Введение - Построение декодера Рида - Маллера
В последнее время передача данных является наиболее быстро развивающейся областью техники. И это не случайно. Всем известно выражение: "Кто владеет информацией, тот правит миром". Спутниковая связь, локальные и глобальные сети, волоконно-оптическая технология, цифровые сети, сотовая телефонная связь, цифровая сеть с интеграцией служб и модель взаимодействия открытых систем - все это далеко не полный список примеров быстрого развития отрасли связи.
Но во всех этих отраслях существует одна и та же проблема - возникновение ошибок при передаче информации. Решение этой проблемы комплексно, оно включает в себя огромное число всевозможных технических решений, но одним из самых главных, эффективных и дешевых является помехоустойчивое кодирование.
История помехоустойчивого кодирования началась в 1948г. публикацией знаменитой статьи Клода Шеннона. Шеннон показал, что с каждым каналом связано измеряемое в битах в секунду и называемое пропускной способностью канала число С, имеющее следующее значение. Если требуемая от системы связи скорость передачи информации R (измеряемая в битах в секунду) меньше С, то, используя помехоустойчивые коды, для данного канала можно построить такую систему связи, что вероятность ошибки на выходе будет сколь угодно мала [1]. Из теории Шеннона следует, что построение слишком хороших каналов связи является расточительством, экономически выгодней использовать помехоустойчивое кодирование. Шеннон, однако, не показал, как найти подходящие коды, а лишь доказал их существование. В пятидесятые годы много усилий было потрачено на попытки построения в явном виде классов кодов, позволяющих получить обещанную сколь угодно малую вероятность ошибки, но результаты были скудными. В следующем десятилетии решению этой увлекательной задачи уделялось меньше внимания, вместо этого исследователи кодов предприняли длительную атаку по двум направлениям.
Первое направление носило чисто алгебраический характер и преимущественно рассматривало блоковые коды. Первые блоковые коды были введены в 1950г., когда Хэмминг описал класс блоковых кодов, исправляющих одиночные ошибки. Коды Хэмминга были разочаровывающе слабы по сравнению с обещанными Шенноном гораздо более сильными кодами. Несмотря на усиленные исследования, до конца пятидесятых годов не было построено лучшего класса кодов. В течение этого периода без какой-либо общей теории были найдены многие коды с малой длиной блока. Основной сдвиг произошел, когда Боуз и Рой-Чоудхури и Хоквингем[1] нашли большой класс кодов, исправляющих кратные ошибки (коды БЧХ), а Рид и Соломон [1960] нашли связанный с кодами БЧХ класс кодов для недвоичных каналов. Хотя эти коды остаются среди наиболее важных классов кодов, общая теория помехоустойчивых блочных кодов с тех пор успешно развивалась, и время от времени удавалось открывать новые коды.
Второе направление исследований по кодированию носило скорее вероятностный характер. Ранние исследования были связаны с оценками вероятностей ошибки для лучших семейств блоковых кодов, несмотря на то что эти лучшие коды не были известны. С этими исследованиями были связаны попытки понять кодирование и декодирование с вероятностной точки зрения, и эти попытки привели к появлению последовательного декодирования. В последовательном декодировании вводится класс неблоковых кодов бесконечной длины, которые можно описать деревом и декодировать с помощью алгоритмов декодирования по дереву. Наиболее полезными древовидными кодами являются коды с тонкой структурой, известные под названием сверточных кодов. Эти коды можно генерировать с помощью цепей линейных регистров сдвига, выполняющих операцию свертки информационной последовательности. В конце 50-х годов для сверточных кодов были успешно разработаны алгоритмы последовательного декодирования. Наиболее простой алгоритм декодирования - алгоритм Витерби - для этих кодов был разработан только в 1967г.
В 70-х годах эти два направления исследований опять стали переплетаться. Теорией сверточных кодов занялись алгебраисты, представившие ее в новом свете. В теории блоковых кодов за это время удалось приблизиться к кодам, обещанным Шенноном: были предложены две различные схемы кодирования (одна Юстесеном, а другая Гоппой), позволяющие строить семейства кодов, которые одновременно могут иметь очень большую длину блока и очень хорошие характеристики. Различного рода исследования помехоустойчивых кодов активно продолжаются до сих пор.
В данном курсовом проекте необходимо разработать декодер кода Рида - Маллера с параметрами (n, k) = (32, 26).
Коды Рида - Маллера (РМ коды) являются одним из наиболее старых и хорошо изученных семейств кодов. Минимальное расстояние РМ кодов меньше, чем минимальное расстояние кодов БЧХ, за исключением кодов первого порядка и кодов с умеренными длинами. Однако большим достоинством РМ кодов является то, что они достаточно просто декодируются при помощи мажоритарно-логических устройств. Интересной особенностью кодов Рида - Маллера является то, что код Рида - Маллера r-го порядка дуален коду Рида - Маллера (m - r - 1)-го порядка
РМ коды являются простейшим примером класса геометрических кодов. Этот класс содержит также евклидово-геометрические и проективно - геометрические коды. Все коды этого класса допускают мажоритарное декодирование.
Коды Рида - Маллера характеризуются следующими параметрами[2]:
R - порядок кода, m - некоторое число, большее r, причем:
N = 2M (1),
D0 = 2M-r (2),
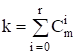
(3),
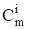
Где - число сочетаний i по m.
Код Рида - Маллера может исправлять следующее число ошибок[2]:
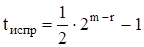
(4).
Похожие статьи
-
Заключение - Построение декодера Рида - Маллера
В этом курсовом проекте мы досконально изучили код Рида - Маллера, ознакомились с историей его открытия Ридом и Маллером, а так же краткой историей всего...
-
Основные сведения о коде - Построение декодера Рида - Маллера
За время исследования помехоустойчивых кодов была наработана огромная теория и выстроена сложнейшая математическая база помехоустойчивого кодирования....
-
На выбор типа кода повлиял тот факт, что коды Рида - Маллера являются одним из наиболее старых и хорошо изученных семейств кодов. Хотя минимальное...
-
Алгоритм работы декодера кода Рида - Маллера будем разрабатывать на основе уже приведенных выше уравнений. Алгоритм приведен на рисунке 12. В начале...
-
Разработка функциональной электрической схемы декодера - Построение декодера Рида - Маллера
При разработке функциональной схемы рассмотрим каждый блок структурной схемы подробнее. Входной регистр. Входной регистр служит для приема всех бит...
-
Введение - Программа построения равновесных стратегий для игры
Игра стратегия математический С появлением компьютеров широкое развитие получила тема искусственного интеллекта. Одним из направлений искусственного...
-
Введение - Роль ключевых предложений в построении текста
Постоянное увеличение объемов существующей в мире информации является вполне естественным процессом. В его основе лежат как стремительно развивающийся...
-
Литература - Построение декодера Рида - Маллера
1. Блейхут Р. Теория и практика кодов, контролирующих ошибки. Москва: Мир, 1986 г. 2. Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих...
-
Каждая диаграмма состояний в UML описывает все возможные состояния одного экземпляра определенного класса и возможные последовательности его переходов из...
-
Принцип построения помехоустойчивых кодов - Кодек каскадного кода Хэмминга
Помехоустойчивое кодирование представляет собой процесс преобразования передаваемых информационных символов по определенному алгоритму, и в результате...
-
Введение - Программа расчета агрегатов по накапливающимся данным для построения отчетов
Бесчисленное количество веб-приложений полагается на базы данных. Нередко архитектура этих баз данных недальновидна с самого начала, а постоянно...
-
Введение, РЕКУРСИЯ - Рекурсивное программирование
Основой для разработки рекурсивных алгоритмов служат, так называемые, Рекуррентные соотношения (формулы), устанавливающие зависимость между результатами...
-
Введение, Общие сведения о локальных сетях - Разработка локальной сети для ОАО "Корпорация Монстров"
Общие сведения о локальных сетях Локальный сеть вычислительный сервер Локальная Сеть (локальная вычислительная сеть, ЛВС) - это комплекс оборудования и...
-
Введение - Обьекто-ориентированное программирование
Объектно-ориентированное программирование (ООП) позволяет разложить проблему на составные части, каждая из которых становится самостоятельным объектом....
-
Роль ключевых предложений в построении текста В первую очередь введем несколько базовых понятий рассматриваемой предметной области: текст, сложное...
-
Разработка кодера Хемминга Кодирующее устройство предназначено для кодирования исходной последовательности информационных символов. Для того, чтобы...
-
Введение - Поиск информации в сети Интернет
Сеть Интернет похожа на огромную мировую библиотеку, имеющую только одно, но существенное отличие: для поиска книги в библиотеке есть каталог, в крайнем...
-
Введение, Понятие информационных ресурсов общества - Информационные ресурсы общества
Понятие "информационного ресурса общества" (ИРО) является одним из ключевых понятий социальной информатики. Широкое использование этого понятия началось...
-
Построение модели - Построение модели сердца
В нашей модели должны присутствовать две переменные состояния - х и b, и два параметра - х0 и eps, где х0 - начальное значение х. Начальное значение...
-
Введение - Карманный персональный компьютер
Данная тема работы была выбрана мной из-за стремительного развития карманных компьютеров. Наверняка все стали замечать, что рынок карманных компьютеров...
-
Обзор структуры каталогов, Введение - Операционная система Linux
В этой главе рассмотрены наиболее важные составляющие структуры каталогов системы Linux, основанные на стандарте FSSTND. Также в общих чертах описывается...
-
Введение - Пользовательский контент
Мы живем в информационную эру -- эпоху, когда информация и знания представляют высшую ценность в обществе, а также, которая отличается практически...
-
Построение дерева - Деревья решений
Пусть нам задано некоторое множество T, содержащее объекты, каждый из которых характеризуется m атрибутами, причем один из них указывает на...
-
Введение - Разработка мобильного приложения расчета и учета оплаты коммунальных услуг
В настоящее время трудно представить свою жизнь без мобильного телефона. Если раньше он был атрибутом деловых людей, то сейчас есть практически у всех....
-
Введение - Информационная система Вуза
Одним из важнейших условий обеспечения эффективного функционирования любой организации является наличие развитой автоматизированной информационной...
-
Описанный метод, по сути, анализирует поведение веб-приложения на предмет совершения недопустимых относительно профиля нормального поведения операций....
-
Введение - Технология разработки программного обеспечения систем управления
С++ является языком объектно-ориентированного программирования (ООП). Объект - абстрактная сущность, наделенная характеристиками объектов реального мира....
-
Введение - Звуковая карта, ее применение
Взаимодействие человека с ЭВМ должно быть, прежде всего, взаимным (на то оно и общение). Взаимность, в свою очередь, предуcматривает возможность общения...
-
Для оценки возможности выполнения проекта имеющимся в распоряжении разработчика штатным составом исполнителей, нужно рассчитать их среднее количество,...
-
3. Построение графиков функций - Основы информатики
3.1 Построить в разных системах координат при х Є [-3.2; -1] графики следующих функций: G = , z = , y = . Решение: Для того, чтобы построить график...
-
Сеансовый уровень, Представительный уровень - Принципы построения открытых графических систем
Сеансовый уровень (Session layer) обеспечивает управление диалогом: фиксирует, какая из сторон является активной в настоящий момент, предоставляет...
-
Сетевой уровень - Принципы построения открытых графических систем
Сетевой уровень (Network layer) служит для образования единой транспортной системы, объединяющей несколько сетей, причем эти сети могут использовать...
-
Канальный уровень - Принципы построения открытых графических систем
На физическом уровне просто пересылаются биты. При этом не учитывается, что в некоторых сетях, в которых линии связи используются (разделяются)...
-
Концентраторы - Построение локальных сетей по стандартам физического и канального уровней
Основные и дополнительные функции концентраторов Практически во всех современных технологиях локальных сетей определено устройство, которое имеет...
-
Рассмотрим замкнутую сеть массового обслуживания с разнотипными заявками, которая является вероятностной моделью обслуживания заявок в УП "Проектный...
-
Введение - Создание электронного учебника (по HTML) в редакторе Microsoft Front Page
Современная система образования все активнее использует информационные технологии и компьютерные телекоммуникации. Особенно динамично развивается система...
-
Введение - Разработка ключевых показателей эффективности для ИТ-отдела организации
Появление новых неблагоприятных условий на рынке (кризис, санкции) заставляет руководителей по-новому взглянуть на управление предприятием. Руководство...
-
ВВЕДЕНИЕ - Анализ алгоритма Лемпеля-Зива
Одна из задач любой информационной системы обеспечивать хранение и передачу информации. Причем хранение и передача информации занимают определяющее место...
-
Введение - Компьютерная графика
Представление данных на мониторе компьютера в графическом виде впервые было реализовано в середине 50-х годов для больших ЭВМ, применявшихся в научных и...
-
Введение - Поиск, накопление и обработка информации
Умственный труд в любой его форме всегда связан с поиском информации. Тот факт, что этот поиск становится сейчас все сложнее и сложнее, в доказательствах...
Введение - Построение декодера Рида - Маллера