Кластеры бизнес-процессов и метрики их анализа - Программа анализа матриц типа "функции-данные" и интерпретации деревьев бизнес-процессов
Кластер представляет собой набор бизнес-процессов, использующих общие элементы данных:
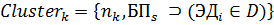
,
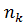
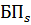
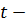
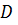
Где - наименование кластера, k - количество кластеров, - бизнес-процесс, , количество бизнес-процессов в кластере, - множество элементов данных, которые и пользуют бизнес-процессы кластера, i - количество элементов множества
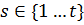
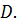
Кластеры обладают следующими свойствами:
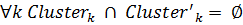
. Это означает, что кластеры не имеют пересечений по используемым элементам данных.
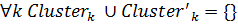
. Это означает, что объединение кластеров эквивалентно их сложению.
Алгоритм кластеризации, выведенный на основании определения (10), выглядит следующим образом:
- 1: for all business_processes i do 2: for all clusters j do 3:if (intersect(business_processes[i].datums, 4:clusters[j].datums).Count > 0) 5:clusters[j].Add (business_processes[i]) 6:else 7:clusters. AddNewCluster(business_processes[i]); 8: end for 9: end for
Схема 1. Псевдокод алгоритма кластеризации.
В своей работе [6], посвященной выделению сервисов на основе описания архитектуры данных в виде CRUD-матриц с помощью кластеризации, Джамшиди и Мансур выделили ряд метрик, позволяющих оценить выделенные сервисы. После подробного изучения данной работы было принято решение о корректности использования этих метрик в данной работе:
Total Semantic Relationship (TSR). Данная метрика определяется общей суммой семантических отношений кластера:
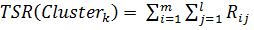
,
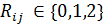
Где k - количество кластеров, m - количество бизнес-процессов в кластере, l - количество ЭД, используемых бизнес-процессом, . Метрика позволяет оценить уровень воздействия на информационные объекты. Влияет на критерий: Уровень взаимодействия с информационными объектами (см. Глава 1).
Internal Semantic Dependency (ISR). Данная метрика определяет связь между парой бизнес-процессов внутри кластера. Значение метрики определяется суммой значений семантических отношений между двумя бизнес-процессами и отражается в матрице зависимостей бизнес-процессов MЗ:
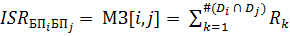
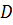
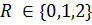
Где i, j - номера элементов в матрице МЗ, - множество элементов данных, используемых бизнес-процессом, . Влияет на критерий: Связность бизнес-процессов. Пример матрицы зависимостей бизнес-процессов представлен на Рисунке 4 .
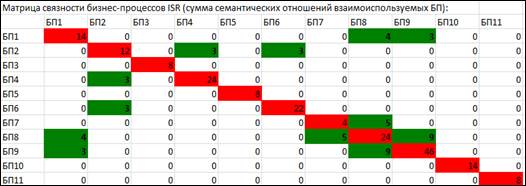
Рисунок 4. Пример матрицы зависимостей бизнес-процессов, созданной в программе
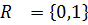
External Semantic Dependency (ESR). Данная метрика определяет зависимость элементов данных от внешних информационных объектов и выражается в количестве внешних элементов данных (), используемых бизнес-процессами в кластере:
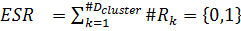
,
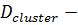
Где количество элементов данных, используемых бизнес-процессом в кластере. Влияет на критерий: Зависимость от внешних данных
Считаем, что распределение метрики по кластерам является нормальным [6]. Отклонение от метрики определяется стандартным среднеквадратичным отклонением:
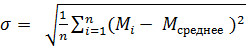
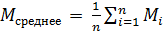
, ,
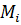
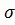
Где n - количество кластеров, - значение метрики для i - кластера. Значительным отклонением по метрике, требующим внимания аналитика, будем считать 2.
Также особое внимание стоит обратить на кластеры, которые содержат в себе всего один бизнес-процесс. С большой вероятностью, такой бизнес-процесс либо автоматизирован для специфической задачи, либо данное описание не было удалено после редуцирования более крупных элементов.
В данной главе было рассмотрено описание матриц "функции-данные", выделены методы выявления неточностей, способ и метрики кластерного анализа. Приведенные описания и формулы являются логической и математической базой для написания программы.
Глава 3
В этой главе рассматривается описание инструментов и методов, которые были использованы при разработке программы. Особое внимание уделяется описанию технологии OpenXML и особенностям разработки с использованием модели MVVM.
Похожие статьи
-
Введение - Программа анализа матриц типа "функции-данные" и интерпретации деревьев бизнес-процессов
В настоящее время трудно представить организацию, не использующую в своей деятельности информационные системы, начиная от простых электронных таблиц и...
-
Матрицы типа "функции-данные" являются внутренним инструментом описания бизнес-процессов в организации ООО "РН-Информ" и являются вариацией CRUD-матриц....
-
Так как матрица типа "функции-данные" является подвидом CRUD-матриц, сначала необходимо разобраться, что из себя представляет данный метод; затем...
-
Выходные данные для работы программы представляют собой матрицу типа "функции-данные", где связь бизнес-функций и элементов данных описывается большим...
-
Для перехода к описанию выбора средств разработки, необходимо выделить этапы работы программы. Алгоритм работы программы представлен ниже: Пользователь...
-
MVVM - Программа анализа матриц типа "функции-данные" и интерпретации деревьев бизнес-процессов
При проектировании визуализации была использована модель Model-View-ViewModel (MVVM) [1]- основной паттерн, используемый при работе с Windows...
-
С увеличением размерности таблицы существенно возрастает вероятность появления некорректных данных, так как таблица заполняется вручную. При средней...
-
За последние годы было разработано большое количество методологий и стандартов построения и описания различных уровней архитектуры организации, в том...
-
Анализ модели архитектуры данных организации является важной и трудоемкой задачей, позволяющей выявить существующие недостатки архитектуры. Также такой...
-
Автоматизированный управление финансы В динамичных условиях развития потребительского спроса в сфере информационных технологий (далее ИТ), создается...
-
В данной части работы, рассмотрим необходимое программное обеспечение для распознавания и перевода вышеприведенных документов из графического формата в...
-
В данной главе проводится анализ деятельности кафедры информационных технологий в бизнесе. Анализ показывает, насколько важен процесс поиска для...
-
ОСНОВНЫЕ ПРОГРАММЫ АРХИВАТОРЫ И ИХ ФУНКЦИИ - Архивация информации и программы-архиваторы
Назначение программ-архиваторов заключается в экономии места на диске за счет сжатия (упаковки) одного или нескольких файлов в архивный файл....
-
, Алгоритм обратного хода: Шаг 1. Вычислим Шаг 2. Вычислим: , Рис. 1. Основной алгоритм решения СЛУ методом исключения Гаусса. Для контроля правильности...
-
Описание и использование процедур и функций Подпрограмма - это часть программы, оформленная в виде отдельной синтаксической конструкции и снабженная...
-
Необходимо исследовать зависимость влияния различных факторов на параметр, характеризующий производство. В качестве такого параметра было выбрано...
-
Обзор протокола Multi-Touch технологий передачи данных TUIO [7] - основной кроссплатформенный протокол с открытым исходным кодом Multi-Touch передачи...
-
Описание модулей программы Проект приложения содержит следующие модули. Модуль UnitCollection. pas содержит описание классов для работы с коллекцией и...
-
Понятие о массивах В ранжированных переменных невозможно использование их отдельных значений. При необходимости иметь доступ к каждому значению...
-
По результатам данного исследования необходимо выявить недостатки и ограничения существующих технологий интеграции. Для проведения исследования...
-
Различные версии продуктов системы программ 1С: Предприятия могут использоваться в организациях с различными объемами информации, различным количеством...
-
Моделирование параллельных программ Рассмотренная схема проектирования и реализации параллельных вычислений дает способ понимания параллельных алгоритмов...
-
В автоматизируемых процессах участвуют сотрудники департамента IT и департамента коммерции. Процесс направлен на внедрение платежной системы клиенту....
-
Анализ функций департаментов и отделов компании ИнПлат - это инновационная платежная компания, а так же разработчик IT - решений для банков и операторов...
-
В выпускной квалификационной работе предметом исследования является деятельность по учету и управлению доставкой корреспонденции. Для того, чтобы...
-
Внедрение данной программы на производстве позволит значительно сократить время на обработку заказов, а значит добиться снижения расхода энергии...
-
Создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки...
-
Построение модели предметной области с помощью описания структур данных и программного кода является классическим подходом в разработке ИС. Зачастую...
-
Антивирусные программы Для обнаружения, удаления и защиты от компьютерных вирусов разработано несколько видов специальных программ, которые позволяют...
-
Функциональное назначение программы Основной функцией программы "AdressBook. exe" является ведение справочника. Имеется возможность добавлять и удалять...
-
Объектом автоматизации сайта "вопрос-ответ" является предметная область "Проектирование информационных систем". Основное назначение сайта "вопрос-ответ"...
-
Функции, возвращающие специальные характеристики матриц - Массивы, векторы и матрицы
Следующие функции возвращают специальные характеристики матриц: Cols(M) Возвращает число столбцов матрицы M Rows(M) Возвращает число строк матрицы M...
-
Описание бизнес-процессов бюджетирования в группе компаний нефтегазового сектора Одна из исследовательских задач данной работы состоит в том, чтобы...
-
Физическая модель базы данных определяет способ размещения данных в среде хранения и способ доступа к этим данным, которые поддерживаются на физическом...
-
1.1 Физические средства-различные устройства и системы механического, электрического либо электронного плана, деятельность которых не зависит от...
-
Антивирусные программы, Требования к антивирусным программам - Компьютерный вирус
Для обнаружения, удаления и защиты от компьютерных вирусов разработаны специальные программы, которые позволяют обнаруживать и уничтожать вирусы. Такие...
-
Методы разработки вычислительной сети: 1. Экспериментальный метод - персонал предприятия закупает "новинки" рынка компьютерной техники. Такой метод -...
-
Правила записи программы на языке Си - Основы программирования
Как указывалось выше, программа перед обработкой компьютером должна быть помещена в файл на диске. Обычно этот файл имеет расширение <.c>. Рассмотрим...
-
Общие данные "о программе" - Учет средств предпрятия
Данная программа представляет собой консольное приложение разработанное в среде Borland Pascal v 7.0. Главное окно программы (не титульный лист)...
-
Введение - Программа трехмерной реконструкции сцены по изображениям и данным сканирования глубины
Трехмерная реконструкция и трехмерное сканирование в настоящее время быстро развиваются и находят широкое применение в робототехнике, медицине,...
Кластеры бизнес-процессов и метрики их анализа - Программа анализа матриц типа "функции-данные" и интерпретации деревьев бизнес-процессов