Представление информации в ЭВМ - Представление и хранение информациии в ЭВМ
В большинстве ЭВМ информация представляется в двоичном виде (Существуют так же двоично-десятичные и троичные ЭВМ). Это обусловлено, в основном, техническими особенностями - простой реализации электронного устройства с двумя (а не с десятью) устойчивыми состояниями: есть сигнал - нет сигнала. Эти два состояния обозначаются символами 0 и 1. Каждый двоичный символ несет 1 бит информации.
Любая информация в ЭВМ представляется последовательностью двоичных символов. Каждому символу внешнего алфавита (т. е. алфавита пользователя). каждой команде или элементу данных сопоставляется своя последовательность символов. Способ кодирования для нас сейчас не имеет значения, тем более длина кода.
С помощью последовательности из 4-х нулей и единиц можно закодировать 24=16 символов. Увеличив длину последовательности до 8 символов можно получить 28=256. Этого вполне достаточно для кодирования символов внешнего алфавита (цифры, строчные и прописные буквы, специальные знаки и т. д.)
Поэтому размер ячейки в ЭВМ у современных машин равен восьми двоичным символам (разрядам). Единица информации, содержащая 8 двоичных символов называется байтом. Т. е. 1 байт = 8 бит. Это наименьшая адресуемая часть памяти машины. Однако многие данные и команды требуют больше места (в командах кроме кода операции нужны и адреса ячеек). Поэтому выделяют машинное слово, которое на разных ЭВМ может состоять из двух или четырех байт.
Кодирование текстовых данных:
Каждый символ занимает 1 байт. Для кодирования могут использоваться различные стандарты. На IBM-совместимых ЭВМ - это ASCII (American Standart Code for Information Interchange - американский стандартный код для обмена информацией), на наших - КОИ-7, КОИ-8 (Коды для обмена информацией, 7 и 8 битные).
ASCII - 7-разрядный код, т. е. стандарт задает только 128 символов. Восьмой бит используется для расширения таблицы (есть много разных вариантов), куда включают символы Кириллицы, псевдографику, математические символы и прочее.
Обычно код символа записывают не в двоичной, а в шестнадцатиричной системе счисления. При этом каждая четверка двоичных символов образует один шестнадцатиричный.
|
Пример: цифре 5 соответствует латинское A соответствует |
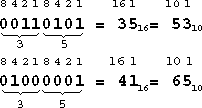
Дать Алгоритмы перевода 10 -> 2 и т. д.
В 16-ричной системе счисления 16 цифр. От 0 до 9 берутся из десятичной, остальные обозначаются латинскими буквами A(10), B(11), C(12), D(13), E(14), F(15). Так что AC16 = (10)*16+12=17210
Кодирование целых чисел: Кодировать числа можно "посимвольно", но это не рационально (1 символ = 1 байт!). Для цифры достаточно 4 бит:
0 <=> 0000, 1 <=> 0001, 2 <=> 0010,..., 9 <=> 1001. (Так называемое двоично-десятичное кодирование). Такое представление применяется в ряде случаев при обработке экономической информации (в языке КОБОЛ в частности). - Это кодирование не эффективно по памяти, поэтому в большинстве случаев используют двоичное кодирование.
Использование двоичной системы требует перевода вводимых чисел из 10-ной в двоичную при вводе и из двоичной в десятичную при выводе данных.
Это снижает эффективность, если необходимо вводить и выводить большие массивы информации при небольшом времени их обработки (как в экономических задачах).
Для представления дробных чисел существуют два варианта - с фиксированной и плавающей запятой.
Для целых чисел используется первый вариант (точка фиксирована после целой части), для вещественных - второй вариант.
Фиксированная запятая.
Максимальная величина целого числа зависит от того, сколько места ему разрешено занять - байт, два байта или больше.
Диапазон целого без знака:
От 0 до 2N-1, где n - общее число разрядов, т. е. от 0 до 255 (1 байт), от 0 до 65535 (2 байта).
Обычно один разряд выделяется для знака числа, поэтому диапазон изменяется.
Знаковое целое: от -128 до 127 (1 байт). от -32768 до 32767 (2 байта).
Формат целого числа:
|
Знак (1 бит) |
Число (15, 31, 63 бита) |
"+": 1. Простая арифметика => быстродействие выше.
"-": 1. Необходимо, чтобы диапазон данных не выходил за пределы представления числа.
- 2. Малый диапазон представления чисел. 3. Погрешность представления зависит от длины числа.
Плавающая запятая.
Т. к. диапазон целых чисел сравнительно небольшой (хотя в некоторых языках есть и длинное целое), для расчетов используются вещественные числа, которые кодируются в форме с плавающей запятой.
В этом случае число представляется в виде ±M*2±p.
В машинном слове фиксируется расположение всех элементов: мантиссы (±M - целое со знаком) и порядка (±p - целое со знаком).
При выполнении операций учитывается, в каком виде представлены числа. Операции над целыми числами реализуются аппаратно, а над вещественными - программно. Для ускорения вычислений используется математический сопроцессор (дополнительно к основному процессору), который выполняет арифметические операции с вещественными числами аппаратно.
Диапазон представления числа с плавающей запятой намного больше, чем целого. Обычно вещественному числу выделяется 4 байта (32 бита).
Тогда диапазон чисел от -3,4*1038 до 3,4*1038
Это не значит, что можно представить любое число из этого диапазона. Фактически представимой оказывается дискретная последовательность чисел. Шаг дискретизации зависит от количества знаков мантиссы.

Например после 0 следует число ~3,4*10-38, внутри вещественных чисел нет. Из формы представления возникают следующие эффекты:
- 1. Ошибка округления. => вычислительные алгоритмы не должны допускать роста погрешности вычислений из-за ошибок округления. 2. Потеря значимости: число стало таким маленьким, что не может быть представлено в ЭВМ - оно превращается в "машинный ноль". 3. Переполнение (эффект, обратный потере значимости): число слишком велико.
Ошибки округления:
Что получится, если к миллиону прибавить одну миллионную? 1 000 000.000 001 - 13 знаков, в мантиссу не поместится, следовательно, миллион не изменится - вроде бы естественно. А если к миллиону прибавить одну миллионную миллион раз? В математике - 1 000 001, в ЭВМ останется тот же миллион.
А если складывать в другую сторону: сначала миллионные доли - получим 1, потом уже прибавим 1 000 000 - получится правильно!
Следовательно коммутативность сложения в ЭВМ нарушается (от перемены мест слагаемых, сумма меняется). Правило: При большом числе слагаемых суммирование начинаем с наименьших.
Похожие статьи
-
Кодирование информации -- процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи,...
-
Под термином графика обычно понимается визуальное (то есть воспринимаемое зрением) представление каких-либо реальных или воображаемых объектов. Графика...
-
Арифметические операции в двоичной системе счисления Умножение в двоичной системе счисления = поразрядные сдвиги + суммирование Основные форматы хранения...
-
Хранение и накопление информации - Теоретические основы информационных технологий
Хранение и накопление информации вызвано многократным ее использованием, применением условно-постоянной, справочной и других видов информации,...
-
Поиск, сбор и хранение научной информации - Поиск, накопление и обработка информации
Не все окружающие нас источники информации можно использовать для подготовки научных работ. Ведь научная работа всегда имеет достаточно узкую...
-
Хранение, кодирование и пpеобpазование данных - Единицы измерения информации в памяти ПК
Хранение информации в памяти ЭВМ - одна из основных функций компьютера. Любая информация хранится с использованием особой символьной формы, которая...
-
Операционные элементы ЭВМ - Представление и хранение информациии в ЭВМ
Операционные элементы - это устройства цифровой техники, которые выполняют некоторые микрооперации за один или несколько тактов. Эти устройства...
-
Машинная арифметика с плавающей точкой - Представление и хранение информациии в ЭВМ
Число с плавающей точкой: X=±Mx-S±px Здесь: M - мантисса; S - порядок. 0.314 101 0.0314 102 Машинные числа. Машинными называются числа, допускающие...
-
Любая информация, включая экономическую, требует материального воплощения, что и достигается ее представлением (фиксацией) в форме определенных сигналов...
-
Кодирование, Кодирование текстовой информации - Экономическая информатика
Кодирование текстовой информации Кодирование информации - процесс преобразования сигнала из формы, удобной для непосредственного использования...
-
МЕТОДЫ АРХИВАЦИИ - Архивация информации и программы-архиваторы
Несмотря на то, что объемы внешней памяти ЭВМ постоянно растут, потребность в архивации не уменьшается. Это объясняется тем, что архивация необходима не...
-
Перед началом непосредственного использования программы "Сервер опроса", следует создать рабочую конфигурацию сервера с помощью программы - конфигуратора...
-
Кодирование графической информации. - Экономическая информатика
Существует несколько способов кодирования графической информации. Так и все виды информации, изображения в компьютере закодированы в виде двоичных...
-
Режим эксплуатации АРМ должен соответствовать режиму работы сотрудников, то есть пользователей в соответствии со штатным расписанием рабочего дня,...
-
Системы счисления. Представление данных в ЭВМ - Основы программирования
В современном мире для записи числовой информации используют позиционные системы счисления, в которых числа записываются с помощью ограниченного...
-
Кодирование по методу четности / нечетности - Кодирование информации
Для контроля правильности передачи информации, а также как средство шифрования информации используются различные коды. Коды, использующие для передачи...
-
"ТЕХНОЛОГИЯ РАЗРАБОТКИ ПРЕЗЕНТАЦИЙ", "ПРЕДСТАВЛЕНИЕ ИНФОРМАЦИИ НА ЭКРАНЕ" - Презентация "Принтеры"
Данный режим предназначен для создания страниц заметок, которые могут использоваться докладчиком во время презентации или служить в качестве раздаточного...
-
Кодирование текстовой информации - Кодирование информации в компьютере
В настоящее время большая часть пользователей при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков...
-
Базовые понятия информации - Компьютерные и сетевые технологии
Информация компьютер математический сеть Мы начинаем первое знакомство с величайшим достижением нашей цивилизации, стоящем в одном ряду с изобретением...
-
Интерфейсы систем управления. Классификация, основные характеристики интерфейсов. Системные (внутримашинные) интерфейсы. Интерфейсы персональных...
-
Контроль функционирования ЭВМ - Представление и хранение информациии в ЭВМ
Назначение схем контроля цифровых устройств, виды контроля для комбинационных схем Потери времени в таких сложных объектах, как ЭВМ, в первую очередь...
-
ЗАКЛЮЧЕНИЕ - Распространение новостной информации
Проведенное исследование позволило составить представление об особенностях распространения новостной информации в социальной сети Twitter. Была проведена...
-
Обеспечение высокопомехоустойчивого обмена информацией в автоматизированных системах управлениях
При передаче цифровых данных в комплексах средств автоматизации управления войсками и оружием существует вероятность того, что принятые данные могут...
-
Для третьего способа мне понадобился способ под названием "Стемминг". Данное понятие очень популярно во всемирной паутине, так как оно применяется в...
-
Цветовые модели. - Кодирование информации в компьютере
Если говорить о кодировании цветных графических изображений, то нужно рассмотреть принцип декомпозиции произвольного цвета на основные составляющие....
-
Внемашинное ИО - Автоматизированные системы обработки экономической информации
Внемашинное ИО - информация, которая воспринимается человеком без каких-либо технических средств (документы). Классификация - система распределения...
-
Выше приведена таблица макропоказателей для каждой сети. В данном случае нельзя говорить об отношении направленности существующих различий...
-
Криптография, аутентификация - Анализ средств защиты информации в ЛВС
Проблемой защиты информации путем ее преобразования занимается криптология (kryptos - тайный, logos - наука). Криптология разделяется на два направления...
-
Как представлять непрерывную информацию?, Выводы - Информация и способы ее получения
Для представления непрерывной величины могут использоваться самые разнообразные физические процессы. В рассмотренном выше примере весы позволяют величину...
-
Растровое изображение. - Кодирование информации в компьютере
При помощи увеличительного стекла можно увидеть, что черно-белое графическое изображение, например из газеты, состоит из мельчайших точек, составляющих...
-
Кодирование графической информации - Кодирование информации в компьютере
В середине 50-х годов для больших ЭВМ, которые применялись в научных и военных исследованиях, впервые в графическом виде было реализовано представление...
-
Метод парольной защиты - Защита информации
Законность запроса пользователя определяется по паролю, представляющему собой, как правило, строку знаков. Метод паролей считается достаточно слабым, так...
-
Способы обработки данных - Автоматизированные системы обработки экономической информации
Различаются следующие способы обработки данных: централизованная, децентрализованная, распределенная и интегрированная. Централизованная предполагает...
-
Внутримашинное ИО - Автоматизированные системы обработки экономической информации
Это совокупность всех данных, записанных на машинных носителях, сгруппированных по определенным признакам. ИО формирует информационную среду....
-
Создание представлений - Банки и базы данных. Системы управления базами данных
Представлением (View) называется виртуальная таблица, отображающая данные, получаемые из реальных таблиц БД, а также из других представлений....
-
Выводы - Системная теория информации и семантическая информационная модель
Интервальные оценки сводят анализ чисел к анализу фактов и позволяют обрабатывать количественные величины как нечисловые данные. Это ограничивает...
-
Структура записей данных в таких файлах имеет вид, представленный на рис. 4. Рис. 4 Структура записей данных в файлах с неплотным индексном При такой...
-
Файлы с плотным индексом или индексно-прямые файлы - Проблема организации и хранения данных
В этих файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а структура индексной записи в...
-
При этой стратегии файловое пространство не разделяется на области, но для каждой записи добавляются два указателя: указатель на предыдущую запись в...
-
Основная часть, Физические модели таблиц базы данных - Проблема организации и хранения данных
Физические модели таблиц базы данных Физическая модели таблицы базы данных предполагает описание свойств каждого поля таблицы. Для описания свойств полей...
Представление информации в ЭВМ - Представление и хранение информациии в ЭВМ