Теоретические основы и анализ объекта исследования, Теоретические предпосылки исследования - Интеллектуальный анализ данных, который способствует поддержке маркетинга в компании
Теоретические предпосылки исследования
Системы поддержки принятия решений
Системы поддержки принятия решений (СППР), представляют собой приложения узкого профиля, которые предназначены для аналитиков и менеджеров, специализирующихся на данном профиле [8]. Они характеризуются возможностью реализации высокого уровня формализации выработки рекомендаций для принятия различных решений, включая управленческие. При этом, сильно снижается уровень "человеческого фактора", который может привести к субъективной оценке. На практике весьма востребованы информационные системы для автоматизации учета и управления. Это объясняется наличием высокоэффективных и высокопроизводительных типовых средств регистрации и обработки данных. Подобные СППР могут быть автоматическими или автоматизированными. Результатом работы СППР для автоматизации учета и управления является получение итоговых отчетов. Одной из основных задач информационной системы поддержки принятия решений является - выбор среди множества альтернатив одной, которая подходит наилучшим образом для достижения определенной цели. Для анализа данных в СППР используется множество различных методов. Среди передовых выделяют: интеллектуальный анализ данных, информационный поиск (аналитические запросы), поиск знаний в базах данных (поиск скрытой, неочевидной информации в данных), имитационное моделирование, нейронные сети и др. СППР, поддерживающие работу методов искусственного интеллекта, называют интеллектуальными СППР (ИСППР). Четкого определения СППР не существует, однако, имеется некоторый набор характеристик, предложенный Турбаном (Turban, 1995) [14], для современных СППР, которым система должна соответствовать:
- - СППР для работы использует данные и модели - СППР предназначается для помощи в принятии решений слабоструктурированных, неструктурированных или нетривиальных задач - СППР служит поддержкой для аналитика (менеджера, консультанта) в принятии решений, а не заменяет его - Основной целью СППР является увеличение показателей эффективности решений.
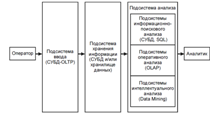
Рис 1. Обобщенная архитектура системы поддержки принятия решений
Базы данных (БД). Databases (DB)
На текущий момент все основные идеи информации, информационных технологий и данных базируются на концепции баз данных. Основой данных информационных технологий являются данные, которые организованы в базах данных. Необходимо иметь возможность сообразно отображать данные, а также с помощью данных отображать изменения реального мира во времени и воздавать информационные потребности пользователей [3]. Данными называют описание восприятия реального мира.
Концепция Баз Данных (БД)
Основной характеристикой систем управления баз данных (СУБД) является наличие процедур для ввода, хранения и обработки данных, а также описания их структуры. Для работы СППР с данными, анализа данных и поиска решений необходимо накопление и хранение массивных объемов информации (данных). В настоящий момент наиболее распространен "реляционный" подход к построению БД, также его называют ER-моделированием. Кодд (1970) сформулировал 12 правил для реляционной БД:
- 1. Данные представляются в виде таблиц. БД состоит из набора таблиц, в которых хранятся данные. Данные группируются в форму рядов и столбцов. Набор значений, который относится к одному объекту, хранящемуся в таблице, отображается в рядах. Также его называют "записью". Столбцом определяется единая характеристика для всех объектов таблицы. Столбцы также называют полями. 2. Данные доступны логически. Подразумевается, что к ячейке нельзя обратиться физически, указав номер ряда и столбца. Доступ реализуется только через идентификаторы таблицы. Первичный ключ является уникальным идентификатором в рамках одной таблицы. Первичные ключи, которые образуются из нескольких полей, называются составными ключами. 3. NULL трактуется как неизвестное значение. Если значение ячейки не заполнено, то записывается значение "NULL". 4. БД должна включать в себя метаданные. Имеется в виду, что в БД помимо пользовательских таблиц, которые заполняются пользователем, хранятся и системные таблицы. Метаданные (данные о данных) хранятся в системных таблицах. 5. Для взаимодействия с СУБД должен использоваться единый язык. В настоящее время используется SQL. 6. СУБД должна обеспечивать альтернативный вид отображения данных. Пользователь должен иметь возможность строить представления (виртуальные таблицы), которые представляют собой динамическое объединение нескольких таблиц. Изменения в представлениях должны автоматически переноситься на исходные таблицы. 7. Должны поддерживаться операции реляционной алгебры. Над записями реляционной БД осуществляются операции реляционной алгебры. В настоящее время данное правило реализуется через SQL. 8. Должна обеспечиваться независимость от физической организации данных. СУБД и иные приложения, оперирующие с данными реляционной БД, не должны зависеть от метода физического хранения данных. 9. Должна обеспечиваться независимость от логической организации данных. СУБД и иные приложения, оперирующие с данными реляционной БД не должны зависеть от метода логической организации связей между таблицами. 10. За целостность данных отвечает СУБД. Под целостностью подразумевается готовность БД к работе. Выделяют два типа целостности:
- - Физическая целостность - сохранность данных на носителях, корректность формата хранения; - Логическая целостность - актуальность и непротиворечивость данных.
Транзакцией называют последовательность операций над БД, которые рассматриваются СУБД как единое целое. Развитые методы управления транзакциями в СУБД делают их основным средством для построения OLTP-систем (Online Transaction Processing Systems), которые предназначены для оперативной обработки транзакций. Однако, для анализа данных эффективность использования OLTP-систем мала. Это вызвано тем, что характеристики OLTP-систем не удовлетворяют требованиям к системе анализа данных. Так, например, OLTP-системы могут хранить только детализированные данные, но не обобщенные; допускаются выбросы, незаполненные строки, ошибки в данных; требуется обеспечение максимальной нормализации; доступ к данным осуществляется по заранее составленным запросам и др. Основной недостаток реляционной БД заключается в отсутствии возможности обработки информации, которая не может быть представлена в табличном формате. В подобных случаях используют объектно-ориентированные модели
Концепция Хранилищ Данных (ХД)
Концепция ХД заключает в себе возможности OLTP-систем и систем анализа. ХД данных представляет собой набор данных, который является неизменным, интегрированным и поддерживающим хронологию [1]. В ХД возможно лишь добавление данных, а не редактирование или удаление уже хранящихся данных. Основные свойства ХД:
- - Предметная ориентация. Одно из фундаментальных различий между ХД и Оперативными Источниками Данных (ОИД). Данные в ХД могут описывать одну и ту же предметную область с разных точек зрения. Также в ХД хранятся только необходимые для анализа данные. - Интеграция. В ХД данные из разных ОИД приводятся к единому формату. - Поддержка хронологии. Данные, которые хранятся в ХД, соответствуют последовательным интервалам времени. - Неизменяемость. Для анализа требуются данные за максимально большой период времени. Данные в ХД после загрузки, как правило, только читаются и добавляются.
На концепции ХД основаны методы реализации таких подсистем анализа, как OLAP-системы или Data Mining системы. ETL-процесс является процессом, который производит обработку, очистку и предварительную подготовку данных для их последующей записи в ХД.
Для реализации в СППР концепции ХД все данные из различных ОИД копируются в единое ХД. При копировании данных из ОИД в ХД на стадии ETL-процессов проводится приведение данных к единому формату и структуре
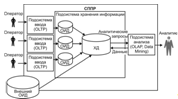
Рис 2. Структура СППР с физическими ХД
Подобная система является эффективной с точки зрения быстродействия. Однако, такой метод вызывает избыточность информации, так как данные хранятся как в ОИД, так и в ХД.
Для исключения избыточности информации используется виртуальное ХД, которое не хранит данные, а лишь ссылается на ОИД. Но с использованием виртуального ХД значительно снижается скорость быстродействия. Также, в случае виртуального ХД, для успешного функционирования такого подхода, необходим постоянный доступ всех ОИД. Перерывы в работе любого из ОИД могут привести к невыполнению аналитического запроса. Основным недостатком виртуального хранилища данных является практическая невозможность получения данных из ОИД за долгий период. Таким образом, организация виртуального ХД является уместной при работе только с текущими детализированными данными, или при необходимости минимизации объема занимаемой памяти.
Процесс организации физического ХД является довольно трудоемким:
- - Данные необходимо интегрировать из неоднородных источников. Основной целью ХД является агрегирование и аккумуляция данных из разнородных ОИД. - Большие объемы информации необходимо эффективно хранить и обрабатывать. ХД обладает свойством неизменности имеющийся информации и добавлением новой, что подразумевает накопление информации. Постоянно растущее количество информации приводит к вынужденному увеличению объемов дискового пространства (памяти). Денормализация данных, которая необходима для выполнения аналитических запросов, приводит к нелинейному росту объемов занимаемой памяти. - Метаданные должны быть многоуровневыми. Наличие развитых метаданных и средств их визуализации для пользователей является одним из наиболее важных условий успешной организации и реализации ХД. Метаданные необходимы для понимания структуры и форматов информации - Необходима повышенная безопасность данных. В ХД могут храниться конфиденциальные данные. По этой причине задача разграничения прав доступа пользователей к информации в ХД является важной.
Альтернативой ХД является Витрина Данных (ВД). ВД представляет собой упрощенный вариант ХД, где содержатся только тематически объединенные данные. ВД можно реализовать автономно, а можно и вместе с ХД. Второй тип реализации ВД в последнее время становится наиболее популярным среди компаний. При таком подходе ХД становится единственным источником интегрированных данных, а ВД являются подмножествами данных из ХД. Конечные пользователи могут использовать как исключительно ВД для анализа, так и ХД, если необходимых данных нет в ВД.
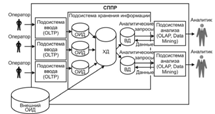
Рис 3. Структура СППР с ХД и ВД
Основным недостатком такого подхода является большая избыточность информации, так как данные хранятся сразу в ОИД, ХД и ВД.
OLAP-системы (Online Analytical Processing Systems)
Реляционная модель БД представляет собой плоскую модель данных, отображающуюся в табличной форме, тогда как OLAP-кубы представляют собой многомерные модели данных, что в определенных случаях удобнее для аналитика. OLAP является технологией оперативной аналитической обработки данных. Целью OLAP-анализа является проверка возникающих гипотез [1]. Кодд (1993) описал основные концепции OLAP и определил требования, которым OLAP должен отвечать:
- 1. Многомерность. OLAP-система на концептуальном уровне должна представлять данные в виде многомерной модели 2. Прозрачность. OLAP-система должна скрывать от пользователя действительную реализацию многомерной модели, метод ее организации, средства обработки, средства хранения и источники информации. 3. Доступность. OLAP-система должна предоставлять пользователю единую, целостную и согласованную модель данных, обеспечивать доступ к данным независимо от места их хранения 4. Постоянная производительность при разработке отчетов. Производительность OLAP-систем не должна существенно снижаться при увеличении количества измерений для анализа. 5. Клиент-серверная архитектура. Пользователь должен иметь доступ к клиент-серверной среде. Имеется ввиду, что OLAP-система должна позволять строить общую концептуальную схему на основе консолидации и обобщения из различных физических и логических схем БД. 6. Равноправие измерений. В многомерной модели OLAP-системы все измерения должны быть равноправны. 7. Динамическое управление разреженными матрицами. OLAP-система должна обеспечивать оптимальную обработку разреженных матриц. 8. Поддержка многопользовательского режима. OLAP-система должна предоставлять возможность работать сразу нескольким пользователям совместно над аналитической моделью. 9. Неограниченные перекрестные операции. OLAP-система должна обеспечивать сохранение функциональных отношений между ячейками гиперкуба при выполнении любых операций среза, вращения, консолидации или детализации. Преобразования установленных отношений должны выполняться автоматически. 10. Интуитивная манипуляция данными. OLAP-система должна давать возможность работать с моделью без необходимости пользователю совершать множество манипуляций. 11. Гибкие возможности получения отчетов. OLAP-система должна поддерживать различные методы и способы визуализации данных. 12. Неограниченная размерность и число уровней агрегации.
Дополнительные правила Кодда
- 13. Пакетное извлечение против интерпретации. OLAP-система должна одинаково эффективно обеспечивать доступ к собственным и внешним данным. 14. Поддержка всех моделей OLAP-анализа. OLAP-система должна поддерживать категориальную, толковальную, умозрительную и стереотипную модель анализа данных. 15. Обработка ненормализованных данных. Должна быть возможность интеграции OLAP-системы с ненормализованными источниками данных. 16. Сохранение результатов OLAP: хранение отдельно от исходных данных. OLAP-система, которая работает в режиме чтения и записи, должна сохранять результаты работы отдельно, не изменяя исходные данные. 17. Исключение отсутствующих значений. OLAP-система должна отбрасывать все отсутствующие значения. 18. Обработка отсутствующих значений. OLAP-система должна игнорировать все отсутствующие значения независимо от их источника.
Выделяют три основных способа организации OLAP:
- - Многомерный OLAP (MOLAP), использует многомерные БД для реализации многомерной модели. Данные хранятся в виде упорядоченных многомерных массивов. Подобные массивы делятся на гиперкубы и поликубы. O Гиперкуб. Все хранимые ячейки имеют одну и ту же мерность O Поликуб. Каждая ячейка имеет свой собственный набор измерений. При этом возникает большая сложность обработки
Основным преимуществом использования MOLAP являются быстродействие и оперативность системы. Однако, из-за денормализации данных и их предварительной агрегации объем данных относительно исходной БД возрастает от 2,5 до 100 раз. Дополнительным недостатком MOLAP-системы является ее чувствительность к изменениям. Добавление нового измерения приводит к изменению структуры всей многомерной БД.
Использовать MOLAP уместно в случаях, когда объем исходных данных не более нескольких гигабайт, структура БД стабильна, а быстродействие системы является наиболее важным параметром
- Реляционный OLAP (ROLAP), использует реляционные БД для организации модели. Наиболее популярными схемами реляционных БД для построения ROLAP-модели являются схемы "Звезда" и "Снежинка". Для схемы "Звезда" основными составляющими являются денормализованная таблица фактов и множество таблиц измерений. Первичным ключом в таблице фактов, как правило, является составной ключ, который объединяет первичные ключи таблиц измерений. Каждая таблица измерений находится в отношении "один ко многим" (1 to n) с таблицей фактов. Схема "Снежинка" используется при наличии сложных задач, связанных с иерархическими измерениями.
Основными достоинствами ROLAP-систем являются: удобство реализации, гибкость модели реляционной БД, высокий уровень защиты данных. При этом, производительность ROLAP меньше чем MOLAP. Но при хорошей реализации и настройке схемы "Звезда", производительность становится сопоставимой с MOLAP
- Гибридный OLAP (HOLAP), использует многомерные и реляционные БД для реализации многомерной модели. Другими словами, HOLAP системы объединяют технологии ROLAP и MOLAP для повышения производительности и сохранения основных преимуществ ROLAP +
Data Mining системы (системы интеллектуального анализа данных).
Data Mining имеет характеристику по исследованиям и обнаружениям ЭВМ знаний [13]. Существуют определенные требования к полученным с помощью Data Mining знаниям:
- - Знания должны быть новыми, ранее неизвестными. Естественное требование к характеристике получаемых знаний, так как поиск уже известной информации не несет никакой ценности - Знания должны быть нетривиальными. Полученные знания должны быть неочевидными, скрытыми в данных, должны отражать закономерности в данных. - Знания должны быть практически полезны. Полученные знания должны быть применимы и приносить определенную выгоду от использования. - Знания должны быть доступны для понимания человеку. Полученные знания должны быть логически объяснены и представлены в понятном для пользователя виде.
По назначению задачи Data Mining делятся на описывающие и предсказательные. Первые, такие как кластеризация и поиск ассоциативных правил, улучшают понимание анализируемых данных, выдавая в итоге прозрачные для восприятия аналитиком результаты. Вторые, такие как регрессия и классификация, помогают спрогнозировать некоторые данные и показатели. Также алгоритмы Data Mining разделяют на "обучающиеся с учителем" и "обучающиеся без учителя".
- - Классификация и регрессия. Классификация применяется в случае, если требуется осуществить разбиение множества объектов на классы. С точки зрения Data Mining, задачу классификации рассматривают как задачу определения одного дискретного объекта на основании значений других параметров. Если значениями зависимой и независимой переменных являются действительные числа, то такая задача относится к задаче регрессии. Задачи классификации и регрессии разбиваются на два этапа: O выделение обучающей выборки, в которую входят объекты с известными значениями как независимых, так и зависимой переменной; O применение построенной модели для анализа зависимой переменной.
Стоит отметить, что для корректной работы методов классификации и регрессии необходимо провести качественную предварительную обработку данных.
- - Задача поиска ассоциативных правил. Главная цель данной задачи заключается в выявлении часто встречаемых наборов объектов в большой выборке. Метод поиска ассоциативных правил является частным случаем метода классификации. Секвенциальным анализом называется разновидность задачи поиска ассоциативных правил. Смысловая ценность секвенциального анализа заключается в предсказании с некоторой долей вероятности появления события в будущем, то есть - предсказательный анализ. - Задача кластеризации. Задача кластеризации заключается в разделении некоторых множеств объектов на кластеры, то есть группы схожих объектов. Кластерный анализ хорошо подходит для выявления портрета потребителя, сегментации клиентов, поведенческого анализа. Как правило, задача кластеризации помогает "объяснить" данные. Часто используется на первых этапах более сложного анализа, когда у аналитика недостаточно знаний, связанных с данными. В качестве коечного результата решения задачи кластеризации принимается выделение групп наиболее близких и похожих между собой объектов (кластеров). - Нечеткая логика. При работе с методами нечеткой логики могут возникать трудности, связанные с неопределенностью, недостоверностью, неполнотой и неизвестностью информации. Есть два типа неопределенности информации: физическая и лингвистическая. Для первого случая подходят методы классической теории множеств и теории вероятности. Для второго случая - лингвистической неопределенности - используются методы искусственного интеллекта, которые постоянно дорабатываются и расширяются.
В отличии от математических методов, нечеткая логика применяется в основном в задачах управления. Основоположник методов нечеткой логики - Л. Заде (1965), предложил лингвистическую модель, которая использует лингвистические слова, отражающие качество, а не математические выражения. При этом, по сравнению с математическими моделями, точность лингвистической модели меньше, но создание качественной модели, которая является намного более устойчивой, чем математическая - возможно. В методах и алгоритмах нечеткой логики наблюдается сравнительное сходство со здравым логическим мышлением человека.
- - Генетические алгоритмы. Методы генетических алгоритмов (ГА) относятся к универсальным методам оптимизации. Предназначаются для решения множества различных, задач, например, комбинаторных. По своей сути метод ГА не всегда позволяет добиваться поставленных целей и задач исследования. Однако, он очень эффективен при интеграции с другими методами. Например, методом нейронных сетей или методом нечеткой логики. - Нейронные сети. Нейронные сети представляют собой класс моделей, методы которых основаны на биологической аналогии с человеческим мозгом. После прохождения обучающего этапа на предназначенных для этого данных, модель может использоваться для решения различных задач анализа данных. Однако, простого обучения модели недостаточно - за аналитиком остается задача выбора архитектуры модели, числа слоев, количества нейронов и прочей настройки модели для увеличения ее эффективности. Задачей нейронных сетей, как правило, является предсказание событий или значений объектов. Проблема нейронных сетей заключается в том, что аналитик не может наблюдать ничего от момента загрузки данных в модель до момента получения итогового результата, на который сильно влияет изначальная настройка модели. Важным является то, что не существует однозначных алгоритмов предварительной настройки модели для максимизации качества анализа.
Похожие статьи
-
Заключение - Интеллектуальный анализ данных, который способствует поддержке маркетинга в компании
В рамках проведенного исследования была проделана работа по разработке системы интеллектуального анализа данных для поддержки маркетинга производственной...
-
Описание исходных данных На текущий момент (в силу большой загрузки IT-отдела) не реализован доступ к серверу с ХД, маркетинговые данные выгружаются в...
-
Прогнозирование оттока клиентов Отделом маркетинга компании ELEMENTAREE было выявлено, что практически все клиенты, у которых отсутствовали заказы в...
-
Предложенный подход к решению задач исследования Используя в качестве основы присутствующее в наличии программное обеспечение, которое применимо к...
-
Введение - Интеллектуальный анализ данных, который способствует поддержке маркетинга в компании
В связи возникших условий экономического кризиса наблюдается рост издержек маркетинговой деятельности. Отдел маркетинга компании "ELEMENTAREE" испытывает...
-
Определение методов реинжиниринга информационных систем Основные задачи, которые стоят перед проектировщиком, занимающимся реинжинирингом информационных...
-
Задача поведенческой сегментации, формирование портретов клиентов по поведению Одними из основных задач анализа являлись: поведенческая сегментация...
-
Объектом исследования является производственная компания ООО "Элементари" (ELEMENTAREE) (http://www. elementaree. ru/). Исследования, отображаемые в...
-
По результатам данного исследования необходимо выявить недостатки и ограничения существующих технологий интеграции. Для проведения исследования...
-
Для того, чтобы разработать оптимальный метод интеграции сторонних систем в существующую ИТ-инфраструктуру систем компании, требуется точно поставить...
-
Увеличение эффективности деятельности отделов В рамках данной задачи производился анализ данных с целью выявления любых знаний, на базе которых можно...
-
Прогнозируемая оценка проекта после реализации единой шины данных как прослойки между всеми компонентами ИТ-ландшафта компании выполняется по методу...
-
Технологии объектного связывания данных - Теоретические основы информационных технологий
Унификация взаимодействия прикладных компонентов с ядром информационных систем в виде SQL-серверов, наработанная для клиент-серверных систем, позволила...
-
UML - унифицированный язык моделирования, призванный упростить построение больших информационных систем. Состоит из диаграмм, связей и сущностей....
-
Основные термины теории баз данных - БД (База данных) - совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы...
-
Корпоративная интеграционная подсистема на базе IBM WebSphere Business Integration Message Broker [28] отвечает за выстраивание корпоративной...
-
Обновленная база данных должна иметь продвинутую структуру пользователей для использования на информационном портале под управлением новой CMS. Для...
-
Постановка задачи Имеющаяся база данных SQL имеет недостаточное количество полей и таблиц, не имеет упорядоченной структуры пользователей для работы с...
-
Онлайн исследования в социологии: новые методы анализа данных - Распространение новостной информации
На сегодняшний день анализ социальных сетей и медиа, Интернет-сообществ, пользователей в целом используется в основном в маркетинге. Компания может...
-
Системы поддержки принятия решений - Системы поддержки принятия решений
Система поддержки принятия решений или СППР (Decision Support Systems, DSS) -- это компьютерная система, которая путем сбора и анализа большого...
-
Введение - Система поддержки принятия решений
Современные системы поддержки принятия решения (СППР) представляют собой системы, максимально приспособленные к решению задач повседневной управленческой...
-
Основные понятия баз данных. Цели использования баз данных - Разработка базы данных
В широком смысле слова база данных (БД) - это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Для удобной...
-
"Базы данных и СУБД", Понятие банка данных, базы данных и СУБД - Базы данных и СУБД
Понятие банка данных, базы данных и СУБД Существует множество различных систем управления базами данных, именуемые в последующем "СУБД", такие как: IMS,...
-
Технологии распределенных вычислений (РВ) Современное производство требует высоких скоростей обработки информации, удобных форм ее хранения и передачи....
-
Описание предметной области ООО ИСК "Волгастройинвест" является официальным представителем ряда отечественных и зарубежных фирм, предлагающих на...
-
Эффективность работы бизнеса напрямую зависит от эффективности работы ИТ. При внедрении новых проектов, связанных с развитием бизнеса, происходит...
-
Известно, что создание систем "с нуля" приводит к глобальным затратам компании на фонд оплаты труда, на поддержание созданного решения. К тому же, чем...
-
Распределенные базы данных - Теоретические основы информационных технологий
Системы распределенных вычислений появляются, прежде всего, по той причине, что в крупных автоматизированных информационных системах, построенных на...
-
SPSS Modeler [29] - это программный комплекс, позволяющий строить прогностические модели и применять эту информацию при принятии решений на уровне...
-
Модели информационных процессов передачи, обработки, накопления данных Обобщенная схема технологического процесса обработки информации При производстве...
-
Построение модели предметной области с помощью описания структур данных и программного кода является классическим подходом в разработке ИС. Зачастую...
-
Информационная система крупной организации, как правило, представляет собой исторически сложившуюся совокупность отдельно работающих систем, которые...
-
Построение ER диаграмм - Модернизация структуры базы данных на основе анализа требований предприятия
При построении моделей информационных систем важнейшей методикой является ER-моделирование или построение диаграмм сущность-связь. Сущность представляет...
-
Введение - Система управления базами данных
Развитие средств вычислительной техники обеспечило для создания и широкого использования систем обработки данных разнообразного назначения....
-
Обоснование выбора средств разработки проекта Для реализации корпоративной информационной системы "Бюджетное планирование и отчетность" в исследуемой...
-
Необходимость защиты информации от внутренних угроз была очевидна на всех этапах развития средств информационной безопасности. Однако первоначально...
-
Области применения ЭС - Теоретические основы информационных технологий
ЭС в задачах интерпретации , как правило, используют информацию от датчиков для описания ситуации. В качестве примера приведем интерпретацию показаний...
-
Основные компоненты - Теоретические основы информационных технологий
Рассмотрим структуру системы поддержки принятия решений (рис. 2.4), а также функции составляющих ее блоков, которые определяют основные технологические...
-
На основе описания методов можно с уверенностью сказать, что данная система может успешно справляться с автоматизацией анализа документации. При этом...
-
Как следует из названия, нефункциональные требования не связаны непосредственно с функциями, выполняемыми системой. Они связаны с такими интеграционными...
Теоретические основы и анализ объекта исследования, Теоретические предпосылки исследования - Интеллектуальный анализ данных, который способствует поддержке маркетинга в компании