команд может коренным образом отличаться от очередности записи команд в программе. Налицо одно из главных преимуществ data-flow парадигмы: разные итерации одного цикла могут выполняться одновременно, на разных вычислительных узлах. Более того, (i+1)-я итерация цикла способна начаться исполняться быстрее, чем i-я, при условии наличия всех необходимых операндов. Система состоит из множества исполнительных устройств, каждое из которых может быть настроено "узко": например, на выполнение вычислительных операций лишь одного типа.
С помощью данной концепции возможно преодолеть слабое место скалярных процессоров, которое заключается в потери времени на процедуры управления данными и спекулятивные вычисления.
Анализ существующих решений в области dataflow-ВС
В истории науки проводились попытки создания эффективных систем dataflow не только на аппаратном уровне, но и на уровне программном. В реализации на программном уровне были достигнуты некоторые положительные результаты: создание объектно-ориентированной парадигмы программирования (ООП), частично работающий по событийному принципу (в особенности язык Smalltalk); некоторые функциональные языки (например, Mozart, Sisal). Итак, перечислим некоторые решения, связанные с программной реализацией принципа dataflow.
Сети Кана
Считается, что предтечей всех dataflow-языков являются сети Кана (англ. Kahn) (Рисунок 1), в которых вычислительный процесс представляется в виде модулей (акторов) обменивающихся между собой сообщениями по линиям связи, установленными между ними. На линиях связи имеются очереди сообщений для того, чтобы в них помещались сообщения, которые ввиду занятости модуля-приемника, не могут быть в данный момент приняты на обработку. Данная модель вычислений была предложена в 1974 году.
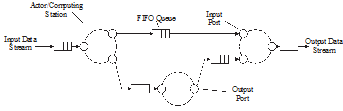
Рисунок 1 - Процессная сеть Кана
U-язык
Данный язык (Рисунок 2) используется для описания токенов, передаваемых по дугам потокового графа в машинах с памятью фреймов.
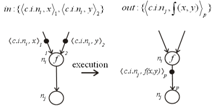
Рисунок 2 - U-язык
Каждый токен включает в себя два поля:
- - активное имя; - данные.
Активное имя, в свою очередь, включает в себя тег, который состоит из полей:
- - адрес инструкции (n); - поле контекста (c), уникально идентифицирующий контекст, в который входит инструкция; - номер итерации (i), который идентифицирует активную итерацию цикла; - в том случае, если узел, куда пересылаются данные, имеет несколько входных аргументов, то в тег включается номер порта назначения узла-адресата (p).
LUCID (1976)
Язык основан на концепции потока: даже константы, представляют собой поток (числовые константы - это поток состоящий из повторений данной числовой константы). Язык по сути функциональный. Потоки могут быть как бесконечные, так и конечные (конечным поток будет, если в качестве его хвоста использована специальное значение eod (end of data). Арифметические операции применяются к потокам поэлементно.
Одна из версий языка под названием Granular Lucid (GLU), разработанная в калифорнийской компании SRI International, предназначена для описания алгоритма крупнозерниского dataflow: dataflow-программа пишется на языке LUCID, а "зерна" - на языке Си. "Зерна" оформляются в виде функций на языке Си, расположенных в отдельном файле.
ID (IRVINE DATAFLOW) 1978
Язык используется для программирования dataflow-систем Массачусетского технологического института (MIT) и системы Monsoon фирмы Motorola. Концепция данного языка высокого уровня была предложена Арвиндом и Гостлоу (англ. Arvind and Gostelow). Язык предназначен для программирования параллельных архитектур, в том числе, и динамического dataflow. Основные черты языка: однократное присвоение значений переменным, блочная структуризация программы, функциональная парадигма. Типы переменных не задаются напрямую, а определяются по значению, которое было в них помещено. Структуры данных и массивы не различаются между собой: элементы структуры могут адресоваться как с помощью индекса, так и с помощью строковых идентификаторов (например, ", t[''height'']"). Над структурами данных определены две операции select (выбор), предназначенный для того, чтобы получить значение из поля данных структуры, и append (добавить), необходимая, чтобы создать новую структуру путем копирования полей другой структуры данных или чтобы записать значение в поле структуры данных.
Id-программа состоит из набора свободных выражений и подвыражений, которые могут выполняться в любом порядке в зависимости от наличия данных (операндов) для их выполнения.
VAL (A Value-oriented Algorithmic Language) 1979
Язык был разработан а Массачусетском технологическом университете. VAL - это язык программирования высокого уровня, который не содержит машинозависимых элементов, что обеспечивает переносимость программы на различные аппаратные платформы. Язык предназначен для реализации статической потоковой архитектуры (следовательно, не реализуются рекурсивные вызовы). По синтаксису напоминает язык Pascal. Функции и выражения могут возвращать сразу несколько значений. У каждой переменной имеется специальное значение "Ошибка". Это нужно для того, чтобы сохранить необходимый порядок вычислений: если значение переменной еще не получено, то переменная содержит значение "Ошибка". Язык обеспечивает скрытое описание параллелизма. В данном языке переменные могут определяться только один раз (до определения в переменной хранится значение "пусто", а после присвоения значения, содержимое переменной меняться уже не может). Во время декларации массивов их размерность не указывается: размерность можно задать и определить с помощью специальных команд.
В VAL весьма ограничены возможности ввода/вывода и не поддерживается рекурсия из-за того, что программа транслируется напрямую в потоковый граф.
SISAL (Streams and Iterations in a Single Assignment Language) 1983 г.
Язык SISAL ориентирован на поддержку научных вычислений и представляет собой дальнейшее развитие языка VAL. Язык появился на свет благодаря сотрудничеству Ливерморской национальной лаборатории имени Лоренца, Университета штата Колорадо, Манчестерского университета (Великобритания) и Digital Equipment Corporation (DEC). Создатели языка ставили перед собой следующие задачи: 1. язык должен эффективно работать на машинах как последовательной, так и параллельной архитектур; 2. обеспечить создание независимого от языка и целевой архитектуры промежуточного представления программы в виде потокового графа; 3. разработать технику оптимизации параллельных программ; 4. внедрить функциональный стиль программирования для сложных научных расчетов; 5. обеспечить программирование микропроцессорных ВС с распределенной памятью.
Хотя SISAL и относится к разряду функциональных языков, однако ему присущи и элементы декларативной парадигмы программирования. Причем декларативная часть программы свободна от побочных эффектов: программа представляет собой набор последовательных императивных процедур, связанных между собой обменом данными. Оптимизирующий компилятор языка SISAL освобождает пользователя от работы по распараллеливанию программы, беря на себя всю нагрузку по планированию операций, передачу данных, синхронизацию вычислений, управлению памятью, что позволяет программисту сконцентрироваться именно на описании логики программы, не больше ни на чем.
Язык получил большую популярность в 90-е годы благодаря тому, что существовал компилятор, который мог переводить программу на этом языке в язык С, и потому программы, написанные на SISAL могли запускаться на любой машине, где был реализован С-компилятор. Еще одна причина популярности языка кроется в весьма удачной концепции модулей и интерфейсов, когда описание функций находится в интерфейсе, а алгоритм самих функций помещается в модуле.
POST
Язык дает обширные возможности по программированию:
- - возможность влияния на стратегию вычислений уже в процессе выполнения программы; - структуры данных, являющие одновременно синхронными и асинхронными; - взаимодействие между вычислениями, чтобы прекратить вычисления по лишним ветвям алгоритмов.
Однако синтаксис программы чрезвычайно неудобен для понимания.
ПИФАГОР 1995
Этот функциональный язык разработан в Красноярском Государственном Техническом Университете (КГТУ).
Программа в ПИФАГОР представляет собой граф программы, описываемый с помощью специальных языковых конструкций. Данные передаются по дугам графа посредством токенов, переносящих как скалярные и векторные величины, так и функции преобразования данных.
Модель вычислительного процесса задается с помощью тройки
M = ( G, P, S0 ),
Где G - ациклический граф, что определяет информационную структуру программы (ее информационный граф),
P - набор правил, определяющих динамику функционирования модели (механизм формирования разметки),
S0 - начальная разметка.
Информационный граф G, в свою очередь, задается двойкой:
G = ( V, A ),
Где V - множество вершин определяющих программо-формирующие операторы,
A - множество дуг, задающих пути передачи информации между ними.
Программно-формирующие операторы, являющиеся вершинами графа, осуществляют информационные преобразования данных, их структуризацию и размножение. Существуют следующие типы операторов:
- - Интерпретации. Узел данного типа имеет два входа (по одному поступает аргумент, что требуется преобразовать с помощью функции, код которой поступает на второй вход; преобразованная величина поступает на единственный выход). - Константный оператор. Данный узел выдает фишку с константой. - Копирования данных. Копирует пришедшие на единственный вход данные на несколько выходов. - Группировки в список: данные, пришедшие на несколько входов, группируются в один список. - Группировки в параллельный список: пришедшие данные группируются в параллельный список (элементы параллельного списка рассматриваются оператором интерпретации как независимые аргументы). - Группировки в список задержанных вычислений. (На рисунке данный оператор представлен в виде прямоугольника, выделяющего определенный подграф). С помощью этого оператора в графе программы выделяется отдельный подграф, выполнение которого активизируется не только по приходе всех необходимых для вычисления данных, но и при снятии задержки, т. е. разрушении границ подграфа.
Ввиду того, что программа ориентирована на непосредственное описание графа программы, синтаксис языка весьма отличается от общепринятого синтаксиса. Например, в языке не поддерживаются инфиксные бинарные операции, отсутствуют модульное построение программы, раздельная трансляция и интеграция стандартных библиотек, что не могло сказаться на популярности данного языка программирования. Отсутствие циклов в языке Пифагор компенсируется возможностью использования рекурсии. А сочетание механизма перегрузки функций и динамических типов, определяемых пользователем, обеспечивает написание эволюционно расширяемых параллельных программ. К тому же в языке реализован механизм перегрузки функций, что позволяет производить безболезненное масштабирование программы.
Mozart
В данном языке программирования, поддерживающим множество парадигм вычислений, реализуется и стратегия dataflow. Для этой цели существует команда Wait, которая используется для синхронизации по данным нескольких параллельных нитей вычислений. Нить, в коде которой встречается команда Wait(A), (A - переменная), дойдя до данной команды, будет ожидать, пока другая нить не запишет данные в переменную A. Как только данные в переменную будут записаны, нить продолжит свою работу. Принцип dataflow может использоваться в языке Mozart и более широко (Листинг 1): здесь в переменную S поступают значения -- если переменная S пустая (не заполненная), то поток, реализующий данную программу останавливается до того момента, когда данные поступят (как очередная порция данных поступить нить вычислений возобновится, и снова остановится для ожидания следующией порции данных и так далее, пока не поступят все данные).
For Msg in S do
End
Листинг 1. Считывание потока данных в языке Mozart
Smalltalk
Язык Smalltalk основывается на следующих понятиях:
- 1. Объект. Вся программа состоит из совокупности объектов, обменивающимися сообщениями между собой. Объекты состоят из полей (данные) и методов (подпрограмм, обрабатывающих пошедшие сообщения). Каждому объекту соответствует свой протокол. 2. Класс. Однотипные объекты объединяются в классы, а каждый объект является экземпляром класса. 3. Метод. Подпрограмма, предназначенная для обработки сообщения, пришедшего от другого объекта. Каждому типу сообщения соответствует свой метод его обработки. Основная задача метода -- при приходе сообщения соответствующим образом изменить состояние объекта и выслать ответ на пришедшее сообщение. 4. Операторы. Существует всего три оператора: посылка сообщения, выдача ответа, присваивание значения переменной. Синтаксис оператора посылки сообщения несколько напоминает синтаксис естественного языка (подлежащее - сказуемое - дополнение): объект-получатель ИмяСообщения, [объекты-атрибуты], например: 5 factorial - объекту 5 посылается сообщение с именем "factorial";
А - 3 - объекту "а" посылается сообщение с именем "-" и аргументом 3;
Pen move:east by:10 - объекту pen посылается сообщение "move:eastby:10" , где "move" и "by" -- селекторы ключевых слов, по которым метод идентифицирует пришедшие с сообщением аргументы, а "east" и "10" -- сами аргументы (":" - обозначение того, что после селектора идет указание параметра).
Хотя Smalltalk очень близок по духу к концепции dataflow, однако он до конца, все же, не уходит от командной парадигмы: по сути сообщение -- это завуалированное описание одной фон-неймановской команды. Можно сказать, что программная среда Smalltalk создает среду из виртуальных объектов, которые обмениваются между собой командами.
DCF
Язык DCF - это расширение языка C для работы в режиме dataflow. Модель, реализованная в DCF, относится к классу data-control flow (система, сочетающая в себе модель управления вычислениями с помощью потоков команд и данных). DCF зиждется на двух ключевых понятиях: нить и токен. Нить является классическим легковесным процессом (цепочка последовательно выполняемых команд). Нить начинает выполняться, как только для программы этой нити приходят все необходимые данные. Функция, реализуемая в виде отдельной нити вычислений, описывается с помощью ключевого слова "thread" вместо типа возвращаемого значения: thread Func( int N, float Var ) { ... }. Выполнение программы начинается с функции-потока с именем main. Функции-нити могут порождать другие нити; выполнение программы считается завершенным, когда завершаются все вычислительные нити.
Данные же передаются с помощью токенов, которые состоят из тега, идентифицирующего получателя данных; самих данных типов int, float, char языка Си, другую описывающую информацию о передаваемых данных. Тег состоит из двух полей: имя функции-получателя данных и "цвет", задающую номер итерации цикла. С помощью токенов происходит запуск и возобновление работы функций. Токены "обитают" в неком "пространстве" токенов, где они хранятся и где происходит их сбор и объединение в группы: каждая группа -- это набор токенов, необходимых для запуска определенной нити вычислений (полностью скомплектованная группа содержит токены, хранящие данные для всех аргументов активируемой функции-потока).
Модель акторов
Модель исходит из того, что вся программа делится на несколько независимых программ (акторов), обменивающихся между собой сообщениями: если актору приходят данные необходимые для выполнения одного из заложенных в него привил, он производит вычисление и выдает сообщение с результатами другим акторам по специальным линиям связи (реальным или виртуальным). Актор может иметь внутреннее состояние и менять его в соответствии с заложенным в него алгоритмом. Во избежание потери информации, организуются очереди сообщений: если актор занят обработкой данных, то пришедшее сообщение помещается в очередь. Модель весьма хорошо подходит для реализации на распределенных ВС, т. к. каждый актор может существовать в изолированном адресном пространстве (связь осуществляется только через очереди сообщений). Термин "актор" был впервые предложен Карлом Хьюиттом (Carl Hewit) в 1970-х годах, который пытался с его основе разработать концепцию "мыслящих исполнительных устройств" (autonomous reasoning agents). Идея акторов применительно к модели параллельных вычислений была затем развита в научных работах Агха.
Акторная модель состоит из двух составляющих:
- 1. Описание акторов (в описание входят интерфейс актора (описание входов и выходов актора), параметры (они обычно задаются перед началом вычислений и во время вычислительного процесса не меняются), алгоритм получения выходных результатов); 2. Описание соединений акторов, по которым они обмениваются сообщениями (задается с помощью XML-файла, специального графического редактора или программы, использующей специальных аппаратно-программный интерфейс (например, SystemC)).
Приведем описание актора на языке Caltrop (листинг 2):
Actor AddAndMultiply2[T] (T k) T A, T B > T C :
Action [a], [b] > [k ? (a + b)] : endaction
Action [a], [] > [k ? a] : endaction
Action [], [b] > [k ? b] : endaction
Endactor
Листинг 2. Описание актора на языке Caltrop
Здесь в качестве входных значений выступают A и B, а в качестве выходного -- C, в качестве параметра актора выступает k (T - обозначение типа переменной); и описаны три действия (action), которые активизируются при:
- 1. приходе двух операндов; 2. приходе только операнда А; 3. приходе только операнда В.
Данный подход уже давно используется в системах Simulink от The Mathworks, LabVIEW от National Instruments, ML-Designer, ПИФАГОР, Erlang, Caltrop и т. д.
Графическое программирование
Программы, выполненные в данной парадигме, представляют алгоритм не в виде текста, а в графическом виде: элементарные операторы и сложные функции иллюстрируются с помощью определенных графических объектов, а передача операндов (скалярных величин или информационных конструкций) от одной операции или функции к другой -- графическими линиями связи (Link). Во время выполнения программы по link-ам будут передаваться токены с данными или ссылками на информационные конструкции. Можно сказать, такая графическая модель как раз и служит отражением графа потока данных.
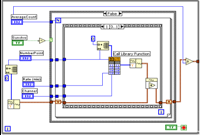
Рисунок 3 - Среда LabView
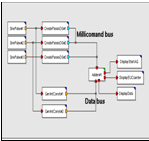
Рисунок 4 - Среда моделирования MLDesigner
В качестве представителей данной парадигмы следует упомянуть системы программирования LabView (Рисунок 3) и MLDesigner (Рисунок 4). Первая система применяется для решения любых вычислительных задач, вторая -- в основном для моделирования различных систем. Данный подход весьма похож на модель акторов (графические элементы являются акторами, которые по виртуальным линиям связи обмениваются различными сообщениями). Родоначальником такой парадигмы программирования можно считать Джека Денниса, который предложил описывать алгоритмы dataflow-машин с помощью изображения потокового графа.
Выводы по анализу программных решений dataflow
Как было показано выше, в основном для реализации систем dataflow применяется функциональная парадигма программирования. Это объясняется тем, что данная парадигма не задает четкой "траектории" вычислений (т. е. последовательности операций), как в классической процедурной (императивной) парадигме вычислений. Именно отсутствие программного счетчика и позволяет произвести полноценное распараллеливание вычислений, и управление вычислительным процессом с помощью потока команд. Однако функциональная парадигма в среде программистов, к сожалению, не получила должной популярности. Чрезвычайно популярная объектно-ориентированная же парадигма больше тяготит к процедурному стилю программирования и не обеспечивает полноценную работу в режиме dataflow. Единственным объектно-ориентированным языком, полностью соответствующим парадигме управления вычислительным процессом с помощью потока данных, является Smaltalk, который, к сожалению, не очень-то любим в среде программистов.
Многие языки, что разрабатывались под конкретные dataflow-машины (например, VAL), со временем были забыты. Универсальные же языки (например, SISAL), которые поддерживали кроссплатформенность развиваются и до сих пор.
Весьма выгодным оказывается направление по созданию гибридных покового-командных языков, таких как DCF: они позволяют программисту работать в привычной процедурной (императивной) парадигме, по возможности добавляя элементы dataflow-стиля.
Акторная модель весьма удобна для реализации на гетерогенных ВС, однако она имеет очень существенный недостаток: программа делится на множество маленьких кусков, которые не очень-то легко воспринимаются как единое целое.
В заключение следует отметить, что до сих пор не создано dataflow-языка программирования, который был бы безоговорочно принят в программистской среде -- сейчас наиболее популярна процедурная (императивная) и объектно-ориентированная парадигмы, которые соответствуют концепции control flow.
Похожие статьи
-
В основном для многих вычислительных систем топологическое проектирование производится с помощью нейросетевых алгоритмов так, чтобы минимизировать...
-
По Р. Шеннону (Robert E . Shannon - профессор университета в Хантсвилле, штат Алабама, США ), "имитационное моделирование - Есть процесс конструирования...
-
Введение - Система управления базами данных
Развитие средств вычислительной техники обеспечило для создания и широкого использования систем обработки данных разнообразного назначения....
-
Введение - Технология разработки программного обеспечения систем управления
С++ является языком объектно-ориентированного программирования (ООП). Объект - абстрактная сущность, наделенная характеристиками объектов реального мира....
-
Иерархия параллельных вычислительных систем - Повышение производительности работы библиотеки GridMD
Одной из основополагающих классификаций параллельных систем является Таксономия Флинна , в которой различаются следующие типы систем по взаимодействию...
-
В связи с увеличением числа сотрудников, работающих в компании, а также с расширением рабочего проекта, возникла проблема, связанная с версионностью...
-
Введение - Система поддержки принятия решений
Современные системы поддержки принятия решения (СППР) представляют собой системы, максимально приспособленные к решению задач повседневной управленческой...
-
ВВЕДЕНИЕ - Составление анимации в web-сайте с применением Macromedia Flash-технологии
В последние годы мультимедиа стало образом жизни для многих пользователей, программы и игры сделаны более интересными и впечатляющими. В настоящее время...
-
Введение - Операционные системы
Windows linux unix Операциомнная системма, ОС (англ. operating system) - базовый комплекс компьютерных программ, обеспечивающий управление аппаратными...
-
Основные требования и характеристики современных и применение технических средств АИС Автоматизированная информационная система (АИС) представляет собой...
-
Области применения экспертных систем - Экспертные системы
Области применения систем, основанных на знаниях, могут быть сгруппированы в несколько основных классов: медицинская диагностика, контроль и управление,...
-
Возможность использования формул и функций является одним из важнейших свойств программы обработки электронных таблиц. Это, в частности, позволяет...
-
Кроме поддержки интерпретатора порождающих правил, описанного в главе 5, CLIPS обладает следующими функциональными возможностями: - для определения...
-
Подпрограммы - Язык программирования PERL. Сфера применения
Как и все структурированные языки программирования, Perl поддерживает подпрограммы. Подпрограмма может быть определена с помощью ключевого слова sub, как...
-
Введение - Основные свойства функциональных языков программирования
Созданная в 1998 году спецификация языка Haskell (названного так в честь ученого Хаскелла Карри, одного из основоположников функционального...
-
Межпроцессное взаимодействие - Файловая система Windows 2000
Для общения друг с другом потоки могут использовать широкий спектр возможностей, включая каналы, именованные каналы, почтовые ящики, вызов удаленной...
-
В настоящее время стала очень актуальна проблема разработки, проектирования и создания "умных" зданий. Умные здания помогают более эффективнее и...
-
Введение - Проектирование локальной вычислительной сети
В данном курсовом проекте мы должны спроектировать локально-вычислительную сеть предприятия, которое расположено в двух зданиях. Успех коммерческой и...
-
Введение - Разработка и тестирование автоматизированной системы контроля успеваемости студентов
Тема разработки автоматизированной системы контроля успеваемости и вычисления оценок слабо освещена в научной литературе со стороны вычислительной части...
-
Среди бурно развивающихся систем компьютерной математики СКМ, в первую очередь ориентированных на численные расчеты, особо выделяется матричная...
-
Что такое Flash? Flash (от англ. Flash - "вспышка", произносится "флэш") Flash - это технология веб-мультипликации и создания интерактивного контента от...
-
Введение, Что такое Internet - Глобальная вычислительная сеть Internet
Что такое Internet Internet -- глобальная компьютерная сеть, охватывающая весь мир. Сегодня Internet имеет около 30 миллионов абонентов в более чем 180...
-
Поисковые системы - Глобальная вычислительная сеть Internet
Основная задача Internet -- предоставление необходимой ин-формации. Чтобы найти нужную информацию необходимо знать адрес Web-страницы, на которой эта...
-
Преимущества и недостатки системы Windows - Операционная система Windows
В заключение нужно упомянуть о преимуществах и недостатках системы Windows. К преимуществам Windows относят: - Удобство и поддержка устройств . Основное...
-
Введение, Операционная система Windows - Операционная система Windows
Компьютер сам по себе (Hardware) без разработанных человеком для него программ (Software) не может выполнить какой-либо работы. Программы для компьютера...
-
ВВЕДЕНИЕ - Разработка системы регистрации новых пользователей
В связи с развитием рыночных отношений в России и необходимостью сокращения разрыва в технологическом отставании России от западных стран, актуальным...
-
Российская система здравоохранения: текущее состояние, основные проблемы и барьеры для дальнейшего развития Российское здравоохранение на сегодняшний...
-
Введение, Проект документирования cистемы Linux - Операционная система Linux
В этой книге рассматриваются аспекты системного администрирования операционной системы Linux. В первую очередь данное руководство предназначено для тех,...
-
Введение - Разработка справочной информационной системы "Рецепты"
Задание курсовой работы. Разработать и отладить информационную справочную систему "Рецепты", которая будет позволять хранить, выводить на экран,...
-
Введение - Информационная система "Автосервис"
За последние годы в нашей стране произошли значительные перемены, которые не могли не затронуть области информатики и вычислительной техники. Десять лет...
-
В работе использовались следующее программное обеспечение для решения поставленных задач: AutoCAD, ANSYS Workbench, ANSYS Icepak. Система AutoCAD...
-
Преимущества и недостатки Windows - Операционная система Windows
Преимущества. Удобство и поддержка устройств. Основное отличие программ для DOS и для Windows состоит в том, что DOS-программа может работать с...
-
Общие сведения о базе данных FoxPro 2.6 СУБД FoxPro относится к классу dBase-систем. Эволюция СУБД семейства dBase прослеживается от dBASE к dBASEII...
-
Язык Ассемблера - Компьютерный парк централизованной библиотечной системы
Язык ассеемблера (англ. assemblylanguage) - машино-ориентированный язык низкого уровня с командами, обычно соответствующими командам машины, который...
-
ПО развивается исходя из требований других подсистем. ПО при обработке данных является связующим звеном между комплексом технических средств и другими...
-
Введение - Обьекто-ориентированное программирование
Объектно-ориентированное программирование (ООП) позволяет разложить проблему на составные части, каждая из которых становится самостоятельным объектом....
-
Использование языка PERL для написания CGI-cкриптов - Язык программирования PERL. Сфера применения
Как вы узнали из предыдущей главы, CGI обеспечивает узлам Web вoзмoжнoсть интерактивной работы с клиентскими программами, в качестве которых обычно...
-
У каждого языка программирования есть свои преимущества и недостатки, и их стоит рассматривать в контексте тех принципов, на которых строился язык, а так...
-
Windows Azure Queue: примеры использования, REST - запросы - Введение в облачные решения Microsoft
Примеры использования Рассмотрим условный пример, демонстрирующий логику использования Azure Queue в приложении (рис. 22.1): Рис. 22.1. Поставщики и...
-
Структура SQL - Банки и базы данных. Системы управления базами данных
Широкое развитие информационных систем и связанная с этим унифицированность информационного пространства привело к необходимости создания стандартного...
Введение - Преимущества применения dataflow-парадигмы в вычислительных системах