Обработка и разметка полученной коллекции текстов. Грамматический парсер MYSTEM (библиотека "pymystem3" для языка программирования Python) - Компьютерная лингвистика в образовательной среде
При извлечении текста из Интернета, он не имеет никой разметки и представлен в виде сплошного набора предложений. Для дальнейшего использования необходимо обработать полученный материал и перевести его в удобочитаемый формат для дальнейшей работы с ним. Именно поэтому в программе, позволяющей извлекать и сохранять статьи, создается функция:
Save_articles (db, filename) - она служит для записи и сохранения полученных статей в файл с расширением ".xml". Использование модуля etree делает возможным разделение текста на части и составление некой иерархии.
Article = etree. SubElement (root, "atricle") - основной элемент (корень), содержащий в себе несколько дочерних элементов:
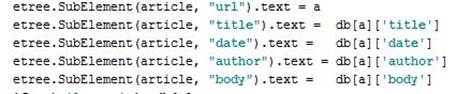
Таким образом, на выходе мы получаем текст, разбитый на части: заголовок, дата, автор и непосредственно сама статья. Пример полученной разметки. Данная обработка текста позволяет обособить разные элементы статьи, а также создает теги, по которым можно легко обращаться к тем или иным частям. Следующий шаг в разметке полученных статей - морфологическая разметка полученных текстов.
Морфологическая разметка осуществляется при помощи бесплатного синтаксического анализатора MYSTEM (парсер или "синтаксический анализатор" -- компьютерная программа, которая принимает данные (как правило, предложения) на естественном языке в качестве входных данных и генерирует структуру вывода, подходящую для анализа)ElaKumar. "ArtificialIntelligence". 2008г. С.316.
Данная программа, написанная И. В. Сегаловичем и В. А. Титовым (программисты компании "Яндекс"), существует в свободном доступе. MYSTEM создана в среде Linux, но имеется возможность работы и в среде MicrosoftWindows (хоть и с некоторыми проблемами относительно кодировки командной строки).
Основу данной программы составляет алгоритм "Грамматического словаря русского языка" А. А. Зализняка. Для обработки текста, на входе требуется файл в формате HTML, XML или TXT (кодировка Windows), на выходе получаем файл с необходимым вариантом разбора:
{словоформа1, [грамматические признаки, лексема1]...}.Д. В. Сичинава "К задаче создания корпусов русского языка" 2002г.
Словоформы, отсутствующие в словаре, указываются со знаком "?" или приводится гипотеза (пример: мурелки{мурелка?}).Статья на сайте Yandex. ru"MYSTEM" https://tech. yandex. ru/mystem/
В данном исследовании используется внешняя библиотека для Python"pymystem3", предоставляющая весь функционал программы. Это позволяет избежать подключение внешних приложений и значительно ускоряет работу с текстами.
При импортировании модуля "Mystem" появляется возможность разметить полученную коллекцию текстов. Первый шаг: определение леммы каждого слова. Такой подход позволяет настроить поиск слов по начальной форме, так, при дальнейшем поиске по статьям, будет учитываться не только словоформа. Второй шаг: полный грамматический разбор слова.
Данные разборы также записываются в. xml файл, являются дочерними от главного элемента <article> и имеют свои собственные теги <lemmas> и <analyze>..
Импорт модуля "json" позволяет перевести полученную библиотеку данных под тегом <analyze> в читаемый формат.
Хотя подобный разбор несовершенен и требует ручной обработки, на этапе применения корпуса в качестве базы для упражнения, ошибки никак не скажутся и не помешают адекватной работе программы.
Выводы по первой главе
Анализ теоретической составляющей данной главы позволяет сделать следующие выводы:
- -Корпусная лингвистика набирает популярность и все чаще используется не только в исследовательской сфере, но и в области преподавания языка. - Материалы для занятий, основанные на корпусных данных, отражающие всю глубину языка, позволяют разбирать не только простые случаи употребления слов, но и реальные языковые средства. - Корпусный подход является оптимальным для наглядного отражения таких аспектов языка, как географический, исторический, социальный; он передает основные изменения в языковой системе.
Что касается практической части:
- - В данной главе описывается процесс написания программы, которая позволяет создавать автоматически пополняющийся и само-обрабатывающийся корпус политических статей интернет-источника Lenta. ru. 1) Первая часть программы нацелена на сохранение и дополнение коллекции текстов; 2) Вторая часть включает: структурирование текста, разделение его на части, а также морфологическую разметку полученного корпуса.
Похожие статьи
-
Автоматизированное извлечение текстов для корпуса политических статей сайта Lenta. ru Для создания полезного обучающего корпуса требуется постоянное...
-
Корпусная лингвистика и ее применение в области преподавания иностранного языка "Корпусная лингвистика - раздел компьютерной лингвистики, занимающийся...
-
Проектирование и разработка сайта Средства разработки Язык гипертекстовой разметки HTML В Интернете сосредотачивается и передается достаточно большое...
-
Проектирование упражнения. Создание списка основных политических терминов. Поиск и разметка терминов в полученном корпусе После создания корпуса статей...
-
Для того, чтобы на сервере можно было запустить файлы с расширением. py, необходимо выполнить несколько операций: 1) Для работы с виртуальным окружением...
-
Введение - Компьютерная лингвистика в образовательной среде
Современная система образования все чаще приветствует внедрение информационных технологий, особенно это касается сферы преподавания языка - постоянно...
-
Язык разметки XML - Компьютерная лингвистика в образовательной среде
XML - это расширяемый язык разметки (ExtensibleMarkupLanguage). Был разработан в соответствии с основными требованиями сервера WWW. Является достаточно...
-
При проектировании упражнения встал вопрос о его реализации. Было необходимо найти такой метод, который не только соответствовал основным требованиям...
-
Заключение - Компьютерная лингвистика в образовательной среде
Целью написания данной выпускной квалификационной работы являлось создание и введение в эксплуатацию упражнения, основанного на размеченном корпусе...
-
Для программирования агентов могут применяться: универсальные языки (Java, C++ , Visual Basic и др.), языки представления знаний (SL, KIF), языки...
-
В данной части работы, рассмотрим необходимое программное обеспечение для распознавания и перевода вышеприведенных документов из графического формата в...
-
Структура сайта - Компьютерная лингвистика в образовательной среде
Структура сайта разработана в соответствии с основными требованиями к веб-приложению. (Рис.3) Содержит в себе 3 основные страницы (одна из которых...
-
Обоснование выбора языка и среды программирования Для реализации данного курсового проекта был выбран язык программирования Visual C#. Язык основан на...
-
Шаблоны сайта Bootstrap3 Веб-дизайн является одним из основных элементов в процессе создания сайта. Именно от него зависит, насколько удобно и комфортно...
-
Создание веб-сервера - Компьютерная лингвистика в образовательной среде
Завершающий шаг в создании и введении в эксплуатацию сайта - выбор и настройка веб-сервера, принимающего HTTP-запросы от клиентов (веб-браузеров), и...
-
Каскадные таблицы стилей CSS - Компьютерная лингвистика в образовательной среде
Язык CSS отвечает за стиль в том или ином документе. Он используется для того, чтобы придать страницам на HTML -- фундаментальном языке WWW --...
-
Языки программирования для Интернета - Теоретические основы информационных технологий
С активным развитием глобальной сети было создано немало популярных языков программирования, адаптированных специально для Интернета. Все они отличаются...
-
Языки и методы параллельного программирования - Администрирование параллельных процессов
Применение параллельных архитектур повышает производительность при решении задач, явно сводимых к обработке векторов. Автоматическое распараллеливание...
-
Разработка сайта, Среда разработки web-сайта - Разработка сайта для компании
Среда разработки web-сайта При разработке web-сайта используются: - HTML - язык разметки web-страниц; - CSS - формальный язык описания внешнего...
-
Для написания АИС использовались следующие языки программирования, программные средства и библиотеки: - Язык программирования PHP 5.4; -...
-
Шестой метод - построение суффиксных деревьев. Среди большого количества методов анализа текста метод аннотированного суффиксного дерева выделяется тем,...
-
Лингвистический процессор GATE GATE представляет собой инфраструктуру для разработки и развертывания компонентов программного обеспечения, которые...
-
Алгоритм работы декодера кода Рида - Маллера будем разрабатывать на основе уже приведенных выше уравнений. Алгоритм приведен на рисунке 12. В начале...
-
Инструментарий технологии программирования - программные продукты поддержки (обеспечения) технологии программирования. В рамках этого направления...
-
Программирование подключенной к параллельному порту аппаратуры заключается в установке определенных битов в регистрах данных и управления и чтении...
-
"WWWSQLDesigner" позиционируется как абсолютно бесплатный, доступный для пользователей, универсальный веб-редактор, значительно упрощающий процесс...
-
Операционная система На сегодняшний момент операционная система Windows фирмы Microsoft во всех ее проявлениях, бесспорно, считается самой...
-
Конфигурация устройств ввода-вывода Турбо Паскаля - Программирование в среде Turbo Pascal
Результаты работы программы и исходные данные могут быть записаны в файлы на диске, с помощью специальных процедур работы с файлами прямо из программы. В...
-
Введение, Правила и порядок выполнения курсовой работы - Программирование в среде Turbo Pascal
Настоящие методические указания предназначены для выполнения курсовой работы "Расчеты на ЭВМ характеристик выходных сигналов электрических цепей" по...
-
Языки программирования баз данных - Теоретические основы информационных технологий
Эта группа языков отличается от алгоритмических языков, прежде всего решаемыми задачами. База данных - это файл (или группа файлов), представляющий собой...
-
В нашей курсовой работе была поставлена задача создания обучающей программы по информатике, с помощью которой студенты смогут проверить свои знания в...
-
Цель Работы - изучить приемы создания и использования шаблонов классов. - Теоретические сведения Достаточно часто встречаются классы, объекты которых...
-
Сравнение аналогов - Разработка программы для реализации редактора временных графов синхронизации
Поскольку конечной целью работы был редактор сетей Петри, интегрированный с внешней библиотекой алгебраических вычислений, было рациональным рассмотреть...
-
ПО развивается исходя из требований других подсистем. ПО при обработке данных является связующим звеном между комплексом технических средств и другими...
-
Текстовый редактор Microsoft Word 2003 - Технология обработки текстовой информации
Текстовый редактор Microsoft Word на сегодняшний день является одной из лучших профессиональных программ для обработки текста. Он также представляет...
-
Алгол (Algol, ALGOrithmic Language -- алгоритмический язык), язык программирования высокого уровня. Существуют три последовательно сменявших друг друга...
-
Заключение - Сравнение моделей представления слов в задаче очистки текста от обесцененной лексики
В данной работе проводится сравнение эффективности 6 методов поиска по однословному запросу. В качестве запроса выступает слов из стоп-листа - списка...
-
1. Изучение теоретических аспектов использования: MS Word, MS Excel, MS Access, Paint и Photoshop... (ППО) Часть 1 : Руководство по выполнению...
-
Для вызова ЛЕКСИКОНа следует набрать LEXICON или LEXICON имя редактируемого - файла Если в команде вызова ЛЕКСИКОНа указано имя файла, которого нет на...
-
ОПЕРАТОР ВВОДА ДЛЯ ЧТЕНИЯ ФАЙЛА, ОПЕРАТОР ВЫВОДА - Язык программирования Паскаль
Оператор ввода для чтения файла обладает всеми свойствамии обычного оператора READ. Вкачестве параметров могут быть переменные; каждая переменная поучает...
Обработка и разметка полученной коллекции текстов. Грамматический парсер MYSTEM (библиотека "pymystem3" для языка программирования Python) - Компьютерная лингвистика в образовательной среде