Каскадный классификатор - Исследование алгоритмов
В настоящее время метод Виолы-Джонса является самым популярным методом для детектирования в силу своей высокой скорости и эффективности. В 2001 году П. Виола и М. Джонс [21, 22] представили многоэтапную процедуру классификации, которая позволила существенно сократить вычислительное время. При этом качество осталось сопоставимо со многими более медленными и сложными одноэтапными классификаторами, такими как машина опорных векторов (SVM)[8], случайный лес (Random Forest)[25] и нейронные сети (ANN) [12]. На протяжении порядка 10 лет предлагались различные модификации этого метода, пригодные для решения более специфичных задач [36].
Этапами алгоритма Виолы и Джонса являются классификаторы бустинга [28] над решающими деревьями, использующими в качестве признаков характеристики Хаара. Общий подход Виолы-Джонса к детектированию объектов на изображении комбинирует четыре концепции:
- 1. Использование простых прямоугольных функций, так называемых функций Хаара; 2. Интегральное представление изображения по этим признакам для быстрого обнаружения функции; 3. Использование метода построения классификатора на основе алгоритма адаптивного бустинга AdaBoost, реализующего концепцию машинного обучения; 4. Применение метода комбинирования классификаторов в каскадную структуру для эффективного совмещения множественных функций.
Именно эти идеи позволяют осуществлять детектирование объекта в режиме реального времени [2].
1. Признаки Хаара
Признаки Хаара (Haar-Like features) представляют собой двоичную аппроксимацию вейвлета Хаара. Каждый признак представляет собой двоичную маску, т. е., черно-белое изображение. В исходных работах [28] использовалось лишь несколько типов характеристик Хаара (рис. 1.1, пп. 1, 2). В более поздних работах [29], представляющих расширенный метод Виолы-Джонса, набор характеристик Хаара был дополнен наклонными характеристиками (рис. 1.1, п.3).
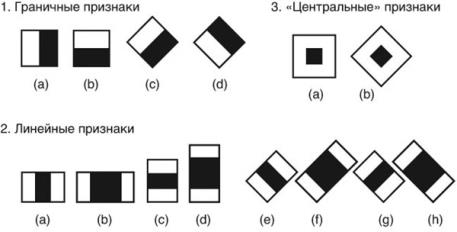
Рисунок 1.1. Признаки Хаара
Характеристику Хаара можно определить как функцию F от суммарной интенсивности и двух прямоугольных участков изображения A и B таких, что участок A вложен в участок B. Прямоугольная форма участков выбрана затем, чтобы можно было применить технику интегральных изображений [18, 22] для расчета суммарных интенсивностей в них. В современных работах используется характеристика вида
,
Где и - константы. Поэтому применение алгоритма Виолы и Джонса требует корректировки освещения:
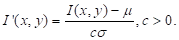
Здесь - интенсивность в точке (x, y), - оценочная дисперсия, - оценочное среднее значение интенсивности по некоторой окрестности, C - положительная константа, которую обычно полагают равной двум [6].
Поскольку признаки Хаара мало подходят для обучения или классификации, для описания объекта с достаточной точностью необходимо большее число признаков. На этапе обнаружения в методе Виолы--Джонса используется окно определенного размера, которое движется по изображению. Признак Хаара рассчитывается для каждой области изображения, над которой проходит окно. Для того, чтобы рассчитать яркость прямоугольного участка изображения, используют интегральное представление. Этот способ позволяет эффективно определять наличие и отсутствие сотен функций Хаара на каждой локации изображении и в нескольких масштабах. Интегральное представление изображения представляет собой матрицу, совпадающую по размерам с исходным изображением. В каждом ее элементе хранится сумма интенсивностей всех пикселей, находящихся левее и выше данного элемента. Элементы матрицы рассчитываются по следующей формуле:
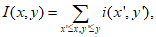
Где I(x, y) - значение точки (x, y) интегрального изображения; I(x, y) - значение интенсивности исходного изображения.
Каждый элемент матрицы I(x, y) представляет собой сумму пикселей в прямоугольнике от I(0,0) до I(x, y), т. е. значение каждого элемента I(x, y) равно сумме значений всех пикселей левее и выше данного пикселя I(x, y). Расчет матрицы занимает линейное время, пропорциональное числу пикселей в изображении и его можно производить по следующей формуле:
Наличие или отсутствие объекта в окне определяется разницей между значением признака и обучаемым порогом, то есть посредством вычитания среднего значения области темных пикселей из среднего значения области светлых пикселей, то есть вычисляемым значением такого признака будет:
F = U - V,
Где U - сумма значений яркостей точек, закрываемых светлой частью признака, а V - сумма значений яркостей точек, закрываемых темной частью признака. Если разница превышает порог, то говорят, что функция является существующей.
Преимущество использования признаков Хаара является наибольшая, по сравнению с остальными признаками, скорость. При использовании интегрального представления изображения, признаки Хаара могут вычисляться за постоянное время.
Таким образом, признаки Хаара организованы в каскадный классификатор.
2. Алгоритм AdaBoost
В основе формирования каскада классификаторов Хаара лежит алгоритм adaptive boosting'a (адаптивного усиления), или сокращенно AdaBoost (мета-алгоритм, предложенный Йоавом Фройндом (Yoav Freund) и Робертом Шапиром (Robert Schapire), [10]). AdaBoost комбинирует T "слабых" классификаторов с целью создания одного "сильного" классификатора. "Слабым" здесь считается такой классификатор, который получает правильный ответ не намного чаще, чем при случайном угадывании. Но если имеется множество таких слабых классификаторов, и каждый из них выдвигает окончательный ответ примерно в верном направлении, можно получить серьезную, комбинированную силу для достижения корректного решения. AdaBoost выбирает набор слабых классификаторов для объединения и присваивает каждому из них свой вес. Эта взвешенная комбинация и является сильным классификатором.
На данный момент наиболее распространенными вариантами базового алгоритма являются Gentle AdaBoost и Real AdaBoost, превосходящие базовый алгоритм по своим характеристикам, но сохраняющие все основные принципы [10].
Общая идея алгоритма заключается в следующем:
- 1. Требуется: построить классифицирующую функцию, где X - пространство векторов признаков, Y - пространство меток классов. 2. Имеется: 2.1. Обучающая выборка (x1, y1), ..., (xN, yN), Где I - номер признака, - вектор признаков, а - бинарная метка класса, , к которому принадлежит(для других boosting-алгоритмов может быть диапазон значений меток). 2.2. Семейство классифицирующих функций ; 2.3. Начальное распределение, для I=1,...,N, т. е. оно должно быть инициализировано заранее; сообщает, сколько стоит неправильная оценка каждого признака. 3. Для каждого шага m=1,2,...,M строится итеративный процесс вида: 3.1. Выбирается наилучший на текущем распределении слабый классификатор :
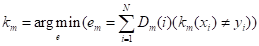
,
То есть тренируется
,
Минимизирующий взрешенную ошибку классификации
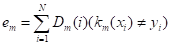
,
Пока
>0,5, иначе выход;
3.2. Вычисляется коэффициент
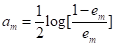
,
Показывающий вклад текущего слагаемого классифицирующей функции;
3.3. Добавляется слагаемое
,
Вычисляемое с учетом работы уже постороенной части классификатора;
3.4. Обновляется распределение (весовые коэффициенты для признаков):
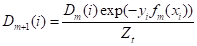
,
Где - нормализующий по всем признакам коэффициент, такой, что
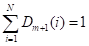
.
Вес каждого элемента обучающей выборки на текущем шаге задает "важность" этого примера для очередного шага обучения алгоритма. Чем больше вес, тем больше алгоритм будет стараться на данном шаге классифицировать этот пример правильно. Как видно из формулы, чем уверенней пример распознается предыдущими шагами, тем его вес меньше - таким образом, самые большие веса получают примеры, которые предыдущими шагами были классифицированы неверно.
Проще говоря, веса варьируются таким образом, чтобы классификатор, включенный в комитет на текущем шаге, концентрировался на примерах, с которыми предыдущие шагами не справились.
Таким образом, на каждом шаге мы работаем с какой-то частью данных, плохо классифицируемой предыдущими шагами, а в итоге комбинируем все промежуточные результаты. Процесс продолжается до некоторого шага M, номер которого определяется вручную. По окончании описанного алгоритма составляется комитет (сильный классификатор): берется новый входной вектор X и классифицируется на основе взвешенной суммы
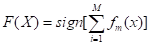
.
Очевидно, что ключевой особенностью boosting-а является то, что, когда алгоритм прогрессирует, эта стоимость будет развиваться так, что обучение "слабых" классификаторов будет сфокусировано на тех признаках, которые ранее в "слабых" классификаторах давали плохие результаты [2].
Однако стоит признать, что конвергенция на учебном этапе этого алгоритма во многом зависит от обучающих данных, точность прогнозирования также остается низкой. К другим недостаткам алгоритма относятся:
- 1) Склонность к переобучению при наличии значительного уровня шума в данных; 2) Требование большой выборки данных, больших объемов памяти для хранения базовых алгоритмов и существенных затрат времени на вычисление классификаций; 3) Жадная стратегия последовательного добавления приводит к построению неоптимального набора базовых алгоритмов.
В связи с этим оптимальным решением станет параллельное изучение и реализация другого метода для последующего сравнения их эффективности. AdaBoost является одним из самых популярных алгоритмов бустинга, но существуют и другие методы, как, например, AnyBoost (бустинг как процесс градиентного спуска), LogitBoost, BrownBoost, TotalBoost, MadaBoost и другие. В работе описан метод, основанный на локальных бинарных шаблонах.
3. Локальные бинарные шаблоны
Оператор LBP (Local Binary Patterns, локальные бинарные шаблоны) впервые был предложен T. Ojala в 1996 году [20]. Базовый оператор LBP, применяемый к пикселю изображения, использует восемь пикселей окрестности, принимая значение интенсивности центрального пикселя в качестве порога. Он представляет каждый пиксель изображения в виде бинарного числа: пиксели со значением интенсивности большим или равным значению интенсивности центрального пикселя принимают значения равные "1", остальные принимают значения равные "0" (рис. 1.2). Описание восьми пикселей окрестности в двоичном представлении и есть локальный бинарный шаблон (рис. 1.3).
Таким образом, результатом применения базового оператора LBP к пикселю изображения является восьмиразрядный бинарный код, который описывает окрестность этого пикселя. Использование круговой окрестности и билинейной интерполяции значений интенсивностей пикселей позволяет построить локальный бинарный шаблон с произвольным количеством точек P и радиусом R.
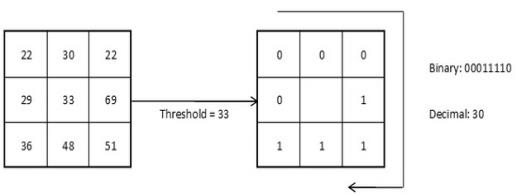
Рисунок 1.2. Базовый оператор LBP
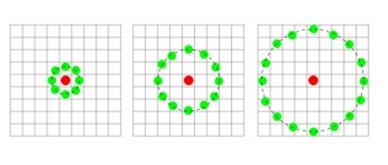
Рисунок 1.3. Графическое представление базового и расширенных операторов LBP
При работе с этим оператором учитывается, что некоторые бинарные коды несут в себе больше информации, чем остальные (равномерные LBP определяют важные локальные особенности изображения, такие как концы линий, грани, углы и пятна и обеспечивают существенную экономию памяти).
Применяя оператор LBP к каждому пикселю изображения, можно построить гистограмму, в которой каждому равномерному коду LBP соответствует отдельный столбец. Также имеется еще один дополнительный столбец, который содержит информацию обо всех неравномерных шаблонах [14].
Основной целью алгоритма является вычисление меры различия гистограмм сопоставляемых изображений и построение соответствующего решающего правила. Существует множество подходов: это и взвешенное расстояние Кульбака-Лейблера (областям назначаются веса в соответствии с важностью информации, которую они несут), и расстояние Махаланобиса (создание векторов различий двух изображений), и применение линейного дискриминанта Фишера, а также некоторые другие.
Похожие статьи
-
В работе возникает необходимость выбора предметной области, в которой будет тестироваться каскадный классификатор. Главными вопросами на данном этапе...
-
Обучение каскадного классификатора - Исследование алгоритмов
В OpenCV есть два приложения для тренировки каскадов URL: http://docs. opencv. org/modules/objdetect/doc/cascade_classification. html?...
-
Заключение - Исследование алгоритмов
В настоящей выпускной квалификационной работе была исследована процедура обучения каскадного классификатора с целью повышения точности и вычислительной...
-
Выводы по результатам тестирования - Исследование алгоритмов
По полученным в ходе анализа данным сделать вывод о качестве обученных каскадных классификаторов и о причинах таких результатов, а также выяснить, какие...
-
Введение - Исследование алгоритмов
С недавнего времени такая область кибернетики, как создание искусственных систем распознавания образов, стала представлять особый интерес. Потребность в...
-
Программа экспериментальных исследований В предыдущей главе была описана процедура создания приложения, а также его структура и интерфейс. В данной главе...
-
В данной главе описан процесс создания Android-приложения, способного детектировать пешеходов в видеопотоке, используя обученный каскадный классификатор....
-
Выбор мобильной платформы и изучение инструментов разработки - Исследование алгоритмов
Практическая реализация алгоритмов, представленных в предыдущих пунктах, предполагает: 1) Выбор мобильной платформы; 2) Изучение соответствующей среды...
-
В настоящее время биометрия входит в состав наиболее распространенных технологий и средств защиты информации. Отпечатки пальцев являются самой широко...
-
Обучение с учителем и формальная запись задачи классификации Теория машинного обучения решает задачи предсказания будущего поведения сложных систем в том...
-
Исследования временных затрат алгоритмов - Алгоритмы нескольких махов
Исследования временных затрат алгоритмов были проведены для трех вариантов программ: LBFS4, LBFS3, MNS3; для двух вариантов сборки исполняемого файла:...
-
Описание проведенных экспериментов - Исследование алгоритмов
1) Эксперимент №1. Детектирование множества объектов. Детектирование множества объектов - задача, с которой работающее приложение должно справляться при...
-
Структура и интерфейс программы - Исследование алгоритмов
В этой части работы описывается процесс создания мобильного приложения на платформе Android, способного использовать обученные каскадные классификаторы...
-
Для создания трехмерной реконструкции сцены или объекта необходимо создать его трехмерную модель и вычислить цвет ее вершин. Для геометрической...
-
Методы изображение алгоритмов - Алгоритм
На практике наиболее распространены следующие формы представления алгоритмов: 12. словесная (записи на естественном языке); 13. графическая (изображения...
-
Исследование математических моделей - Информационные модели
На языке алгебры формальные модели записываются с помощью уравнений, точное решение которых основывается на поиске равносильных преобразований...
-
Приложение, которое необходимо разработать, должно производить геометрическую реконструкцию сцены и вычисление цвета вершин модели. Для геометрической...
-
В основе алгоритма лежит численное исследование пространства управляемых параметров редуктора. Процесс поиска оптимального решения выполняется за четыре...
-
Свойства алгоритмов - Алгоритм
Данное выше определение алгоритма нельзя считать строгим - не вполне ясно, что такое "точное предписание" или "последовательность действий,...
-
Задание: 1. Прочитать текст "Алгоритм и его свойства", в таблице №1 "Алгоритм и его свойства" проверьте правильное заполнение таблицы. Запишите в тетрадь...
-
В алгоритме Zhou&;Koltun при вычислении отклонений цвета используется изображение, переведенное в градации серого. В данной реализации используется...
-
Для вычисления цвета могут быть использованы различные подходы. Вычисление цвета может проводиться одновременно с геометрической реконструкцией,...
-
Предложенный подход к решению задач исследования Используя в качестве основы присутствующее в наличии программное обеспечение, которое применимо к...
-
Теоретические предпосылки исследования Системы поддержки принятия решений Системы поддержки принятия решений (СППР), представляют собой приложения узкого...
-
Под критическим значением параметра регулятора (K или Т) понимается такое значение (Ккр или Ткр), при котором система оказывается на границе...
-
Для того, чтобы строить диаграммы в соответствии с рисунком 2.7, необходимо реализовать алгоритм соединения двух объектов линией. Для отображения линии...
-
Обобщенный алгоритм решения задачи Необходимо рассчитать сумму налога на дарение, воспользовавшись налоговой шкалой. Если сумма подарка менее 80, то она...
-
Транспортная задача оптимальность Поставим в соответствие поставщикам потенциалы Ui, , а потребителям - Vj, . В оптимальном плане для всех базисных...
-
ОСОБЕННОСТИ РЕАЛИЗАЦИИ АЛГОРИТМОВ - Структуры и алгоритмы обработки данных
В ходе выполнения курсовой работы, помимо основных алгоритмов, потребовалось реализовать также несколько вспомогательных, необходимых для корректной...
-
Графический способ описания алгоритмов
Графический способ описания алгоритмов Цель практической работы Цель работы: изучение графического способа описания алгоритма для решения задачи. Задачи...
-
Цель Работы - изучить основные способы работы с пользовательским типом данных "класс", его объектами, методами и способы доступа к ним. - Теоретические...
-
Цель Работы - научиться использовать операции динамического выделения и освобождения памяти на примере работы с одномерными и двумерными массивами, а...
-
Онлайн исследования в социологии: новые методы анализа данных - Распространение новостной информации
На сегодняшний день анализ социальных сетей и медиа, Интернет-сообществ, пользователей в целом используется в основном в маркетинге. Компания может...
-
Общее описание программного обеспечения, реализующего разработанный алгоритм Основной идеей дипломного проекта, является реализация алгоритма...
-
Данный алгоритм (англ. Maximal Neighborhood Search - MNS) [7] в отличие от алгоритма BFS позволяет дополнительно упорядочить вершины в найденных...
-
Алгоритм LZ78 - Анализ алгоритма Лемпеля-Зива
Этот алгоритм генерирует на основе входных данных словарь фрагментов, внося туда фрагменты данных (последовательности байт) по определенным правилам (см....
-
Идея алгоритма Лемпеля-Зива, Алгоритм LZ77 - Анализ алгоритма Лемпеля-Зива
Основная идея алгоритма Лемпеля-Зива состоит в замене появления фрагмента в данных (группы байт) ссылкой на предыдущее появление этого фрагмента....
-
Сжатие данных можно разделить на два основных типа: 1) Сжатие без потерь или полностью обратимое; 2) Сжатие с потерями, когда несущественная часть данных...
-
Методы разработки вычислительной сети: 1. Экспериментальный метод - персонал предприятия закупает "новинки" рынка компьютерной техники. Такой метод -...
-
В этом разделе намеренно допущено отступление от общей методики - не смешивать разные компоненты. Это сделано для облегчения демонстрации построения...
Каскадный классификатор - Исследование алгоритмов