Метод аннотированного суффиксного дерева - Сравнение моделей представления слов в задаче очистки текста от обесцененной лексики
Шестой метод - построение суффиксных деревьев.
Среди большого количества методов анализа текста метод аннотированного суффиксного дерева выделяется тем, что он представляет текст не как последовательность слов, а как последовательность символов. Благодаря этому достигается практически полная независимость от языка анализируемых текстов. В основе данного метода лежит построение аннотированного суффиксного дерева(далее - АСД), с помощью которого можно определить степень вхождения исходных (данных) слов или словосочетаний в анализируемый текст. В моем исследовании использовалась эффективная и быстрая реализация АСД на основе суффиксных массивов [7]. В публикации [7] предлагает построение АСД, как корневого дерева, где все узлы, кроме корня помечены каким-либо символом из алфавита, на котором определена коллекция строк. В моем случае АСД кодирует все суффиксы всех строк, которые представлены в стоп-листе. Каждому узлу соответствует число, которое обозначает сколько раз данный фрагмент вошел в набор текстов. Пример данного дерева можно увидеть на рис. 1.

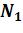
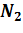
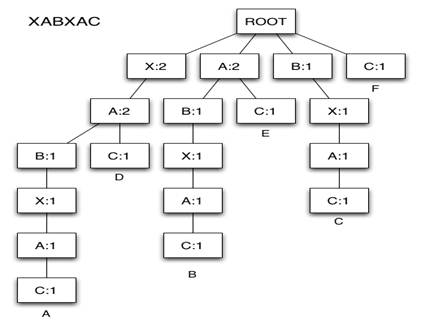
Рис. 5.2
5. Полученные результаты
В качестве полученных результатов будет предложена таблица с количеством нецензурных слов, полученных после использования методов, которые были описаны выше. Для того, чтобы узнать, насколько они хорошо работают, была проведена ручная проверка каждой статьи на наличие ненормативной лексики, что являлось эталонным результатом с которым были сравнены все автоматические методы. В таблице ниже приведены результаты.
Табл. 6.1.
|
Номер статьи |
В ручную |
Деревья |
Стеммер |
Лемматизация |
Поиск по совпадению |
Левенштейн |
Жаккар |
|
1 |
5 |
3 |
5 |
3 |
1 |
5 |
5 |
|
2 |
88 |
69 |
13 |
3 |
23 |
23 | |
|
3 |
30 |
29 |
4 |
3 |
3 |
8 |
7 |
|
4 |
2 |
2 |
2 |
2 |
2 |
2 |
2 |
|
5 |
8 |
7 |
6 |
8 |
1 |
7 |
7 |
|
6 |
6 |
6 |
0 |
3 |
2 |
3 |
4 |
|
7 |
13 |
11 |
4 |
8 |
5 |
8 |
10 |
|
8 |
38 |
30 |
7 |
11 |
7 |
20 |
30 |
|
9 |
15 |
6 |
8 |
8 |
7 |
14 |
14 |
|
10 |
8 |
4 |
4 |
3 |
2 |
5 |
5 |
|
11 |
5 |
1 |
1 |
3 |
0 |
4 |
4 |
|
12 |
10 |
8 |
4 |
4 |
4 |
8 |
9 |
|
13 |
10 |
4 |
4 |
3 |
3 |
5 |
5 |
|
14 |
2 |
2 |
2 |
0 |
0 |
2 |
2 |
|
15 |
25 |
23 |
18 |
18 |
4 |
18 |
21 |
|
16 |
21 |
11 |
11 |
12 |
9 |
18 |
18 |
|
17 |
14 |
5 |
6 |
6 |
10 |
11 |
13 |
|
18 |
53 |
33 |
9 |
9 |
7 |
21 |
33 |
|
19 |
6 |
5 |
3 |
2 |
1 |
3 |
4 |
|
20 |
26 |
17 |
9 |
8 |
7 |
12 |
17 |
|
21 |
18 |
15 |
6 |
5 |
4 |
7 |
8 |
|
22 |
6 |
5 |
1 |
2 |
0 |
1 |
2 |
|
23 |
10 |
8 |
2 |
5 |
4 |
7 |
7 |
|
24 |
11 |
8 |
7 |
7 |
3 |
8 |
7 |
|
25 |
14 |
10 |
2 |
2 |
2 |
2 |
2 |
|
26 |
8 |
7 |
3 |
3 |
1 |
7 |
7 |
|
27 |
5 |
3 |
2 |
2 |
1 |
4 |
3 |
|
28 |
5 |
4 |
1 |
0 |
2 |
3 |
3 |
|
29 |
12 |
7 |
4 |
5 |
2 |
5 |
8 |
|
30 |
7 |
6 |
2 |
2 |
1 |
3 |
3 |
|
31 |
18 |
15 |
9 |
9 |
5 |
15 | |
|
32 |
17 |
12 |
11 |
4 |
3 |
14 | |
|
33 |
6 |
4 |
3 |
1 |
1 |
4 | |
|
34 |
13 |
11 |
9 |
8 |
5 |
12 | |
|
35 |
9 |
4 |
7 |
5 |
4 |
7 | |
|
36 |
18 |
14 |
6 |
4 |
2 |
11 | |
|
37 |
10 |
8 |
6 |
3 |
1 |
8 | |
|
38 |
7 |
7 |
6 |
2 |
0 |
5 | |
|
39 |
9 |
7 |
3 |
3 |
2 |
7 | |
|
40 |
25 |
12 |
3 |
4 |
1 |
5 | |
|
41 |
10 |
7 |
4 |
4 |
1 |
7 | |
|
42 |
19 |
16 |
7 |
8 |
4 |
12 | |
|
43 |
20 |
12 |
2 |
3 |
1 |
12 | |
|
44 |
23 |
17 |
10 |
7 |
9 |
14 | |
|
45 |
10 |
10 |
5 |
1 |
2 |
8 | |
|
46 |
12 |
10 |
6 |
3 |
2 |
10 | |
|
47 |
15 |
12 |
8 |
4 |
4 |
10 | |
|
48 |
9 |
8 |
4 |
4 |
2 |
9 | |
|
49 |
15 |
10 |
7 |
7 |
3 |
11 | |
|
50 |
23 |
15 |
10 |
4 |
8 |
12 | |
|
51 |
13 |
10 |
5 |
1 |
4 |
9 | |
|
52 |
15 |
11 |
9 |
6 |
3 |
13 | |
|
53 |
30 |
21 |
15 |
16 |
9 |
24 | |
|
54 |
14 |
12 |
5 |
6 |
3 |
10 | |
|
55 |
13 |
11 |
8 |
10 |
5 |
11 | |
|
56 |
6 |
5 |
2 |
2 |
1 |
6 | |
|
57 |
8 |
7 |
5 |
4 |
4 |
7 | |
|
58 |
9 |
9 |
2 |
6 |
2 |
7 | |
|
59 |
6 |
6 |
2 |
2 |
1 |
4 | |
|
60 |
5 |
4 |
3 |
4 |
1 |
4 | |
|
61 |
2 |
2 |
1 |
1 |
1 |
1 | |
|
62 |
6 |
3 |
2 |
2 |
0 |
2 | |
|
63 |
10 |
8 |
2 |
1 |
1 |
5 | |
|
64 |
9 |
5 |
4 |
3 |
3 |
4 | |
|
65 |
5 |
4 |
3 |
2 |
1 |
4 | |
|
66 |
7 |
5 |
3 |
3 |
3 |
6 | |
|
67 |
6 |
5 |
3 |
0 |
2 |
4 | |
|
68 |
6 |
4 |
3 |
2 |
1 |
4 | |
|
69 |
5 |
3 |
4 |
2 |
0 |
5 | |
|
70 |
6 |
5 |
4 |
2 |
1 |
6 | |
|
71 |
6 |
6 |
4 |
4 |
3 |
5 | |
|
72 |
6 |
4 |
2 |
3 |
1 |
5 | |
|
73 |
8 |
8 |
6 |
3 |
3 |
7 | |
|
74 |
3 |
2 |
1 |
1 |
0 |
2 | |
|
75 |
2 |
2 |
1 |
1 |
0 |
2 | |
|
76 |
6 |
5 |
3 |
2 |
2 |
4 | |
|
77 |
7 |
7 |
6 |
2 |
2 |
7 | |
|
78 |
1 |
1 |
0 |
0 |
1 |
1 | |
|
79 |
1 |
1 |
1 |
1 |
1 |
1 | |
|
80 |
1 |
1 |
1 |
0 |
0 |
1 | |
|
81 |
3 |
1 |
1 |
1 |
0 |
1 | |
|
82 |
9 |
8 |
3 |
3 |
2 |
8 | |
|
83 |
8 |
6 |
3 |
2 |
1 |
5 | |
|
84 |
1 |
1 |
1 |
1 |
0 |
1 | |
|
85 |
1 |
1 |
0 |
0 |
0 |
1 | |
|
86 |
8 |
6 |
1 |
2 |
1 |
2 | |
|
87 |
6 |
4 |
2 |
1 |
0 |
4 | |
|
88 |
5 |
5 |
3 |
3 |
0 |
4 | |
|
89 |
2 |
2 |
1 |
0 |
0 |
2 | |
|
90 |
23 |
20 |
21 |
5 |
1 |
13 | |
|
91 |
7 |
4 |
2 |
2 |
0 |
5 | |
|
92 |
10 |
8 |
3 |
6 |
4 |
7 | |
|
93 |
12 |
10 |
5 |
4 |
2 |
8 | |
|
94 |
3 |
3 |
1 |
1 |
2 |
2 | |
|
95 |
6 |
4 |
3 |
3 |
2 |
6 | |
|
96 |
6 |
3 |
1 |
2 |
2 |
6 | |
|
97 |
2 |
1 |
2 |
1 |
1 |
2 | |
|
98 |
4 |
3 |
2 |
0 |
0 |
2 | |
|
99 |
5 |
5 |
3 |
1 |
0 |
3 | |
|
100 |
8 |
6 |
4 |
5 |
1 |
4 | |
|
Общие рез-ты |
1120 |
838 |
448 |
370 |
236 |
733 |
Как видно из полученной таблицы, самым эффективным способом оказался способ АСД. Но у него есть существенный недостаток, который можно увидеть в приложении к данной работе. Данный метод выдает очень большое количество, так называемого "мусора", то есть слов, которые на самом деле не являются обесцененной лексикой. Но также у данного метода есть существенное преимущество над его ближайшим соседом (теоретико-множественная мера Жаккара), данный метод работает быстрее, чем его преследователь. Остальные методы работают очень точно, но и при этом очень не полно. Также следует отметить, что худшим методом, с точки зрения полноты оказался простой поиск по совпадению. Но у него также имеются преимущества. Например, очень существенным плюсом данного метода является то, что его точность максимальна, то есть, если он выдает слово, то оно обязательно входит в стоп-лист, то есть является обесцененной лексикой. Нельзя обойти стороной тот факт, что при применении метода "Расстояние Левенштейна" было проверено лишь треть коллекции данных. Это было сделано из-за того, что данный метод работает очень долго. На основе проверенных статей можно сделать вывод, что его полнота близка к полноте метода "теоретико-множественная мера Жаккара", но при этом, как было сказано ранее, данный метод слишком медлителен, экспериментально был сделан вывод о том, что данный метод не является лучшим.
В данном исследовании главным фактором сравнения методов будет являться полнота[5]. Введем формальное определение полноты. В данном исследование полнота - это количество нецензурных слов из статей, которые были найдены в ручную. Полнота всех методов рассчитывалась по формуле:
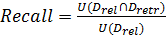
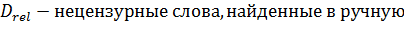
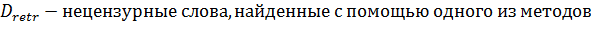
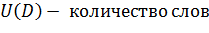
Также введем формальное определение точности методов. Точность - это количество слов, из тех, которые найдены, действительно являются нецензурными. Точность можно рассчитать по формуле:
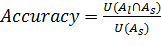
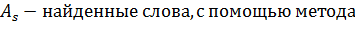
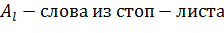
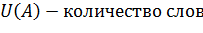
Необходимо найти все нецензурные слова в тексте, иначе очистка от нецензурной лексики не будет иметь смысла. Точность при этом менее важна: не так страшно, что несколько слов ошибочно будут признаны нецензурными. Пропустить же нецензурное слово гораздо хуже. Таким образом, главным критерием оптимизации в данной работе является полнота. Точность важна, но не настолько сильно. Приведем пример: первый способ работает очень точно, но при этом он выдает далеко не всю, а если быть откровенным, то максимум 50% от того, что на самом деле содержит статья. При этом в моем исследовании есть 4 достаточно полных метода.
Другим немаловажным критерием для сравнения методов является время работы. Допустим, что разрабатывается некий онлайн-сервис для очистки текстов от нецензурной лексики. Его эффективность и польза от него получаемая напрямую зависит от скорости его работы. Два из рассмотренных методов, теоретико-множественная мера Жаккара и стемминг, работают быстро, а один, расстояние Левенштейна, хоть он и полный, но времени затрачивает очень много. В результате этих суждений нужно можно сделать вывод о том, что самым эффективным и при этом, что не мало важно, самым быстрым методом оказался метод АСД.
6. Программная реализация
Все методы за исключением одного (метода АСД) реализованные в данной работе были написаны с помощью языка программирования Python 3.4.3. Этот язык был выбран вследствие того, что он является одним из самых удобных при обработке или работе с текстовыми файлами. Также одним из критериев выбора данной платформы было то, что в ней реализованы библиотеки, которые были необходимы для выполнения данного исследования. Приведем пример схемы работы программы, реализованной для простого поиска по совпадению. На вход подается стоп-лист и статья, в которой должна быть найдена ненормативная лексика. Далее нужно сравнить каждое слово из статьи с каждым словом из стоп-листа, если они при этом совпадают, отметить совпадающее слово в статье определенными тегами, чтобы зафиксировать его "ненормативность". Лемматизация и Стеммер работают по тому же принципу, за исключением того, что на начальном этапе статья подвергается форматированию, с использование стандартной библиотеки Python 3.4.3 (pymystem3) в случае метода лемматизации и с использованием библиотеки, созданной моим научным руководителем, в случае стемминга. Также, стоит отметить то, что в случае стемминга необходимо "отстеммить" стоп-лист, чтобы сравнение слов из статьи и стоп-листа происходило правильно. В случае лемматизации в этом нет необходимости, так как слова в стоп-листе написаны в своей словарной форме. Способ "расстояние Левенштейна" и "теоретико-множественная мера Жаккара" также использовали сравнение каждого слова из статьи с каждым словом из стоп-листа, но после сравнения применялись формулы и действия, которые описаны выше, чтобы определить подходит слово под определение нецензурной лексики или нет.
Единственный метод, который реализовывался с помощью языка программирования Python 2.7.9 - это метод АСД. Это делалось из-за того, что библиотека, которая понадобилась для реализации данного метода (east. asts), была реализована только для этой версии. Данная библиотека была применена к каждому слову из стоп-листа, то есть определенным образом каждое слово было разбито на суффиксы (см. рис.5.2) Далее считался результат опять же с использованием данной библиотеки и если этот результат был выше определенного порога, в моем случае это 10% (такой маленький процент брался специально для полноты метода) слово отбиралось для дальнейшего анализа.
Все способы сравнивались с самым точным и полным методом, который позволил сделать все выводы, описанные выше. Название этого способа "в ручную". Название говорит само за себя, то есть все статьи были проверены самостоятельно мной на наличие обесцененной лексики.
Похожие статьи
-
Для третьего способа мне понадобился способ под названием "Стемминг". Данное понятие очень популярно во всемирной паутине, так как оно применяется в...
-
Первый способ нахождения обесцененной лексики в текстах является самым простым. Данный способ - это простой поиск по совпадению, то есть мы берем слово...
-
Заключение - Сравнение моделей представления слов в задаче очистки текста от обесцененной лексики
В данной работе проводится сравнение эффективности 6 методов поиска по однословному запросу. В качестве запроса выступает слов из стоп-листа - списка...
-
Пятый способ - мера Жаккара. Мера Жаккара -- бинарная мера сходства, предложенная Полем Жаккаром в 1901 году : Где -- общее количество чего-либо в первой...
-
Для того, чтобы разработать оптимальный метод интеграции сторонних систем в существующую ИТ-инфраструктуру систем компании, требуется точно поставить...
-
Технические требования Техническое задание данной работы требует разработать программу для визуального редактирования HTML-кода. Программа должна быть...
-
Описание классов и методов - Обзор проблематики и теоретических основ электронного документооборота
В данной работе реализован один публичный класс Form1, в котором и происходит основной функционал программы, посредством выполнения методов по кнопкам....
-
При извлечении текста из Интернета, он не имеет никой разметки и представлен в виде сплошного набора предложений. Для дальнейшего использования...
-
Предложенный подход к решению задач исследования Используя в качестве основы присутствующее в наличии программное обеспечение, которое применимо к...
-
Необходимо исследовать зависимость влияния различных факторов на параметр, характеризующий производство. В качестве такого параметра было выбрано...
-
Возрастающая сложность современных автоматизированных систем управления и повышение требовательности к ним обуславливает применение эффективных...
-
Свойства алгоритмов - Алгоритм
Данное выше определение алгоритма нельзя считать строгим - не вполне ясно, что такое "точное предписание" или "последовательность действий,...
-
Метод представления знаний при проектировании модели - Искусственный интеллект
Предлагаемая модель ИИ основывается на когнитивных картах - некотором базовом знании о мире. Ключевые идеи, положенные в основу этой концепции, сходны с...
-
Известно, что создание систем "с нуля" приводит к глобальным затратам компании на фонд оплаты труда, на поддержание созданного решения. К тому же, чем...
-
Информационная система крупной организации, как правило, представляет собой исторически сложившуюся совокупность отдельно работающих систем, которые...
-
Оценка качества работы системы - Роль ключевых предложений в построении текста
Для того чтобы оценить качество работы системы, с ее помощью были составлены рефераты 40 текстов. Среди них было 20 текстов публицистического стиля...
-
В работе возникает необходимость выбора предметной области, в которой будет тестироваться каскадный классификатор. Главными вопросами на данном этапе...
-
Роль ключевых предложений в построении текста В первую очередь введем несколько базовых понятий рассматриваемой предметной области: текст, сложное...
-
Онлайн исследования в социологии: новые методы анализа данных - Распространение новостной информации
На сегодняшний день анализ социальных сетей и медиа, Интернет-сообществ, пользователей в целом используется в основном в маркетинге. Компания может...
-
В выпускной квалификационной работе предметом исследования является деятельность по учету и управлению доставкой корреспонденции. Для того, чтобы...
-
Широкое распространение в операционной системе Windows имеет множество стандартных программ обеспечивающих работу устройств компьютера и служащих для...
-
Определение методов реинжиниринга информационных систем Основные задачи, которые стоят перед проектировщиком, занимающимся реинжинирингом информационных...
-
Модели транзакций - Банки и базы данных. Системы управления базами данных
Под транзакциями понимаются действия, производимые над базой данных и переводящие ее из одного согласованного состояния в другое согласованное состояние....
-
Для упрощения работы с трехмерной моделью на любом этапе проектирования и повышения ее наглядности в SolidWorks используется Дерево Построений (Feature...
-
Как уже отмечалось в разделе "Различимость входных данных" числовые сигналы рекомендуется масштабировать и сдвигать так, чтобы весь диапазон значений...
-
Каждая СУБД имеет особенности в представлении структуры таблиц, связей, определении типов данных и т. д. которую необходимо учитывать при проектировании....
-
Актуальность Сегодня всемирная популярность социальных информационных сетей продолжает набирать обороты, все большее пользователей не может отказать себе...
-
По Р. Шеннону (Robert E . Shannon - профессор университета в Хантсвилле, штат Алабама, США ), "имитационное моделирование - Есть процесс конструирования...
-
Собственными называют периодические колебания консервативной системы, совершающиеся исключительно под воздействием инерционных и упругих сил. Для...
-
Задача поведенческой сегментации, формирование портретов клиентов по поведению Одними из основных задач анализа являлись: поведенческая сегментация...
-
Построение аналитической модели АОУ затруднено из-за отсутствия или недостатка априорной информации об объекте управления, а также из-за ограниченности и...
-
Постановка задачи Основной целью дипломной работы является создание комплексной системы информационной безопасности предприятия на примере информационной...
-
ИЕРАРХИЧЕСКАЯ МОДЕЛЬ ДАННЫХ ИМД основана на понятии деревьев, состоящих из вершин и ребер. Вершине дерева ставится в соответствие совокупности атрибутов...
-
Физические модели БД - Банки и базы данных. Системы управления базами данных
Под физической моделью БД понимается способ размещения данных на устройствах внешней памяти и способ доступа к этим данным. Каждая СУБД по-разному...
-
В качестве доступного инструментария были рассмотрены две открытые кроссплатформенные библиотеки для разработки C++ приложений WxWidgets и Boost ,...
-
Многие организации, рассматривая вопрос о сетевой безопасности, не уделяют должного внимания методам борьбы с сетевыми атаками на втором уровне. В...
-
Разработка интерфейса, Разработка запросов - Высокоуровневые методы информатики и программирования
Программа, будет начинать работу с вывода главной формы, на которой будет располагаться самое главное меню, т. е. другими словами "панель навигации"....
-
Создание и редактирование функциональных моделей в Ramus Educational
Цель работы: получение навыков создания и редактирования функциональных моделей в Ramus Educational. Для выполнения последующей лабораторной работы...
-
ВВЕДЕНИЕ - Методы доступа к передающей среде в ЛВС
На сегодняшний день более 80 % всех компьютеров мира объединено в различные информационно-вычислительные сети. Появление компьютерных сетей было вызвано...
-
Система мониторинга социальных сетей предоставляет исследователю возможность собрать интересующие его упоминания в социальных сетях по какой-либо...
Метод аннотированного суффиксного дерева - Сравнение моделей представления слов в задаче очистки текста от обесцененной лексики