Алгоритмы детектирования объектов на видео для мобильных платформ, Обучение с учителем и формальная запись задачи классификации - Исследование алгоритмов
Обучение с учителем и формальная запись задачи классификации
Теория машинного обучения решает задачи предсказания будущего поведения сложных систем в том случае, когда отсутствуют точные гипотезы о механизмах, управляющих поведением таких систем. Имеется ряд категорий машинного обучения: контролируемое обучение или обучение с учителем (supervised learning), неконтролируемое обучение (unsupervised learning) (в частности, кластеризация), обучение с подкреплением (reinforcement learning).
В данной работе рассматривается первый тип машинного обучения - контролируемое обучение. Оно берет начало на обучающей выборке, которая представляет собой примеры: пары вида "вход - выход". Целью обучения является восстановление зависимости между элементами этих пар с целью предсказания будущего выхода по заданному входу. В сущности, имеется два основных класса задач: задачи классификации и задачи регрессии. В данном исследовании интерес представляет задача классификации, в которой выход - это метка класса, к которому принадлежит вход [31].
Задача классификации базируется на основных идеях теории PAC-машинного обучения (Probably Approximately Correct-learning), предложенную Валлиантом [38]. В работе предлагается отойти от классической концепции этой теории; вместо этого используется постановка задачи, принятая в современной статистической теории машинного обучения.
Так, предполагается, что каждый пример X, представленный для обучения или проверки, является элементом некоторого множества X (снабженного полем борелевских множеств) и генерируется некоторым неизвестным распределением вероятностей P на X . Предполагается, что каждый пример X имеет метку Y - признак принадлежности к некоторому классу. Метки классов образуют множество D. Пары (x; y) объектов X И их меток Y одинаково и независимо распределены согласно некоторому неизвестному вероятностному распределению P на множестве. В соответствии с этим полагается, что выборка
Генерируется (порождается) некоторым источником, а на множестве задано распределение вероятностей
.
Правило или функция (гипотеза) классификации - это функция типа, которая разбивает элементы на несколько классов. Мы будем также называть функцию K классификатором, или решающим правилом. В дальнейшем будет рассмотрен случай бинарной классификации, а функция будет называться индикаторной.
В этом случае вся выборка S разбивается на две подвыборки:
Положительные примеры (или первый класс) и
- отрицательные примеры (или второй класс). Именно эта информация и подводит к физической, программной реализации алгоритма AdaBoost. Подробнее об этом рассказывается в главе 2, там же можно проследить параллели между положительными и отрицательными подвыборками S И позитивными и негативными наборами изображений для тренировки каскада.
В некоторых случаях индикаторная функция классификации K задается с Помощью некоторой вещественной функции f и числа
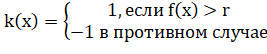
:.
Строго говоря, пары (x; y) являются реализациями случайной величины (X;Y), которая имеет распределение вероятностей P. Плотность распределения P будет обозначаться так же, как и P(x; y).
Предсказательная способность произвольной функции классификации K будет оцениваться по ошибке классификации, которая определяется как вероятность неправильной классификации:
,
Где K(X) - функция от случайной величины X, также является случайной величиной, поэтому можно рассматривать вероятность события.
Основная цель при решении задачи классификации - для заданного класса функций классификации K построить оптимальный классификатор, т. е. такую функцию классификации, при которой ошибка классификации является наименьшей в классе K.
Похожие статьи
-
В работе возникает необходимость выбора предметной области, в которой будет тестироваться каскадный классификатор. Главными вопросами на данном этапе...
-
Выбор мобильной платформы и изучение инструментов разработки - Исследование алгоритмов
Практическая реализация алгоритмов, представленных в предыдущих пунктах, предполагает: 1) Выбор мобильной платформы; 2) Изучение соответствующей среды...
-
Создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки...
-
Обучение каскадного классификатора - Исследование алгоритмов
В OpenCV есть два приложения для тренировки каскадов URL: http://docs. opencv. org/modules/objdetect/doc/cascade_classification. html?...
-
Описание деятельности ИТ-отдела компании в рамках разработки ключевых показателей эффективности является одной из важнейших частей процесса. Однако...
-
Обобщенный алгоритм решения задачи Необходимо рассчитать, какую сумму денежных средств внесет лицо, производящее оплату по 1 000 рублей ежеквартально под...
-
Для того, чтобы строить диаграммы в соответствии с рисунком 2.7, необходимо реализовать алгоритм соединения двух объектов линией. Для отображения линии...
-
Теоретические предпосылки исследования Системы поддержки принятия решений Системы поддержки принятия решений (СППР), представляют собой приложения узкого...
-
Заключение - Исследование алгоритмов
В настоящей выпускной квалификационной работе была исследована процедура обучения каскадного классификатора с целью повышения точности и вычислительной...
-
Предложенный подход к решению задач исследования Используя в качестве основы присутствующее в наличии программное обеспечение, которое применимо к...
-
В качестве доступного инструментария были рассмотрены две открытые кроссплатформенные библиотеки для разработки C++ приложений WxWidgets и Boost ,...
-
Свойства алгоритмов - Алгоритм
Данное выше определение алгоритма нельзя считать строгим - не вполне ясно, что такое "точное предписание" или "последовательность действий,...
-
Построение аналитической модели АОУ затруднено из-за отсутствия или недостатка априорной информации об объекте управления, а также из-за ограниченности и...
-
Практическая часть, Постановка задачи, Инструмент рендеринга - Моделирование эффектов
Постановка задачи В качестве практической задачи необходимо разработать следующий алгоритм. Вход: - фотография, в которую будет вставлен синтетический...
-
Классификация АИС по функциональному признаку Функциональный признак определяет назначение подсистемы, а также ее основные цели, задачи и функции....
-
На чем основана работа программы - Rational Rose для разработчиков
Итак, от общих тем перейдем непосредственно к тому, что умеет делать CASE Rational Rose. Являясь объектно-ориентированным инструментом моделирования,...
-
Геометрический метод, Двойственная задача - Линейное программирование
Применяется для задач с двумя переменными. Метод решения состоит в следующем: На плоскости строятся прямые, которые задают соответствующие ограничения:...
-
Для создания наиболее совершенных и экономичных механизмов и машин важно получить оптимальный вариант входящих в них редукторов (МЗП). Показатель, на...
-
Языки и системы программирования, их эволюция - Автоматизация решения задач пользователя
Язык программирования - это способ записи программ решения различных задач на ЭВМ в понятной для компьютера форме. Процессор компьютера непосредственно...
-
Объектом исследования является микросхема 4-х процессорной "системы на кристалле" на базе ядер 32-разрядных процессов цифровой обработки сигналов с...
-
Входная информация разделяется на условно-постоянную и оперативно-учетную информацию. - Условно-постоянная информация включает в себя справочные данные о...
-
Объектом исследования является производственная компания ООО "Элементари" (ELEMENTAREE) (http://www. elementaree. ru/). Исследования, отображаемые в...
-
Система Windows NT не является дальнейшим развитием ранее существовавших продуктов. Ее архитектура создавалась с нуля с учетом предъявляемых к...
-
Разработка интеграционных платформ началась одновременно с исследованием и развитием Интернета Вещей. Это происходило по той причине, что сама концепция...
-
Теоретические аспекты поставленной задачи В этой части проекта будут объяснены этапы применения МКЭ для плоской фермы. В первой главе было рассмотрено...
-
Описание проекта, который является объектом исследования Проект - представляет собой внедрение информационно - аналитической системы управления карьерой...
-
Технология программирования Для реализации поставленной задачи наиболее удобной парадигмой программирования будет являться объектно-ориентированная...
-
Понятие функционала, Понятие оператора - Теория множеств в теории систем
Говоря об отображении f: XY как о функции с вещественными значениями, мы не накладывали на характер элементов множества X каких-либо особых ограничений....
-
Оптимизация, оптимальное управление - Нейронные сети
Этот список можно было бы продолжить и дальше. Заметим, однако, что между всеми этими внешне различными постановками задач существует глубокое родство....
-
2.1. ИСПДн класса К3 Заказчика характеризуются сосредоточенностью на территории занимаемого Заказчиком помещения без подключения к сетям общего...
-
Архитектура разрабатываемой системы имеет два уровня: нижний - подсистема управления (датчики, микроконтроллер, исполнительные механизмы и оборудование)...
-
Описание используемых методов и алгоритмов - Выбор оптимального маршрута для строительства дороги
В данном пункте нужно проанализировать используемый алгоритм поиска кратчайшего пути. Алгоритм Дейкстры Находит кратчайший путь от одной из вершин графа...
-
Работа программы представлена на рисунке 2.3 Рис. 2.3 Кодирование и тестирование программы Программа кодировалась на языке Си++, используя библотеку Qt5x...
-
Анализ функций департаментов и отделов компании ИнПлат - это инновационная платежная компания, а так же разработчик IT - решений для банков и операторов...
-
В данной главе описан процесс создания Android-приложения, способного детектировать пешеходов в видеопотоке, используя обученный каскадный классификатор....
-
Для определения выплат по займу используется финансовая функция ПЛТ (Ставка, КПер, Пс, Бс, Тип). Определим значения параметров функции ПЛТ: Ставка =9%...
-
Сервисное обслуживание разрабатываемого ПО будет выполнять один сотрудник. Для выполнения данной работы привлечем программиста, который участвовал в...
-
Для решения трехмерной задачи упругости с помощью метода конечных элементов были заданы следующие основные параметры: [1]. Количество секций. [2]....
-
Метод конечных элементов (МКЭ) жесткости возник в аэрокосмической отрасли. Исследователи рассматривали различные подходы к анализу сложных частей...
-
Каскадный классификатор - Исследование алгоритмов
В настоящее время метод Виолы-Джонса является самым популярным методом для детектирования в силу своей высокой скорости и эффективности. В 2001 году П....
Алгоритмы детектирования объектов на видео для мобильных платформ, Обучение с учителем и формальная запись задачи классификации - Исследование алгоритмов