Логарифмическая зависимость параметра сходства от числа ячеек сетки - Фундаментальные закономерности распознавания социальных категорий по астрономическим данным на момент рождения
Для каждого масштаба сетки распознаются все 37 категорий, определяется их параметр сходства и средний параметр сходства для всех 37 категорий, что соответствует 86314 случаям. Такая представительная статистика позволяет выполнить параметрические исследования зависимости среднего параметра сходства от числа ячеек и определить эту зависимость с высокой достоверностью. На рис. 1 представлены обобщенные данные среднего параметра сходства в зависимости от числа ячеек для трех использованных БД. Все эти данные обобщаются одной универсальной зависимостью, которую можно представить в виде весьма хорошей аппроксимации ():
(2)
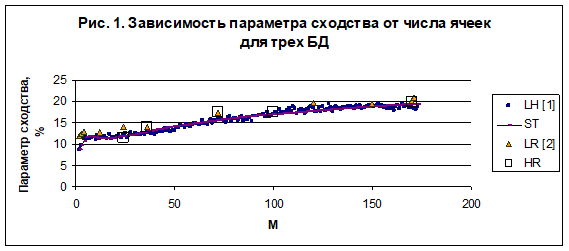
Зависимость (2) отображена на рис 1. сплошной линией ST.
Необходимо отметить, что вид эмпирической формулы (2) совпадает с теоретическим выражением для системного обобщения формулы Хартли (3), обоснованного в работе [16].
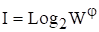
(3) |
Где:
W - количество чистых (классических) состояний системы.
- коэффициент, названный в [16] коэффициентом эмерджентности Хартли (уровень системной организации объекта, имеющего W чистых состояний).
В работе [16] получено следующее выражение (4) для этого коэффициента:
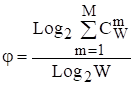
(4) |
В работе [16] обоснована интерпретация смысла коэффициента эмерджентности Хартли. Непосредственно из вида выражения (4) для коэффициента эмерджентности Хартли видно, что он представляет собой относительное превышение количества информации о системе при учете системных эффектов (смешанных состояний, иерархической структуры ее подсистем и т. п.) над количеством информации без учета системности, т. е. этот коэффициент отражает уровень системности объекта. Таким образом, коэффициент эмерджентности Хартли отражает уровень системности объекта и изменяется от 1 (системность минимальна, т. е. отсутствует) до W/Log2W (системность максимальна). Очевидно, для каждого количества элементов системы существует свой максимальный уровень системности, который никогда реально не достигается из-за действия правил запрета на реализацию в системе ряда подсистем различных уровней иерархии. Более подробный анализ смысла этого коэффициента приведен в работе [17].
По сути дела степень в выражении (2) представляет собой эмпирическое выражение для коэффициента эмерджентности Хартли, полученное на основе анализа огромной выборки, поэтому представляет безусловный интерес совместная сопоставительная теоретическая интерпретация этих выражений. В предварительном плане можно предположить, что наличие этого коэффициента в выражении (2) означает, что предметом исследования в данной статье является система и этот коэффициент отражает уровень ее системности, т. е. степень ее отличия от множества. Однако более подробная интерпретация данного коэффициента - это дело будущего.
Кроме того, полученные результаты можно интерпретировать таким образом, что все использованные комбинации астрономических параметров эквивалентны между собой в смысле распознавания категорий по параметру сходства. Из выражения (2) следует, что асимптотически, при числе ячеек модели стремящемся к бесконечности, средний параметр сходства зависит от числа ячеек как логарифмическая функция. Подобная зависимость характерна для сеточной энтропии, которая пропорциональна логарифму числа элементов множества. Таким образом, параметр сходства ведет себя как сеточная энтропия, что, по сути, означает теоретическую возможность повышения среднего параметра сходства вплоть до 100% при числе ячеек М порядка 1.673131011. Конечно, чтобы в этом случае все ячейки были представлены, необходим объем выборки, превышающей суммарное население Земли за тысячи лет. По-видимому, это можно считать одним из следствий известной теорема Котельникова об отсчетах, смысл которой в том, что если ставится цель детальнее прописать кривую, то для этого необходимо больше точек (отсчетов). В нашем случае это означает, что если мы хотим точнее прописать кривую, то необходимо увеличивать количество ячеек, т. е. уменьшать интервал, но чем меньше интервал, тем хуже модель подавляет шум, а чтобы она его подавляла как при прежнем большом интервале - нужно столько же реализаций на уменьшенный интервал, т. е. соответственно больший объем выборки. Получается два источника погрешностей, которые действуют по своим законам, т. е. по-разному:
- 1. Слишком большой интервал. 2. Ухудшение шумоподавляющих свойств модели при уменьшении интервала.
Поэтому если мы хотим повысить точность модели, уменьшая интервал, то это приводит увеличению шума из-за уменьшения количества реализаций в каждом интервале, и наоборот, если улучшать шумоподавляющую способность модели за счет увеличения интервала то это приводит к потере ее точности из-за увеличения его величины. Так что для любого конкретного объема выборки, распределения респондентов по классам и распределения признаков по респондентам есть некий экстремум достоверности, получающийся при определенном количестве ячеек. Теоретически найти этот экстремум пока не представляется возможным. Поэтому чтобы найти его на практике была просчитана целая серия частных моделей с уменьшающимся интервалом и измерена достоверность идентификации респондентов по разным категориям в этих моделях [1]. Отметим, что в настоящее время М173 является предельной моделью, которая может быть изучена на основе системы [2]. Поэтому достичь предельного значения среднего параметра сходства не представляется возможным. Реально, однако, разброс параметра сходства для различных категорий весьма велик, как это можно видеть из данных таблицы 2, где представлены результаты распознавания в модели 170 для трех исследованных БД. Поэтому некоторые категории могут быть распознаны с высокой вероятностью в моделях с относительно малыми значениями М. Отметим также, что полученные значения параметра сходства для 34 категорий из 37 превосходят вероятность случайного угадывания, которая определяется как отношение абсолютной частоты (встречаемости респондентов определенной категории) к общему числу случаев, т. е.
P=(Частота/86314)*100%.
При этом отношение среднего параметра сходства к средней вероятности случайного угадывания любой категории составляет 7.343, что можно считать показателем эффективности алгоритма распознавания. Отметим, что в статистике считается, что если для некоторой модели эта величина больше 2.5, то достоверность статистических высказываний, полученных на основе модели, выше 95%.
Категории, имеющие отношение к женскому и мужскому полу, распознаются на уровне случайного угадывания. В данной задаче эти категории используются как шум, на фоне которого выделяется полезный сигнал, связанный с более тонкой социальной специализацией индивида. Интересно, что к плохо определяемым категориям относится и категория SC:A1-Book Collection, включающая большую группу исторических личностей, чьи биографии стали частью мировой литературы. Если исключить эти три плохо распознаваемые категории, тогда эффективность модели повышается вплоть до 9.667. Отметим также, что определенные комбинации астрономических параметров могут приводить к повышению параметра сходства некоторых категорий - см. таблицу 1. Например, категория SC:A129-Death лучше всего распознается в составе базы данных HR, категория SC:B329-Sexuality:Sexual perversions хорошо распознается в составе базы LR, а категория SC:B173-Sports:Football в составе базы LH.
Таблица 2. Параметр сходства 37 категорий для трех БД в модели М170
|
NAME |
Частота |
Sk (M170,LH) |
Sk (M170,LR) |
Sk (M170,HR) |
P, % |
|
SC:М- |
13640 |
11.313 |
10.659 |
12.969 |
15.80277 |
|
SC:Ж- |
5125 |
3.579 |
9.107 |
6.535 |
5.937623 |
|
SC:A53-Sports |
4567 |
42.618 |
29.463 |
42.256 |
5.291146 |
|
SC:A1-Book Collection |
4471 |
3.463 |
1.701 |
8.316 |
5.179924 |
|
SC:A15-Famous |
3373 |
5.069 |
7.997 |
8.115 |
3.907825 |
|
SC:A42-Medical |
2910 |
7.289 |
8.060 |
11.676 |
3.371411 |
|
SC:A323-Sexuality |
2675 |
24.914 |
33.141 |
17.938 |
3.099150 |
|
SC:A5-Entertainment |
2577 |
14.015 |
17.830 |
12.977 |
2.985611 |
|
SC:A9-Relationship |
2442 |
13.986 |
16.989 |
13.094 |
2.829205 |
|
SC:A40-Occult Fields |
2396 |
11.665 |
15.359 |
14.083 |
2.775911 |
|
SC:B111-Sports:Basketball |
2385 |
41.088 |
24.414 |
44.295 |
2.763167 |
|
SC:B329-Sexuality:Sexual perversions |
2360 |
24.935 |
34.041 |
21.432 |
2.734203 |
|
SC:A55-Art |
2232 |
11.641 |
13.937 |
13.325 |
2.585907 |
|
SC:A19-Writers |
2223 |
13.584 |
13.498 |
15.043 |
2.575480 |
|
SC:A129-Death |
2168 |
4.874 |
5.025 |
14.091 |
2.511759 |
|
SC:A25-Personality |
2083 |
12.990 |
13.552 |
14.250 |
2.413282 |
|
SC:A68-Childhood |
1996 |
11.384 |
12.960 |
16.223 |
2.312487 |
|
SC:A31-Business |
1813 |
19.130 |
22.154 |
17.276 |
2.100470 |
|
NAME |
Частота |
Sk (M170,LH) |
Sk (M170,LR) |
Sk (M170,HR) |
P, % |
|
SC:C330-Sexuality:Sexual perversions:Homosexual |
1807 |
24.002 |
33.204 |
23.918 |
2.093519 |
|
SC:B45-Famous:Greatest hits |
1795 |
11.309 |
14.805 |
15.217 |
2.079616 |
|
SC:A29-Parenting |
1754 |
17.465 |
19.513 |
17.266 |
2.032115 |
|
SC:B173-Sports:Football |
1613 |
67.566 |
56.238 |
53.233 |
1.868758 |
|
SC:B97-Occult Fields:Astrologer |
1480 |
17.432 |
20.549 |
19.853 |
1.714670 |
|
SC:B21-Relationship:Number of marriages |
1417 |
21.293 |
21.619 |
18.547 |
1.641680 |
|
SC:B2-Book Collection:Profiles Of Women |
1389 |
17.702 |
17.137 |
18.073 |
1.609241 |
|
SC:A92-Birth |
1343 |
25.215 |
34.791 |
25.316 |
1.555947 |
|
SC:B14-Entertainment:Actor/ Actress |
1256 |
17.993 |
22.088 |
19.385 |
1.455152 |
|
SC:?- (Неопределенный пол) |
1242 |
18.595 |
20.786 |
23.522 |
1.438932 |
|
SC:B49-Book Collection:American Book |
1178 |
23.722 |
20.916 |
25.780 |
1.364784 |
|
SC:B26-Personality:Body |
1163 |
19.552 |
19.102 |
20.487 |
1.347406 |
|
SC:B189-Medical:Illness |
1159 |
18.246 |
20.351 |
19.725 |
1.342772 |
|
SC:B6-Entertainment:Music |
1086 |
17.912 |
23.052 |
21.181 |
1.258197 |
|
SC:A99-Financial |
1075 |
19.091 |
22.838 |
21.513 |
1.245453 |
|
SC:B48-Famous:Top 5% of Profession |
1073 |
17.441 |
20.637 |
20.215 |
1.243136 |
|
SC:A38-Politics |
1039 |
17.540 |
19.623 |
22.316 |
1.203744 |
|
SC:A23-Psychological |
1007 |
19.996 |
25.056 |
22.644 |
1.166671 |
|
SC:A108-Education |
1002 |
19.157 |
21.411 |
22.186 |
1.160878 |
|
Среднее значение |
2332.811 |
18.615 |
20.097 |
19.845 |
2.702703 |
Зависимость интегральной информативности от долготы углов домов. В работе [4] была обнаружена регулярная зависимость интегральной информативности от расстояния до небесных тел. Это означает, что влияние небесных тел на психологию группы индивидов имеет субстанциональный характер. Какая именно субстанция является агентом влияния остается пока под вопросом. Есть основания предполагать, что таковой субстанцией может являться гравитационный потенциал, под влиянием которого меняются статистические характеристики системы фермионов, что в свою очередь приводит к изменению электрических и магнитных свойств проводников, а также скорости радиоактивного распада [5-11]. Возможно, что для согласования результатов потребуется некоторая модификация уравнений гравитационного поля типа [12].
В настоящей работе выполнено исследование зависимости интегральной информативности от долготы углов домов. Обнаружена регулярная зависимость интегральной информативности от долготы угла первого дома (асцендента) - рис. 2, от долготы угла 4 дома (IC) - рис. 3, от долготы угла 7 дома (десцендента) - рис. 4, и от долготы угла 9 дома - рис. 5. Полученные зависимости являются однотипными во всех исследованных моделях - М24, М36, М72, М100 и М170. Наилучшая достоверность при интерполяции данных квадратичным полиномом наблюдается в модели М24.
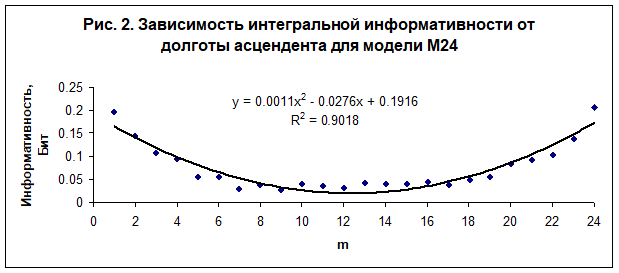
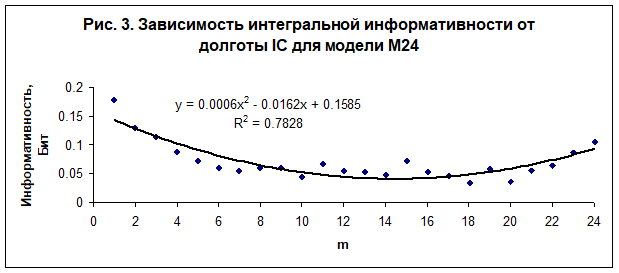
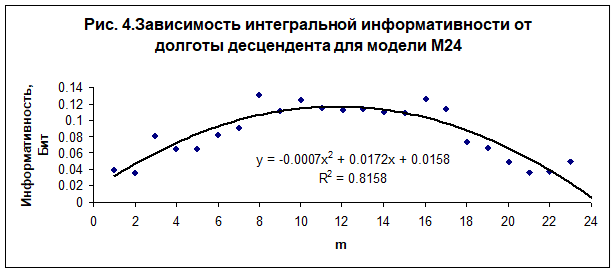
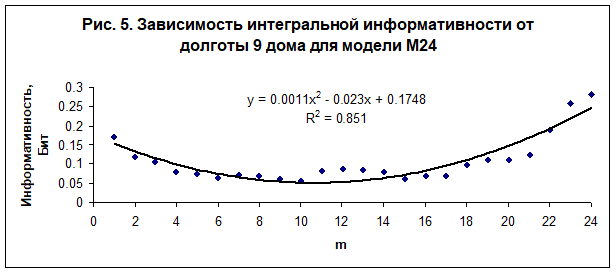
Анализ полученных данных показывает, что существует асимметрия пространства вдоль оси знаков Овен - Весы. В настоящее время неизвестно, чем вызвана эта асимметрия. Возможно, что это обусловлено движением нашей Галактики в сторону гигантского скопления галактик в созвездии Девы со скоростью. Тогда точка осеннего равноденствия, которая в настоящее время проецируется в созвездие Девы рядом со скоплением галактик, будет выделена этим движением, как и противоположная ей точка весеннего равноденствия (обе точки находятся на оси Овен - Весы). Скопление галактик обладает колоссальным гравитационным потенциалом, который, видимо, на два порядка превосходит гравитационный потенциал Солнца на поверхности земли. Неизвестно, однако, могут ли вариации этого потенциала, вызванные суточным вращением нашей планеты, создать заметное изменение в ритмах психической активности, или же влияние скопления проявляется на уровне восприятия информации [12]. Можно рассмотреть и другие причины, например, движение Солнца в направление созвездия Лебедя вокруг центра Галактики. Пока лишь можно утверждать, опираясь на полученные данные, что группа индивидов чувствует асимметрию пространства, что в свою очередь отражается на выборе социальных категорий. Кроме того, можно однозначно утверждать, что время суток в момент рождения, от которого зависит положение углов домов, влияет на выбор социальной специализации.
Похожие статьи
-
Если посчитать корреляцию между различными видами человеческой деятельности и положениями стрелок часов, то окажется, что между многими из них подобная...
-
Исходные параметры задачи представляют собой банк данных, содержащий 20007 записей биографий реальных личностей, отобранных из AstroDatabank [15]. Эти...
-
Существует оптическая астрономия, изучающая свойства небесных тел по изображениям. Есть также радиоастрономия, изучающая свойства небесных тел по их...
-
При моделировании влияния расстояния до небесных тел на интегральную информативность было обнаружено, что наиболее достоверно зависимости выявляются в...
-
Обнаруженная зависимость интегральной информативности от расстояния до небесных тел свидетельствует о том, что взаимодействие субъектов с ближним...
-
Тело небесный система солнечный 1. Луценко Е. В., Трунев А. П. Астросоциотипология и спектральный анализ личности по астросоциотипам с применением...
-
Зависимость направления неустойчивости от координаты Z - Космический аппарат
Орбиты, для которых были рассчитаны направления неустойчивости в предыдущем разделе, лежат в плоскости эклиптики (плоскости XY). Однако также необходимо...
-
Исследование зависимости энергетики поддержания гало-орбиты от места и направления исполнения импульса Суммарный импульс, затрачиваемый на коррекции для...
-
Орбиты, для которых были рассчитаны направления неустойчивости в предыдущем разделе, лежат в плоскости эклиптики (плоскости XY). Однако также необходимо...
-
Покажем, что для любой классической системы, обладающей центральной симметрией и заданной энергией, существует такая метрика, что действие системы будет...
-
Интерполяция направления неустойчивости - Космический аппарат
Зависимость направления неустойчивости от координат X, Y КА образует поверхность, проекции которой представлены на рис. 36-38. Рис. 36. Точки, для...
-
Зависимость направления неустойчивости от координат X, Y КА образует поверхность, проекции которой представлены на рис. 36-38. Рис. 36. Точки, для...
-
В результаті дисертаційних досліджень вирішено важливу наукову задачу розробки і дослідження методів підвищення точності оцінок параметрів поверхонь при...
-
Випромінювання земних дистанційний зондування Актуальність теми. Для розв'язання задач вивчення природних ресурсів, прогнозування погодних умов,...
-
Исследование зависимости энергетики поддержания гало-орбиты от места и направления исполнения импульса Суммарный импульс, затрачиваемый на коррекции для...
-
Гиперболическое движение - Математическое моделирование движения небесных тел
(p=0,e>1) Каноническое уравнение гиперболы в центральных прямоугольных координатах O?!?! представляется в виде (1.68) Где a - действительная, а b...
-
Общие соображения - К вопросу о коррекции климата Марса
Прежде всего, каковы потребные условия? Давление паров воды при температуре +37 OС составляет около 6300 Па [0.062 атм]. Значит, чтобы ходить без...
-
Гравитационные волны - Черные дыры
Теория тяготения Эйнштейна предсказала существование гравитационных волн. Они подобны электромагнитным, которые являются быстро меняющимся...
-
Черные дыры - Освоение космоса
О черных дырах узнали в 1960-х годах. Оказалось, что если бы наши глаза могли видеть только рентгеновское излучение, то звездное небо над нами выглядело...
-
Математическое описание модели Модель "Radiocity" Расчет излучения в результате переотражения элементами космического аппарата друг на друга выполнятся с...
-
Импедансная оценка состояния клеточных суспензий в условиях космического полета
Импедансная оценка состояния клеточных суспензий в условиях космического полета Непрерывное развитие современных медицинских клеточных технологий в...
-
Нестационарная космология Фридмана - Космологические модели Вселенной
Фридмана как математика не удовлетворило полученное решение Эйнштейна, так как он получил одно из всех возможных решений системы уравнений тяготения,...
-
Использование фотографических методов - Оптическая астрономия
С середины прошлого века в астрономии стал применяться фотографический метод регистрации излучения. В настоящее время он занимает ведущее место в...
-
Горячая модель Вселенной - Эволюция вещества во Вселенной
Фундаментальное взаимодействие модель горячая вселенная Модель горячей Вселенной -- космологическая модель, в которой эволюция Вселенной начинается с...
-
Парадоксы кривой вращения галактики Млечный Путь
Парадоксы кривой вращения галактики Млечный Путь Принято считать, что кривая вращения звезд Млечного Пути имеет вид, отличающийся от кеплеровской кривой...
-
Вселемнная -- фундаментальное понятие астрономии, строго не определяемое[1][2][3][4]. Включает в себя весь окружающий мир. На практике под Вселенной...
-
Введение, Полеты в космос, Космос на данный момент - Первый полет в космос
Ежегодно 12 апреля в России и в странах всего мира отмечают Международный День космонавтики - первый полет человека в космос - космонавта Юрия Гагарина....
-
Схема рождения Вселенной., Возникновение и эволюция звезд - Астрономическая картина мира
Возбужденный вакуум, сжатый до состояния точки. Быстрое расширение - инфляция. Через 10-32 с. Холодная и пустая Вселенная размером в несколько...
-
Движение планет - История астрономических знаний
Наблюдая за годичным перемещением Солнца среди звезд, древние люди научились заблаговременно определять наступление того или иного времени года. Они...
-
На протяжении веков человек стремился разгадать тайну великого мирового "порядка" Вселенной, которую древнегреческие философы и назвали Космосом (в...
-
Формат данных ДЗЗ - Космические аппараты
Многоканальная видеоинформация представляется комбинацией пространственной позиции (номер пикселя и номер строки) и номера канала. Классификация форматов...
-
Модель принимает на вход: - описание геометрии аппарата в виде твердотельной модели, выполненной в САПР SolidWorks; - описание геометрии поверхности Луны...
-
Об изменении параметров солнечного ветра с расстоянием от солнца. - Солнечный ветер
Изменение скорости солнечного ветра с расстоянием от Солнца определяется двумя силами: силой солнечной гравитации и силой, связанной с изменением...
-
ВСЕЛЕННАЯ. ЭВОЛЮЦИЯ ВСЕЛЕННОЙ - Астрономическая картина мира
Современная космология - это сложная, комплексная и быстро развивающаяся система естественно-научных (астрономия, физика, химия и др.) и философских...
-
Фундаментальные взаимодействия в природе и их особенности - Эволюция вещества во Вселенной
Фундаментальные взаимодействия -- качественно различающиеся типы взаимодействия элементарных частиц и составленных из них тел. Исследуя окружающий нас...
-
Параметры полета, История запуска - Первый спутник Земли
* Начало полета -- 4 октября 1957 в 19:28:34 по Гринвичу * Окончание полета -- 4 января 1958 * Масса аппарата -- 83,6 кг; * Максимальный диаметр -- 0,58...
-
Ответ: Охотничье огнестрельное оружие - это ружья. Они различаются по числу стволов, сверлению и калибра стволов, устройству ударного механизма и по...
-
Ответ: Среди многочисленных типов отечественных ружей можно выделить следующие: нарезные (неавтоматические и полуавтоматические), гладкоствольные (одно-,...
-
Краткие исходные данные. - Тайна прецессии Земной оси
Достаточно подробное и последовательное обоснование, приведено в [2], однако это обоснование носит очень разноплановый характер. Для сокращения и...
-
Эволюция звезд - Рождение и эволюция звезд
Современная астрономия располагает большим количеством аргументов в пользу утверждения, что звезды образуются путем конденсации облаков газопылевой...
Логарифмическая зависимость параметра сходства от числа ячеек сетки - Фундаментальные закономерности распознавания социальных категорий по астрономическим данным на момент рождения