Тестовые прогоны на модели ОА-архитектуры dataflow-ВС задач бенчмарка GREP - алгоритма сопоставления файловых строк шаблонам команды - Преимущества применения dataflow-парадигмы в вычислительных системах
Ниже представлены результаты моделирования теста Grep на ОА-архитектуре. Моделирование проводилось при следующих параметрах анализируемого текста:
- 1) Число знаков - 18000; 2) Число строк - 1000.
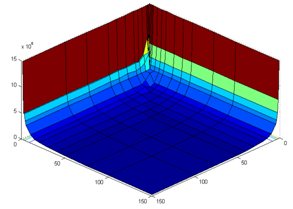
Рисунок 34. Зависимость времени выполнения (T) от числа исполнительных (Rd) и виртуальных устройств (Fu).
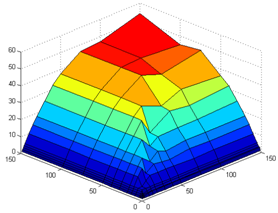
Рисунок 35. Зависимость коэффициента параллелизма P от числа исполнительных (Rd) и виртуальных устройств (Fu).
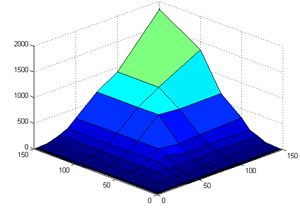
Рисунок 36. Зависимость дисперсии (D) среднего коэффициента параллелизма от числа исполнительных (Rd) и виртуальных устройств (Fu).
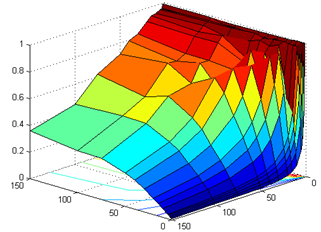
Рисунок 37. Зависимость коэффициента использования оборудования (A) от числа исполнительных (Rd) и виртуальных устройств (Fu).
4.4 Анализ результатов тестовых прогонов на модели ОА-архитектуры dataflow-ВС
Запуск тестовых приложений на модели суперкомпьютера потребовал разработки индивидуальных способов реализации dataflow-архитектуры вычислительного процесса, настроенной на решение той или иной вычислительной задачи. В результате проведенных исследований было показано, что для максимально полного использования преимуществ dataflow-организации вычислений в параллельной суперкомпьютерной системе необходимо очень тщательно подходить к выбору "номенклатуры" (типов), "зернистости" (количества и размеров) и "качества" (функционального наполнения) ФУ архитектуры ВС. Набор ФУ ОА-архитектуры суперкомпьютерной системы может достаточно существенно различаться от задачи к задаче, что выдвигает на первый план задачу разработки эффективных методов адаптации архитектуры ВС к решению задач различной природы и топологии.
По имеющимся результатам тестов можно сделать вывод, что главным критерием эффективности системы является максимальное использование вычислительного оборудования, а также максимальное количество параллельно работающих устройств.
В задачах, для решения которых используются сеточные методы, анализируемая область разбивается на отдельные элементы, информационно связанные со своими "соседями". В этом случае для реализации вычислительной задачи на dataflow-ВС ОА-архитектуры каждый узел сетки оформляется в виде отдельного ВФУ, которое осуществляет вычисления и обменивается данными с помощью милликоманд со своими "соседями". По проведенным тестам, можно сделать вывод, что коэффициент использования аппаратуры зависит от числа "волн" вычислений. Иными словами, чем меньше устройств участвует в вычислении одной и той же "волны", тем ниже коэффициент использования аппаратуры.
В задачах, основанных на операциях с графами большой размерности мы также можем наблюдать незначительный прирост производительности, при повышении числа исполнительных устройств (ядер). Производительность теста в задаче вычисления наибольшего (или наименьшего) пути в графе сильно зависит от параметров задачи (число вершин, число связей между графами, число функциональных устройв и т. п.).
Наиболее высокие результаты тестирования видны в задаче поиска по тексту большого объема. Это объясняется тем, что число "мини-задач", т. е. (число поиска вхождений в одной заданной строке) намного превышает число функциональных устройств. Алгоритм данной задачи построен таким образом, что весь объем текстовых данных (все строки) в самом начале работы программы распределяется между функциональными устройствами, таким образом, у каждого устройства сразу создается очередь задач на выполнение. При таком распределении время "простоя" некоторого устройства без задачи минимально, что является причиной высокой производительности ВС в данной задаче.
Для обеспечения максимально эффективной работы dataflow-ВС (с точки зрения использования доступных вычислительных ресурсов и достижения высокой степени параллелизма вычислений) требуется ее адаптация к решению конкретной вычислительной задачи, что подразумевает (по возможности автоматическую) подстройку ВП, представленного множеством ВФУ, под возможности имеющейся вычислительной среды. Критериями качества адаптации суперкомпьютерной ОА-системы к выполнению той или иной прикладной задачи может служить максимальный коэффициент использования оборудования.
Методы адаптации ОА-системы делятся на два класса:
- - ручные, когда настройка конфигурации ВС и программы осуществляется программистом и инженером перед запуском ВП, включая выбор нужной топологии ВС, распределение сегментов расчетной сетки по вычислительным узлам, подбор оборудования с наиболее оптимальными характеристиками (число процессорных ядер в вычислительном узле, скорость передачи данных коммуникационным оборудованием и т. п.); - автоматические, когда автоматическая корректировка вычислений (набор, количество и качество ВФУ) осуществляется непосредственно во время ВП.
При запуске и тестировании имитационной модели dataflow-ВС ОА-архитектуры варьировались следующие параметры ВС:
- - количество вычислительных узлов в ВС; - способ разбиения вычислительной сетки на сегменты - топология вычислительной сети, объединяющей вычислительные узлы; - скорость передачи данных по линиям связи; - количество ИУ на вычислительном узле; - количество ФУ на вычислительном узле.
При экспериментальных исследованиях критериями эффективности и качества работы ВС служил коэффициент использования оборудования (отношение количества задействованных в вычислениях ИУ к общему количеству ИУ), который должен быть максимальным.
Анализ ручной адаптации вычислительного процесса показал что, для достижения максимальной вычислительной эффективности ОА-системы необходимо соблюдение следующих правил по адаптации ВС к вычислительной задаче:
- 1. Среднее количество виртуальных функциональных устройств, задействованных в вычислениях, должно быть близко к числу ИУ, т. е. ядер системы. При такой конфигурации ВС тратит минимальное время на планирование вычислений, и ей требуется минимальный объем ОП. В том случае, когда NФУ < nиу, коэффициент использования аппаратуры будет равен kиа nфу; и при nфу > neu коэффициент использования kиа близок к единице, однако с дальнейшим увеличением числа функциональных устройств убывает. при nфу = nиу коэффициент использования оборудования kиа достигает своего максимума и примерно равен единице. 2. Пропускная способность канала (каналов) передачи данных должна быть больше поступающего потока данных из вычислительной сетки. В противном случае на ФУ "Шлюз" (ФУ, обеспечивающее передачу данных между вычислительными узлами) будет образовываться очередь из милликоманд, ожидающих передачу на соседний вычислительный узел. Милликоманды, ожидающие отправления, помещаются в буфер Шлюза и ожидают отправления. Зависимость объема буфера передаваемых милликоманд в ситуации, когда пропускная способность канала меньше поступающего из сегмента потока данных, выражается формулой: VMkBuf (VМК *NFUGateway - U)*Nit*Tit, где NFUGateway - число ФУ, передающих данные через Шлюз, VМК - объем памяти, занимаемый одной милликомандой, U - скорость передачи информации по каналу связи, Nit - номер итерации, Tit - время между итерациями (генерациями вычислительных волн). 3. Для задач с использованием сеточных методов средняя скорость прохождения (UCountWave) вычислительной волны должна быть примерно одинаковой во всех вычислительных узлах системы. Скорость прохождения вычислительной волны - это среднее время, за которое вычислительная волна продвигается по сетке на ФУ вперед (рис. 90). В случае, если в сегменте число требуемых для вычисления ФУ меньше или равно числу ИУ в вычислительном узле, данную величину можно вычислить по формуле: UCountWave=(ТWaveEnd - ТWaveStart)/(Lx+Ly), где ТWaveStart и ТWaveEnd - времена начала и конца вычислительной волны в сегменте сетки, Lx и Ly - размерность вычислительной сетки по x и y. В противном случае на данную величину могут влиять следующие факторы: среднее количество задействованных в вычислительной волне ФУ, количество ИУ в вычислительном узле, период генерации вычислительных волн, пропускная способность Шлюзов, осуществляющих передачу сгенерированных в сегменте данных на другие вычислительные узлы, время планировки вычислений (время выделения вычислительного ядра для ФУ). Для выполнения данного требования оператор и инженер, производящий конфигурацию ВС, должны оптимальным образом осуществить разбивку вычислительной сетки на сегменты и их распределение по вычислительным узлам, подобрать коммуникационное и вычислительное оборудование с наиболее подходящими параметрами.
Анализ результатов исследования методов адаптации суперкомпьютерной системы показал эффективность ручных методов адаптации. Также анализ выявил неэффективность автоматического анализа учета трафика (учета номера итерации) передаваемых через ФУ "Шлюз" милликоманд и эффективность учета номера итерации планировшиком (балансиром) во время планирования вычислений (ФУ, принявшее милликоманду с наименьшим номером итерации, помещается в начало очереди ожидания ресурсов) и эффективность метода информирования Шлюзом Топ-менеджера об опасности переполнения буфера передаваемых сообщений. Эффективность последнего способа снижается при увеличении размерности вычислительной сетки.
Dataflow вычислительный алгоритм
Похожие статьи
-
При прогонах тестовой программы, написанной на ПЯ, для алгоритма бенчмарка Graph500, изменялись значения входных параметров, таких как: - N - число ИУ...
-
Все проводимые ниже тесты были проведены для получения характеристик производительности моделируемой системы, описанных в разделе №2. Для каждого теста...
-
Grep - хорошо известная утилита командной строки различных операционных систем. С ее помощью можно производить поиск по тексту строк, соответствующих...
-
Моделирование различных вычислительных систем можно разделить на два главенствующих класса: матечатическое моделировании и имитационное. Математическое...
-
В реалиазации милликомандного типа управления вычислительной системой основную роль играет функциональное устройство "Автомат". Это устройство отвечает...
-
Выбор и обоснование критериев оценки моделируемой системы Основными критериями оценки созданной вычислительной системы с управлением потоком данных по...
-
Данный тест моделирует работу интернет-ресурсов социальных сетей. Социальная сеть представляется в виде графа, где узлы обозначают людей, а ребра - связи...
-
Ядром вычислительной dataflow-системы будем называть совокупность оборудования, которое осуществляет сбор данных для формирования исполняемого пакета. В...
-
В предыдущем разделе был приведен необходимый для получения набор выходных характеристик моделируемой вычислительной системы, требуемый от тестирования....
-
ОА-архитектура - Преимущества применения dataflow-парадигмы в вычислительных системах
В данной работе предлагается использование объектно-атрибутной архитектуры ВС (или ОА-архитектуры). В отличие от классической ВС, ОА-архитектура работает...
-
Введение - Преимущества применения dataflow-парадигмы в вычислительных системах
Dataflow-парадигма В архитектурах вычислительных сетей на сегодняшний день преобладающую роль играют ВС, управляемые потоком команд - Control Flow. Такая...
-
Оценка моделируемой ВС осуществляется на основе анализа функционирования ВС на тестовых задачах по следующему набору параметров: - общее число ИУ в ВС; -...
-
Для проверки соответствия требованиям ТЗ, была поставлена задача разработки 3-D модели корпуса Kyocera KD-PB1D79 при помощи системы AutoCAD. В этой части...
-
Формы и характеристики параллелизма Параллелизм -- это возможность одновременного выполнения нескольких арифметико-логических или служебных операций. На...
-
Аннотация В статье рассматриваются два способа уменьшения времени вычисления дерева решений для задач линейного параметрического программирования с...
-
При создании или при классификации информационных систем неизбежно возникают проблемы, связанные с формальным - математическим и алгоритмическим...
-
Построение аналитической модели АОУ затруднено из-за отсутствия или недостатка априорной информации об объекте управления, а также из-за ограниченности и...
-
Для того, чтобы разработать оптимальный метод интеграции сторонних систем в существующую ИТ-инфраструктуру систем компании, требуется точно поставить...
-
Для третьего способа мне понадобился способ под названием "Стемминг". Данное понятие очень популярно во всемирной паутине, так как оно применяется в...
-
Распределение задач между процессами - Администрирование параллельных процессов
Распределение подзадач между процессорами является завершающим этапом разработки параллельного метода. Надо отметить, что управление распределением...
-
Расчет надежности системы, Завершенность - Моделирование беспроводных сенсорных сетей
Для разрабатываемого программного обеспечения необходимо определение следующих свойств: - завершенность; - устойчивость; - восстанавливаемость; -...
-
Введение, Постановка задачи - Моделирование беспроводных сенсорных сетей
Данная квалификационная работа посвящена моделированию беспроводных сенсорных сетей (БСС) на базе современных маломощных модулей. Рассматриваются...
-
Алгоритм LZ78 - Анализ алгоритма Лемпеля-Зива
Этот алгоритм генерирует на основе входных данных словарь фрагментов, внося туда фрагменты данных (последовательности байт) по определенным правилам (см....
-
Назначение вычислительного кластера - Администрирование параллельных процессов
Кластеры используются в вычислительных целях, в частности в научных исследованиях. Для вычислительных кластеров существенными показателями являются...
-
Программная модель данных, получившая название "MapReduce", была создана несколько лет назад в компании Google, и там же была осуществлена первая...
-
Постановка задачи Необходимо разработать программу для поиска автобусных маршрутов. В качестве среды разработки должна использоваться Delphi 7. В...
-
Постановка задачи Основной целью дипломной работы является создание комплексной системы информационной безопасности предприятия на примере информационной...
-
У цей час існують різні системи керування запасами, кожна з яких характеризується певними особливостями планування запасів. Розглянемо основні з даних...
-
Модель вычислительного процесса в GridMD - Повышение производительности работы библиотеки GridMD
Узлы графа исполнения, используемого в GridMD, представляют собой конкретные этапы исполнения, с которыми связываются действия, определяемые программным...
-
Требования к программному обеспечению системы На сетевом оборудовании должна функционировать межсетевая операционная система, причем ее версия должна...
-
Требования к системе в целом Требования к структуре и функционированию ЛВС .1 ЛВС должна состоять из следующих функциональных подсистем: Подсистема...
-
Устойчивость элементов и устройств к внешним воздействиям. Характеристики климатических воздействий. Механическая прочность. Радиационная стойкость...
-
Функционально-структурная организация персонального компьютера. Персональные компьютеры используют в домашних условиях. Их основное назначение:...
-
Шестой метод - построение суффиксных деревьев. Среди большого количества методов анализа текста метод аннотированного суффиксного дерева выделяется тем,...
-
Теоретические аспекты поставленной задачи В этой части проекта будут объяснены этапы применения МКЭ для плоской фермы. В первой главе было рассмотрено...
-
Цель Работы - изучить приемы создания и использования шаблонов классов. - Теоретические сведения Достаточно часто встречаются классы, объекты которых...
-
Цель Работы - изучить основные способы работы с пользовательским типом данных "класс", его объектами, методами и способы доступа к ним. - Теоретические...
-
Заключение - Сравнение моделей представления слов в задаче очистки текста от обесцененной лексики
В данной работе проводится сравнение эффективности 6 методов поиска по однословному запросу. В качестве запроса выступает слов из стоп-листа - списка...
-
Программный алгоритм визуальный гаусс В программу включены следующие процедуры: "gauss1", "gaussj", "New1Click", "Button1Click", "Button2Click",...
-
Математическое обеспечение позволяет использовать методы автоматизированного поиска оптимальных вариантов при проектировании системы. Часто при решении...
Тестовые прогоны на модели ОА-архитектуры dataflow-ВС задач бенчмарка GREP - алгоритма сопоставления файловых строк шаблонам команды - Преимущества применения dataflow-парадигмы в вычислительных системах