Прогнозирование потребности в продукте на планируемый период - Оптимизация многономенклатурных поставок
Основные положения теории прогнозирования.
В снабженческой, производственной и распределительной логистике широко используются методы прогнозирования, поскольку прогнозные оценки развития анализируемых процессов являются основой принятия управленческих решений при оперативном, тактическом и стратегическом планировании. От точности и надежности прогноза зависит эффективность реализации различных логистических операций и функций: от оценки вероятности дефицита продукции на складе до выбора стратегии развития фирмы.
Различным аспектам теории прогнозирования посвящено значительное количество исследований. В большинстве работ прогноз определяется как вероятностное научно обоснованное суждение о перспективах, возможных состояниях того или иного явления в будущем и/или об альтернативных путях и сроках их осуществления. Под методологией прогнозирования понимается область знаний о методах, способах и системах прогнозирования, а именно:
- - метод прогнозирования -- способ исследования объекта, направленный на разработку прогноза; - методика прогнозирования -- совокупность одного ИЛД? нескольких методов; - система прогнозирования -- упорядоченная совокупность методик и средств реализации.
Известно, что теория прогнозирования включает: анализ объекта прогнозирования; методы прогнозирования, подразделяющиеся на математические (формализованные) и экспертные (интуитивные); системы прогнозирования, в частности непрерывного, при котором за счет мониторинга осуществляется корректировка прогнозов в процессе функционирования обьекта.
Экспертные методы прогнозирования рекомендуется использовать в том случае, если:
- - нет достаточной статистической информации об изменении ана - лизируемого показателя и влияющих на него факторов; - показатель не изменяется численно, а выражается качественны - ми признаками; - анализируемый показатель не может быть описан на основе эволюционного развития, поскольку изменяется скачкообразно и при - рода этих изменений неизвестна.
Математические методы прогнозирования подразделяются на три группы:
- - симплексные (простые) методы экстраполяции по временным - рядам (метод наименьших квадратов, экспоненциальное сглаживание и др.); - статистические методы, включающие корреляционный и регрессионный анализ, факторный анализ и др.; - комбинированные методы, представляющие собой синтез различных вариантов прогнозов.
При формировании методики прогнозирования целесообразно, на наш взгляд, рассматривать прогноз в узком (I тип прогноза) и в широком (II тип прогноза) смысле.
В узком смысле прогноз выполняется при условии, что основные факторы, определяющие развитие прогнозируемого процесса или явления, не претерпят существенных изменений. Это позволяет выдвигать гипотезы о будущем развитии процессов и явлений, в значительной мере базирующиеся на анализе прошлого.
Прогнозы I типа осуществляются с применением симплексных или статистических методов на основе временных рядов. Для прогнозов I типа характерно, что:
Число значимых переменных включает от 1 до 3 параметров, т. е.
По масштабности они относятся к сублокальным прогнозам;
При использовании одного параметра, например времени, такие
Прогнозы считаются сверхиростыми, при двух-трех взаимосвя
Занных параметрах -- сложными;
По степени информационной обеспеченности периода ретроспекции прогнозы 1 типа могут быть отнесены к объектам с полным
Информационным обеспечением.
Для повышения точности и достоверности прогнозных оценок I типа целесообразно использование комбинированных методов, при этом желательно использование большого количества вариантов прогноза, рассчитанных на основе различных подходов или альтернативных источников информации.
Прогноз II типа (в "широком" смысле) подразумевает, что исходные данные для получения оценок определяются с использованием опережающих методов прогнозирования: патентного, публикационного и др. Как правило, прогнозы II типа используются для долгосрочного прогнозирования и разбиваются на два этапа: первый -- получение прогнозных оценок основных факторов; второй -- собственно прогноз развития процесса или явления. Учитывая объективную сложность и трудоемкость выполнения прогнозов II типа, можно констатировать, что наибольшее распространение получили методы прогнозирования I типа. В дальнейшем мы будем рассматривать только прогнозы I типа.
В ряде работ приводится более полная классификация методов прогнозирования и дается их подробная характеристика, например [47, 61, 63 и др.]. Некоторые методы иллюстрируются примерами, при этом не говорится, как ориентироваться в этих методах, какой из них лучше выбрать для прогноза на основе имеющихся данных.
На наш взгляд, для успеха в построении прогнозов знаний только о способах получения прогнозных оценок недостаточно. Важно четко разграничивать области применения разных методов прогнозирования и в зависимости от объема и характера данных быстро и безошибочно выбирать нужный метод в соответствии с целью получения конкретного прогноза.
Рассмотрим методы прогнозирования, требующие применения специальной вычислительной процедуры, в порядке увеличения объема исходных данных, необходимых для получения прогнозных оценок.
Простые методы сглаживания данных
К простым методам сглаживания данных можно отнести метод экспоненциального сглаживания с одним параметром и метод арифметического сглаживания. Важнейшая предпосылка любого метода сглаживания состоит в использовании последних данных ряда, поскольку информация имеет свойство устаревания, причем чем ближе данные к интервалу прогноза, тем их вес (или значимость) для прогноза должен быть больше. При прогнозировании по методу экспоненциального сглаживания с одним параметром прогнозируемое значение у+ { в момент времени I + 1 представляет собой сумму фактического значения показателя ус и прогнозируемого значения уъ момент времени I.
Определение параметра сглаживания имеет большое значение для функционирования модели (7.1). В работе [35] даны следующие рекомендации по выбору параметра сглаживания:
Если в модели наиболее значимым является именно последнее наблюдение, рекомендуется назначать большое значение а. В случае а - 1 прогнозное значение будет равно фактическому за предыдущий период;
Если существует практически полное доверие ко всем данным временного ряда и игнорирование значимости последнего наблюдения, то а близко к 0;
Если исследуемый показатель характеризуется низким уровнем случайных воздействий, но подвержен редким и значительным по величине скачкам, то следует выбирать относительно высокое значение а(а~ 0,5).
Модель (7.1) называется однопараметрической моделью Брауна, значение параметра а в которой должно подбираться путем последовательных приближений. Процедура подбора сводится к поиску такого значения а, которое обеспечивает наименьшую погрешность -- среднеквадратичное от клонение:
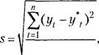
Где п -- число учитываемых периодов времени (можно принять как число данных исходного ряда); тп -- количество параметров показательного сглаживания (модель (7.1) однопараметрическая, поэтому гп = 1).
Наилучшее значение параметра а может быть найдено с помощью процедуры Поиск решения М5 Ехсе1.
Для прогнозирования с использованием модели (7.1) помимо выбора параметра а важно задать начальное условие (или начальное предположение). Существует несколько способов определения начального условия. Во-первых, наиболее часто предполагается, что начальное условие равно фактическому значению показателя при I = 1. Заметим, что этот способ доступен при количестве исходных данных Ы>2. Во-вторых, в качестве начального условия выбирается среднее арифметическое значение, рассчитанное по всем доступным к началу прогнозирования данным. В-третьих, при большом объеме данных в качестве начального условия используется среднее значение нескольких наблюдений (например, первой трети имеющихся данных), которые далее не будут участвовать в модели прогнозирования (7.1).
Следует иметь в виду, что экспоненциальное сглаживание не является подходящим методом прогнозирования для монотонно возрастающих или убывающих статистических данных. В первом случае модель (7.1) даст всегда заниженный, а во втором -- завышенный прогноз. Метод можно скорректировать, включив в него направление изменения значений прогнозируемого показателя, и такой метод называется методом Хольта или экспоненциальным сглаживанием с учетом тренда. Этот метод мы рассмотрим немного позднее. Модель (7.1) также не может дать удовлетворительный прогноз, если исходные данные подвержены сезонным изменениям. В этом случае необходимы специальные методы прогнозирования.
Метод экстраполяции тренда
Суть метода экстраполяции тренда состоит в том, что закономерность, действующая внутри анализируемого временного ряда, выступающего в качестве базы прогнозирования, сохраняется и на период прогноза. Прогнозирование в этом случае можно свести к подбору аналитически выраженных моделей трендов типа у =/({) по данным предпро-гнозного периода и экстраполяции полученных трендов на интервале прогноза.
Расчетная формула для получения прогноза может быть записана в аддитивном и мультипликативном виде. Аддитивная модель прогноза имеет вид
Где у* 1 -- прогнозные значения временного ряда; у( -- среднее значение прогноза (тренд); 5( -- составляющая прогноза, отражающая периодические колебания, которые повторяются через примерно одинаковые промежутки в течение небольшого промежутка времени (сезонные колебания или сезонная волна); V, -- составляющая прогноза, отражающая периодические колебания, повторяющиеся в течение длитель - ного промежутка времени (циклические колебания); г/( -- составляющая, позволяющая учесть другие важные для конкретного прогноза факторы, такие как фаза жизненного цикла и другие факторы, определяемые долгосрочной динамикой, или эффект от маркетинговых мероприятий [21; е, -- случайная величина отклонения прогноза, обусловленного стохастическим характером социально-экономических процессов (случайные колебания, характеризующиеся абсолютной нерегулярностью величины, частоты, направления возникновения, поэтому их предсказание на основе анализа временного ряда оказывается невозможным). Мультипликативная модель прогноза имеет вид
У=уСХ1^1Г,х14+е(, (7-5)
Где /, -- коэффициент (индекс), учитывающий сезонные колебания; /р -- коэффициент (индекс), учитывающий циклические колебания; 1г1 -- коэффициент (индекс), учитывающий другие важные для конкретного прогноза факторы (фаза жизнентюго цикла, эффект от маркетинговых мероприятий и др.); Е, -- случайная величина отклонения прогноза.
Рассмотрим простой вариант, когда модели (7.4) или (7.5) содержат только составляющие у1 и ег Процедуру прогнозирования в этом случае можно представить в виде следующей последовательности.
Первый этап -- подбор зависимости для описания уравнения тренда. Видом функции задаются, обычно используются полиномы различных порядков, экспоненциальные, степенные функции и т. п. Параметры модели прогнозирования определяются методом наименьших квадратов (МПК), при этом модель тренда должна быть такой, чтобы сумма квадратов опстонений расчетных значений от фактических была бы наименьшей.
Если модель тренда является линейной: у*'( = п0 + п{ С, то расчет ко-эффициенгов уравнения я()п д( производится по формулам:
*'*УА; (7.6)
Второй этан -- продолжение полученного тренда за интервал значений, по которым строилась зависимость, или определение точечного прогноза. Для получения значения прогноза на 1-й год в уравнение тренда подстав, шюгея конкретные значения I. При этом важно помни гь о соотношении длины предпрогнозного периода и периода прогноза, их соотношение должно быть не менее чем 3 : 1.
Третий этап -- расчет ошибки прогноза. Тренд характеризует лишь средний уровень ряда на каждый момент времени, в том числе и на прогнозный период. Отдельные наблюдения в прошлом (на интервале наблюдения) отклоняются от линии тренда, это дает право предполагать, что н в будущем следует ожидать таких отклонений. Значит, прогноз имеет погрешность, которая помимо колебаний значений от среднего уровня объясняется еще и наличием неопределенности при определении параметров модели тренда, поскольку их оценивание производится на основе ограниченной совокупности данных. Погрешность прогноза можно оценить по среднеквадратнческому отклонению:
Погрешность прогноза отражается в виде доверительного интервала, с помощью которого точечный прогноз преобразуется в интервальный.
Четвертый этап -- определение интервала прогноза. Доверительный интервал прогноза при небольшом числе наблюдений и при предположении о нормальном распределении прогнозных оценок определяется следующим образом:
Ьу = у,±1А$Г (7.9)
Где га -- табличное значение /¦-критерия Стыодента с к степенями свободы и уровнем значимости р.
Похожие статьи
-
Основная модель расчета оптимального размера заказа. Учет скидок при расчете оптимальной партии заказа Наиболее распространенной моделью прикладной...
-
Методы прогнозирования в маркетинговой деятельности - Маркетинговое исследование предприятия
Прогнозирование служит для выяснения тенденций развития фирмы в условиях постоянного изменения факторов внешней и внутренней среды и поиска рациональных...
-
Характеристика предприятия и его достижения в области управления складским хозяйством В 2010 году холдинг в который входило российское предприятие...
-
Прогнозирование рынка - Модель оптимизации моментов выпуска новых моделей продукции на рынок
При изучении рынка маркетологи используют в основном кабинетные методы [2]. Причина проста - опросы (полевые методы маркетинга) трудоемки и сравнительно...
-
Прогнозирование - Маркетинговая политика предприятия
Цели прогнозирования. Прогнозные исследования необходимы, чтобы убедиться, на сколько реальны благоприятны поставленные цели для предприятия. Разумеется,...
-
Введение - Оптимизация многономенклатурных поставок
Склады влияют на издержки обращения, на размер и движение запасов на различных участках логистической цепи, поэтому игнорирование рационального,...
-
Методы, основанные на статистических данных - Методы, основанные на суждениях
Экстраполяция. Методы экстраполяции предполагают использование исторических данных по изучаемому ряду. Наиболее распространенными являются методы...
-
В закупках выделяют несколько методов, используемых для выбора поставщика: § Метод категорий предпочтения § Затратно-коэффициентный метод § Рейтинговая...
-
Одним из основных методов оценки конкурентоспособности продукции является рейтинговая оценка, которая широко применяется в мировой экономической...
-
Разбор и классификация ресурсов организации, а также методы их оптимизации Различают материальные, финансовые, трудовые, энергетические ресурсы, ресурсы...
-
Телевизионная реклама - это рекламные сообщения, которые включают в себя "изображения, звук, движение, цвет". Это очень эффективное, но одновременно и...
-
В данной главе работы будут рассмотрены основные теоретические положения, связанные с удовлетворенностью потребителя. Сначала будут выделены ключевые...
-
Методы, основанные на суждениях - Методы, основанные на суждениях
Изучение намерений контрагентов. Суть подхода состоит в том, что респондентов просят описать свое поведение в различных ситуациях. Опросы с целью...
-
Методы оценки лояльности покупателей торговых компаний
Методы оценки лояльности покупателей торговых компаний Современный рынок экономики характеризуется высоким уровнем конкуренции, в связи с этим ожидания...
-
Итак, мы рассмотрели основные технологии продвижения антивирусных продуктов в целом. Почему же мы сейчас рассматриваем именно данную компанию?...
-
Раньше практически все кредитные организации рассказывали о своей надежности и стабильности. Деньги, руки, проценты, свиньи-копилки, черно-белые...
-
Когда банки оценили выгоды ритейла, то принципиальной задачей для них стало привлечение как можно большего количества клиентов, при этом что лишь очень...
-
ВВЕДЕНИЕ - Консервирование пищевых продуктов по материалам ЧТУП "СеленаПрод" г. Добруша
В настоящее время вопросы хранения приобретают важное экономическое значение, особенно это касается продовольственных товаров. Для разных товаров данная...
-
Прогнозирование спроса. Бенчмаркинг - Основы маркетинга
Прогнозирование спроса - это научно обоснованное предсказание развития рынка во времени на основе изучения причинно-следственных связей, тенденций и...
-
Понятие и основные параметры конкурентоспособности продукта Проблема качества и конкурентоспособности товаров и услуг носит в современном мире...
-
Значение консервирования пищевых продуктов. Степень их безопасности Консервирование - это обработка пищевых продуктов для длительного сохранения их...
-
В переводе с латинского "реклама" означает "извещать". И в этом кроется одна из ее основных особенностей, отраженная в определении, описанном в Законе...
-
В настоящее время дефицит пищевых продуктов отеч Ественного среди прочих факторов обусловлен проблемой сохранения сырья как растительного, так и...
-
К физическим методам относят консервирование с помощью низких и высоких температур, фильтрования, лучистой энергии, ультразвука, ионизирующей обработки....
-
Новые механизмы стимулирования применения инновационных рекламных продуктов
Инновационные виды рекламы активно внедряется в современных рекламных промо кампаниях. В 21 веке получило широкое распространение Just touch me -...
-
Реклама в России в советский период - История развития рекламы
Советский период был временем практического отсутствия рекламной индустрии в понимании, принятом в странах с рыночной экономикой, где она признается...
-
Оценка качества товаров Оценка качества товара по существу - это установление соответствия товара общественным потребностям. Существует некоторая...
-
Результаты пилотного опроса посетителей ресторанов - Удовлетворенность посетителей ресторанов
Перейдем к описанию результатов пилотного исследования. Как было описано выше, цель пилотажа заключалась в том, чтобы из полученного путем контекстного...
-
На данном этапе работы оценивались регрессионная модель для дальнейшего тестирования влияния различных факторов на успешное ведение бизнеса в соцсетях....
-
Эффективность маркетинга во многом зависит от того, как построена служба маркетинга в организации, какие задачи и на каком уровне она решает. При этом...
-
Методы оценки конкурентоспособности товаров и услуг Разработка проблемы конкурентоспособности товаров и услуг напрямую зависит от выбранного метода...
-
Понятие конкурентоспособности и ее значение в рыночной экономике Конкурентоспособность торговый рынок Понятие конкуренции является сложным и...
-
Методы определения конкурентоспособности - Анализ конкурентоспособности товара
Оценка конкурентоспособности с помощью товара-образца. В данном случае товар сравнивается с уже существующим на рынке и пользующимся спросом. Выбор...
-
Показатели конкурентоспособности товаров - Анализ конкурентоспособности товара
Конкурентоспособность товаров более полно раскрывается через систему ее показателей. Они представляют собой совокупность критериев количественной оценки...
-
Методы исследования целевого рынка - Розничная торговля
Для сбора информации маркетологи пользуются определенными методами. Первичные исследования - сбор данных - осуществляется по мере их возникновения с...
-
Метод экспертных оценок - Понятие и сущность маркетинга
Современная экономическая система предъявляет все более новые и более высокие требования к управлению. Совершенствование методов управления имеет большое...
-
Как уже было сказано в предыдущих частях работы, исследование включает в себя предварительный анализ данных и оценку двух эконометрических моделей. В...
-
Есть заметная разница в маркетинге на стадии исследований и проектирования продукции и на стадии обращения и эксплуатации (потребления) продукции [3]....
-
Конкурентоспособность товара -- его интегральное свойство, обусловливающее способность товара удовлетворять требованиям покупателей к его составляющим по...
-
Существует множество методик по оценке эффективности инновационных проектов, среди которых выделяют: Методические рекомендации по оценке эффективности...
Прогнозирование потребности в продукте на планируемый период - Оптимизация многономенклатурных поставок