Общее представление задачи интеграции, Методы интеграции данных - Метод интеграции сторонних систем анализа и обработки данных в существующую ИС-архитектуру компании
Для того, чтобы разработать оптимальный метод интеграции сторонних систем в существующую ИТ-инфраструктуру систем компании, требуется точно поставить задачу интеграции.
Потребность:
Необходимо интегрировать N информационных систем, характеризуемых факторами (см. п. 1.2). Количество прослоек, конвертеров, брокеров и интерфейсов между ними должно быть минимальным.


Пусть количество связей между N ИС равно X. Тогда. Следовательно, при двухстороннем взаимодействии интерфейсов. Под интерфейсом можно понимать как веб-сервис, так и любой процесс, запускаемый в определенное время.
Методы интеграции данных
Задачи интеграции возникают в случае внедрения в компанию новых ИС или добавления в существующие системы новой функциональности. При интеграции информационных систем производится интеграция именно данных, и только потом техническая реализация канала, способа, формата передачи данных. В связи с этим, основной проблемой, возникающей при интеграции, является проблема, связанная с качеством данных [4].
Интеграция данных на синтаксическом уровне
Особенно ситуация становится актуальной в случае интеграции базы знаний о клиентах (Customer Data Integration, CDI) при объединении компании (слиянии и поглощении, M&;A). Для этого требуется консолидация хранилищ имен, адресов, истории клиентов и др. При отсутствии единого метода интеграции данных существует риск получить в результате несогласованные данные в приемнике с дублированными или конфликтующими атрибутами клиентов.
В данном случае компания может воспользоваться системами управления мастер-данными (Master Data Management, MDM). В отсутствие единой MDM-системы в компании задачи согласования данных и обеспечения их качества ложатся на процессы интеграции. Для этого разрабатываются бизнес-правила преобразования данных, создаются таблицы соответствия и т. п. решения, что по сути своей представляет систему MDM для одного или группы интеграционных процессов [4].
Большинство современных промышленных СУБД имеют встроенные средства реплицирования данных несколькими способами. Однако, если требуется организовать информационный обмен между системами, реализованными на разных платформах, использование таких средств становится практически невозможным, так как не все СУБД поддерживают данную функциональность.
Одной из основных проблем, стоящих перед разработчиками многих современных ИС, является постоянное изменение требований и условий деятельности учреждений, объединенных использованием единой ИС. Изменения должны оперативно вноситься в функционирующие компоненты по возможности без переписывания программного кода. Поэтому разрабатываемые компоненты тиражирования должны учитывать возможность модификации модели предметной области (БД, пользовательского интерфейса, шаблонов отчетов и бизнес-процессов, в частности, появление новых операций и пр.). Реализация таких функций обеспечивает расширяемость, адаптируемость ИС к новым условиям [7].
Многие системы тиражирования основаны на синхронной схеме реплицирования, при которой узел-поставщик данных отслеживает результат фиксации отправленных данных на узле-приемнике. Отличительной особенностью предлагаемого подхода к тиражированию является отсутствие требования постоянного оперативного (on-line) соединения между узлами. Это может оказаться необходимым в условиях ненадежных каналов связи и позволяет передавать пакет тиражирования любым удобным способом (на носителе, по электронной почте и т. д.). Возможность тиражирования данных ИС в асинхронном режиме - одна из основных задач [7].
Одним из распространенных методов интеграции данных является схема интеграции, основанная на классификации технологий интеграции данных из шести уровней, которую предложил исследователь из Цюрихского университета Клаус Диттрих (см. рисунок 1).
Шесть уровней интеграции по Клаусу Дитриху [21]:
Ѕ Common Data Storage (Общие системы хранения). Осуществляется за счет слияния данных из разных систем хранения данных в одну общую. Сегодня мы бы объединили эти два уровня в один и назвали бы его виртуализацией систем хранения.
Ѕ Uniform Data Access (Унифицированный доступ к данным). На этом уровне осуществляется логическая интеграция данных, различные приложения получают единообразное видение физически распределенных данных. Такая виртуализация данных имеет свои несомненные достоинства, но гомогенизация данных в процессе работы с ними требует значительных ресурсов.
Ѕ Integration by Middleware (Интеграция средствами ПО промежуточного слоя). ПО этого слоя играет посредническую роль, его составляющие способны к выполнению отдельных предписанных им функций, в полном объеме интеграционная задача решается во взаимодействии с приложениями.
Ѕ Integration by Applications (Интеграция средствами приложений). Обеспечивает доступ к разным источникам данных и возвращает пользователю обобщенные результаты. Сложность интеграции на этом уровне объясняется большим разнообразием интерфейсов и форматов данных.
Ѕ Common User Interface (Общий пользовательский интерфейс). Дает возможность единообразного доступа к данным, например, с помощью браузера, но при этом данные остаются неинтегрированными и неоднородными.
Ѕ Manual Integration (Интеграция вручную). Пользователь сам объединяет данные, применяя различные типы интерфейсов и языки запросов.
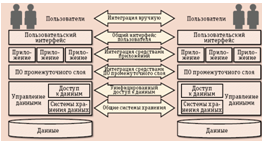
Рисунок 1. Классификация методов интеграции данных по Клаусу Дитриху
Схема Диттриха позволяет связать вместе интеграцию данных с интеграцией информации - по мере продвижения снизу вверх простые атомарные данные обретают семантику, становятся доступными пониманию и превращаются в полезную информацию, представленную в удобной форме [21].
Интеграция данных на семантическом уровне
Относительно новым подходом К интеграции данных является семантический подход. В отличие от синтаксического подхода он основывается не на внешнем сходстве объединяемых данных, а на содержательной компоненте.
В источнике [10] авторы рассматривают так называемые ODBA (Ontology-Based Data Access Systems) системы. Сравнивают различные подходы к построению систем: реляционный, объектный, логический, дескриптивные логики, онтологии. Рассматривается ряд систем: QuOnto, ROWLkit, QToolKit, DIG Server wrapper, MASTRO. Все эти системы используют онтологии. Онтология используется в качестве концептуальной схемы для интеграции данных из гетерогенных источников. Все перечисленные системы основаны на LD-Lite логике, имеют графический интерфейс и могут подключаться к большому числу баз данных.
В источнике [19] решается задача каталогизации и интеграции разнородных источников данных. Также предлагается метод, основанный на онтологиях. Рассматриваются проблемы интеграции данных. Ставится задача, не внося изменений в существующие источники данных, предоставить к ним доступ по принципу "единого окна", а также предоставить возможность "семантической окраски" данных для дальнейшей машинной обработки. Авторы предлагают использовать дескрипционные логики для описания семантики источников и онтологии как инструмент представления обобщенных спецификаций. Авторы предлагают медиаторную архитектуру системы для решения данных задач. Центральное место занимает онтология-классификатор для описания предметных областей на высоком уровне. Кроме того, создаются расширяющие онтологии-отображения, которые отображают классы и свойства на реальную структуру источника.
В [13] рассматривается возможность применения онтологий для интеграции данных АСУ предприятия. Решается задача интеграции онтологий, извлеченных из источников данных. Для этого используется базовая онтологическая модель промышленного предприятия, которая позволяет осуществить глубокую интеграцию разнородных данных и избежать лексических и семантических конфликтов, а также специальный алгоритм определения семантической близости понятий.
В источнике [33] авторы ставят задачу интеграции данных из гетерогенных источников. Как и в некоторых рассмотренных ранее системах предлагается медиаторный подход к проектированию системы. Центрально место в системе (медиатор) занимает онтология SEMANCO. При помощи этой онтологии интегрируется техническая и статистическая информация о зданиях, которая располагается в структурированных гетерогенных источниках.
В статье [26] описывается подход для доступа к гетерогенным источникам, описанным при помощи xml. Онтология играет роль интерфейса между конечными пользователями и xml-источниками, предоставляет гомогенное семантическое представление xml описаний данных, чтобы поддержать формулирование запросов на семантическом уровне, не заботясь о структуре и синтаксисе каждого описания. Онтология определяет и поддерживает проекции между онтологическими схемами и данными в источниках. Свои идеи авторы воплотили в системе VISPO. Онтология организована в 3 уровня: уровень семантического проецирования, промежуточный уровень, категоризирующий уровень.
В [32] глобальная онтология определяет все термины и понятия онтологии домена, кроме того, на дополнена связями с глобальными репозиториями онтологий, которые содержат разработанные и специфицированные предметные онтологии, каждая из которых описывает контент всех источников данных из домена. Система, предлагаемая авторами, предполагает агентный подход. Есть агент для построения запроса, проецирующий агент, который сопоставляет запрос и предметную онтологию, далее транспортный агент перемещается на источник и получает данные.
Примеры продуктов рынка ПО для реализации семантической интеграции
Компания Progress Software выпустила семантический интегратор DataXtend Semantic Integrator. Progress. Он предоставляет единую модель данных, делающую возможной семантическую интеграцию данных различных информационных структур [25]. DataXtend позволяет сохранять бизнес-целостность данных при коллизиях между системой-источником и системой-приемника. Коллизии могут быть выражены в несхожести представлений систем о структуре данных. Использование решения семантической интеграции данных DataXtend позволяет предприятию ограничиться для приложений только слабо связанными интерфейсами и обеспечивает слабую связанность на семантическом уровне [33].
Семантический сервер компании "Алтимета" позволяет в реальном времени превратить разрозненные данные организации в полноценную бизнес-информацию, пригодную для принятия эффективных решений. Семантический сервер обеспечивает интеграцию приложений с использованием архитектуры SOA и подходов интеграционных процессов - BPEL, BPMN [25]. Семантический сервер применяет семантические стандарты к SOA-архитектуре и позволяет:
Ѕ консолидировать не только справочники и классификаторы, а вообще всю информацию, которую необходимо совместно использовать интегрируемым системам;
Ѕ объединить, интегрировать информацию и гарантировать качество данных;
Ѕ обеспечить получение информации из слабоструктурированных источников;
Ѕ производить автоматическую классификацию данных и логический вывод.
Похожие статьи
-
Известно, что создание систем "с нуля" приводит к глобальным затратам компании на фонд оплаты труда, на поддержание созданного решения. К тому же, чем...
-
Информационная система крупной организации, как правило, представляет собой исторически сложившуюся совокупность отдельно работающих систем, которые...
-
По результатам данного исследования необходимо выявить недостатки и ограничения существующих технологий интеграции. Для проведения исследования...
-
В данной главе представлено описание возможных вариантов совершенствования архитектуры предприятия в части гибкого подключения сторонних систем и их...
-
Корпоративная интеграционная подсистема на базе IBM WebSphere Business Integration Message Broker [28] отвечает за выстраивание корпоративной...
-
Прогнозируемая оценка проекта после реализации единой шины данных как прослойки между всеми компонентами ИТ-ландшафта компании выполняется по методу...
-
Построение модели предметной области с помощью описания структур данных и программного кода является классическим подходом в разработке ИС. Зачастую...
-
SPSS Modeler [29] - это программный комплекс, позволяющий строить прогностические модели и применять эту информацию при принятии решений на уровне...
-
Эффективность работы бизнеса напрямую зависит от эффективности работы ИТ. При внедрении новых проектов, связанных с развитием бизнеса, происходит...
-
В данном пункте представлено описание подключаемых к общей архитектуре ИС компании систем. Описание систем является справочной информацией для...
-
Как известно , необходимость интеграции нескольких информационных систем как внутри одной организации (системы являются подсистемами к историчной...
-
Текущая инфраструктура компании совершенствуется, всегда появляются новые системны для подключения и внедрения. Инфраструктура построена на схеме...
-
Специалисты Gartner предполагали, что к 2006 году более 60% компании будут внедрять сервис-ориентированную архитектуру (Service-Oriented Architecture -...
-
В данном пункте представлено описание подключенных систем к общей инфраструктуре ИС компании. В случае IBM SPSS: Вследствие того, что сбор данных с...
-
В данной главе приведена характеристика текущей архитектуры информационных систем компании. Описаны основные компоненты архитектуры. Приведено...
-
Предложенный подход к решению задач исследования Используя в качестве основы присутствующее в наличии программное обеспечение, которое применимо к...
-
Теоретические предпосылки исследования Системы поддержки принятия решений Системы поддержки принятия решений (СППР), представляют собой приложения узкого...
-
Онлайн исследования в социологии: новые методы анализа данных - Распространение новостной информации
На сегодняшний день анализ социальных сетей и медиа, Интернет-сообществ, пользователей в целом используется в основном в маркетинге. Компания может...
-
Определение методов реинжиниринга информационных систем Основные задачи, которые стоят перед проектировщиком, занимающимся реинжинирингом информационных...
-
Задачей проекта По внедрению Campaign Management является автоматизация полного цикла проведения кампаний, включая: Ѕ сегментацию и отбор Клиентов; Ѕ...
-
Задача поведенческой сегментации, формирование портретов клиентов по поведению Одними из основных задач анализа являлись: поведенческая сегментация...
-
Заключение - Интеллектуальный анализ данных, который способствует поддержке маркетинга в компании
В рамках проведенного исследования была проделана работа по разработке системы интеллектуального анализа данных для поддержки маркетинга производственной...
-
Способы обработки данных - Автоматизированные системы обработки экономической информации
Различаются следующие способы обработки данных: централизованная, децентрализованная, распределенная и интегрированная. Централизованная предполагает...
-
Необходимость защиты информации от внутренних угроз была очевидна на всех этапах развития средств информационной безопасности. Однако первоначально...
-
Объектно-ориентированные СУБД Несмотря на большую популярность реляционных СУБД, развитие технологии появления данными на них не остановилось. Развитие...
-
Концептуализации - Экспертные системы, методика построения
На данном этапе проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач....
-
Объектом исследования является производственная компания ООО "Элементари" (ELEMENTAREE) (http://www. elementaree. ru/). Исследования, отображаемые в...
-
Для достижения цели, поставленной в данной работе, необходимо проанализировать текущую ситуацию в области информационных систем, сравнить информационные...
-
Полное наименование разрабатываемой системы - корпоративная информационная система "Бюджетное планирование и отчетность" группы компаний, занимающейся...
-
При создании или при классификации информационных систем неизбежно возникают проблемы, связанные с формальным - математическим и алгоритмическим...
-
После того, как был реализован процесс карьерного планирования в информационной системе, можно сделать выводы о том, что внедрение информационной системы...
-
Информационная система Lumesse ETWeb является системой, которая автоматизирует весь комплекс процессов управления персоналом. Важно отметить, что данная...
-
Постановление Правительства Российской Федерации №1119 "Об утверждении требований к защите персональных данных при их обработке в информационных системах...
-
Решения компании IBM - Технологии больших данных: анализ и выбор решения для реализации проекта
Технологии анализа больших данных являются прекрасным дополнением к средам хранения больших данных. Множество применений включает в себя, например,...
-
Описание исходных данных На текущий момент (в силу большой загрузки IT-отдела) не реализован доступ к серверу с ХД, маркетинговые данные выгружаются в...
-
В работе использовались следующее программное обеспечение для решения поставленных задач: AutoCAD, ANSYS Workbench, ANSYS Icepak. Система AutoCAD...
-
Прогнозирование оттока клиентов Отделом маркетинга компании ELEMENTAREE было выявлено, что практически все клиенты, у которых отсутствовали заказы в...
-
Введение - Интеллектуальный анализ данных, который способствует поддержке маркетинга в компании
В связи возникших условий экономического кризиса наблюдается рост издержек маркетинговой деятельности. Отдел маркетинга компании "ELEMENTAREE" испытывает...
-
Методы и средства проектирования - Автоматизированные системы обработки экономической информации
Проектирование - процесс создания проекта-прототипа, прообраза предполагаемого или возможного объекта, его состояния. Современная технология создания АИС...
-
Шестой метод - построение суффиксных деревьев. Среди большого количества методов анализа текста метод аннотированного суффиксного дерева выделяется тем,...
Общее представление задачи интеграции, Методы интеграции данных - Метод интеграции сторонних систем анализа и обработки данных в существующую ИС-архитектуру компании