Базовые понятия информации - Компьютерные и сетевые технологии
Информация компьютер математический сеть
Мы начинаем первое знакомство с величайшим достижением нашей цивилизации, стоящем в одном ряду с изобретением книгопечатания и открытием электричества - компьютером. Сначала мы вспомним базовые понятия информатики, как науки, изучающей основные аспекты получения, хранения, преобразования и передачи информации. Затем мы раскроем сущность, принцип работы компьютера как технического устройства. Затем мы изучим наиболее оптимальные способы соединений компьютерных устройств и технологий с целью получения максимальной эффективности хранения, обработки и передачи информации.
Особенностью нашего курса будет пристальное внимание к фундаментальным аспектам компьютерных и сетевых технологий. Еще одна особенность, мы будем помнить, что ПК давно перестал быть просто вычислителем. Это универсальная система обработки больших и разнородных информационных потоков. А что такое информационный поток? Или более конкретно - Что такое информация?
В сотнях книг и учебниках это понятие трактуется по-разному. А ведь все мы интуитивно понимаем, что это такое. В чем здесь дело? А дело в том, что понятие информации стоит в одном ряду с такими фундаментальными понятиями как энергия, вещество, энтропия, время. Действительно, в природе существует два фундаментальных вида взаимодействия: обмен веществом и обмен энергией (не будем вдаваться в тонкости фактической эквивалентности этих двух явлений). Фундаментальность их проявляется в том, что все остальные взаимодействия происходят только посредством этих взаимодействий. Эти два взаимодействия являются симметричными и подчиняются фундаментальному закону сохранения - сколько вещества и/или энергии один объект передал другому, столько он потерял, а другой приобрел (рассматриваются замкнутые системы, в которых потери можно охарактеризовать просто другими видами взаимодействия).
Когда в процессе взаимодействия приобретения и потери НЕ совпадают, НЕ равны - такое взаимодействие называют несимметричным. Очевидно, что в предельном случае несимметричного взаимодействия при передаче некоторой субстанции между объектами один из них ее приобретает, а другой НЕ теряет.
Исходя из этого, попробуем выделить необходимый и достаточный признак, по которому можно будет определить, относится то или иное явление к обмену веществом/энергией или к обмену информацией. В этом контексте сформулируем наиболее общее свойство информации.
Любое взаимодействие между объектами, в процессе которого один приобретает некоторую субстанцию, а другой ее не теряет называется ИНФОРМАЦИОННЫМ ВЗАИМОДЕЙСТВИЕМ. При этом передаваемая субстанция называется ИНФОРМАЦИЕЙ.
Отсюда следуют некоторые очевидные свойства информации:
Если энергия определяет возможность совершения действия, то информация определяет возможность целесообразного выбора этого действия;
Информация не может существовать вне взаимодействия объектов;
Информация не теряется ни одним из них в процессе этого взаимодействия;
Информация устраняет неопределенность, предоставляет человеку или техническому устройству возможность сделать выбор в пользу одного из нескольких равноправных вариантов.
Впервые понятие информации ввел американский математик Клод Шеннон, рассматривая процесс передачи сообщения между двумя точками в 1948 г. как численную меру неопределенности или неупорядоченности, с которой посланное сообщение прибывает в пункт назначения. Он назвал этот параметр энтропией, применив термин из термодинамики, который там используется для оценки неупорядоченности материи и характеризует несимметричные взаимодействия. Более того, Шеннон предложил формулу, позволяющую определить количество информации, содержащееся в сообщении:
I = Log 2 P
Где I - количество информации в битах или энтропия вероятности;
P - вероятность, величина неопределенности, число возможных вариантов.
Модель передачи сообщения по Шеннону
Отметим одну интересную особенность этого выражения: символ с высокой вероятностью появления кодируется несколькими битами, тогда как маловероятный символ требует многих бит. Другими словами, энтропия системы, объекта с большим числом степеней свободы очень велика, больше величина хаоса, беспорядка. Однако не всем и не сразу стала очевидной связь количества информации и энтропии, попробуем разобраться в этом.
В работах Планка, а главным образом Больцмана понятие энтропии трактовалась, как мера неумолимой тенденции всякой системы двигаться от менее вероятного состояния к более вероятному состоянию. Наиболее вероятным состоянием системы является РАВНОВЕСНОЕ состояние, а любая система движется к состоянию равновесия. Содержание второго постулата (принципа) термодинамики формулирует этот закон более строго - энтропия замкнутой системы не убывает (растет для необратимых процессов и остается постоянной для обратимых:
Hs = k Ln Wt
Где k - постоянная Больцмана;
Wt - термодинамическая вероятность состояния системы.
Сравним это выражение с определением количества информации данное Шенноном. Очевидно сходство обоих выражений и это сходство носит фундаментальный характер. Как мы уже говорили, энтропия является функцией статистического состояния системы (мерой ее неупорядоченности, хаоса). Пусть имеется некоторая система, энтропия которой равна Н нач. После получения некоторой информации (либо о состоянии объекта, либо о взаимодействии с внешней средой) энтропия должна уменьшаться (растет порядок, уменьшается хаос). В широком смысле можно сказать, что информация, принимаемая объектом, необходимо является для него целесообразной, в противном случае это - дезинформация. Следовательно, количество полученной информации можно определить следующим образом:
I = Н нач - Н кон
Количество получаемой объектом информации численно равно неопределенности по выбору действий ведущих к достижению целей объекта или энтропии устраненной благодаря сообщению. Очевидно, что в данном случае речь идет о синтаксической мере информации. Информация устраняет неопределенность, структурирует систему.
Пример:
Примитивные формы информационного взаимодействия в чистом виде можно выделить уже в неживой природе. Действительно, каталическое взаимодействие. Объект, называемый катализатором изменяет скорость протекания химической реакции между группой других объектов, сам катализатор остается неизменным по всем своим свойствам. Ярчайшим примером информационного взаимодействия в ходе которого уменьшается энтропия всей системы, а химические, физические свойства катализатора остаются неизменными - является реакция кристаллизации насыщенного солевого раствора в присутствии кристаллической "затравки".
Обратите внимание на еще одно немаловажное свойство информации - изменение возможно и без получения информации, но при этом оно будет менее вероятным.
Информация, энтропия и избыточность при передаче данных
Связь количества информации и энтропии сообщения, введенные К. Шенноном, имеет большой практический интерес. Если мы рассматриваем информацию как числовой параметр, выражающий энтропию некоторого сообщения или результатов проводимого эксперимента то, очевидно, мы можем рассматривать энтропию как меру вероятности, случайности. Тогда, необходимое количество битов для кодировки одного символа (энтропия), например, английского алфавита, содержащего 26 букв и знак пропуска, равна log2 27 = 4,76 бита на символ. Учтем неравномерность использования букв английского алфавита (вероятность встретить букву "e" в 12 раз выше, чем букву "s", учтем вероятность следования определенных сочетаний), получим:
H= - (P1log2P1 + P2 log2P2 +......+P26log2 P26)
Это значение средней длины кода называется энтропией распределения вероятности, т. к. это мера количества порядка (или беспорядка) в кодах, представляющих символ языка. Вычисленное Шенноном значение энтропии алфавита английского языка равно 3,3 бита на символ. Другими словами избыточность английского языка равна 70% (сравнение с 4,76 битов на символ). Отсюда можно сделать интересные практические выводы:
Если в английском тексте каждая вторая буква потеряна или изменена в результате помех, ничего страшного, есть возможность полного восстановления текста;
Нет необходимости использовать 8 бит кода ASCII для передачи каждого символа, поэтому можно применить один или несколько алгоритмов компрессии, тем самым временно уменьшая избыточность.
Вообще говоря, тема компрессии (сжатии) данных чрезвычайно важна при передаче цифровых сообщений и здесь расчет энтропии играет ключевую роль. Все современные модемы, аппаратура связи для IP-телефонии и многое другое имеют встроенные механизмы компрессии данных.
Тема эта чрезвычайно интересна, но нам пора приступить к рассмотрению тех прикладных свойств информации, которые являются абсолютно необходимыми в изучении компьютера и компьютерных технологий.
Информационные процессы
Мы понимаем под информацией все, так или иначе оформленные сведения или сообщения о вещах и явлениях, которые уменьшают степень неопределенности, хаотичности знаний об этих вещах или явлениях. Информация не есть нечто статичное, неизменное, она не существует вне взаимодействия объектов. Как правило, с ней все время что-то происходит, т. е. осуществляются информационные процессы. Эти процессы можно разделить на четыре группы - сбор, хранение, обработка и передача информации.
Восприятие информации приемником - преобразователем осуществляется при помощи сигналов. Сигналы имеют различную физическую природу и являются продуктами энергообмена, имеющие в своей основе материальную природу. Технические средства, преобразующие сигналы в форму, удобную для восприятия (человеком, техническим средством) называются первичными преобразователями информации или датчиками.
Данные - это зарегистрированные сигналы. Данные, несоответствующие ни каким целям объекта, не несут для него информацию и, поэтому, пропадают, возвращая объект в то состояние, в котором он был до получения этих данных.
Данные, зафиксированные в некоторой материальной форме, способные сохраняться и передаваться уже представляют собой скрытую, зашифрованную информацию и называются сообщением. Для того, что бы из данных получить информацию надо иметь алгоритм преобразования или механизм интерпретации информационных кодов. Материальная среда, определяющая взаимодействие между источником и приемником сообщения, называется каналом связи.
Данные не тождественны информации.
Примеры: состязание бегунов, пловцов - регистрация начального и конечного положения стрелки механического секундомера - перемещение стрелки это регистрация данных (однако информации о времени преодоления дистанции пока нет) - метод пересчета одной физической величины в другую (четверть круга - 15 секунд) позволяет получить информацию о скорости перемещения бегуна. Другой пример - напишем последовательность нескольких телефонных номеров:
302 65 21; 145 44 75; 194 05 67 и т. д.
Непосвященный человек воспримет эти цифры как данные ему ни о чем не говорящие. Если теперь подписать рядом с числами название и имена абонентов - это уже данные, с которыми можно работать, использовать - т. е. ИНФОРМАЦИЯ. Для получения информации необходим алгоритм обработки данных, механизм интерпретации данных. Прежде чем данные обрабатывать их нужно отформатировать или, лучше сказать, структурировать.
Основные структуры данных
Понятие ДАННЫЕ будет пронизывать весь курс, поэтому необходимо ознакомиться с основными структурами данных: линейная, иерархическая и табличная.
Пример: книга - разобрали на отдельные листы и смешали, набор данных есть, но подобрать адекватный метод получения информации трудно. Если же собрать все листы в правильной последовательности, мы получим простейшую структуру данных - ЛИНЕЙНУЮ. Однако читать придется с самого начала до конца, что не всегда удобно.
Для быстрого поиска требуемой информации применяется ИЕРАРХИЧЕСКАЯ структура. Оглавление - разделы - параграфы и т. д. Элементы структуры более низкого уровня обязательно входят в элементы более высокого уровня.
Теперь представьте, мы связали линейную и иерархическую структуры, то есть связали разделы, главы, параграфы с номерами страниц (содержание). Тем самым, мы создали НАВИГАТОРА, который еще более упростит поиск - ТАБЛИЧНАЯ структура.
Обработка данных
Обработка данных или преобразование данных включает следующие операции:
Сбор данных;
Формализация данных, приведение к единому формату;
Фильтрация данных, уменьшение уровня "шума";
Сортировка данных, повышение доступности информации;
Архивация данных, организация хранения;
Защита данных;
Транспортировка данных;
Преобразование данных, важнейшая и наиболее дорогая задача информатики, как правило, связанная с изменением носителя.
Способы представления информации и два класса ЭВМ
Первая форма представления информации называется аналоговой или непрерывной. Величины, представленные в такой форме, могут принимать любые значения, в каком - то диапазоне. Они могут быть сколь угодно близки друг к другу и изменяться в произвольные моменты времени.
Вторая форма представления информации называется цифровой или дискретной. Для дискретных сообщений характерно наличие фиксированного набора элементов, из которых в некоторые (вполне определенные) моменты времени формируются различные последовательности. В отличие от непрерывной величины количество значений дискретной величины всегда будет конечным.
Первая форма используется в аналоговых вычислительных машинах. Эти машины предназначены для решения задач, описываемых системами дифференциальных уравнений: исследования поведения подвижных объектов, моделирования ядерных реакторов, электромагнитных полей. Но АВМ не могут решать задачи, связанные с хранением и обработкой больших объемов информации, которые легко решаются при использовании цифровой формы представления информации, реализуемой цифровыми вычислительными машинами (ЦВМ).
Кодирование информации
Кодирование информации - это процесс формирования определенного представления информации. В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (например, звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть преобразована в числовую форму. Например, чтобы перевести в числовую форму музыкальный звук, можно через небольшие промежутки времени измерять интенсивность звука на определенных частотах, представляя результаты каждого измерения в числовой форме. С помощью программ для компьютера можно выполнить преобразования полученной информации, например "наложить" друг на друга звуки от разных источников. Аналогичным образом на компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
Представление данных в ЭВМ.
За основу представления данных в ЭВМ, как правило, принята двоичная система счисления. Как и десятичная система счисления, двоичная система (в которой используются лишь цифры 0 или 1) является позиционной системой счисления, т. е. в ней значение каждой цифры числа зависит от положения (позиции) этой цифры в записи числа. Каждой позиции присваивается определенный вес.
В компьютерной технике широкое распространение получили также следующие позиционные системы счисления: восьмеричная, шестнадцатеричная и двоично-десятичная система.
(В двух словах - 16- ная система - это простое решение сложной проблемы - точное представление данных в ЭВМ, 16 - ная система счисления - это краткая нотация двоичной системы).
Форматы файлов
Основное назначение файлов - хранить информацию. Они также предназначены для передачи данных от программы к программе и от системы к системе. Другими словами, файл - это хранилище стабильных и мобильных данных. Но, файл - это нечто большее, чем просто хранилище данных. Обычно файл имеет имя, атрибуты, время модификации и время создания. Понятие файла менялось с течением времени. Операционные системы первых больших ЭВМ представляли файл, как хранилище для базы данных и, поэтому файл являлся набором записей. Обычно все записи в файле были одного размера, часто по 80 символов каждая. При этом много времени уходило на поиск и запись данных в большой файл. В конце 60-х годов наметилась тенденция к упрощению операционных систем, что позволило использовать их на менее мощных компьютерах. Это нашло свое отражение и в развитии операционной системы Unix. В Unix под файлом понималась последовательность байтов. Стало легче хранить данные на диске, так как не надо было запоминать размер записи. Unix оказал очень большое влияние на другие операционные системы персональных компьютеров. Почти все они поддерживают идею Unix о том, что файл - это просто последовательность байтов. Файлы, представляющие собой поток данных, стали использоваться при обмене информацией между компьютерными системами. Если используется более сложная структура файла (как в операционных системах OS/2 и Macintosh), она всегда может быть преобразована в поток байтов, передана и на другом конце канала связи воссоздана в исходном виде.
Итак, мы можем считать, что файл - это поименованная последовательность байтов.
Файловая структура представляет собой систему хранения файлов на запоминающем устройстве, например, диске. Файлы организованы в каталоги (иногда называемые директориями или папками). Любой каталог может содержать произвольное число подкаталогов, в каждом из которых могут храниться файлы и другие каталоги. Способ, которым данные организованы в байты, называется форматом файла. Для того чтобы прочесть файл, например, электронной таблицы, необходимо знать, каким образом байты представляют числа (формулы, текст) в каждой ячейке; чтобы прочесть файл текстового редактора, надо знать, какие байты представляют символы, а какие шрифты или поля, а также другую информацию. Программы могут хранить данные в файле таким способом, какой выберет программист. Зачастую предполагается, однако, что файлы будут использоваться различными программами. По этой причине многие прикладные программы поддерживают некоторые наиболее распространенные форматы, так что другие программы могут понять данные в файле. Компании по производству программного обеспечения (которые хотят, чтобы их программы стали "стандартами"), часто публикуют информацию относительно форматов, которые они создали, чтобы их можно было бы использовать в других приложениях. Все файлы условно можно разделить на две части - текстовые и двоичные.
Текстовые файлы - наиболее распространенный тип данных во всем компьютерном мире. Для хранения каждого символа чаще всего отводится один байт, а кодирование текстовых файлов выполняют с помощью специальных таблиц, в которых каждому символу соответствует определенное число, не превышающее 255. Файл, для кодировки которого используется только 127 первых чисел, называется ASCII-файлом (сокращение от American Standard Code for Information Interchange - американский стандартный код для обмена информацией), но в таком файле не могут быть представлены буквы, отличные от латиницы (в том числе и русские). Большинство национальных алфавитов можно закодировать с помощью восьмибитной таблицы. Для русского языка наиболее популярны на данный момент три кодировки: Koi8-R, Windows-1251 и, так называемая, альтернативная (alt) кодировка. Подробнее о кодировании русского текста рассказано в главе "Обработка документов". Такие языки, как китайский, содержат значительно больше 256 символов, поэтому для кодирования каждого из них используют несколько байтов. Для экономии места зачастую применяется следующий прием: некоторые символы кодируются с помощью одного байта, в то время как для других используются два или более байтов. Одной из попыток обобщения такого подхода является стандарт Unicode, в котором для кодирования символов используется диапазон чисел от нуля до 65 536. Такой широкий диапазон позволяет представлять в численном виде символы языка людей из любого уголка планеты. Но чисто текстовые файлы встречаются все реже. Люди хотят, чтобы документы содержали рисунки и диаграммы и использовали различные шрифты. В результате появляются форматы, представляющие собой различные комбинации текстовых, графических и других форм данных.
Двоичные файлы, в отличие от текстовых, не так просто просмотреть и в них, обычно, нет знакомых нам слов - лишь множество непонятных символов. Эти файлы не предназначены непосредственно для чтения человеком. Примерами двоичных файлов являются исполняемые программы и файлы с графическими изображениями.
Кодирование чисел
Существуют два основных формата представления чисел в памяти компьютера. Один из них используется для кодирования целых чисел, второй (так называемое представление числа в формате с плавающей точкой) используется для задания некоторого подмножества действительных чисел. Множество целых чисел, представимых в памяти ЭВМ, ограничено. Диапазон значений зависит от размера области памяти, используемой для размещения чисел. В k-разрядной ячейке может храниться 2k различных значений целых чисел. Чтобы получить внутреннее представление целого положительного числа N, хранящегося в k-разрядном машинном слове, необходимо:
Перевести число N в двоичную систему счисления;
Полученный результат дополнить слева незначащими нулями до k разрядов.
Пример. Получить внутреннее представление целого числа 1607 в 2-х байтовой ячейке.
Переведем число в двоичную систему: 160710 = 110010001112. Внутреннее представление этого числа в ячейке будет следующим: 0000 0110 0100 0111.
Для записи внутреннего представления целого отрицательного числа (-N) необходимо:
Получить внутреннее представление положительного числа N;
Обратный код этого числа заменой 0 на 1 и 1 на 0;
Полученному числу прибавить 1.
Пример. Получим внутреннее представление целого отрицательного числа -1607. Воспользуемся результатом предыдущего примера и запишем внутреннее представление положительного числа 1607: 0000 0110 0100 0111. Инвертированием получим обратный код: 1111 1001 1011 1000. Добавим единицу: 1111 1001 1011 1001 - это и есть внутреннее двоичное представление числа -1607.
Формат с плавающей точкой использует представление вещественного числа R в виде произведения мантиссы m на основание системы счисления n в некоторой целой степени p, которую называют порядком: R = m * n p.
Представление числа в форме с плавающей точкой неоднозначно. Например, справедливы следующие равенства:
12.345 = 0.0012345 x 104 = 1234.5 x 10-2 = 0.12345 x 102
Чаще всего в ЭВМ используют нормализованное представление числа в форме с плавающей точкой. Мантисса в таком представлении должна удовлетворять условию: 0.1p <= m < 1p. Иначе говоря, мантисса меньше 1 и первая значащая цифра - не ноль (p - основание системы счисления).
В памяти компьютера мантисса представляется как целое число, содержащее только значащие цифры (0 целых и запятая не хранятся), так для числа 12.345 в ячейке памяти, отведенной для хранения мантиссы, будет сохранено число 12345. Для однозначного восстановления исходного числа остается сохранить только его порядок, в данном примере - это 2.
Кодирование текста
Множество символов, используемых при записи текста, называется алфавитом. Количество символов в алфавите называется его мощностью.
Для представления текстовой информации в компьютере чаще всего используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации, т. к. 28 = 256. Но 8 бит составляют один байт, следовательно, двоичный код каждого символа занимает 1 байт памяти ЭВМ.
Все символы такого алфавита пронумерованы от 0 до 255, а каждому номеру соответствует 8-разрядный двоичный код от 00000000 до 11111111. Этот код является порядковым номером символа в двоичной системе счисления.
Для разных типов ЭВМ и операционных систем используются различные таблицы кодировки, отличающиеся порядком размещения символов алфавита в кодовой таблице. Международным стандартом на персональных компьютерах является уже упоминавшаяся таблица кодировки ASCII.
Принцип последовательного кодирования алфавита заключается в том, что в кодовой таблице ASCII латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений.
Стандартными в этой таблице являются только первые 128 символов, т. е. символы с номерами от нуля (двоичный код 00000000) до 127 (01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, начиная со 128 (двоичный код 10000000) и кончая 255 (11111111), используются для кодировки букв национальных алфавитов, символов псевдографики и научных символов. О кодировании символов русского алфавита рассказывается в главе "Обработка документов".
Кодирование графической информации
В видеопамяти находится двоичная информация об изображении, выводимом на экран. Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части - растровую и векторную графику.
Растровые изображения представляют собой однослойную сетку точек, называемых пикселами (pixel, от англ. picture element). Код пиксела содержит информацию о его цвете. Для черно-белого изображения (без полутонов) пиксел может принимать только два значения: белый и черный (светится - не светится), а для его кодирования достаточно одного бита памяти: 1 - белый, 0 - черный. Пиксел на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксел недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксел, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 - черный, 10 - зеленый, 01 - красный, 11 - коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов - красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций:
|
R |
G |
B |
Цвет |
|
0 |
0 |
0 |
Черный |
|
0 |
0 |
1 |
Синий |
|
0 |
1 |
0 |
Зеленый |
|
0 |
1 |
1 |
Голубой |
|
R |
G |
B |
Цвет |
|
1 |
0 |
0 |
Красный |
|
1 |
0 |
1 |
Розовый |
|
1 |
1 |
0 |
Коричневый |
|
1 |
1 |
1 |
Белый |
Разумеется, если иметь возможность управлять интенсивностью (яркостью) свечения базовых цветов, то количество различных вариантов их сочетаний, порождающих разнообразные оттенки, увеличивается. Количество различных цветов - К и количество битов для их кодировки - N связаны между собой простой формулой: 2N = К.
В противоположность растровой графике векторное изображение многослойно. Каждый элемент векторного изображения - линия, прямоугольник, окружность или фрагмент текста - располагается в своем собственном слое, пикселы которого устанавливаются независимо от других слоев. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т. д.). Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов.
Объекты векторного изображения, в отличии от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость). Подробнее о графических форматах рассказывается в разделе "Графика на компьютере".
Кодирование звука
Из курса физики вам известно, что звук - это колебания воздуха. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой - аналоговый - сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел.
Поступим следующим образом. Будем измерять напряжение через равные промежутки времени и записывать полученные значения в память компьютера. Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его - аналого-цифровым преобразователем (АЦП).
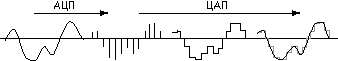
Для того чтобы воспроизвести закодированный таким образом звук, нужно выполнить обратное преобразование (для него служит цифро-аналоговый преобразователь - ЦАП), а затем сгладить получившийся ступенчатый сигнал.
Чем выше частота дискретизации (т. е. количество отсчетов за секунду) и чем больше разрядов отводится для каждого отсчета, тем точнее будет представлен звук. Но при этом увеличивается и размер звукового файла. Поэтому в зависимости от характера звука, требований, предъявляемых к его качеству и объему занимаемой памяти, выбирают некоторые компромиссные значения.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Человек издавна использует довольно компактный способ представления музыки - нотную запись. В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI.
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Заметим, что существуют и другие, чисто компьютерные, форматы записи музыки. Среди них следует отметить формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку. При этом вместо 18-20 музыкальных композиций на стандартный компакт-диск (CDROM) помещается около 200. Одна песня занимает примерно 3,5 Mb, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.
Типы данных
Основными типами данных в вычислительной технике являются: бит, байт и слово. Компьютеры работают в основном с байтами, которые являются основной операционной единицей компьютерных данных. Машинное слово (слово) технический термин, означающий 16 бит или 2 байта одновременно. Двойное слово - 4 байта, расширенное слово - 8 байт.
Для представления данных существует три основных формата:
Двоичный с фиксированной запятой;
Двоичный с плавающей запятой;
Двоично-кодированный десятичный (BCD).
Если надо закодировать целое число со знаком, то старший бит регистра (ячейки памяти) используется для хранения знака (0 при положительном знаке числа и 1 при отрицательном) - формат с фиксированной запятой.
Исходные возможности компьютера позволяют ему работать только с целыми числами, к тому же не самыми большими. Даже в случае 2х байтового слова, мы можем записать максимальное число 65536, учитывая необходимость отображения, как положительных чисел, так и отрицательных получаем только половину всех числовых значений. Способы представления чисел и программное обеспечение позволяют значительно расширить возможности компьютера. Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
- 3,1415926 = 0,31415926 * 101 500 000 = 0,5 * 106 123 456 789 = 0,1 * 1010
Первая часть числа называется мантиссой - М, а вторая - порядком q
Для того чтобы оперировать дробными числами или числами очень большой длины, используется понятие плавающей запятой. Плавающая запятая действует по принципу экспоненциального формата - числа вида -+M *q+p
Необходимо отметить что, вычисления с целыми числами выполняются очень быстро, в то время как вычисления с плавающей запятой в сотни раз медленнее.
Для реализации скоростных вычислений с плавающей запятой применяются числовые сопроцессоры (FPU - floating point unit). Данные в нем хранятся в 80-ти разрядных регистрах.
В двоично-кодированном десятичном формате каждая десятичная цифра представляется в виде 4-х битного двоичного эквивалента. Существует две основные разновидности этого формата: упакованный и неупакованный. В упакованном BCD-формате цепочка десятичных цифр хранится в виде последовательности 4-х битовых групп. В неупакованном формате каждая десятичная цифра находится в младшей тетраде байта, а содержимое старшей тетрады определяется используемой ЭВМ конкретной системой кодирования, и в данном случае несущественно.
Аналогичным образом (в виде двоичных чисел) кодируются команды - инструкции на выполнение каких-либо операций со словами данных. Например, трехадресная команда в двухбайтовом формате будет выглядеть следующим образом:
Кроме этого, данные бывают в виде строк - непрерывная последовательность бит или байт, символьные данные, поддерживаемые кодом ASCII и данные типа указатель. Более подробно мы с ними познакомимся после изучения архитектуры компьютера.
Выводы
Знание основных принципов работы компьютера необходимы тем инженерам, которые связали свою карьеру с компьютерными технологиями и телекоммуникационными сетями.
Несмотря на огромный прогресс компьютерных технологий, фундаментальные принципы функционирования компьютера как инструмента для хранения, обработки и передачи информации не изменились.
Информация не может существовать вне взаимодействия объектов и она не теряется ни одним из них в процессе взаимодействия.
Информация устраняет неопределенность, уменьшает хаос и энтропию системы.
Все процессы в природе сопровождаются сигналами. Зарегистрированные сигналы образуют данные. Отформатированные данные - сообщения преобразуются, транспортируются и потребляются с помощью методов. При взаимодействии данных и адекватных им методов образуется информация. Информация - это динамический объект, образующийся в ходе информационного процесса. Информационный процесс состоит из: сбора, хранения, обработки и передачи информации. Для удобства работы с данными их структурируют.
Существуют следующие важнейшие структуры: линейная, табличная и иерархическая. В ЭВМ применяется универсальная система кодирования, называемая двоичным кодом. Элементарной единицей представления данных называется - бит, далее идут байт, слово, двойное слово.
Вопросы и задания
Как вы понимаете термин "средства массовой информации"? Что это?
Являются ли данные товаром? Могут ли методы быть товаром?
Определите в каком из сообщений содержится больше информации:
Собака укусила мальчика;
Мальчик укусил собаку.
Что происходит с информацией по окончании информационного процесса?
Перечислите основные составляющие информационного процесса.
Что такое позиционная система счисления? Дайте примеры таких систем.
Какое число является основанием десятичной, двоичной системы счисления?
Перевести число из одной системы счисления в другую:
210 = Х2, 10112 = Х10, 1610 = Х2, 1011,12 =Х10
Записать двоичное число, соответствующее десятичному числу 5 в однобайтовом формате.
Другим примером может служить семейство ЭВМ, разработанное под руководством Израиля Яковлевича Акушского (1911-1992). Для ускорения ряда арифметических операций он предложил использовать не позиционную (традиционную двоичную, или троичную, как у Брусенцова), а оригинальную систему вычислений в остаточных классах (СОК). Работы над ЭВМ в СОК начались в 1957 году в СКБ-245, затем продолжались в других организациях. В то время, когда скорость традиционных ЭВМ измерялась десятками тысяч оп./с, быстродействие ЭВМ в СОК на определенном классе задач достигало миллиона оп./с. Машины Акушского успешно использовались в интересах ПВО страны.
Лекция 2. Компьютер - общие сведения
Компьютер, по существу, устройство способное исполнять четко определенную последовательность операций, предписанную программой. Очень грубо, все многообразие компьютеров можно разделить на три основных класса: персональные системы (от настольных, до карманных), мейнфреймы и сервера на их основе и суперкомпьютеры. Мы начнем изучение этой области знания со структуры персонального компьютера. ПК характерен тем, что им может пользоваться один человек, не обладающий высокой квалификацией. На основе персональных компьютеров можно строить самые сложные контрольно-измерительные, управляющие, вычислительные и информационные системы. Имеющиеся в персональном компьютере аппаратные и программные средства делают его универсальным инструментом для самых разных задач. В случае вычислительных и информационных систем персональный компьютер не нуждается в подключении нестандартной аппаратуры, все сводится к подбору или написанию необходимого программного обеспечения. В случае же контрольно-измерительных и управляющих систем персональный компьютер оснащается набором инструментов для сопряжения с внешними устройствами и соответствующими программными средствами. Во многих случаях строить систему на основе персонального компьютера оказывается гораздо проще, быстрее и даже дешевле, чем проектировать ее с нуля на базе какого-то микропроцессора, микропроцессорного комплекта или микроконтроллера.
Конечно, в большинстве случаев система на основе персонального компьютера оказывается сильно избыточной, это плата за универсальность. Но в то же время один и тот же компьютер может решать самые разнообразные задачи. Например, в системе управления технологическими процессами или научными установками он может математически моделировать происходящие процессы, выдавать в реальном времени управляющие сигналы, принимать в реальном времени ответные сигналы, накапливать информацию, обрабатывать ее, обмениваться информацией с другими компьютерами и т. д. Развитый интерфейс пользователя (видеомонитор, полноразмерная клавиатура, мышь) делают работу с персональным компьютером комфортной и эффективной. А стоимость персональных компьютеров вследствие большого объема выпуска постоянно снижается. Поэтому их использование не только удобно, но и экономически выгодно.
Материнская плата
Основные электронные компоненты, определяющие структуру компьютера, размещаются на основной плате компьютера, которая называется системной или материнской (Mother Board). А контроллеры и адаптеры дополнительных устройств, либо сами эти устройства, выполняются в виде плат расширения (Dаughter Board -- дочерняя плата) и подключаются к шине с помощью разъемов расширения, называемых также слотами расширения (англ. slot -- щель, паз).
Функции основных узлов компьютера следующие:
Центральный процессор (ЦПУ) -- это микропроцессор со всеми необходимыми вспомогательными микросхемами, включая внешнюю кэш-память и контроллер системной шины. (О кэш-памяти подробнее будет рассказано в следующих разделах). В большинстве случаев именно центральный процессор осуществляет обмен по системной шине.
Оперативная память (ОП) может занимать почти все адресуемое пространство памяти процессора. Однако чаще всего ее объем гораздо меньше. В современных персональных компьютерах стандартный объем системной памяти составляет, как правило, от 512 до 1 Гбайт. Оперативная память компьютера выполняется на микросхемах динамической памяти и поэтому требует регенерации.
Постоянная память (ПП) (ROM - BIOS Base Input/Output System) имеет небольшой объем (до 64 Кбайт), содержит программу начального запуска, описание конфигурации системы, а также драйверы (программы нижнего уровня) для взаимодействия с системными устройствами.
Внешняя память организуется, как правило, на магнитных и оптических дисках, магнитных лентах. Объем, по существу, не ограничен.
Контроллер прерываний преобразует аппаратные прерывания системной магистрали в аппаратные прерывания процессора и задает адреса векторов прерывания. Все режимы функционирования контроллера прерываний задаются программно процессором перед началом работы.
Контроллер прямого доступа к памяти принимает запрос на ПДП из системной магистрали, передает его процессору, а после предоставления процессором магистрали производит пересылку данных между памятью и устройством ввода/вывода. Все режимы функционирования контроллера ПДП задаются программно процессором перед началом работы. Использование встроенных в компьютер контроллеров прерываний и ПДП позволяет существенно упростить аппаратуру применяемых плат расширения.
Контроллер регенерации осуществляет периодическое обновление информации в динамической оперативной памяти путем проведения по шине специальных циклов регенерации.
Часы реального времени и таймер-счетчик -- это устройства для внутреннего контроля времени и даты, а также для программной выдержки временных интервалов, программного задания частоты и синхронизации всех процессов.
Системные устройства ввода/вывода -- это те устройства, которые необходимы для работы компьютера и взаимодействия со стандартными внешними устройствами по параллельному и последовательному интерфейсам. Они могут быть выполнены на материнской плате, а могут располагаться на платах расширения.
Платы расширения устанавливаются в слоты (разъемы) системной магистрали и могут содержать оперативную память и устройства ввода/вывода. Они могут обмениваться данными с другими устройствами на шине в режиме программного обмена, в режиме прерываний и в режиме ПДП. Предусмотрена также возможность захвата шины, то есть полного отключения от шины всех системных устройств на некоторое время.
Важная особенность подобной архитектуры -- ее открытость, то есть возможность включения в компьютер дополнительных устройств, причем как системных устройств, так и разнообразных плат расширения. Открытость предполагает также возможность простого встраивания программ пользователя на любом уровне программного обеспечения компьютера. Первый компьютер семейства, получивший широкое распространение, IBM PC XT, был выполнен на базе оригинальной системной магистрали PC XT-Bus. В дальнейшем (начиная с IBM PC AT) она была доработана до магистрали, ставшей стандартной и получившей название ISA (Industry Standard Architecture). До недавнего времени ISA оставалась основой компьютера. Однако, начиная с появления процессоров i486 (в 1989 году), она перестала удовлетворять требованиям производительности, и ее стали дублировать более быстрыми шинами: VLB (VESA Local Bus) и PCI (Peripheral Component Interconnect bus) или заменять совместимой с ISA магистралью EISA (Enhanced ISA). Постепенно шина параллельная PCI вытеснила конкурентов и стала фактическим стандартом, однако сегодня господствует тенденция перехода от параллельных к последовательным способам передачи данных. Так интерфейс жесткого диска эволюционировал от параллельных IDE, EIDE, SCASI к последовательному интерфейсу Serial ATA с 4рех жильным кабелем, т. е. от пропускной способности 33 Мбит/с к 600 Мбит/с. Знаменитая PCI эволюционировала в последовательную PCI Express с ее рекордной скоростью на уровне 5 Гбит/с в полнодуплексном режиме. При этом в архитектуре компьютера появились чисто сетевые компоненты - мосты, коммутаторы и маршрутизаторы, что нашло свое отражение в конструкции чипсетов.
Интерфейсные шины
Другое направление совершенствования архитектуры персонального компьютера связано с максимальным ускорением обмена информацией с системной памятью. Именно из системной памяти компьютер читает все исполняемые команды, и в системной же памяти он хранит данные. То есть больше всего обращений процессор совершает именно к памяти. Ускорение обмена с памятью приводит к существенному ускорению работы всей системы в целом. Но при использовании для обмена с памятью системной магистрали приходится учитывать скоростные ограничения магистрали. Системная магистраль должна обеспечивать сопряжение с большим числом устройств, поэтому она должна иметь довольно большую протяженность; она требует применения входных и выходных буферов для согласования с линиями магистрали. Циклы обмена по системной магистрали сложны, и ускорять их нельзя. В результате существенного ускорения обмена процессора с памятью по магистрали добиться невозможно.
Разработчиками был предложен следующий подход. Системная память подключается не к системной магистрали, а к специальной высокоскоростной шине, находящейся "ближе" к процессору, не требующей сложных буферов и больших расстояний. В таком случае обмен с памятью идет с максимально возможной для данного процессора скоростью, и системная магистраль не замедляет его. Особенно актуальным это становится с ростом быстродействия процессора (сейчас тактовые частоты процессоров персональных компьютеров достигают 1--3 ГГц).
Таким образом, структура персонального компьютера из одношинной, применявшейся только в первых компьютерах, становится трехшинной.
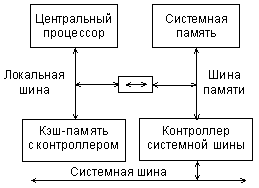
Рис. 2.2. Организация связей в случае трехшинной структуры.
Назначение шин следующее:
К локальной шине подключаются центральный процессор и кэш-память (быстрая буферная память);
К шине памяти подключается оперативная и постоянная память компьютера, а также контроллер системной шины;
К системной шине (магистрали) подключаются все остальные устройства компьютера.
Все три шины имеют адресные линии, линии данных и управляющие сигналы. Но состав и назначение линий этих шин не совпадают между собой, хотя они и выполняют одинаковые функции. С точки зрения процессора, системная шина (магистраль) в системе всего одна, по ней он получает данные и команды и передает данные как в память, так и в устройства ввода/вывода. Временные задержки между системной памятью и процессором в данном случае минимальны, так как локальная шина и шина памяти соединены только простейшими быстродействующими буферами. Еще меньше задержки между процессором и кэш-памятью, подключаемой непосредственно к локальной шине процессора и служащей для ускорения обмена процессора с системной памятью. Как правило, в компьютере применяются две и более системные шины, например, EISA, PCI и PCI Express. Каждая из них имеет свой собственный контроллер, и работают они параллельно. В этом случае получается многошинная структура компьютера, но на этом мы остановимся в лекции посвященной интерфейсам компьютера.
Основные внешние устройства компьютера
Клавиатура служит для ввода информации в компьютер и подачи управляющих сигналов. Она содержит стандартный набор алфавитно-цифровых клавиш и некоторые дополнительные клавиши -- управляющие и функциональные, клавиши управления курсором, а также малую цифровую клавиатуру.
Видеосистема компьютера состоит из трех компонент:
- - монитор (называемый также дисплеем); - видеоадаптер; - программное обеспечение (драйверы видеосистемы).
Видеоадаптер посылает в монитор сигналы управления яркостью лучей и синхросигналы строчной и кадровой разверток. Монитор преобразует эти сигналы в зрительные образы. А программные средства обрабатывают видеоизображения -- выполняют кодирование и декодирование сигналов, координатные преобразования, сжатие изображений и др.
Подавляющее большинство мониторов сконструированы на базе электронно-лучевой трубки (ЭЛТ), и принцип их работы аналогичен принципу работы телевизора. Мониторы бывают алфавитно-цифровые и графические, монохромные и цветного изображения. Современные компьютеры комплектуются, как правило, цветными графическими мониторами.
Наряду с традиционными ЭЛТ-мониторами все шире используются плоские жидкокристаллические (ЖК) мониторы.
Жидкие кристаллы -- это особое состояние некоторых органических веществ, в котором они обладают текучестью и свойством образовывать пространственные структуры, подобные кристаллическим. Жидкие кристаллы могут изменять свою структуру и светооптические свойства под действием электрического напряжения. Меняя с помощью электрического поля ориентацию групп кристаллов и используя введенные в жидкокристаллический раствор вещества, способные излучать свет под воздействием электрического поля, можно создать высококачественные изображения, передающие более 15 миллионов цветовых оттенков.
Большинство ЖК-мониторов использует тонкую пленку из жидких кристаллов, помещенную между двумя стеклянными пластинами. Заряды передаются через так называемую пассивную матрицу -- сетку невидимых нитей, горизонтальных и вертикальных, создавая в месте пересечения нитей точку изображения (несколько размытого из-за того, что заряды проникают в соседние области жидкости).
Активные матрицы вместо нитей используют прозрачный экран из транзисторов и обеспечивают яркое, практически не имеющее искажений изображение. Панель при этом разделена на 308160 (642х480) независимых ячеек, каждая из которых состоит из четырех частей (для трех основных цветов и одна резервная). Таким образом, экран имеет почти 1,25 млн точек, каждая из которых управляется собственным транзистором.
По компактности такие мониторы не знают себе равных. Они занимают в 2 - 3 раза меньше места, чем мониторы с ЭЛТ и во столько же раз легче; потребляют гораздо меньше электроэнергии и не излучают электромагнитных волн, воздействующих на здоровье людей.
Разновидность монитора -- сенсорный экран. Здесь общение с компьютером осуществляется путем прикосновения пальцем к определенному месту чувствительного экрана. Этим выбирается необходимый режим из меню, показанного на экране монитора.
Меню -- это выведенный на экран монитора список различных вариантов работы компьютера, по которому можно сделать конкретный выбор.
Сенсорными экранами оборудуют рабочие места операторов и диспетчеров, их используют в информационно-справочных системах и т. д.
Видеоадаптер -- это электронная плата, которая обрабатывает видеоданные (текст и графику) и управляет работой дисплея. Содержит видеопамять, регистры ввода вывода и модуль BIOS. Посылает в дисплей сигналы управления яркостью лучей и сигналы развертки изображения.
Наиболее распространенный видеоадаптер на сегодняшний день -- адаптер SVGA (Super Video Graphics Array -- супервидеографический массив), который может отображать на экране дисплея 1280х1024 пикселей при 256 цветах и 1024х768 пикселей при 16 - 32 миллионах цветов.
С увеличением числа приложений, использующих сложную графику и видео, наряду с традиционными видеоадаптерами широко используются разнообразные устройства компьютерной обработки видеосигналов:
Графические акселераторы (ускорители) -- специализированные графические сопроцессоры, увеличивающие эффективность видеосистемы. Их применение освобождает центральный процессор от большого объема операций с видеоданными, так как акселераторы самостоятельно вычисляют, какие пиксели отображать на экране и каковы их цвета.
Фрейм-грабберы, которые позволяют отображать на экране компьютера видеосигнал от видеомагнитофона, камеры, лазерного проигрывателя и т. п., с тем, чтобы захватить нужный кадр в память и впоследствии сохранить его в виде файла.
TV-тюнеры -- видеоплаты, превращающие компьютер в телевизор. TV-тюнер позволяет выбрать любую нужную телевизионную программу и отображать ее на экране в масштабируемом окне. Таким образом можно следить за ходом передачи, не прекращая работу.
Аудиоадаптер (Sound Blaster или звуковая плата) это специальная электронная плата, которая позволяет записывать звук, воспроизводить его и создавать программными средствами с помощью микрофона, наушников, динамиков, встроенного синтезатора и другого оборудования. Аудиоадаптер содержит в себе два преобразователя информации:
- - аналого-цифровой, который преобразует непрерывные (то есть, аналоговые) звуковые сигналы (речь, музыку, шум) в цифровой двоичный код и записывает его на магнитный носитель; - цифро-аналоговый, выполняющий обратное преобразование сохраненного в цифровом виде звука в аналоговый сигнал, который затем воспроизводится с помощью акустической системы, синтезатора звука или наушников.
Модем -- устройство для передачи компьютерных данных на большие расстояния по телефонным линиям связи, выделенной 4хпроводной линии или радио каналам.
Цифровые сигналы, вырабатываемые компьютером, нельзя напрямую передавать по телефонной сети, потому что она предназначена для передачи человеческой речи -- непрерывных сигналов звуковой частоты.
Модем обеспечивает преобразование цифровых сигналов компьютера в аналоговый сигнал звукового диапазона -- этот процесс называется модуляцией, а также обратное преобразование, которое называется демодуляцией. Отсюда название устройства: модем -- модулятор/демодулятор.
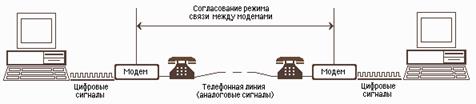
Рис 2.3 Схема реализации модемной связи
Для осуществления связи один модем вызывает другой по номеру телефона, а тот отвечает на вызов. Затем модемы посылают друг другу сигналы, согласую подходящий им обоим режим связи. После этого передающий модем начинает посылать модулированные данные с согласованными скоростью (количеством бит в секунду) и форматом. Модем на другом конце преобразует полученную информацию в цифровой вид и передает ее своему компьютеру. Закончив сеанс связи, модем отключается от линии.
Управление модемом осуществляется с помощью специального коммутационного программного обеспечения.
Модемы бывают внешние, выполненные в виде отдельного устройства, и внутренние, представляющие собой электронную плату, устанавливаемую внутри компьютера. Почти все модемы поддерживают и функции факсов.
Факс -- это устройство факсимильной передачи изображения по телефонной сети. Название "факс" произошло от слова "факсимиле" (лат. fac simile -- сделай подобное), означающее точное воспроизведение графического оригинала (подписи, документа и т. д.) средствами печати. Модем, который может передавать и получать данные как факс, называется факс-модемом.
Манипуляторы (мышь, джойстик и др.) -- это специальные устройства, которые используются для управления курсором.
Мышь имеет вид небольшой коробки, полностью умещающейся на ладони. Мышь связана с компьютером кабелем через специальный блок -- адаптер, и ее движения преобразуются в соответствующие перемещения курсора по экрану дисплея. В верхней части устройства расположены управляющие кнопки (обычно их три), позволяющие задавать начало и конец движения, осуществлять выбор меню и т. п.
Джойстик -- обычно это стержень-ручка, отклонение которой от вертикального положения приводит к передвижению курсора в соответствующем направлении по экрану монитора. Часто применяется в компьютерных играх. В некоторых моделях в джойстик монтируется датчик давления. В этом случае, чем сильнее пользователь нажимает на ручку, тем быстрее движется курсор по экрану дисплея.
Трекбол -- небольшая коробка с шариком, встроенным в верхнюю часть корпуса. Пользователь рукой вращает шарик и перемещает, соответственно, курсор. В отличие от мыши, трекбол не требует свободного пространства около компьютера, его можно встроить в корпус машины.
Дигитайзер -- устройство для преобразования готовых изображений (чертежей, карт) в цифровую форму. Представляет собой плоскую панель -- планшет, располагаемую на столе, и специальный инструмент -- перо, с помощью которого указывается позиция на планшете. При перемещении пера по планшету фиксируются его координаты в близко расположенных точках, которые затем преобразуются в компьютере в требуемые единицы измерения.
Принтеры (печатающие устройства) - это устройства вывода данных из ЭВМ, преобразующие информационные ASCII-коды в соответствующие им графические символы (буквы, цифры, знаки и т. п.) и фиксирующие эти символы на бумаге.
Сканер - это устройство ввода в ЭВМ информации непосредственно с бумажного документа. Можно вводить тексты, схемы, рисунки, графики, фотографии и другую графическую информацию.
Сканеры являются важнейшим звеном электронных систем обработки документов и необходимым элементом любого "электронного стола". Записывая результаты своей деятельности в файлы и вводя информацию с бумажных документов в ПК с помощью сканера с системой автоматического распознавания образов, можно сделать реальный шаг к созданию систем безбумажного делопроизводства.
Сканеры весьма разнообразны, и их можно классифицировать по целому ряду признаков. Сканеры бывают черно-белые и цветные.
Выводы
Большинство вычислительных машин имеет один и тот же набор функциональных блоков-модулей.
ПК характерен тем, что им может пользоваться один человек, не обладающий высокой квалификацией.
На основе персональных компьютеров можно строить самые сложные контрольно-измерительные, управляющие, вычислительные и информационные системы.
Все возрастающие требования высокого быстродействия привели к многошинной структуре персонального компьютера.
Вопросы и задания
Что такое поколения ЭВМ и по каким признакам они различаются?
Перечислите все функциональные узлы ЭВМ и объясните назначение каждого.
Дайте понятие адреса, адресного пространства, линейного адреса, разрядности шины адреса.
Что такое контроллер, интерфейс, системный интерфейс?
Лекция 3. Многоуровневая компьютерная организация
Организация взаимодействия между всеми элементами компьютера является чрезвычайно сложной задачей. Как известно, для решения сложных задач используется универсальный прием - декомпозиция, то есть разбиение одной сложной задачи на несколько более простых задач-модулей. Декомпозиция состоит в четком определении функций каждого модуля, а также порядка их взаимодействия. При декомпозиции часто используют многоуровневый подход.
Компьютер, как и любая сложная система, обладает многоуровневой организацией при которой абстракции более высокого уровня не только надстраиваются над абстракциями более низкого уровня, но и органично включают их в свой состав. Многоуровневая компьютерная организация иногда называется архитектурой компьютера.
Архитектура компьютера
Применительно к вычислительным системам в целом термин "архитектура" можно интерпретировать как распределение функций, реализуемых системой, по ее уровням и определение интерфейсов между этими уровнями. Очевидно, архитектура вычислительной системы предполагает многоуровневую, иерархическую организацию.
Взаимодействие между различными уровнями осуществляется посредством интерфейсов. Например, система в целом взаимодействует с внешним миром через набор интерфейсов: языки высокого уровня, системные программы и т. д. Большинство современных вычислительных систем состоят из трех и более уровней.
На самом нижнем уровне (нулевом) - цифровом логическом уровне, объекты называются вентилями или переключателями. Эти переключатели могут находиться в одном из двух устойчивых состояний: переключатель включен или выключен, конденсатор заряжен или разряжен, магнитный домен намагничен или нет, транзистор находится в проводящем состоянии или непроводящем и т. п. Одно из таких физических состояний создает высокий уровень выходного напряжения (например, 4 В), а другое - низкий (например, 0 В). В компьютере эти электрические напряжения принимаются соответственно за 1 (логическая) и 0 (логический). Хотя возможно и обратное кодирование.
Следующий уровень - микроархитектурный уровень. На этом уровне можно анализировать совокупности логических схем, например АЛУ, оперативную память, регистры. Регистры вместе с АЛУ формируют тракт данных, обеспечивающий тот или иной алгоритм выполнения арифметической или логической операции. Иногда, работа тракта данных регулируется особой программой - микропрограммой. Сейчас чаще всего тракт данных контролируется аппаратным обеспечением.
Второй уровень называется уровнем архитектуры системы команд. В процессе работы МП обслуживает данные, находящиеся в его регистрах, в поле ОП, а также во внешних портах ЭВМ. Часть данных он интерпретирует как непосредственно данные, часть как адресные данные, а часть как команды. Совокупность всех возможных команд образует систему команд процессора. Именно система команд (расширенная или сокращенная) разделяет процессоры на RISC, CISC или векторные, суперскалярные и т. д. Машинная команда состоит из двух частей: операционной и адресной. Операционная часть команды - это группа разрядов в команде, предназначенная для предоставления кода операции машины (КОП). Адресная часть команды - это группа разрядов, в которых записываются коды адреса ячеек памяти машины. Часто эти адреса называются адресами операндов, т. е. чисел, участвующих в операции. По количеству адресов, записываемых в команде, команды делятся на безадресные, одно -, двух - и трехадресные. Типовая структура трехадресной команды:
Современные ЭВМ выполняют несколько сотен различных команд, структура команд, их сложность и длина определяют архитектуру процессора. Все машинные команды можно разделить на группы по видам выполняемых операций:
Операции пересылки информации внутри ЭВМ;
Арифметические операции над информацией;
Логические операции над информацией;
Операции обращения к внешним устройствам ЭВМ;
Операции передачи управления;
Обслуживающие и вспомогательные операции.
Следующий уровень - уровень ОС обычно гибридный. Большинство команд в его языке есть также и на уровне архитектуры системы команд. Далее идут высокоуровневые блоки, которые уже предназначены для прикладных программистов, первые три для системных программистов. На рисунке 3.1 показан пример такого подхода.
Классическая структура ЭВМ - модель фон Неймана
В каждой области науки и техники существуют некоторые фундаментальные идеи или принципы, которые определяют ее содержание и развитие. В компьютерной науке роль таких фундаментальных идей сыграли принципы, сформулированные независимо друг от друга двумя гениями современной науки - американским математиком и физиком Джоном фон Нейманом и советским инженером и ученым Сергеем Лебедевым.
Принято считать, что первый электронный компьютер ENIAC был изготовлен в США в 1946 г. (если мы на минуточку забудем, что уже в 1941 году цифровая машина Z1 и Z2 Конрада Цузе расчитывала траекторию ракет обстреливающих Лондон). Блестящий анализ сильных и слабых сторон проекта ENIAC был дан в отчете Принстонского института перспективных исследований "Предварительное обсуждение логического конструирования электронного вычислительного устройства" (июнь 1946 г.). Этот отчет, составленный выдающимся американским математиком Джоном фон Нейманом и его коллегами по Принстонскому институту Г. Голдстайном и А. Берксом, представлял проект нового электронного компьютера. Идеи, высказанные в этом отчете, известные под названием "Неймановских Принципов", оказали серьезное влияние на развитие компьютерной техники.
Сущность "Неймановских Принципов" состояла в следующем:
Двоичная система счисления - компьютеры на электронных элементах должны работать не в десятичной, а в двоичной системе счисления;
Принцип программного управления и хранимой в памяти программы - компьютер работает под управлением программы, программа должна размещаться в одном из блоков компьютера - в запоминающем устройстве (первоначально программа задавалась путем установки перемычек на коммутационной панели);
Принцип однородности - команды, так же как и данные, с которыми оперирует компьютер, хранятся в одном блоке памяти и записываются в двоичном коде, то есть по форме представления команды и данные однотипны и хранятся в одной и той же области памяти;
Принцип адресности - основная память структурно состоит из нумерованных ячеек, т. е. доступ к командам и данным осуществляется по адресу. Трудности физической реализации запоминающего устройства большого быстродействия и большой памяти требуют иерархической организации памяти;
В компьютере используется параллельный принцип организации вычислительного процесса (операции над двоичными кодами осуществляются одновременно над всеми разрядами).
В Советском Союзе работы по созданию электронных компьютеров были начаты несколько позже. Первый советский электронный компьютер был изготовлен в Киеве в 1953 г. Он назывался МЭСМ (малая электронная счетная машина), а его главным конструктором был академик Сергей Лебедев, автор проектов компьютеров серии БЭСМ (большая электронная счетная машина).
Самой важной отличительной чертой модели фон Неймана был и остается принцип единой линейной памяти, которая адресуется последовательными адресами и в которой команды неотличимы от данных. Структура ЭВМ фон Неймана приведена на рис. 3.2.
Представления данных как чисел и соответствующий характер команд с самого начала определили выбор архитектуры, ориентированной на числовую обработку. Обычно в этих ЭВМ данные представляются в виде скалярных данных, векторов и матриц. Числа в ЭВМ представляются как целые. Таким образом, ЭВМ с архитектурой фон Неймана, это ЭВМ с управлением потоком команд. Принято считать, что ВМ с архитектурой фон Неймана присущи следующие особенности:1. единая, последовательно адресуемая память (обычные скалярные однопроцессорные системы, при этом наличие конвейера не меняет дела);2. память является линейной и одномерной (одномерная - имеет вид вектора слов, память состоит из ячеек фиксированной длины и имеет линейную структуру адресации); 3. отсутствует явное различие между командами и данными;
- 4. ход выполнения вычислительного процесса определяется только централизованными и последовательными командами или, другими словами, управление потоком команд (выбрать адрес команды - выбрать данные - произвести действие и т. д.); 5. назначение данных не является их неотъемлемой, составной частью, назначение данных определяется логикой программы.
Нет никаких средств, позволяющих отличить набор битов, представляющих число с плавающей точкой, от набора битов, являющихся строкой символов. Если процессор извлекает из ОП команду сложения чисел с плавающей точкой и над ними выполняется сложение согласно правилам арифметики с плавающей точкой, хотя в действительности они могут быть просто строкой символов. Снова обратимся к "принципам Неймана". Существенно подчеркнуть, что центральное место среди "принципов Неймана" занимает предложение об использовании двоичной системы счисления, что было обусловлено рядом обстоятельств. Во-первых, несомненными арифметическими достоинствами двоичной системы счисления, ее "оптимальным" согласованием с "булевой" логикой и простотой технической реализации двоичного элемента памяти (триггера).
Однако на определенном этапе развития компьютерной техники было обнаружено ряд недостатков классической двоичной системы счисления. Первым из них является так называемая "проблема представления отрицательных чисел". Как известно, отрицательные числа непосредственно не могут быть представлены в классической двоичной системе счисления, использующей только две двоичные цифры 0 и 1, без дополнительных "ухищрений". Основным "ухищрением" является использование специальных кодов для представления отрицательных чисел - обратного или дополнительного.
Второй недостаток двоичной системы счисления - ее "нулевая избыточность". Дело в том, что если в процессе передачи, хранения или обработки двоичной кодовой комбинации, например 10011010, под влиянием "помех", действующих в "канале", произойдет искажение данной кодовой комбинации и она перейдет в кодовую комбинацию 11010010 (искажения отдельных битов подчеркнуты), то, поскольку комбинация 11010010 (как и любая другая двоичная кодовая комбинация) является "разрешенной" в классической двоичной системы счисления, то не существует способа обнаружить данную ошибку без дополнительных "ухищрений", то есть без использования специальных методов избыточного кодирования.
Третий недостаток более серьезен. Применение двоичной булевой логики необходимо приводит к появлению условия синхронности в процессорах. Двоичная логика не включает в себя условие завершения функции, а это значит, что она может существовать только на фоне соответствующей временной диаграммы. Другими словами наряду с потоком данных и команд должен существовать поток управляющих импульсов, или "стробов", поступающих от системных часов. Последствия этого явления очень значительны и будут рассмотрены позже.
Особенности современных ЭВМ
Естественно, что бурное развитие новых технологий производства средств вычислительной техники привело к появлению целого ряда новшеств и особенностей. Эти отличительные особенности вычислительных машин, появившихся после EDVAC, сводятся к следующим:
Индексные регистры. Позволяют формировать адреса памяти добавлением содержимого указанного регистра к содержимому поля команды. Этот принцип впервые реализован в 1949г. в ЭВМ Манчестерского университета и использован в 1953г. фирмой Electro Data Corporation при производстве ЭВМ Datatron.
Регистры общего назначения. Благодаря этой группе регистров устраняется различие между индексными регистрами и аккумуляторами и в распоряжении пользователя оказывается не один, а несколько регистров-аккумуляторов. Впервые это решение было применено, вероятно, в ЭВМ Pegasus фирмы Ferranti (1956г.).
Представление данных в форме с плавающей точкой. Представление данных в виде мантиссы и порядка и выполнение операций над ними было реализовано в 1954г. в вычислительных машинах NORC и 704 фирмы IBM.
Косвенная адресация. Средство позволяющее использовать команды, указывающие адреса, по которым в свою очередь находится информация о местоположении операндов команд. Принцип косвенной адресации был реализован в 1958г. в ЭВМ 709 фирмы IBM.
Программные прерывания. При возникновении некоторого внешнего события состояние вычислительной системы, связанное с выполнением прерванной команды, запоминается в определенной области. Этот принцип впервые был применен в 1954г. в машине Univac1103.
Асинхронный ввод-вывод. Параллельно обычному выполнению команд независимые процессоры управляют операциями ввода-вывода. Первой ЭВМ с независимым процессором ввода-вывода являлась ЭВМ709 фирмы IBM (1958г.).
Виртуальная память. Определение адресного пространства программы осуществляется без "привязки" к физическим областям памяти обычно с целью создания впечатления, что вычислительная система имеет больший объем основной памяти, чем тот, которым она фактически располагает. В 1959г. в вычислительной системе Atlas Манчестерского университета были реализованы принципы разделения памяти на страницы и динамическая трансляция адресов аппаратными средствами.
Мультипроцессорная обработка. Два или более независимых процессора обрабатывают потоки команд из общей памяти. Не ясно, кто был первооткрывателем такого способа обработки, однако, в конце 50-х начале 60-х годов, он был реализован в вычислительных машинах Sage фирмы IBM, Sperri-Univac LARC и D825 фирмы Burroughs.
Существенное противоречие между высокой скоростью обработки данных в процессоре и низкой скоростью работы устройств ввода/вывода потребовало высвобождения ЦПУ от функций передачи информации и предоставления этих функций специальным устройствам - контроллерам и интерфейсам. Трудно перечислить все особенности современных компьютеров и систем, да и ненужно. Постараемся их раскрыть по мере изучения дальнейшего материала.
Выводы
Архитектура вычислительной системы предполагаем многоуровневую, иерархическую организацию.
Взаимодействие между различными уровнями осуществляется посредством интерфейсов. Например, система в целом взаимодействует с внешним миром через набор интерфейсов: языки высокого уровня, системные программы и т. д.
Решение задач на ЭВМ реализуется программным способом, т. е. путем выполнения
Последовательно во времени отдельных операций над информацией, предусмотренных алгоритмом решения задачи.
Классическая структура ЭВМ отвечает модели Фон Неймана. Современные ЭВМ далеко ушли от этой модели, но по-прежнему имеют большое число общих черт, например - двоичная система счисления, управление потоком команд
Система программного (математического) обеспечения ЭВМ представляет собой комплекс программных средств, в котором можно выделить операционную систему. Операционная система - предназначена для эффективного управления вычислительным процессом, планирования работы и распределения ресурсов
Вопросы и задания
Какие задачи решает цифровой логический уровень?
Что умеет делать АЛУ?
Чем вызвано многообразие форматов и размеров команд?
Какова роль ОС?
Компьютер по Фон Нейману - основные черты, недостатки и достоинства.
Лекция 4. Математическое обеспечение компьютеров
Иногда говорят, что вычислительная техника (hardware) без программ, олицетворяющих действия людей по управлению ею, мертва и бездушна как всякое железо. И только программное обеспечение (software) вдыхает жизнь в эти кристаллы, разъемы и провода, заставляет компьютеры делать все те чудеса, которым мы не перестаем удивляться.
Пакеты прикладных программ представляют собой структурированные комплексы программ (часто со специализированными языковыми средствами), предназначенные для решения определенных задач, а также для расширения функций ОП (управления базами данных и др.). Аппаратные средства ЭВМ и система ее программного обеспечения образуют вычислительную систему. За более чем полувековую историю развития ЭВМ многие поколения программистов создали гигантский объем программного обеспечения (ПО). Зачастую он создавался стихийно, под влиянием различных обстоятельств, поэтому чтобы разобраться в этом многообразии попробуем создать некоторую классификацию.
Прежде всего, все программное обеспечение можно разделить на общее и специальное. Общее ПО рассчитано на самый широкий круг пользователей и используется почти на каждом компьютере. Специальное ПО разрабатывается для решения конкретной задачи, оно как правило уникально. В качестве примера укажем на разнообразные бухгалтерские и банковские системы, которые часто разрабатываются под заказ, хотя есть и исключения. Общее ПО, в свою очередь, подразделяется на системное, служащее для разработки программ и поддержки вычислительного процесса на компьютере (операционные системы, системы программирования, различные вспомогательные программы) и прикладное, иначе называемое пакетами прикладных программ (ППП). Типичными ППП являются текстовые процессоры, системы управления базами данных (СУБД), электронные таблицы, некоторые другие широко распространенные программы. Граница раздела между упомянутыми классами весьма условна и в процессе эволюции постоянно передвигается в пользу общего ПО.
Общее программное обеспечение -- это ценнейший интеллектуальный ресурс, накопленный человечеством за последние полвека. В его разработку вложены миллионы человеко - лет труда нескольких поколений программистов, потрачены многие миллиарды долларов. Каждое десятилетие внесло свой существенный вклад в формирование общего ПО.
- * 50-е годы: библиотеки стандартных программ, низкоуровневые языки и системы автоматизации программирования (ассемблеры и автокоды); * 60-е годы: высокоуровневые языки и системы автоматизации программирования, пакетные операционные системы; * 70-е годы: диалоговые операционные системы, системы управления базами данных (СУБД); * 80-е годы: пакеты прикладных программ для персональных компьютеров, системы автоматизации проектирования (CASE); * 90-е годы: программное обеспечение компьютерных сетей, мультимедиа.
Библиотеки стандартных программ и ассемблеры
Первые вычислительные машины вообще не имели никакого общего программного
Обеспечения. Программы для решения конкретных задач писались с нуля, в машинных двоичных кодах (для сокращения записи использовалась восьмеричная или шестнадцатеричная система, но это не меняло сути) в абсолютных адресах, они загружались в чистую оперативную память. Процесс был мучительным и трудоемким. Приходилось помнить двоичные коды всех операций, а любую подпрограмму выписывать из справочника в условных адресах, затем вручную привязывать к главной программе, распределять память и т. д. На каждом этапе возникали ошибки, поэтому отладить программу даже в тысячу команд было уже очень трудно. Первоочередной задачей программистов на данном этапе было создание библиотек, которые обеспечивали бы вызов стандартных программ из внешней памяти и автоматически подключали их к
Главной программе.
Вторая проблема была связана с мнемоническим кодированием и автоматическим распределением памяти. Впервые она была решена в Кембридже в Великобритании на ЭВМ EDSAC (1949 г.). Вместо того, чтобы записывать коды операций двоичными цифрами программист писал текст программы на символическом языке, пользуясь мнемоническими обозначениями операций и условными адресами, а специальная программа (руководитель проекта Морис Уилкс назвал ее собирающей системой -- по английски assembly system) автоматически преобразовывала мнемонические коды в понятные машине двоичные, и распределяла память для выполнения программы. Идея оказалась столь продуктивной, что все последующие поколения программистов на всех ЭВМ отказались от абсолютного кодирования. Языки программирования низкого уровня, в которых коды операций заменены мнемоническими обозначениями, стали называться языками ассемблера или автокодами (мнемокодами), а преобразующие программы -- ассемблерами.
Высокоуровневые языки и системы автоматизированного программирования
В 60-е годы объем производства ЭВМ резко возрос, появились разнообразные машины второго поколения, они вышли из узких стен научных и военных учреждений, начали использоваться в бизнесе. Резко расширился круг решаемых задач, соответственно возросло и число людей, занятых программированием. Языки низкоуровневого кодирования, реализованные в ассемблерах, ненамного облегчили их тяжкий труд. Голубой мечтой казалась возможность полной автоматизации программирования, когда программист пишет математические формулы на привычном символическом языке, а компьютер самостоятельно преобразовывает их в тексты машинных программ.
Языки и системы программирования наиболее бурно развивались в 60-е годы, когда были разработаны основные принципы их построения и родились многие сотни языков различного назначения. В результате естественного отбора до конца века дожили немногие "великие языки", в которых воплощены пять основных концепций современного программирования:
- * процедурное программирование, составляющее основу классических алгоритмических языков Фортран, Бэйсик, Кобол, Алгол, Си и др.; * объектно-ориентированное программирование (ООП), в чистом виде присутствующее в языке Smalltalk, и в той или иной степени -- во всех современных языках; * визуально-событийное программирование, являющиеся развитием ООП в части работы с особыми классами визуальных объектов, реализованное в визуальных средах Visual Basic, Delphi, Visual Fux Pro, Visual C++, Visual Age, Java и др.; * функциональное программирование, реализованное в языке обработки списков Лисп; * логическое программирование, воплощенное в декларативном языке Пролог.
Диалоговые ОС и СУБД
70-е годы -- время безраздельного господства унифицированных машин из клона IBM 360/370. Компьютеры по-прежнему были безумно дороги, но их мощность и надежность резко возросли. Начали создаваться крупные информационные системы для промышленных и торговых предприятий, банков, социальных учреждений. Пользователи перестали бегать с колодами перфокарт -- на их рабочих местах появились дисплеи, подключенные к центральной ЭВМ, расположенной в вычислительном центре фирмы. Для организации вычислительного процесса в этих условиях понадобились операционные системы нового типа, позволяющие организовать диалог большого числа пользователей в режиме разделения времени. Родина таких систем -- Массачусетский технологический институт (МТИ), где, начиная с середины 60-х годов, проводились экспериментальные работы, но крупные промышленные диалоговые ОС разрабатывались фирмами -- производителями аппаратуры. Создание крупных информационных систем поставило перед разработчиками общего ПО проблему хранения больших массивов данных и организации их обработки множеством независимых программ. Так возникла концепция систем управления базами данных (СУБД). Разработка эффективных СУБД оказалась задачей не мене трудоемкой, чем проектирование ОС, первая промышленная СУБД IMS для IBM 360/370 была создана корпорацией IBM в 19691970 годах в рамках проекта полета человека на Луну "Аполлон" и потребовала очень больших капиталовложений.
Использование СУБД произвело настоящую революцию в индустрии обработки данных. Многие заказные кустарные программы, осуществляющие стандартные операции над данными, оказались ненужными, они были вытеснены надежными промышленными продуктами. Это-- характерный пример того, как специальное ПО становится общим.
Прикладные программы и CASE - технологии
В конце 70-х наступил золотой век софтверного бизнеса, возникли тысячи фирм, выбросивших на рынок необъятное море пакетов прикладных программ для деловых применений и развлечений. Они в корне отличались от "тяжелого" софта 70-х годов -- были простыми, дешевыми, играли на экранах всеми цветами радуги, упаковывались в яркие коробки и продавались в магазинах как книги или грампластинки. На невероятно расширившемся рынке программного обеспечения возникла ожесточенная конкуренция. Как это бывает с товарами ширпотреба, коммерческий успех того или иного продукта часто обуславливается не техническими параметрами, а широкой рекламой, продуманной маркетинговой политикой. Показательна в этом отношении судьба фирмы Microsoft ее активная, даже агрессивная маркетинговая стратегия привела к тому, что продукция Microsoft стала фактическим стандартом на рынке офисного ПО, а операционная система Windows сумела победить более прогрессивную по своим идеям систему OS/2 фирмы IBM.
Повальное увлечение домашними компьютерами и потребительским софтом как-то отодвинуло в тень работы по совершенствованию серьезного общего программного обеспечения. По-видимому, самым большим успехом в этом направлении в 80-е годы можно считать разработу CASE-технологий, то есть технологий автоматизированного проектирования программного обеспечения (CASE -- Computer Aided Software Design). Их необходимость возникла при создании информационных систем для крупных организаций, объединяющих сотни пользователей и оперирующих с тысячами объектов и экранных форм. Даже применение языков высокого уровня таких как Cobol, Pascal или C и средств СУБД не избавляет программиста от рутинной работы по проектированию связанных информационных таблиц и организации диалога. Автоматизированные технологии позволяют отказаться от большинства механической работы. На специальных языках сверхвысокого уровня, символьных или графических (они часто называются языками четвертого поколения 4GL -- 4th Genrration Language), описывается содержательная постановка задачи, а система сама, пользуясь встроенными в нее стандартными правилами проектирования, генерирует код на обычном языке программирования. Программисту остается подправить текст, если он его почему-то не устраивает, пропустить через компилятор и получить готовую программу.
Компьютерные сети и мультимедиа
Компьютерные сети начали развиваться исподволь с начала 70-х годов, но именно в 90-е годы скорость их распространения превысила некоторый критический порог. Произошло то, что специалисты предсказывали давно: вычислительная техника и техника связи, слившись воедино как две половинки атомного заряда, привели к подлинному информационнму взрыву. Миллионы компьютеров, разбросанных по всему свету, оказались связанными всемирной паутиной Интернета. Гигантские объемы научной, культурной и всякой другой информации сделались доступными любому рядовому пользователю, оказались, по меткому выражению Билла Гейтса "на кончиках пальцев".
Появление "сети сетей" -- Интернета -- вызвало рождение целой отрасли нематериального производства -- сетевого бизнеса. Тысячи фирм делают деньги "из воздуха", занимаясь предоставлением доступа в Интернет (Internet providing) и предоставляя различные услуги по организации электронной почты, публикации и поиску информации в сети, размещению рекламы, электронной торговле и т. д. Годовой оборот таких гигантов сетевой индустрии как America On Line (AOL), Yahoo, Amazon измеряется миллиардами долларов, и это только начало.
Развитие сетевых технологий потребовало разработки соответствующего слоя общего программного обеспечения. Историю и современное состояние компьютерных сетей, а также их программного обеспечения мы будем рассматривать в главе 4, а сейчас несколько слов скажем еще об одном важном достижении, которое в 90-х годах перешло из разряда экспериментальных в общедоступные. Речь идет о мультимедиа-технологиях. Буквальный перевод слова multimedia -- "многие среды". Имеются в виду типы объектов, с которыми имеет дело компьютер. В прежние времена вариантов было немного: стандартный компьютер вводил, обрабатывал и выводил только строки символов или неподвижные картинки, на большее не хватало ни мощности процессора, ни объема памяти, ни возможностей устройств вввода-вывода. Однако в последние годы эти характеристики достигли такого состояния, что появилась возможность существенно расширить класс обрабатываемых объектов.
Операционные системы
История операционных систем начинается в 60-е годы, когда для облегчения труда операторов и экономии машинного времени были созданы первые программы-автооператоры и мониторные системы. Впоследствии они развились в операционные системы следующих основных типов:
- * пакетные (однозадачные и с мультипрограммированием); * диалоговые (с разделением времени -- ОС РВ); * системы реального времени.
Пакетные операционные системы, поддерживающие режим мультипрограммирования, были разработаны в начале 60-х годов. Наиболее совершенной системой такого типа было OS/360 MVT для IBM S/360. Следующий этап в развитии ОС для больших ЭВМ -- диалоговые операционные системы с разделением времени (ОС РВ). Экспериментальные ОС такого типа, сформировавшие идеологию систем, были созданы в Массачусетском технологическом институте. Сама идея была высказана Джоном Маккарти в 1961 году, проект Multics под руководством Фернандо Корбато реализовывался во второй половине 60-х годов. Промышленные ОС РВ появилсь в 70-х годах, их разработка и доводка выполнялась как правило фирмами-производителями соответствующих ЭВМ, например, OS/VM для IBM S/360 или RSX-11 для PDP-11. Для отечественной ЭВМ БЭСМ-6 также было разработаны ОС "Диспак" и "Дубна". Среди ОС РВ особое место занимает система Unix, первый вариант которой был разработан Кеннетом Томпсоном и Деннисом Ричи в Bell Laboratories в 1969 году. Написанная на машинно-независимом языке Си, она является портируемой, то есть допускает перенос на различные аппаратные платформы. Это свойство, а также доступность и бесплатность исходного кода, сделали Unix чрезвычайно популярной в 80-х и 90-х годах. Однако доступность исходного кода привела к тому, что единая система перестала существовать, образовалось множество хоть и близких по существу, но различающихся в деталях Unix-подобных систем, как бесплатных, так и коммерческих, например, Solaris от Sun, AIX от IBM, Xenix от Microsoft.
Появление персональных ЭВМ в 80-х годах породило новый класс настольных операционных систем, которые на первыхпорах относились к классу простейших пакетных однозадачных ОС. Для первого поколения 8-битовых ПК характерной была ОС CP/M, разработанная в 1976 году Гэри Килдолом. Второе поколение, ознаменовавшиеся выпуском 16-битовой IBM PC, оснащалось в основном операционной системой MS-DOS, выпущенной фирмой Microsoft в 1981 году. Эта система стала классической ОС для 80-х годов, однако ей присущи принципиальные недостатки, вытекающие из ограниченности аппаратных ресурсов:
- * однозадачный режим работы, * отсутствие встроенных средств управления расширенной памятью и внешними устройствами, прикладная программа должна решать эти задачи сама; * отсутствие унифицированного графического интерфейса, каждое приложение имеет свою логику взаимодействия с пользователем.
Третье поколение 32-битовых персональных компьютеров, появившееся к концу 80-х годов, обладало достаточными аппаратными возможностями для организации графического человеко-машинного интерфейса. Идеи этого интерфейса, разработанные еще в 70-х годах в Xerox PARC, были впервые широко использованы фирмой Apple в операционной системе Mac OS для ЭВМ Macintosh, выпущенной в 1984 году. Фирма Microsoft, отставшая в этом отношении от Apple, выпустила в 1985 году графическую надстройку над DOS под названием Windows. Первые две версии коммерческого успеха не имели, и только Windows 3.0, появившаяся в 1990 году, стала завоевывать рынок. К концу века Microsoft с настольными ОС Windows-95/98/Me, поддерживающими многозадачный режим работы, стала фактическим монополистом на рынке ОС для платформы Intel, победив в конкурентной войне фирму IBM с ее OS/2.
Кроме настольных ОС, в 90-е годы разрабатывались серверные операционные системы, являющиеся прямыми потомками ОС с разделением времени 70-х и 80-х годов. На рынке доминировали NetWare фирмы Novell, Windows NT фирмы Microsoft и различные версии Unix, среди которых наиболее активно развивалась бесплатная система Linux, первая версия которой была создана в 1991 году финским студентом Линусом Торвальдсом.
Особый класс операционных систем -- системы реального времени. Они применяются в системах управления технологическими процессами, в которых критическим является время реакции системы на запросы внешних устройств.
Системы управления базами данных (СУБД), появившиеся в середине 60-х годов, имеют ряд преимуществ по сравнению с прежней схемой независимой работы программ с данными:
- * однократный ввод данных, * независимость программ от данных, * сокращение затрат на программирование.
Основные функции СУБД:
- * описание логической структуры данных, * манипулирование данными, * обеспечение целостности данных, * обеспечение многопользовательского доступа, * защита данных.
Существуют три основных типа СУБД, различаюшиеся логической организацией данных: иерархические, сетевые и реляционные. Первыми были иерархические СУБД (первая промышленная СУБД IMS была разработана фирмой IBM в 1968 году), затем в результате теоретических исследований, предпринятых рабочей группой КОДАСИЛ, появилась сетевая модель данных. Наиболее совершенными и распространенными в настоящее время являются реляционные СУБД, основанные на табличной (реляционной) модели данных, предложенной в 1970 году сотрудником IBM Эдгаром Коддом. Стандартным языком запросов в такой СУБД является язык SQL, разработанный в 1974 году Чемберленом и Бойсом.
Современные промышленные СУБД являются очень дорогими и долгоживущими программными продуктами, соизмеримыми по сложности с операционными системами. К концу века на рынке лидирует "большая шестерка": Oracle, DB2, Informix, Sybase, Ingres, MS SQL Server.
Микрокомпьютерная революция и появление персональных ЭВМ в корне изменили ситуацию на рынке программного обеспечения. Из профессионального инструмента оно превратилось в товар массового спроса, доступный миллионам неквалифицированных пользователей. В 80-е годы на рынок было выброшено множество пакетов прикладных программ (ППП) для персональных компьютеров, расцвел софтверный бизнес, авторы удачных разработок в одночасье делали миллионные состояния. К наиболее популярным ППП относятся текстовые редакторы, электронные таблицы и настольные СУБД.
Рынок текстовых редакторов делится на три основных сектора: простейшие текстовые редакторы, текстовые процессоры широкого применения типа MS Word и настольные издательские системы, берущие начало от пакета Page Maker, разработанного в 1985 году для Apple Macintosh. Особое место среди издательских пакетов занимает система TeX, созданная классиком информатики Дональдом Кнутом и принятая в качестве стандарта многими научными журналами Электронные таблицы были изобретены сотрудником Digital Equipment Corp. Дэниэлом Бриклином и впервые реализованы им совместно с Робертом Фрэнкстоном в 1979 году для персонального компьютера Apple-II. Лидером рынка электронных таблиц в среде MS DOS был пакет Lotus 1-2-3, разработанный основателем фирмы Lotus Development Митчелом Кэпором в 1982 году. После появления Windows наиболее распространенной стала система Excel фирмы Microsoft.
Лекция 5. Вычислительные системы - общие сведения
Один из основателей и глава компании Intel Гордон Мур в 1965 году сформулировал статистическую закономерность, названную позднее - законом Мура:
"Число транзисторов на чипе и производительность компьютеров возрастает вдвое каждые 18 месяцев".
Закон Мура связан с тем, что некоторые экономисты называют эффективным циклом. Действительно, увеличение производительности машин приводит к падению цен, это вызывает появление новых прикладных программ (никому не приходило в голову разрабатывать компьютерные игры для машин стоимостью 10 млн. долларов). Новые прикладные программы - новые рынки - появление новых компаний - повышение конкуренции - понижение цены - новое качество. И над всем этим его величество - потребитель, который предъявляет свои требования к продукту, которые постоянно растут.
Общие требования
К современным компьютерам и вычислительным системам предъявляются следующие требования:
Отношение стоимость/производительность
Надежность и отказоустойчивость
Масштабируемость
Совместимость и мобильность программного обеспечения
Отношение стоимость/производительность
Начнем с очевидного. Суперкомпьютеры - приоритет производительность, стоимостные характеристики на втором плане. Персональные компьютеры - на первом месте стоимостные характеристики, производительность на втором плане.
Между этими двумя крайними направлениями находятся конструкции, основанные на отношении стоимость/ производительность, в которых разработчики находят баланс между стоимостными параметрами и производительностью. Типичными примерами такого рода компьютеров являются миникомпьютеры и рабочие станции.
Производительность
Зачастую производительность вычислительной машины подменяют термином быстродействие и при этом считают, что производительность это - среднестатистическое число операций (кроме операций ввода/вывода), выполняемых машиной в единицу времени. Не вдаваясь в тонкости классификации примем этот подход. Различают пиковую производительность - производительность процессора без учета времени обращения к оперативной памяти; номинальную - производительность процессора с учетом обращений к ОП; системную - общее время выполнения задания с учетом базовых технических и программных средств.
Пиковая производительность компьютера вычисляется однозначно, и эта характеристика является базовой, по которой производят сравнение высокопроизводительных вычислительных систем. Чем больше пиковая производительность, тем теоретически быстрее пользователь сможет решить свою задачу. Пиковая производительность есть величина теоретическая и, вообще говоря, не достижимая при запуске конкретного приложения. Реальная же производительность, достигаемая на данном приложении, зависит от взаимодействия программной модели, в которой реализовано приложение, с архитектурными особенностями машины, на которой приложение запускается.
В качестве единиц измерения используются:
MIPS (Million Instruction Per Second) - миллион целочисленных операций в секунду;
MFLOPS (Million Floating Operations Per Second) - миллион операций над числами с плавающей запятой в секунду, ну и конечно их производные T, G,...
Системная производительность измеряется с помощью синтезированных тестовых
Программ. Результаты оценки ЭВМ конкретной архитектуры приводятся относительно базового образца.
Надежность
Важнейшей характеристикой вычислительных систем является надежность. Повышение надежности основано на принципе предотвращения неисправностей путем снижения интенсивности отказов и сбоев за счет применения электронных схем и компонентов с высокой и сверхвысокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечение тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры.
Отказоустойчивость - это такое свойство вычислительной системы, которое обеспечивает ей, как логической машине, возможность продолжения действий, заданных программой, после возникновения неисправностей. Введение отказоустойчивости требует избыточного аппаратного и программного обеспечения.
Масштабируемость
Масштабируемость представляет собой принципиальную возможность бесконфликтного изменения конфигурации компьютера в процессе эксплуатации, адаптируя его к конкретным условиям эксплуатации. Масштабируемость должна обеспечиваться архитектурой и конструкцией компьютера, а также соответствующими средствами программного обеспечения.
Добавление каждого нового процессора в действительно масштабируемой системе должно давать прогнозируемое увеличение производительности и пропускной способности при приемлемых затратах. Одной из основных задач при построении масштабируемых систем является минимизация стоимости расширения компьютера и упрощение планирования. В идеале добавление процессоров к системе должно приводить к линейному росту ее производительности. Однако это не всегда так. Потери производительности могут возникать, например, при недостаточной пропускной способности шин из-за возрастания трафика между процессорами и основной памятью, а также между памятью и устройствами ввода/вывода. В действительности реальное увеличение производительности трудно оценить заранее, поскольку оно в значительной степени зависит от динамики поведения прикладных задач.
Совместимость
Совместимость проявляется на аппаратном и программном уровнях. Аппаратная совместимость дает возможность комплексировать аппаратуру разных производителей, что предполагает унификацию разъемов, электрических параметров и логики сигналов различных устройств. Программная совместимость обеспечивает работоспособность программы, написанной для одного компьютера, на другом без какой либо перекомпиляции и редактирования.
Концепция программной совместимости впервые в широких масштабах была применена разработчиками системы IBM/360. Основная задача при проектировании всего ряда моделей этой системы заключалась в создании такой архитектуры, которая была бы одинаковой с точки зрения пользователя для всех моделей системы независимо от цены и производительности каждой из них. Огромные преимущества такого подхода, позволяющего сохранять существующий задел программного обеспечения при переходе на новые (как правило, более производительные) модели были быстро оценены как производителями компьютеров, так и пользователями и начиная с этого времени практически все фирмы-поставщики компьютерного оборудования взяли на вооружение эти принципы, поставляя серии совместимых компьютеров. Следует заметить однако, что со временем даже самая передовая архитектура неизбежно устаревает и возникает потребность внесения радикальных изменений в архитектуру и способы организации вычислительных систем.
Классификация компьютеров по областям применения
Задача классификации чрезвычайно затруднительна хотя бы в силу своей многовариантности, тем не менее попробуем это сделать выбрав в качестве критерия сферу применения компьютеров и стоимость.
Теперь мы можем более подробно остановится на наиболее распространенных типах компьютеров.
Персональные компьютеры и рабочие станции
Персональные компьютеры (ПК) появились в результате эволюции миникомпьютеров при переходе элементной базы машин с малой и средней степенью интеграции на большие и сверхбольшие интегральные схемы. ПК, благодаря своей низкой стоимости, очень быстро завоевали хорошие позиции на компьютерном рынке и создали предпосылки для разработки новых программных средств, ориентированных на конечного пользователя. Это прежде всего - "дружественные пользовательские интерфейсы", а также проблемно-ориентированные среды и инструментальные средства для автоматизации разработки прикладных программ. Различают две большие группы ПК: IBM совместимые и Apple Macintosh. Сюда же могут быть отнесены и портативные ПК - portable, laptop, noutbook, palmtop ...
Сетевой компьютер (Net Computer) появился как компонент приложения клиент-сервер, имеющий минимальную конфигурацию ПО и предназначенный для работы в сети. Впервые об этом заявили в 1996 году Oracle, Sun Microsystems, IBM в совместном документе "Network Computer Reference Profile", в котором сформулировали основные черты NC - обработка информации, хранящейся на сервере; принцип бездисковых рабочих станций; должны поддерживать все сетевые протоколы IP, TCP, UDP .... В свою очередь Microsoft и Intel провозгласили свою концепцию Net PC, самое основное - как можно дешевле и вообще не надо памяти.
Рабочая станция. Миникомпьютеры стали прародителями и другого направления развития современных систем - 64 - разрядных машин. Создание RISC-процессоров и микросхем памяти емкостью более 1 Мбайт привело к окончательному оформлению настольных систем высокой производительности, которые сегодня известны как рабочие станции. Первоначальная ориентация рабочих станций на профессиональных пользователей (в отличие от ПК, которые в начале ориентировались на самого широкого потребителя непрофессионала) привела к тому, что рабочие станции - это хорошо сбалансированные системы, в которых высокое быстродействие сочетается с большим объемом оперативной и внешней памяти, высокопроизводительными внутренними магистралями, высококачественной и быстродействующей графической подсистемой и разнообразными устройствами ввода/вывода. Это свойство выгодно отличает рабочие станции среднего и высокого класса от ПК и сегодня. Даже наиболее мощные IBM PC совместимые ПК не в состоянии удовлетворить возрастающие потребности систем обработки из-за наличия в их архитектуре ряда "узких мест".
X-терминалы
X-терминалы представляют собой комбинацию бездисковых рабочих станций и стандартных ASCII-терминалов. Бездисковые рабочие станции часто применялись в качестве дорогих дисплеев и в этом случае не полностью использовали локальную вычислительную мощь. Одновременно многие пользователи ASCII-терминалов хотели улучшить их характеристики, чтобы получить возможность работы в многооконной системе и графические возможности. Совсем недавно, как только стали доступными очень мощные графические рабочие станции, появилась тенденция применения "подчиненных" X-терминалов, которые используют рабочую станцию в качестве локального сервера.
На компьютерном рынке X-терминалы занимают промежуточное положение между персональными компьютерами и рабочими станциями. Поставщики X-терминалов заявляют, что их изделия более эффективны в стоимостном выражении, чем рабочие станции высокого ценового класса, и предлагают увеличенный уровень производительности по сравнению с персональными компьютерами. Быстрое снижение цен, прогнозируемое иногда в секторе X-терминалов, в настоящее время идет очевидно благодаря обострившейся конкуренции в этом секторе рынка. Многие компании начали активно конкурировать за распределение рынка, а быстрый рост объемных поставок создал предпосылки для создания такого рынка. В настоящее время уже достигнута цена в $1000 для Х-терминалов начального уровня, что делает эту технологию доступной для широкой пользовательской базы.
Как правило, стоимость X-терминалов составляет около половины стоимости сравнимой по конфигурации бездисковой машины и примерно четверть стоимости полностью оснащенной рабочей станции.
Серверы
Прикладные многопользовательские коммерческие и бизнес-системы, включающие системы управления базами данных и обработки транзакций, крупные издательские системы, сетевые приложения и системы обслуживания коммуникаций, разработку программного обеспечения и обработку изображений все более настойчиво требуют перехода к модели вычислений "клиент-сервер" и распределенной обработке. В распределенной модели "клиент-сервер" часть работы выполняет сервер, а часть пользовательский компьютер (в общем случае клиентская и пользовательская части могут работать и на одном компьютере). Существует несколько типов серверов, ориентированных на разные применения: файл-сервер, сервер базы данных, принт-сервер, вычислительный сервер, сервер приложений. Таким образом, тип сервера определяется видом ресурса, которым он владеет (файловая система, база данных, принтеры, процессоры или прикладные пакеты программ).
С другой стороны существует классификация серверов, определяющаяся масштабом сети, в которой они используются: сервер рабочей группы, сервер отдела или сервер масштаба предприятия (корпоративный сервер). Эта классификация весьма условна. Например, размер группы может меняться в диапазоне от нескольких человек до нескольких сотен человек, а сервер отдела обслуживать от 20 до 150 пользователей. Очевидно в зависимости от числа пользователей и характера решаемых ими задач требования к составу оборудования и программного обеспечения сервера, к его надежности и производительности сильно варьируются.
Файловые серверы небольших рабочих групп (не более 20-30 человек) проще всего реализуются на платформе персональных компьютеров и программном обеспечении Novell NetWare. Файл-сервер, в данном случае, выполняет роль центрального хранилища данных. Серверы прикладных систем и высокопроизводительные машины для среды "клиент-сервер" значительно отличаются требованиями к аппаратным и программным средствам.
Однако для файл-серверов общего доступа, с которыми одновременно могут работать несколько десятков, а то и сотен человек, простой однопроцессорной платформы и программного обеспечения Novell может оказаться недостаточно. В этом случае используются мощные многопроцессорные серверы с возможностями наращивания оперативной памяти до нескольких гигабайт, дискового пространства до сотен гигабайт, быстрыми интерфейсами дискового обмена (типа Fast SCSI-2, Fast&;Wide SCSI-2 и Fiber Channel) и несколькими сетевыми интерфейсами. Эти серверы используют операционную систему UNIX, сетевые протоколы TCP/IP и NFS. На базе многопроцессорных UNIX-серверов обычно строятся также серверы баз данных крупных информационных систем, так как на них ложится основная нагрузка по обработке информационных запросов. Подобного рода серверы получили название суперсерверов.
По уровню общесистемной производительности, функциональным возможностям отдельных компонентов, отказоустойчивости, а также в поддержке многопроцессорной обработки, системного администрирования и дисковых массивов большой емкости суперсерверы вышли в настоящее время на один уровень с мейнфреймами и мощными миникомпьютерами. Современные суперсерверы характеризуются:
Наличием двух или более центральных процессоров RISC, либо CISC;
Многоуровневой шинной архитектурой, в которой запатентованная высокоскоростная системная шина связывает между собой несколько процессоров и оперативную память, а также множество стандартных шин ввода/вывода, размещенных в том же корпусе;
Поддержкой технологии дисковых массивов RAID;
Поддержкой режима симметричной многопроцессорной обработки, которая позволяет распределять задания по нескольким центральным процессорам или режима асимметричной многопроцессорной обработки, которая допускает выделение процессоров для выполнения конкретных задач.
Как правило, суперсерверы работают под управлением операционных систем UNIX, а в последнее время и Windows NT, 2000, XP, которые обеспечивают многопотоковую многопроцессорную и многозадачную обработку.
Мейнфреймы
Мейнфрейм - это синоним понятия "большая универсальная ЭВМ". Мейнфреймы и до сегодняшнего дня остаются наиболее мощными (не считая суперкомпьютеров) вычислительными системами общего назначения, обеспечивающими непрерывный круглосуточный режим эксплуатации. Они могут включать один или несколько процессоров, каждый из которых, в свою очередь, может оснащаться векторными сопроцессорами (ускорителями операций с суперкомпьютерной производительностью). В нашем сознании мейнфреймы все еще ассоциируются с большими по габаритам машинами, требующими специально оборудованных помещений с системами водяного охлаждения и кондиционирования. Однако это не совсем так. Прогресс в области элементно-конструкторской базы позволил существенно сократить габариты основных устройств. Наряду со сверхмощными мейнфреймами, требующими организации двухконтурной водяной системы охлаждения, имеются менее мощные модели, для охлаждения которых достаточно принудительной воздушной вентиляции, и модели, построенные по блочно-модульному принципу и не требующие специальных помещений и кондиционеров.
Основными поставщиками мейнфреймов являются известные компьютерные компании IBM, Amdahl, ICL, Siemens Nixdorf и некоторые другие, но ведущая роль принадлежит безусловно компании IBM. Именно архитектура системы IBM/360, выпущенной в 1964 году, и ее последующие поколения стали образцом для подражания. В нашей стране в течение многих лет выпускались машины ряда ЕС ЭВМ, являвшиеся отечественным аналогом этой системы.
В архитектурном плане мейнфреймы представляют собой многопроцессорные системы, содержащие один или несколько центральных и периферийных процессоров с общей памятью, связанных между собой высокоскоростными магистралями передачи данных. При этом основная вычислительная нагрузка ложится на центральные процессоры, а периферийные процессоры (в терминологии IBM - селекторные, блок-мультиплексные, мультиплексные каналы и процессоры телеобработки) обеспечивают работу с широкой номенклатурой периферийных устройств.
Суперкомпьютеры
Что такое суперЭВМ? Оксфордский толковый словарь по вычислительной технике, изданный в 1986 году, сообщает, что суперкомпьютер это очень мощная ЭВМ с производительностью свыше 10 MFLOPS (10 миллионов операций с плавающей запятой в секунду). Сегодня это средненький результат даже для ПК. Планки производительности в 10 TFLOPS были успешно перекрыты довольно давно. Суперкомпьютер ASCI WHITE, занимающий первое место в списке пятисот самых мощных компьютеров мира, объединяет 8192 процессора Power 3 с общей оперативной памятью в 4 Терабайта и производительностью более 12 триллионов операций в секунду, а суперкомпьютер IBM Blue Gene/L достиг на тесте Linpack производительности в 153, 3 TFLOPS.
Наиболее значимое отечественное достижение в данном направлении связано с созданием семейства суперкомпьютеров под общим названием "Скиф" в рамках сотрудничества российской и белорусской академий наук. От российской стороны ответственным исполнителем является Институт программных систем в г. Переяславле-Залесском, а от Республики Беларусь - объединение "Кибернетика". Целью работ является создание кластеров с пиковой производительностью в сотни GFLOPS. К практической реализации программы приступили осенью 2000 года, а презентация двух работающих вычислительных систем состоялась уже в мае 2001 года. По основным параметрам "Скиф" не уступает зарубежным аналогам в своем классе компьютеров, а по соотношению цена/производительность намного их превосходит. Осенью 2004 года старшая в ряду "Скифов" система К-1000, включающая 288 двухпроцессорных вычислительных узлов на базе 64-разрядных процессоров AMD Opteron с частотой 2200 МГц, показала производительность 2500 GFLOPS и вошла в рейтинг-лист Top-500, заняв в нем 98-е место.
Второе направление зародилось на базе ИТМ и ВТ - колыбели отечественного компьютеростроения. После того, как резко снизилось государственное финансирование, большая группа разработчиков во главе с Б. А. Бабаяном стала активно искать зарубежных инвесторов с целью реализации передовых отечественных идей на современной западной технологии. В их активе была закончившаяся в 1991 году разработка 16-процессорного "Эльбруса-3", содержащего самые передовые архитектурные решения и по своей производительности (10 GFLOPS) опережавшего современный ему Cray Y-MP. Однако реализованный в стенах ИТМ и ВТ экземпляр был собран на элементах устаревшей 2-микронной технологии. Громоздкий шкаф с 15 млн. транзисторов и около 3 тыс. схем средней и малой интеграции вполне мог быть "упакован" в 2-3 чипа. В 1992 году работами российских ученых заинтересовалась фирма Sun Microsystems. Был создан "Московский центр SPARC-технологий" (МЦСТ), который, объединившись с некоторым другими фирмами в группу компаний "Эльбрус", осуществляет ряд успешных проектов для отечественных и зарубежных заказчиков. Среди них процессор "Эльбрус-2000" (Е2k), в котором в доработанном и усовершенствованном виде воплощены на кристалле основные принципы "Эльбруса-3".
Вот лишь небольшой список областей человеческой деятельности, где использование суперкомпьютеров необходимо:
Автомобилестроение;
Нефте - и газодобыча;
Фармакология;
Прогноз погоды и моделирование изменения климата;
Сейсморазведка;
Проектирование электронных устройств;
Синтез новых материалов;
И многие, многие другие.
В 1995 году корпус автомобиля Nissan Maxima удалось сделать на 10% прочнее благодаря использованию суперкомпьютера фирмы Cray (The Atlanta Journal, 28 мая, 1995г). С помощью него были найдены не только слабые точки кузова, но и наиболее эффективный способ их удаления. По данным Марка Миллера (Mark Miller, Ford Motor Company), для выполнения crash-тестов, при которых реальные автомобили разбиваются о бетонную стену с одновременным замером необходимых параметров, съемкой и последующей обработкой результатов, компании Форд понадобилось бы от 10 до 150 прототипов новых моделей при общих затратах от 4 до 60 миллионов долларов. Использование суперкомпьютеров позволило сократить число прототипов на одну треть. Совсем недавний пример - это развитие одной из крупнейших мировых систем резервирования Amadeus, используемой тысячами агенств со 180000 терминалов в более чем ста странах. Установка двух серверов Hewlett-Packard T600 по 12 процессоров в каждом позволила довести степень оперативной доступности центральной системы до 99.85% при текущей загрузке около 60 миллионов запросов в сутки. И подобные примеры можно найти повсюду. В свое время исследователи фирмы DuPont искали замену хлорофлюорокарбону. Нужно было найти материал, имеющий те же положительные качества: невоспламеняемость, стойкость к коррозии и низкую токсичность, но без вредного воздействия на озоновый слой Земли. За одну неделю были проведены необходимые расчеты на суперкомпьютере с общими затратами около 5 тысяч долларов. По оценкам специалистов DuPont, использование традиционных экспериментальных методов исследований потребовало бы около трех месяцев и 50 тысяч долларов и это без учета времени, необходимого на синтез и очистку необходимого количества вещества.
Увеличение производительности ЭВМ, за счет чего?
А почему суперкомпьютеры считают так быстро? Вариантов ответа может быть несколько, среди которых два имеют явное преимущество: развитие элементной базы и использование новых решений в архитектуре компьютеров. Попробуем разобраться, какой из этих факторов оказывается решающим для достижения рекордной производительности. Обратимся к известным историческим фактам. На одном из первых компьютеров мира - EDSAC, появившемся в 1949 году в Кембридже и имевшем время такта 2 микросекунды (2*10-6 секунды), можно было выполнить 2*n арифметических операций за 18*n миллисекунд, то есть в среднем 100 арифметических операций в секунду. Сравним с одним вычислительным узлом современного суперкомпьютера Hewlett-Packard V2600: время такта приблизительно 1.8 наносекунды (1.8*10-9 секунд), а пиковая производительность около 77 миллиардов арифметических операций в секунду. Что же получается? Более чем за полвека производительность компьютеров выросла почти в 800 миллионов раз. При этом выигрыш в быстродействии, связанный с уменьшением времени такта с 2 микросекунд до 1.8 наносекунд, составляет лишь около 1000 раз. Откуда же взялось остальное? Ответ очевиден - использование новых решений в архитектуре компьютеров. Основное место среди них занимает принцип параллельной обработки команд и данных, воплощающий идею одновременного (параллельного) выполнения нескольких действий.
Параллельные системы
Итак, пути повышения производительности ВС заложены в ее архитектуре. С одной стороны это совокупность процессоров, блоков памяти, устройств ввода/вывода ну и конечно способов их соединения, т. е. коммуникационной среды. С другой стороны, это собственно действия ВС по решению некоторой задачи, а это операции над командами и данными. Вот собственно и вся основная база для проведения параллельной обработки. Параллельная обработка, воплощая идею одновременного выполнения нескольких действий, имеет несколько разновидностей: суперскалярность, конвейеризация, SIMD - расширения, Hyper Threading, многоядерность. В основном эти виды параллельной обработки интуитивно понятны, поэтому сделаем лишь небольшие пояснения. Если некое устройство выполняет одну операцию за единицу времени, то тысячу операций оно выполнит за тысячу единиц. Если предположить, что есть, пять таких же независимых устройств, способных работать одновременно, то ту же тысячу операций система из пяти устройств может выполнить уже не за тысячу, а за двести единиц времени. Аналогично система из N устройств ту же работу выполнит за 1000/N единиц времени. Подобные аналогии можно найти и в жизни: если один солдат вскопает огород за 10 часов, то рота солдат из пятидесяти человек с такими же способностями, работая одновременно, справятся с той же работой за 12 минут (параллельная обработка данных), да еще и с песнями (параллельная обработка команд).
Конвейерная обработка. Что необходимо для сложения двух вещественных чисел, представленных в форме с плавающей запятой? Целое множество мелких операций таких, как сравнение порядков, выравнивание порядков, сложение мантисс, нормализация и т. п. Процессоры первых компьютеров выполняли все эти "микрооперации" для каждой пары аргументов последовательно одна за одной до тех пор, пока не доходили до окончательного результата, и лишь после этого переходили к обработке следующей пары слагаемых. Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Получаем очевидный выигрыш в скорости обработки за счет совмещения прежде разнесенных во времени операций.
Суперскалярность. Как и в предыдущем примере, только при построении конвейера используют несколько программно-аппаратных реализаций функциональных устройств, например два или три АЛУ, три или четыре устройства выборки.
Hyper Threading. Перспективное направление развитие современных микропроцессоров, основанное на многонитевой архитектуре. Основное препятствие на пути повышения производительности за счет увеличения функциональных устройств - это организация эффективной загрузки этих устройств. Если сегодняшние программные коды не в состоянии загрузить работой все функциональные устройства, то можно разрешить процессору выполнять более чем одну задачу (нить), чтобы дополнительные нити загрузили - таки все ФИУ (очень похоже на многозадачность).
Многоядерность. Можно, конечно, реализовать мультипроцессирование на уровне микросхем, т. е. разместить на одном кристалле несколько процессоров (Power 4). Но если взять микропроцессор вместе с памятью как ядра системы, то несколько таких ядер на одном кристалле создадут многоядерную структуру. При этом в кристалле интегрируются функции (например, интерфейсы сетевых и телекоммуникационных систем) для выполнения которых обычно используются наборы микросхем (процессоры Motorola MPC8260, Power 4).
По каким же направлениям идет реализация высокопроизводительной вычислительной техники в настоящее время? Основных направлений четыре.
- 1. Векторно-конвейерные компьютеры. Конвейерные функциональные устройства и набор векторных команд - это две особенности таких машин. В отличие от традиционного подхода, векторные команды оперируют целыми массивами независимых данных, что позволяет эффективно загружать доступные конвейеры, т. е. команда вида A=B+C может означать сложение двух массивов, а не двух чисел. Характерным представителем данного направления является семейство векторно-конвейерных компьютеров CRAY куда входят, например, CRAY EL, CRAY J90, CRAY T90 (в марте 2000 года американская компания TERA перекупила подразделение CRAY у компании Silicon Graphics, Inc.). 2. Массивно-параллельные компьютеры с распределенной памятью. Идея построения компьютеров этого класса тривиальна: возьмем серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим посредством некоторой коммуникационной среды - вот и все. Достоинств у такой архитектуры масса: если нужна высокая производительность, то можно добавить еще процессоров, если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т. п.
Однако есть и решающий "минус", сводящий многие "плюсы" на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов иногда просто невозможно. К данному классу можно отнести компьютеры Intel Paragon, IBM SP1, Parsytec, в какой-то степени IBM SP2 и CRAY T3D/T3E, хотя в этих компьютерах влияние указанного минуса значительно ослаблено. К этому же классу можно отнести и сети компьютеров, которые все чаще рассматривают как дешевую альтернативу крайне дорогим суперкомпьютерам.
- 3. Параллельные компьютеры с общей памятью. Вся оперативная память таких компьютеров разделяется несколькими одинаковыми процессорами. Это снимает проблемы предыдущего класса, но добавляет новые - число процессоров, имеющих доступ к общей памяти, по чисто техническим причинам нельзя сделать большим. В данное направление входят многие современные многопроцессорные SMP-компьютеры или, например, отдельные узлы компьютеров HP Exemplar и Sun StarFire. 4. Кластерные системы. Последнее направление, строго говоря, не является самостоятельным, а скорее представляет собой комбинации предыдущих трех. Из нескольких процессоров (традиционных или векторно-конвейерных) и общей для них памяти сформируем вычислительный узел. Если полученной вычислительной мощности не достаточно, то объединим несколько узлов высокоскоростными каналами. Подобную архитектуру называют кластерной, и по такому принципу построены CRAY SV1, HP Exemplar, Sun StarFire, NEC SX-5, последние модели IBM SP2 и другие. Именно это направление является в настоящее время наиболее перспективным для конструирования компьютеров с рекордными показателями производительности.
Использование параллельных вычислительных систем
К сожалению, чудеса в жизни редко случаются. Гигантская производительность параллельных компьютеров и супер-ЭВМ с лихвой компенсируется сложностями их использования. Начнем с самых простых вещей. У вас есть программа и доступ, скажем, к 256-процессорному компьютеру. Что вы ожидаете? Да ясно что: вы вполне законно ожидаете, что программа будет выполняться в 256 раз быстрее, чем на одном процессоре. А вот как раз этого, скорее всего, и не будет.
Закон Амдала и его следствия
Предположим, что в вашей программе доля операций, которые нужно выполнять последовательно, равна f, где 0<=f<=1 (при этом доля понимается не по статическому числу строк кода, а по числу операций в процессе выполнения). Крайние случаи в значениях f соответствуют полностью параллельным (f=0) и полностью последовательным (f=1) программам. Так вот, для того, чтобы оценить, какое ускорение S может быть получено на компьютере из 'p' процессоров при данном значении f, можно воспользоваться законом Амдала:
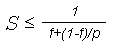
Если 9/10 программы исполняется параллельно, а 1/10 по-прежнему последовательно, то ускорения более, чем в 10 раз получить в принципе невозможно вне зависимости от качества реализации параллельной части кода и числа используемых процессоров.
Отсюда первый вывод - прежде, чем основательно переделывать код для перехода на параллельный компьютер (а любой суперкомпьютер, в частности, является таковым) надо основательно подумать. Если оценив заложенный в программе алгоритм вы поняли, что доля последовательных операций велика, то на значительное ускорение рассчитывать явно не приходится и нужно думать о замене отдельных компонент алгоритма. В ряде случаев последовательный характер алгоритма изменить не так сложно. Допустим, что в программе есть следующий фрагмент для вычисления суммы n чисел:
S = 0
Do i = 1, n
S = s + a(i)
End Do
(можно тоже самое на любом другом языке)
По своей природе он строго последователен, так как на i-й итерации цикла требуется результат с (i-1)-й и все итерации выполняются одна за одной. Имеем 100% последовательных операций, а значит и никакого эффекта от использования параллельных компьютеров. Вместе с тем, выход очевиден. Поскольку в большинстве реальных программ (вопрос: а почему в большинстве, а не во всех?) нет существенной разницы, в каком порядке складывать числа, выберем иную схему сложения. Сначала найдем сумму пар соседних элементов: a(1)+a(2), a(3)+a(4), a(5)+a(6) и т. д. Заметим, что при такой схеме все пары можно складывать одновременно! На следующих шагах будем действовать абсолютно аналогично, получив вариант параллельного алгоритма. Казалось бы в данном случае все проблемы удалось разрешить. Но представьте, что доступные вам процессоры разнородны по своей производительности. Значит будет такой момент, когда кто-то из них еще трудится, а кто-то уже все сделал и бесполезно простаивает в ожидании. Если разброс в производительности компьютеров большой, то и эффективность всей системы при равномерной загрузке процессоров будет крайне низкой. Но пойдем дальше и предположим, что все процессоры одинаковы. Проблемы кончились? Опять нет! Процессоры выполнили свою работу, но результат-то надо передать другому для продолжения процесса суммирования... а на передачу уходит время... и в это время процессоры опять простаивают... Словом, заставить параллельную вычислительную систему или супер-ЭВМ работать с максимальной эффективность на конкретной программе это, прямо скажем, задача не из простых, поскольку необходимо тщательное согласование структуры программ и алгоритмов с особенностями архитектуры параллельных вычислительных систем.
Заключительный вопрос. Как вы думаете, верно ли утверждение: чем мощнее компьютер, тем быстрее на нем можно решить данную задачу? Заключительный ответ. Нет, это не верно. Это можно пояснить простым бытовым примером. Если один землекоп выкопает яму 1м*1м*1м за 1 час, то два таких же землекопа это сделают за 30 мин - в это можно поверить. А за сколько времени эту работу сделают 60 землекопов? За 1 минуту? Конечно же нет! Начиная с некоторого момента они будут просто мешаться друг другу, не ускоряя, а замедляя процесс. Так же и в компьютерах: если задача слишком мала, то мы будем дольше заниматься распределением работы, синхронизацией процессов, сборкой результатов и т. п., чем непосредственно полезной работой.
Выводы
Именно компьютерный рынок определяет баланс в отношении стоимость/производительность.
Важнейшей характеристикой вычислительных систем является надежность.
Повышение отказоустойчивости требует введение избыточности аппаратного и программного обеспечения.
Масштабируемость представляет собой возможность бесконфликтного наращивания числа и мощности процессоров, объемов оперативной и внешней памяти и других ресурсов вычислительной системы.
Совместимость и мобильность ПО должна обеспечивать возможность запуска одних и тех же программных систем на различных аппаратных платформах, т. е. обеспечивать мобильность программного обеспечения.
Вопросы и задания
Какие параметры ВС определяют ее производительность?
Какова производительность современных суперкомпьютеров?
Что такое кластерные системы и системы высокой готовности?
Приведите примеры наиболее распространенных серверов.
Лекция 6. Структурная организация ЭВМ - процессор
Введение
В предыдущих лекциях мы познакомились с функциональными блоками ЭВМ, вычислительных систем и основными принципами их взаимодействия. Теперь мы можем приступить к более детальному анализу каждого из блоков и узлов в отдельности. Начнем, естественно, с процессора и истории его появления.
Что известно всем
В 1968 году Роберт Нойс, изобретатель кремниевой интегральной схемы (1958), Гордон Мур, автор известного закона Мура, и Артур Рок, капиталист из Сан-Франциско, основали корпорацию Intel для производства компьютерных микросхем.
Первоначальное название "NM Electronicx" звучало не очень привлекательно, после ряда проб остановились на "Integrated Electronics", утвердить не удалось, зато абривиатуру Intel теперь знают все и стоит она $31 млрд. !!!
За первый год своего существования корпорация продала микросхем (аж!) на $3000. Но вот улыбка судьбы! В августе 1969 года крохотная фирма Intel Corporation, которая была совсем недавно зарегистрирована, получила заказ от небольшой японской фирмы Nippon Calculating Machines, на проектирование микросхем для семейства калькуляторов (10-12 различных несерийных микросхем-калькуляторов). Вместо того, чтобы делать 10-12 различных микросхем на "жесткой логике", т. е. специализированной системе, настроенной на одну, или несколько близких задач. Другими словами, микросхем в которых алгоритмы обработки и хранения данных жестко связаны со схемотехникой и изменения алгоритмов возможны только путем изменения схемотехники системы. Тед Хофман и его сотрудник Стен Мейзор решили разработать одну твердотельную 4-битную микросхему-процессор, представляющую из себя универсальный компьютер с программируемыми функциями, который мог работать в любом из заказанных калькуляторов. Далее грандиозный успех: ноябрь 1970 чип 4001 ----- декабрь 1970 чип 4004. В июне 1971 года Intel анонсировала микропроцессорное семейство 4004 и выкупила все права на микросхему у японской компании за те-же $60000, которые она заплатила, решив расходы на 4004 чрезмерными. Она отказалась от исключительных (!) прав на продукты Intel. Последняя в 1974 г. своими усилиями выпустила 8-разрядный процессор 8080, и наконец покупатели стали проявлять к решениям микроэлектроники реальный интерес. Авторы разработки навечно были внесены в список лауреатов Национального зала Славы США, а само изобретение признано одним из величайших достижений XX века.
Процессор 4004 - 4-х разрядный, 2250 транзисторов, частота - 108 кГц, производительность - 60 000 операций в сек, чип размером со шляпку гвоздя.
Что известно немногим.
В 1968 году (!) два американских инженера Рэй Холт и Стив Геллер создали 20 - разрядный микропроцессор SLF (Special Logic Function).
Чип SLF служил основой бортового компьютера CADC для новейшего истребителя с изменяемой стреловидностью крыла F14. SLF - 20 разрядный процессор с элементами параллельной логики и возможностью расширения (3 синхронно работающих SLF на бортовом компьютере, плюс элементы DSP процессора (!). Можно сказать, что CADC - гениальное для своего времени решение и заложенные в него принципы не устарели и по сей день. Так, в F-14 из-за больших объемов вычислений использовалось одновременно три (!) синхронно работающих микропроцессора SLF. Сравнительно недавно на мировом рынке появились первые общедоступные версии четырехпроцессорных ПК. Строжайшая секретность этой работы не позволила опубликовать результаты исследований, а широкий рынок микропроцессорной техники все больше становился вотчиной Intel.
Первый 16 разрядный Intel 8086 вышел в свет только в 1978 году. Далее история развития микропроцессорной техники это в подавляющем числе случаев - история Intel. Одна самая характерная черта, на мой взгляд, маркетинговой политики этой компании это то, что все процессоры Intel совместимы со своими предшественниками вплоть до процессора 8086. Другими словами, Pentium II, III, IV могут выполнять программы, написанные для процессоров 8086, не думаю, что это есть хорошо, по крайней мере, могу представить возмущение сегодняшних программистов.
Микропроцессорная система
Микропроцессорная система может рассматриваться как частный случай электронной системы, предназначенной для обработки входных сигналов и выдачи выходных сигналов (рис. 6.1). В качестве входных и выходных сигналов при этом могут использоваться аналоговые сигналы, одиночные цифровые сигналы, цифровые коды, последовательности цифровых кодов. Характерная особенность традиционной цифровой системы состоит в том, что алгоритмы обработки и хранения информации в ней жестко связаны со схемотехникой системы. То есть изменение этих алгоритмов возможно только путем изменения структуры системы, замены электронных узлов, входящих в систему, и/или связей между ними. Например, если нам нужна дополнительная операция суммирования, то необходимо добавить в структуру системы лишний сумматор. Или если нужна дополнительная функция хранения кода в течение одного такта, то мы должны добавить в структуру еще один регистр. Естественно, это практически невозможно сделать в процессе эксплуатации, обязательно нужен новый производственный цикл проектирования, изготовления, отладки всей системы. Именно поэтому традиционная цифровая система часто называется системой на "жесткой логике".
Рис. 6.1. Электронная система.
Любая система на "жесткой логике" обязательно представляет собой специализированную систему, настроенную исключительно на одну задачу или (реже) на несколько близких, заранее известных задач. Это имеет свои бесспорные преимущества. Во-первых, специализированная система (в отличие от универсальной) никогда не имеет аппаратурной избыточности, то есть каждый ее элемент обязательно работает в полную силу (конечно, если эта система грамотно спроектирована). Во-вторых, именно специализированная система может обеспечить максимально высокое быстродействие, так как скорость выполнения алгоритмов обработки информации определяется в ней только быстродействием отдельных логических элементов и выбранной схемой путей прохождения информации. А именно логические элементы всегда обладают максимальным на данный момент быстродействием. Но в то же время большим недостатком цифровой системы на "жесткой логике" является то, что для каждой новой задачи ее надо проектировать и изготавливать заново.
Путь преодоления этого недостатка довольно очевиден: надо построить такую систему, которая могла бы легко адаптироваться под любую задачу, перестраиваться с одного алгоритма работы на другой без изменения аппаратуры. И задавать тот или иной алгоритм мы тогда могли бы путем ввода в систему некой дополнительной управляющей информации, программы работы системы (рис. 6.2). Тогда система станет универсальной, или программируемой, не жесткой, а гибкой. Именно это и обеспечивает микропроцессорная система.
Рис. 6.2. Программируемая (она же универсальная) электронная система.
Но любая универсальность обязательно приводит к избыточности. Ведь решение максимально трудной задачи требует гораздо больше средств, чем решение максимально простой задачи. Поэтому сложность универсальной системы должна быть такой, чтобы обеспечивать решение самой трудной задачи, а при решении простой задачи система будет работать далеко не в полную силу, будет использовать не все свои ресурсы. И чем проще решаемая задача, тем больше избыточность, и тем менее оправданной становится универсальность. Избыточность ведет к увеличению стоимости системы, снижению ее надежности, увеличению потребляемой мощности и т. д. Кроме того, универсальность, как правило, приводит к существенному снижению быстродействия. Оптимизировать универсальную систему так, чтобы каждая новая задача решалась максимально быстро, попросту невозможно. Общее правило таково: чем больше универсальность, гибкость, тем меньше быстродействие. Более того, для универсальных систем не существует таких задач (пусть даже и самых простых), которые бы они решали с максимально возможным быстродействием. За все приходится платить.
Таким образом, можно сделать следующий вывод. Системы на "жесткой логике" хороши там, где решаемая задача не меняется длительное время, где требуется самое высокое быстродействие, где алгоритмы обработки информации предельно просты. А универсальные, программируемые системы хороши там, где часто меняются решаемые задачи, где высокое быстродействие не слишком важно, где алгоритмы обработки информации сложные. То есть любая система хороша на своем месте. Однако за последние десятилетия быстродействие универсальных (микропроцессорных) систем сильно выросло (на несколько порядков). К тому же большой объем выпуска микросхем для этих систем привел к резкому снижению их стоимости. В результате область применения систем на "жесткой логике" резко сузилась. Более того, высокими темпами развиваются сейчас программируемые системы, предназначенные для решения одной задачи или нескольких близких задач. Они удачно совмещают в себе как достоинства систем на "жесткой логике", так и программируемых систем, обеспечивая сочетание достаточно высокого быстродействия и необходимой гибкости. Так что вытеснение "жесткой логики" продолжается.
Что такое микропроцессор?
Ядром любой микропроцессорной системы является микропроцессор или просто процессор (от английского processor). Перевести на русский язык это слово правильнее всего как "обработчик", так как именно микропроцессор -- это тот узел, блок, который производит всю обработку информации внутри микропроцессорной системы. Остальные узлы выполняют всего лишь вспомогательные функции: хранение информации (в том числе и управляющей информации, то есть программы), связи с внешними устройствами, связи с пользователем и т. д. Процессор заменяет практически всю "жесткую логику", которая понадобилась бы в случае традиционной цифровой системы. Он выполняет арифметические функции (сложение, умножение и т. д.), логические функции (сдвиг, сравнение, маскирование кодов и т. д.), временное хранение кодов (во внутренних регистрах), пересылку кодов между узлами микропроцессорной системы и многое другое. Количество таких элементарных операций, выполняемых процессором, может достигать нескольких сотен. Процессор можно сравнить с мозгом системы.
Но при этом надо учитывать, что все свои операции процессор выполняет последовательно, то есть одну за другой, по очереди. Конечно, существуют процессоры с параллельным выполнением некоторых операций, встречаются также микропроцессорные системы, в которых несколько процессоров работают над одной задачей параллельно, но это редкие исключения. С одной стороны, последовательное выполнение операций -- несомненное достоинство, так как позволяет с помощью всего одного процессора выполнять любые, самые сложные алгоритмы обработки информации. Но, с другой стороны, последовательное выполнение операций приводит к тому, что время выполнения алгоритма зависит от его сложности. Простые алгоритмы выполняются быстрее сложных.
Итак, микропроцессор способен выполнять множество операций. Но откуда он узнает, какую операцию ему надо выполнять в данный момент? Именно это определяется управляющей информацией, программой. Программа представляет собой набор команд (инструкций), то есть цифровых кодов, расшифровав которые, процессор узнает, что ему надо делать. Программа от начала и до конца составляется человеком, программистом, а процессор выступает в роли послушного исполнителя этой программы, никакой инициативы он не проявляет (если, конечно, исправен). Поэтому сравнение процессора с мозгом не слишком корректно. Он всего лишь исполнитель того алгоритма, который заранее составил для него человек. Любое отклонение от этого алгоритма может быть вызвано только неисправностью процессора или каких-нибудь других узлов микропроцессорной системы. Все команды, выполняемые процессором, образуют систему команд процессора. Структура и объем системы команд процессора определяют его быстродействие, гибкость, удобство использования. Всего команд у процессора может быть от нескольких десятков до нескольких сотен. Система команд может быть рассчитана на узкий круг решаемых задач (у специализированных процессоров) или на максимально широкий круг задач (у универсальных процессоров). Коды команд могут иметь различное количество разрядов (занимать от одного до нескольких байт). Каждая команда имеет свое время выполнения, поэтому время выполнения всей программы зависит не только от количества команд в программе, но и от того, какие именно команды используются. Для выполнения команд в структуру процессора входят внутренние регистры, арифметико-логическое устройство (АЛУ, ALU -- Arithmetic Logic Unit) , мультиплексоры, буферы, регистры и другие узлы. Работа всех узлов синхронизируется общим внешним тактовым сигналом процессора. То есть процессор представляет собой довольно сложное цифровое устройство (рис. 6.3).
Назначение элементов процессора
Процессор - ЦПУ или CPU, его задача не только обрабатывать большую часть информации (выполнять программу, находящуюся в памяти компьютера), но и управлять работой всех частей (аппаратных и программных) компьютера. Процессор состоит из:
АЛУ, которое выполняет арифметические и логические операции;
УУ или блок управления, вызывает команды из памяти, определяет их тип (декодирует), интерпретирует эти команды (ПЗУ - интерпретатор) и организует обращение к памяти (поиск операндов, запись результатов и т. д.), обрабатывает поступающие на процессор запросы на прерывание, блок управления прямым доступом к памяти (ПДП) служит для временного отключения процессора от внешних шин и организации прямого доступа к памяти различным устройствам ввода/вывода;
Кэш-память - внутренняя память 1-го уровня, хранение исполняемой команды и данных;
Микропроцессорная, сверхбыстродействующая память - регистровый файл, регистровая память, содержащая: специальные регистры (счетчик команд, регистр команд, регистр данных и т. д.), регистры общего назначения (РОН)- память для временного хранения операндов, сегментные регистры для организации логической памяти;
Внутрисистемный интерфейс или интерфейс магистрали - реализует протоколы обмена ЦПУ с памятью компьютера, контроллерами устройств ввода/вывода, и т. д., по определенным правилам и каналам связи.
АЛУ
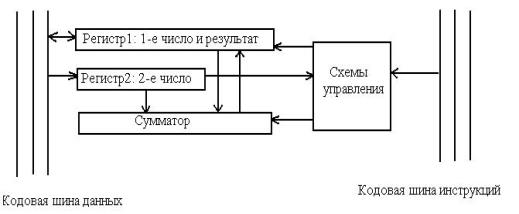
Рис. 6.4 Функциональная схема АЛУ
Арифметикo-логическое устройство предназначено для выполнения арифметических и логических операций преобразования информации.
Функционально АЛУ (рис. 5.1) состоит обычно из двух регистров, сумматора и схем управления (местного устройства управления).
Сумматор - вычислительная схема, выполняющая процедуру сложения поступающих на ее вход двоичных кодов.
Регистры - быстродействующие ячейки памяти различной длины. При выполнении операции в Pr1 помещается первое число, участвующее в операции, а по завершении операции - результат; в Pr2- второе число, участвующее в операции (по завершении операции информация в нем не изменяется). Регистр 1 может принимать информацию с кодовых шин данных, и выдавать информацию с этих шин.
Схемы управления принимают по кодовым шинам инструкций управляющие сигналы от устройства управления и преобразуют их в сигналы для управления работой регистров и сумматора АЛУ.
АЛУ выполняет арифметические операции только над двоичной информацией с запятой, фиксированной после последнего разряда, т. е. только над целыми двоичными числами.
Выполнение операций над двоичными числами с плавающей запятой и над двоично-кодированными десятичными числами осуществляется или с привлечением математического сопроцессора, или по специально составленным программам.
Устройство управления
Для реализации любой команды необходимо на соответствующие управляющие входы любого устройства компьютера подать определенным образом распределенную во времени последовательность управляющих сигналов. Часть цифрового вычислительного устройства, предназначенная для выработки этой последовательности, называется устройством управления.
Любое действие, выполняемое в операционном блоке, описывается некоторой микропрограммой и реализуется за один или несколько тактов. Элементарная функциональная операция, выполняемая за один тактовый интервал и приводимая в действие управляющим сигналом, называется микрооперацией. Совокупность микроопераций, выполняемых в одном такте, называется микрокомандой (МК). Если все такты должны иметь одну и ту же длину, а именно это имеет место при работе компьютера, то она устанавливается по самой продолжительной микрооперации. микрокоманды, предназначенные для выполнения некоторой функционально законченной последовательности действий, образуют микропрограмму. Например, микропрограмму образует набор микрокоманд для выполнения команды умножения. Устройство управления предназначено для выработки управляющих сигналов, под воздействием которых происходит преобразование информации в арифметико-логическом устройстве, а также операции по записи и чтению информации в/из запоминающего устройства.
Устройства управления делятся на:
УУ с жесткой, или схемной логикой;
УУ с программируемой логикой (микропрограммные УУ).
В устройствах управления первого типа для каждой команды, задаваемой кодом операции, строится набор комбинационных схем, которые в нужных тактах вырабатывают необходимые управляющие сигналы. В микропрограммных УУ каждой команде ставится в соответствие совокупность хранимых в специальной памяти слов - микрокоманд. Каждая из микрокоманд содержит информацию о микрооперациях, подлежащих выполнению в данном такте, и указание, какое слово должно быть выбрано из памяти в следующем такте. Микропрограммное устройство управления представлено на рисунке. Преобразователь адреса микрокоманды преобразует код операции команды, присутствующей в данный момент в регистре команд, в начальный адрес микропрограммы, реализующей данную операцию, а также определяет адрес следующей микрокоманды выполняемой микропрограммы по значению адресной части текущей микрокоманды.
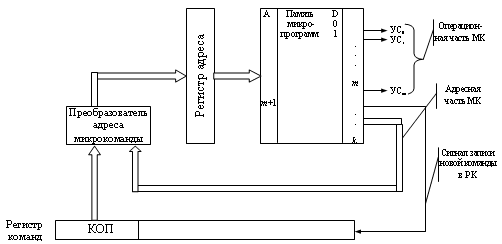
Рис. 6.5 Функциональная схема микропрограммного устройства управления
Устройство управления содержит дешифратор операций - логический блок, выбирающий в соответствии с поступающим из регистра команд кодом операции (КОП) один из множества имеющихся у него выходов.
Постоянное запоминающее устройство микропрограмм - хранит в своих ячейках коды об управляющих сигналах (импульсах), необходимые для выполнения в блоках ПК операций обработки информации. Эти коды, по выбранному дешифратором операций в соответствии с кодом операции команды, считывает из ПЗУ микропрограмм необходимую последовательность управляющих сигналов.
Узел формирования адреса (находится в интерфейсной части МП) - устройство, вычисляющее полный адрес ячейки памяти (регистра) по реквизитам, поступающим из регистра команд и регистров микропроцессорной памяти.
Кодовые шины данных, адреса и инструкций - часть внутренней шины микропроцессора. В общем случае УУ формирует управляющие сигналы для выполнения следующих основных процедур:
Выборки из регистра-счетчика адреса команды МПП адреса ячейки ОЗУ, где хранится очередная команда программы;
Выборки из ячеек ОЗУ кода очередной команды и приема считанной команды в регистр команд;
Расшифровки кода операции и признаков выбранной команды;
Считывания из соответствующих расшифрованному коду операции ячеек ПЗУ микропрограмм управляющих сигналов (импульсов), определяющих во всех блоках машины процедуры выполнения заданной операции, и пересылки управляющих сигналов в эти блоки;
Считывания из регистра команд и регистров МПП отдельных составляющих адресов операндов (чисел), участвующих в вычислениях, и формирования полных адресов операндов;
Выборки операндов (по сформированным адресам ) и выполнения заданной операции обработки этих операндов;
Записи результатов операции в память;
Формирования адреса следующей команды программы.
Микропроцессорная память
Микропроцессорная память - память небольшой емкости, но чрезвычайно высокого быстродействия (время обращения к МПП, т. е. время, необходимое на поиск, запись или считывание информации из этой памяти, измеряется наносекундами).
Она предназначена для кратковременного хранения, записи и выдачи информации, непосредственно в ближайшие такты работы машины, участвующей в вычислениях. МПП используется для обеспечения высокого быстродействия машины, так как, основная память и даже кэш-память, не всегда обеспечивает скорость записи, поиска и считывания информации, необходимую для эффективной работы быстродействующего микропроцессора. Микропроцессорная память состоит из быстродействующих регистров с разрядностью не менее машинного слова. Количество и разрядность регистров в разных микропроцессорах различны. Регистры микропроцессора делятся на регистры общего назначения (РОН) и специальные. Специальные регистры применяются для хранения различных адресов (адреса команды, например), признаков результатов выполнения операций и режимов работы ПК (регистр флагов, например) и др. Регистры общего назначения являются универсальными и могут использоваться для хранения любой информации. Особенностью РОН является то, что к ним не надо адресоваться через основную память МП. Они имеют номера, зашитые в микропрограммном устройстве.
Структура адресной памяти процессора
Память состоит из ячеек, каждая из которых может хранить некоторую порцию информации. Каждая ячейка имеет номер, который называется адресом. Если память содержит n ячеек, они будут иметь адреса от 0 до n-1, как правило, каждая ячейка содержит один байт. Для процессора байтовая организация оперативной памяти является не только основной, но и вполне естественной (см. рис. 6.6). Для хранения данных в такой памяти и обращения к ней надо каждый раз наращивать (инкрементировать) счетчик команд на единицу.
Однако физически при работе с памятью по шине передаются не отдельные байты, а машинные слова. В 32-разрядной архитектуре машинное слово -- это четыре подряд идущих байта, при этом адрес младшего байта кратен четырем. (В 64-разрядной архитектуре машинное слово состоит из восьми байтов.) Машинное слово -- это наиболее естественный элемент данных для процессора. Принято нумеровать биты внутри машинного слова (как и внутри байта) справа налево, начиная с нуля и кончая 31. Младший бит имеет нулевой номер, старший, или знаковый, бит -- номер 31 . Младшие биты числа находятся в младших битах машинного слова. В этом случае каждое 16-разрядное слово состоит из двух последовательно расположенных байтов. Например, байты 2 и 3 образуют одно полное слово, а байты 3 и 4 нет. При работе с такой памятью счетчик команд микропроцессора после выборки каждой команды должен наращиваться на 2, а не на 1, как в предыдущем случае. Аналогично решается задача в случае 4-х байтового слова.
Необходимо отметить, что и в том, и в другом случае слово, содержащее это число, имеет, адрес - 0, но в одном случае мы записываем его в прямом виде - 17BA, а в другом в перевернутом - ВА17. Принято в качестве адреса слова, которое состоит из нескольких последовательно расположенных байтов, использовать адрес байта с наименьшим номером. В итоге адреса слов уже не будут меняться через единицу, приращение будет зависеть от длины машинного слова. Например, при обращении к целому слову (с содержимым 17BA) процессор выставляет адрес 0. При обращении к младшему байту этой ячейки (с содержимым BA) процессор выставляет тот же самый адрес 0, но использует команду адресующую байт, а не слово. При обращении к старшему байту этой же ячейки (с содержимым 17) процессор выставляет адрес 1 и использует команду адресующую байт. Архитектура Big End была популярна в середине XX века. К концу 70-х годов программисты осознали, что Little End-архитектура гораздо удобнее. Тем не менее многие компьютерные протоколы ориентируются на Big End, поскольку они были приняты достаточно давно. Например, все протоколы сети Internet передают данные в формате Big End, т. к. они были разработаны в 70-х годах XX века. На машинах с архитектурой Little End приходится переставлять байты внутри слова перед отправкой IP-пакета в сеть или при получении IP-пакета из сети.
Интерфейсная часть МП
Интерфейсная часть МП предназначена для связи и согласования МП с системной шиной компьютера, а также для приема, предварительного анализа команд выполняемой программы и формирования полных адресов операндов и команд. Интерфейсная часть включает в свой состав адресные регистры, узел формирования адреса, блок регистров команд, являющийся буфером команд в МП, внутреннюю интерфейсную шину МП и схемы управления шиной и портами ввода-вывода. Порты ввода-вывода - это пункты системного интерфейса компьютера, через которые МП обменивается информацией с другими устройствами. Всего портов у МП может быть 65536. Каждый порт имеет адрес - номер порта, хранящийся в соответствующей ячейке памяти. Порт любого устройства содержит аппаратуру сопряжения и два регистра памяти - для обмена данными и обмена управляющей информацией.
Тракт данных типичного процессора
Тракт данных типичного фон-неймановского процессора состоит из регистров (обычно от 8 до 32), АЛУ и нескольких коммуникационных шин. Структура тракта, особенности архитектуры процессора зависят от структуры системы команд.
Большинство команд можно разделить на две группы: команды типа регистр-память и типа регистр-регистр. Команды первого типа вызывают слова из оперативной памяти и помещают их в регистры, где они используются в качестве входных данных АЛУ. В этом случае регистры выполняют специальные функции и носят названия: регистр данных (запомним, что разрядность слова соответствует разрядности регистра данных), регистр адреса, регистр команд. Самый важный регистр - счетчик команд, который указывает, какую команду нужно выполнять дальше.
Содержимое регистров поступает во входные регистры АЛУ, которые служат в качестве буфера (временного хранилища данных, как, собственно, и любой регистр по определению). Это абсолютно необходимо, т. к. АЛУ может выполнять операции сложения, вычитания и т. д. только если входные данные приходят к нему одновременно. Содержимое АЛУ (результат операции или пересылки) отправляется в следующий регистр - буфер, иногда его называют аккумулятором. При этом даже простые команды занимают 3-4 такта частоты процессора.
Команды второго типа (регистр-регистр) вызывают два операнда из регистров процессора, играющих роль сверхбыстродействующей памяти, помещают их во входные регистры АЛУ, выполняют над ними какую-нибудь арифметическую или логическую операцию и переносят результат обратно в один из регистров. Характерной особенностью этого метода является существенно более высокое быстродействие, т. к. операция обращения к ОП (наиболее длительная) производится заранее и не влияет на время выполнения, например, сложения. Описанный процесс называется циклом тракта данных, и именно он определяет, что и как быстро может делать машина.
Базовые команды
Процессор выполняет каждую команду (инструкцию) за несколько шагов (тактов):
Выборка очередной команды (ЦП вызывает команду из ОП и переносит ее в регистр команд);
Формирование адреса следующей команды (меняется значение счетчика команд);
Декодирование команды (определяется тип вызванной, текущей команды);
Выборка операндов (если команда использует "слово" из памяти, определяет где находится это слово и вызывает его; переносит слово из ОП в один из регистров (регистр данных));
Выполнение операции (выполняет команду (АЛУ));
Запись результата (заносит результат в промежуточный буфер, регистр - аккумулятор);
Переходит к шагу 1 или заканчивает выполнение программы "ОСТАНОВ".
Такая последовательность шагов: выборка - декодирование - исполнение является основой работы всех компьютеров. Описание работы ЦП можно представить, или имитировать, в виде программы-интерпретатора на языке Java. Сама возможность имитировать работу ЦП с помощью программы, показывает, что программа вычислений не обязательно должна выполняться аппаратным процессором. Напротив, вызывать из памяти, определять тип команды и выполнять команду может другая программа (интерпретатор). Другими словами, применение трансляторов с ЯВУ не только способ перейти к машинному языку, языку понятному машине, но и мощный метод эмуляции работы ЦП.
Трансляторы
Как следует из многоуровневой архитектуры ЭВМ, прикладные программы пишутся на языках высокого уровня (ЯВУ). Существуют сотни таких языков, но процессор понимает только язык единиц и нулей. Поэтому программы на ЯВУ обычно транслируются на уровень 3 или 4 (уровень ассемблера). Программы трансляторы бывают двух видов - интерпретаторы и компиляторы.
Программа (микропрограмма) способная вызывать команды, операнды из памяти, определять тип команд и выполнять эти команды называется - интерпретатор.
Интерпретатор разбивает исходную программу на маленькие шаги и последовательно переводит каждую команду в исполняемый машинный код, посылая ее сразу на исполнение. Интерпретатор, как правило, хранится в виде микрокоманд в ПЗУ, например, устройства управления.
Отличительные особенности: медленно (надо декодировать каждую команду, процессор простаивает), но легко переносится на любую платформу, самое главное - в этом случае машина получается существенно более простой, т. к. часть аппаратного обеспечения заменяется программным.
Другая возможность создать транслятор - это использовать программу компилятор. Компилятор переводит полностью исходную программу на эквивалентный набор машинного языка и только затем загружает ее в память машины для выполнения.
Отличительные особенности: быстро, но изменение платформы приводит к необходимости разработки нового компилятора. Есть и третья возможность, известная под именем Java машины или виртуальной машины Java - это компилятор, транслирующий ЯВУ на промежуточный псевдокод, а затем с псевдокода интерпретатор. При этом сочетаются отличительные особенности того и другого метода.
Компьютеры могут иметь интерпретатор и тогда они гораздо проще и дешевле чем компьютеры без интерпретации, а могут и не иметь, но тогда они должны использовать технику компиляции. Впервые интерпретация получила применение при реализации компьютеров способных выполнять сложные команды, предназначенные для высокопроизводительных и дорогих машин (IBM S./360, S/370, S/390). Это сформировало тенденцию введения все более и более сложных команд (порядка 300 у VAX DEC и 200 способов определения операндов). Главное преимущество интерпретации заключалось в том, что можно было разработать простой процессор, а вся сложность сводилась к созданию интерпретатора.
(Такое операторное управление вычислительным процессом привело к необходимости использовать разнообразные форматы обработки данных (например: тривиальное суммирование в S/360 имело около 20 различных форматов). Хотя машина была способна вычислять экспоненту, логарифм, но простые операции производились очень медленно. Действительно, что бы перевести команду сложения в машинный код, интерпретатор должен был просмотреть более 20 возможных команд. Такое разнообразие инструкций потребовало и множества командных форматов различной длины.) Каждый процессор имеет свои специфические команды, наборы регистров и режимы адресации, поэтому программу на Ассемблере невозможно перенести с одной аппаратной платформы на другую. Для того чтобы не зависеть от конкретного процессора, часто используют язык описания команд RTL, от англ. Register Transfer Language -- язык перемещения регистров. Фактически RTL представляет собой Ассемблер, не зависящий от конкретного процессора. Многие компиляторы, например, gcc, не переводят программу с языка высокого уровня сразу на язык машинных команд, а сначала транслируют ее на язык RTL. Затем на уровне RTL выполняется оптимизация кода, которая составляет 99% работы компилятора. И лишь на последнем этапе программа c языка RTL переводится на язык команд конкретного процессора. Поскольку RTL максимально приближен к Ассемблеру, трансляция из RTL в конкретный Ассемблер не представляет никакого труда. Такой подход позволяет сделать компилятор с языка высокого уровня практически независимым от конкретной архитектуры. Зависим лишь модуль, осуществляющий перевод с RTL в Ассемблер, но его реализация требует минимальных усилий.
Архитектура системы команд и классификация процессоров
Итак, именно эволюция ЭВМ с интерпретатором (позже названных машинами с CISC процессорами) сформировала тенденцию использования:
Сложных, длинных команд;
Разнообразных форматов данных;
Разнообразных форматов команд;
Медленное выполнение наиболее простых операций.
С другой стороны, именно эволюция CISC (Complex Instruction Set Computer) процессоров послужила мощным стимулом для возникновения концепции RISC (Reduced Instruction Set Computer) архитектуры. Дело в том, что в начале 80-х архитектура CISC стала серьезным препятствием на пути реализации идеи "один процессор в одном кристалле", поскольку для работы с традиционным расширенным списком команд требуется очень сложное устройство управления (микропрограммный интерпретатор), занимающее свыше 60% площади кристалла. К тому времени стали известны результаты статистических исследований ученых IBM - правило 20/80.
На 20% команд программы приходится 80% времени исполнения задания.
В 1980 году группа разработчиков университета Беркли во главе с Девидом Паттерсоном и Карлом Секуин начали разработку процессора без использования интерпретации. Именно они и придумали термин RISC архитектура и выпустили RISC I, RISC II, которые эволюционировали в процессоры SPARC, а уже в 1981 году появились и знаменитые процессоры MIPS (Джон Хенноси - Стенфорд). Концепция RISC - архитектуры базируется на почти очевидной логической формуле: если быстрые технологии и параллельная обработка недостижимы для всего списка команд из-за высокого уровня затрат, необходимо оставить в системе команд несколько десятков простых, наиболее универсальных и часто употребляемых инструкций, исключив сложные и редко используемые.
Результатом должно было стать существенное упрощение центрального управления, а значит высвобождения значительной поверхности кристалла процессора для размещения более мощных средств обработки данных. Так возникла философия RISC - меньше команд, выше скорость и одна команда за один такт.
Первоначально RISC - процессоры действительно существенно вырвались вперед, сравните:
Процессор 80386, технология КМОП, частота 25 МГц, число транзисторов 275 000, производительность - 5 млн. оп. в сек (CISC);
Процессор R3000, технология КМОП, частота 25 МГц, число транзисторов 11500, производительность - 20 млн. оп. в сек (RISC). Сегодня условны и эти названия и различия между ними. Те и другие заимствовали лучшие черты конкурентов.
Для CISC процессоров характерно:
Небольшое число РОН (до 16);
Большое количество машинных команд (свыше 200);
Большое количество разнообразных форматов команд и методов адресации;
Преобладание двухадресного и безадресного формата команд;
Наличие команд типа "регистр - память";
Команда выполняется за несколько тактов;
Использование механизма интерпретации.
Для RISC процессоров характерно:
Все обычные команды непосредственно выполняются аппаратным обеспечением, они не интерпретируются микрокомандами;
В повышении производительности главную роль играет параллелизм, одновременное выполнение большого числа команд и одновременная обработка большого количества данных;
Большое количество РОН (свыше 32), лучший способ избежать транзакций - иметь достаточное количество регистров;
Сокращенный набор команд (несколько десятков);
Единообразие форматов команд, одинаковая длина и минимум адресных форматов;
Наличие и преобладание форматов команд "регистр - регистр", к памяти должны обращаться только команды загрузки и сохранения;
Команды выполняются за один такт, а, как правило, несколько команд за один такт;
Использование механизма компиляции.
И, само собой разумеется, все перечисленные базовые принципы RISC - архитектуры не существуют вне основного закона RISC: система команд должна содержать минимум наиболее часто используемых и наиболее простых инструкций.
При построении большинства CISC - процессоров используется аккумуляторная архитектура ("память-регистр"). При этой архитектуре, в общем случае, требуется кроме собственно команды (например - сложение) еще две, по крайней мере, операции пересылки данных. При построении большинства RISC - процессоров применяется исключительно архитектура "регистр-регистр". При таком подходе любая из команд процессора может быть 3-х операндной и выполнена за один такт. При этом даже если RISC должен выполнить 4-5 простых команд вместо одной сложной, которую выполняет CISC все равно в выигрыше будет RISC т. к. его команды выполняются в 10 раз быстрее (поскольку они не интерпретируются). То, что в CISC архитектуре является сложной внутренней командой процессора, которую реализует интерпретатор, в RISC - целая подпрограмма, состоящая из простых, элементарных команд фиксированной длины, которую готовит компилятор. Реализация полной Гарвардской архитектуры, предсказание переходов и введение конвейеров команд и конвейеров обработки данных позволило на долгие годы RISC архитектуре стать лидером высокопроизводительных процессоров для серверов и рабочих станций.
Микроархитектура процессора Pentium II
В заключении, на примере процессора Pentium II, типичного процессора CISC-архитектуры, но с элементами RISC кратко затвердим основные черты процессоров.
Pentium II - один из процессоров семейства Intel. Он содержит ту же архитектуру системы команд, что и 80486, Pentium, Pentium Pro, однако с точки зрения аппаратного обеспечения, он представляет собой нечто большее. Действительно, он может обращаться к 64 Гбайт физической памяти, передавать данные в память и из памяти блоками по 64 бита, хотя и является 32-разрядной машиной. Более того, Pentium II является суперскалярным процессором.
Pentium II имеет двухуровневую кэш-память с полной Гарвардской архитектурой. Кэш первого уровня содержит 16 Кбайт для команд и 16 Кбайт для данных, а кэш-память второго уровня содержит 512 Кбайт команд и данных. Строка кэша состоит из 32 байт и работает на частоте процессора, тактовая частота кэша второго уровня в два раза меньше. На рисунке 6.12 показаны основные компоненты центрального процессора: блок вызова/декодирования, блок отправки/выполнения и блок возврата, которые вместе действуют как конвейер высокого уровня. Эти три блока обмениваются данными через пул команд - Re Order Buffer (буфер перестройки команд). Если говорить кратко, блок вызова/декодирования вызывает команды и разбивает их на микрооперации для хранения в ROB, блок отправки/выполнения получает микрооперации из буфера и выполняет их, блок возврата завершает выполнение каждой операции и обновляет регистры.
Блок вызова/декодирования содержит семи стадийный конвейер, блок отправки/выполнения содержит в своем составе блоки выполнения операций над целыми числами, блоки выполнения операций над числами с плавающей точкой и блоки выполнения команд ММХ (мультимедийная обработка данных). Блок возврата содержит в своем составе большой регистровый файл в регистрах которого хранятся значения завершенных команд, промежуточные результаты и т. д.
Система локальных шин и интерфейсов связывает ЦП с кэш-памятью второго уровня и мостом PCI, который играет важную роль в коммуникации обрабатываемых данных. Эти устройства находятся на материнской плате.
Микропроцессор на аппаратном уровне поддерживает мультипрограммный режим работы ЭВМ, то есть возможность иметь в памяти одновременно несколько готовых к выполнению программ, запуск которых осуществляется операционной системой в соответствии с алгоритмами ее функционирования либо в зависимости от особых ситуаций, складывающихся в работе внешних устройств. С этой возможностью неразрывно связаны средства защиты памяти, которые обеспечивают контроль над неразрешенными взаимодействиями между отдельными программами. Они включают в себя защиту при управлении памятью и защиту по привилегиям.
Главные особенности расширенного формата команды - возможность использовать любой из регистров общего назначения в любом из режимов адресации, а также добавление еще одного режима адресации - относительного базового индексного с масштабированием. При этом эффективный адрес формируется следующим образом:
ЭА = (base) + (index) - scale + disp,
Где (base) - значение базового регистра; (index) - значение индексного регистра; scale - величина масштабного множителя; disp - значение смещения, закодированного в самой команде.
Отметим, что в 32-разрядной архитектуре эффективный адрес обычно называют смещением (offset), в то же время отличая его от смещения, кодируемого в самой команде (displacement).
Выводы
Компьютерные системы состоят из трех основных компонентов: процессоров, памяти и устройств ввода-вывода. Задача процессора заключается в том, чтобы последовательно вызывать команды из ОП, декодировать их и выполнять.
Применяемая система команд ("память-регистр" или "регистр-регистр") определяют архитектуру тракта данных процессора.
Тракт данных и вид транслятора (компилятор или интерпретатор) определяют тот или иной вид процессора (RISC или CISC).
Современные процессоры содержат в своем составе как элементы RISC, так и CISC архитектуры.
Вопросы и задания
Объяснить значение терминов: транслятор, интерпретатор и компилятор.
Одно из следствий идеи фон Неймана хранить программу в памяти компьютера - возможность вносить изменения в хранимые программы. Приведите пример, где это может быть полезно применено (подсказка: подумайте об арифметических операциях над массивами).
Рассмотрим машину с трактом данных "регистр-регистр". Предположим, что загрузка регистров АЛУ занимает 5 нс, работа АЛУ - 10 нс, а помещение результата обратно в регистр - 5 нс. Какое максимальное число команд в секунду способна выполнить эта машина?
На компьютере 1 выполнение каждой команды занимает 10 нс, а на машине 2 - 5 нс. Можете ли вы с уверенностью сказать, что компьютер 2 работает быстрее?
Объясните различия в CISC и RISC архитектуре и к чему это приводит, в каких областях находит применение?
Лекция 7. Структурная организация ЭВМ - память
Общие сведения
Память ЭВМ - это совокупность всех запоминающих устройств, входящих в состав машины. Запоминающие устройства классифицируют по следующим признакам:
По типу (полупроводниковые, магнитные, конденсаторные, оптоэлектронные, голографические, криогенные и т. д.);
По функциональному назначению (ОЗУ, буферные - БЗУ, сверхоперативные - СОЗУ, внешние - ВЗУ, постоянные - ПЗУ, и т. д.);
По способу организации обращения (с последовательным поиском, с прямым доступом, адресные, стековые, страничные, ассоциативные и т. д.);
По характеру считывания (с разрушением или без);
По способу хранения (статические или динамические);
Этим классификация не исчерпывается, но мы рассмотрим только основные типы.
Важнейшие характеристики - емкость, удельная емкость (плотность записи), быстродействие (продолжительность операции быстродействия, т. е. время затрачиваемое на поиск единицы информации), пропускная способность (количество данных, предаваемых в секунду).
Архитектура памяти компьютера - система иерархическая, состоящая из нескольких уровней. Типы памяти отличаются по своему функциональному назначению, способам хранения информации, методам доступа, логической организации и конструктивно (см. рисунок ниже).
Все компьютеры используют четыре вида памяти: оперативную, постоянную, регистровую и внешнюю.
Оперативная память или память с произвольным доступом - Random Access Memory или ОЗУ предназначена для хранения информации, к которой приходится часто обращаться, и обеспечивает режимы ее записи, считывания и хранения. ОЗУ обладает адресным пространством, разделенным на несколько областей. Некоторые из них используются самой системой, другие предназначены для специальных целей. В первых процессорах семейства х86 память представлялась в виде сегментов размером по 64 Кбайт, а суммарный объем адресуемой памяти не превышал 1 Мбайт. При этом архитектура РС ограничивала размер собственно оперативной памяти объемом 640 Кбайт, начиная с нулевых адресов. Эта область называется основной памятью или стандартной (conventional memory). Основная память была предназначена для прикладных программ (400 -550 Кбайт), а остальное съедала операционная система вместе с разными драйверами. Потребности решаемых задач быстро переросли эти ограничения и в процессоры ввели средства организации виртуальной памяти. Было снято ограничение на 64-килобайтный размер сегмента, теперь любой сегмент может иметь почти произвольный (до 4 Гбайт) размер. Во-вторых, был введен механизм страничной трансляции адресов. С его помощью можно было реализовать не только виртуальную память размером 4 Гбайт без сегментации, но и формировать физический адрес с разрядностью 36 бит (64 Гбайт адресуемой памяти). С появлением 64-битных расширений размер виртуальной памяти увеличился до 264 байт.
Распределение адресного пространства памяти (Intel - совместимые)
Для оценки производительности основной памяти используются два основных параметра: задержка и полоса пропускания. Задержка памяти традиционно оценивается двумя параметрами: временем доступа (access time) и длительностью цикла (cycle time). Время доступа - промежуток времени между запросом на чтение и выдачей запрошенного слова из памяти. Длительность цикла - определяется минимальным временем между двумя последовательными обращениями к памяти.
Верхняя память (Upper Memory Area) - это 384 Кбайт, зарезервированных у верхней границы системной памяти. Верхняя память разделена на несколько частей:
Первые 128 Кбайт являются областью видеопамяти и предназначены для использовании видеоадаптерами, когда на экран выводится текст или графика, в этой области хранятся образы изображений;
Следующие 128 Кбайт отведены для программ BIOS адаптеров, которые записаны в микросхемах ПЗУ;
Последние 128 Кбайт зарезервированы для системной программы BIOS.
Видеопамять
Видеоадаптер использует часть системной памяти для хранения графической или символьной информации, выводимой на монитор. На некоторых платах видеоадаптеров, например VGA, содержатся собственные BIOS, которые размещаются в области системной памяти.
Дополнительная (extended) память
Как мы уже говорили в современных процессорах объем оперативной памяти может существенно превышать предел 1Мбайт, например для систем на базе Pentium II максимальный объем ОП составляет 64 Гбайт. Для адресации памяти за пределами первого мегабайта процессор должен работать в защищенном режиме..
Расширенная (expanded) память
В некоторых программах может использоваться еще одна разновидность памяти - расширенная память (Expanded Memory Specification). В отличии от основной (в пределах первого мегабайта) и дополнительной (от 2 до 16) памяти, расширенную память процессор адресовать не может. К ней можно обращаться только через небольшое окно размером 62 Кбайт, образуемое в области верхней памяти. EMS память используется только для хранения данных.
Постоянная память (ПЗУ - постоянное запоминающее устройство) обычно содержит такую информацию, которая не должна меняться в ходе выполнения программы. Она имеет также название ROM (Read Only Memory) которое указывает на то, что обеспечиваются только режимы считывания и хранения. Постоянная память энергонезависима. Все микросхемы ПЗУ по способу занесения в них информации делятся на масочные, программируемые производителем - ROM, однократно программируемые пользователем - Programmable ROM, и многократно программируемые пользователем - Erasable Prom. Данный тип памяти используется для хранения программы начальной загрузки компьютера - BIOS.
Регистровая память процессора находится на кристалле процессора, тактируется его частотой и служит для организации сверхбыстродействующей памяти, работающей в формате команд регистр-регистр.
Внешняя память реализована, как правило, на магнитных и оптических носителях самого разнообразного вида и конструкций. ВП предназначена для хранения большого массива данных и обмена этими данными с ОЗУ, через кэш-память и посредством интерфейса или контроллера диска.
Иерархия памяти компьютера
Память ЭВМ представляет собой иерархию запоминающих устройств (ЗУ), отличающихся средним временем доступа к данным, объемом и стоимостью хранения одного бита.
Очевидно, по мере продвижения по предложенной структуре сверху вниз, время доступа увеличивается от нескольких наносекунд у регистровой памяти до десятков микросекунд доступа к дискам. Увеличивается объем памяти (регистры в лучшем случае могут содержать 128 байт, а объем внешней памяти по существу не ограничен), а вот стоимость хранения данных в расчете на один бит уменьшается.
Иерархия памяти современных компьютеров строится на нескольких уровнях, причем более высокий уровень меньше по объему, быстрее и имеет большую стоимость в пересчете на байт, чем более низкий уровень. Уровни иерархии взаимосвязаны: все данные на одном уровне могут быть также найдены на более низком уровне, и все данные на этом более низком уровне могут быть найдены на следующем нижележащем уровне и так далее, пока мы не достигнем основания иерархии.
Иерархия памяти состоит из многих уровней, но в каждый момент времени мы имеем дело только с двумя близлежащими уровнями. Минимальная единица информации, которая может либо присутствовать, либо отсутствовать в двухуровневой иерархии, называется block или line. Размер блока может быть либо фиксированным, либо переменным. Если этот размер зафиксирован, то объем памяти является кратным размеру блока.
Успешное или неуспешное обращение к более высокому уровню называются соответственно попаданием (hit) или промахом (miss). Попадание - есть обращение к объекту в памяти, который найден на более высоком уровне, в то время как промах означает, что он не найден на этом уровне. Доля попаданий (hit rate) или (hit ratio) есть доля обращений, найденных на более высоком уровне. Иногда она представляется процентами. Доля промахов (miss rate) есть доля обращений, которые не найдены на более высоком уровне.
Время обращения при попадании: hit time, потери на промахи miss penalty - это время на замещение блока высокого уровня блоком из более низкого уровня + время пересылки этого блока. Различают время пересылки (transfer time) и время доступа (access time).
|
Размер строки - line |
4-128 байт |
|
Hit time |
1-4 такта |
|
Miss Penalty |
8-32 такта |
|
Access time |
6-10 тактов |
|
Transfer time |
2-22 такта |
|
Miss rate |
1-2 % |
Оперативная память, типы ОП
Тип оперативной памяти важен постольку, поскольку технология изготовления и физические принципы ее функционирования определяют самый важный параметр - быстродействие. Чем выше быстродействие ОП, тем меньше время доступа к ней. В настоящее время наиболее распространены микросхемы памяти двух типов: статические ОЗУ - SRAM и динамические - DRAM. Разумеется, более быстрая память дороже стоит, поэтому SRAM используется, как правило, для кэш памяти, в регистрах микропроцессора и системах управления.
Конструктивное исполнение
Динамическое ОЗУ со времени своего появления прошло несколько стадий роста и продолжает совершенствоваться. Вначале микросхемы динамического ОЗУ производились в DIP-корпусах. Затем их сменили модули SIPP, DIMM, SIMM и RIMM.
SIMM - модуль (Single In-Line Memory Module), модуль с однорядным расположением выводов, могут иметь объем 256 Кбайт, 1,2,4, 8, 16 и 32 Мбайт. Модули SIMM для соединения с системной платой имеют не штырьки, а позолоченные полоски (так называемые pin, пины). Первыми SIMM-модулями были 30-пиновые SIMM FPM DRAM, с частотой работы 29 МГц, затем 72-пиновые EDO RAM с частотой 50 МГц. Существенной особенностью ПК, собранных на Pentium является то, что они имеют 64-разрядную шину данных, а это означает, что 32-разрядные SIMM можно устанавливать только парами. В настоящее время SIMM-модули, как 30-пиновые, так и 72-пиновые заменяются модулями DIMM. DIMM (Dual Inline Memory Module) - модуль памяти с двойным расположением 168 выводов. Следует отметить, что разъем DIMM имеют много разновидностей DRAM.
SDRAM (Synchronic DRAM) - динамическое ОЗУ с синхронным интерфейсом, работающие на частотах 143 МГц и выше. ESDRAM - динамические ОЗУ с синхронным интерфейсом, с кэшом на самом модуле, работающие на частотах 200 МГц и выше. SLDRAM - имеет в своем составе SRAM, работает на частоте до 400 МГц. RDRAM, RIMM - работает на частоте до 800 МГц.
Мы уже видели, что стоимость хранения данных в расчете на один бит увеличивается с ростом быстродействия. Однако пользователю хотелось бы иметь и недорогую, и быструю память. Кэш-память представляет некоторое компромиссное решение этой проблемы. Однако известно, рост производительности процессора составляет 60% в год, а уменьшение задержки памяти всего на 7%. Разрыв между быстродействием CPU и быстродействием памяти приводит к появлению "узкого горла". Кэш-память только частично решает эту проблему, создавая новую - почти 50% площади кристалла отдается кэшу (например, Alpha 21164 компании Digital).
Кэш-память
Одним из самых важных вопросов компьютерной техники был и остается вопрос построение такой системы памяти, которая могла бы передавать операнды процессору с той же скоростью, с которой он может их обрабатывать. Одним из способов решения этой проблемы - это технология сочетания маленькой и быстрой памяти с большой, но медленной или технология кэш-памяти. Основная идея кэш-памяти проста, в ней находятся наиболее часто встречающиеся слова. Программистам известно, что в течении какого то отрезка времени ограниченный фрагмент кода работает с ограниченным набором данных, если эту часть кода и данных разместить в быстрый буфер, то получим увеличение производительности всего процессора. Если процессору нужно, какое то слово, сначала он обращается к кэш-памяти. Если значительная часть слов находится в кэше, среднее время доступа значительно сокращается.
В основе иерархической организации памяти и принципа функционирования кэш-памяти лежит принцип локальности - большинство программ не выполняют обращений к своим командам и данным равновероятно, а оказывают предпочтение некоторой часть адресного пространства, при этом различают:
Пространственную локализацию, которая основана на вероятности того, что в скором времени появится потребность обратится к тому же разделу памяти из котрого была считана предыдущая информация;
Временную локальность, которая имеет место тогда, когда недавно запрашиваемые ячейки запрашиваются снова.
Принцип действия кэш-памяти
Основная память и кэш-память делятся на блоки фиксированного размера с учетом принципа локальности. Блоки внутри кэша называют строками кэш-памяти (cache line). Если обращение к кэш-памяти нерезультативно, из основной памяти в кэш загружается вся строка, а не только необходимое слово. Возможно, через некоторое время понадобятся другие слова из этой строки.
Обычно содержимое кэш-памяти представляет собой совокупность записей обо всех загруженных в нее элементах данных из основной памяти. Строка кэш-памяти состоит из нескольких последовательных байтов (обычно от 4 до 64). Строки нумеруются, начиная с 0. Т. е. если размер строки составляет 16 байт, то строка 0 - это байты с 0 по 15, строка 1 - это байты с 16 по 31 и т. д. (см. Рис 6.2). Возьмем в качестве примера некоторый микропроцессор с 12 разрядной шиной адреса (объем памяти 4Кбайт) и кэшем из 16 строк по 16 байт.
В любой момент времени несколько строк находятся в кэш-памяти. Когда происходит обращение к памяти, контроллер кэша проверяет, есть ли нужное слово в данный момент в кэш-памяти, если нет тогда происходит загрузка необходимой строки из ОП. Существует множество вариаций данной схемы, различающихся временем доступа, производительностью и т. д.
Кэш-память прямого отображения
Самый простой тип кэш-памяти - это кэш прямого отображения, когда любая строка из ОП может появиться только на одном месте кэша. Пусть кэш-память содержит 16 строк по 16 байт. Каждый элемент кэша (строка) вмещает ровно одну строку из ОП. В этом случае мы имеем кэш-память объемом 256 байт на которую должен быть отображен объем 4 Кбайт ОП (Рис.6.3)
Кэш - 256 байт ОП - 4 Кбайт
Очевидно, что при таком отображении основной памяти на память кэша каждому блоку (по объему) ОП отводится одна строка кэш-памяти.
Предположим, процессор обращается по адресу 0010 0001 0110, в этом случае мы должны проверить 1-ую строку кэша (0001) и если в ней находится нужная строка памяти, то считать 5-ый байт (0110). Но в этой строке кэша могут быть представлены 1,17,33 и т. д. строки из основной памяти. Как же узнать, какая именно строка записана в кэш? Для этого служит информация представленная в тэге (tag), четыре бита в нашем случае (0010), т. е. это 33 строка (0010 0001) и никакая другая. Таким образом, физический адрес разбивается на несколько частей:
Из рисунка видно, что в первую строку кэша можно помещать только первую, семнадцатую, тридцать третью и т. д. строки основной памяти.
Каждый элемент кэш-памяти состоит из четырех частей:
Адрес строки кэша;
Блок достоверности, управляющая информация (указывает есть ли достоверные данные в элементе или нет, и т. д.);
Поле "Тег", указывает соответствующую строку памяти, из которой поступили данные;
Поле "Данные" содержит копию данных основной памяти, поле данных вмещает одну строку в 16 байт.
Как мы видим, каждая запись включает в себя адрес, который этот элемент данных имеет в ОП, сами данные, дополнительную управляющую информацию (признак модификации, признак частотности обращения к данным за некоторый последний промежуток времени), которая используется для реализации алгоритма замещения данных в кэш-памяти.
Для каждой строки в кэш-памяти должен храниться один управляющий бит, называемый битом достоверности. При включении питания системы и при загрузке с диска в ОП все биты достоверности устанавливаются в ноль. Когда строка кэша в первый раз загружается из ОП, его бит достоверности устанавливается в 1. Если блок ОП обновляется из другого источника (например, из ЖД), минуя кэш, система проверяет, находится ли загружаемый блок в кэше. Если нет, его бит достоверности устанавливается в 0, чтобы в кэш-памяти не оказалось устаревших данных.
Итак, при каждом обращении к основной памяти по физическому адресу просматривается содержимое кэш-памяти с целью определения, не находятся ли там нужные данные. Зачастую, кэш-память не является адресуемой, поэтому поиск данных осуществляется по содержимому - по взятому из запроса значению поля "Тэг - адрес в ОП". Далее возможны два варианта:
Если данные обнаруживаются в кэше, т. е. произошло кэш-попадание (cache-hit), они считываются из нее и результат передается источнику запроса;
Если нужные данные отсутствуют в кэш-памяти, т. е. произошел кэш-промах (cache-miss), они считываются из основной памяти и одновременно копируются из ОП в кэш.
На практике в кэш-память считывается не один элемент данных, к которому произошло обращение, а целый блок данных, что увеличивает вероятность попадания в кэш. Покажем на примере эффективность применения кэш-памяти. Пусть имеется ОП со средним временем доступа t1=60,0 нс и кэш-память, имеющая время доступа к данным t2=12,0 нс, а p - вероятность кэш-попадания, причем p=0,8, тогда среднее время доступа к данным t в системе с кэш-памятью равно:
T = t1 (1-p) + t2p = 60,0*0,2 + 12,0*0,8 = 21,6 нс
Очевидно, что полученное среднее время доступа к такой системе больше чем среднее время доступа непосредственно к кэшу, но значительно меньше времени доступа к ОП. В реальных системах вероятность попадания в кэш близка к 0,9. Столь высокое значение hit rate связано с наличием у данных объективных свойств - локальность обращения, которое включает пространственную локальность (если произошло обращение по некоторому адресу, то с высокой степенью вероятности произойдет обращение к соседним адресам), временную локальность (если произошло обращение по некоторому адресу, то в ближайшее время будет обращение по этому же адресу). Однако, несмотря на свою простоту и высокое быстродействие кэш-память прямого доступа обладает большими недостатками, вытекающими из того факта, что различные строки основной памяти конкурируют за одну и ту же область кэш-памяти. Решение этих проблем достигается на пути конструирования различных видов иерархии кэш-памяти.
Способы организации кэш-памяти
Чтобы описать некоторый уровень иерархии памяти надо ответить на следующие четыре вопроса:
- 1. Где может размещаться блок на верхнем уровне иерархии? (размещение блока). 2. Как найти блок, когда он находится на верхнем уровне? (идентификация блока). 3. Какой блок должен быть замещен в случае промаха? (замещение блоков). 4. Что происходит во время записи (стратегия записи)?
Рассмотрим организацию кэш-памяти в общем случае, отвечая на четыре вопроса об иерархии памяти.
Похожие статьи
-
Что происходит во время записи? - Компьютерные и сетевые технологии
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и...
-
Сетевые технологии в работе секретаря - Компьютерные технологии в деятельности секретаря
Практически повсеместное подключение имеющихся в офисе компьютеров к сети Интернет делает возможным использование сетевых технологий для реализации...
-
Где может размещаться блок в кэш-памяти? - Компьютерные и сетевые технологии
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации: Если каждый блок основной памяти имеет только одно фиксированное...
-
У каждого блока в кэш-памяти имеется адресный тег, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти теги обычно...
-
Секретарь - под этим словом часто скрываются разные функции, должности, степень ответственности. Эта профессия уникальна, к ней можно предъявлять чисто...
-
База данных представляет собой информационную модель того объекта (организации или предприятия), информация о котором требуется пользователю для...
-
Большинство ученых в наши дни отказываются от попыток дать строгое определение информации и считают, что информацию следует рассматривать как первичное,...
-
Компьютерные преступления - Основы теории информации
Экономические Против личных прав Против общественных и гос интересов Признаки преступления: Уничтожение, блокирование, модификация или копирование...
-
Для компьютерного оборудования и данных (информации) существуют три основные угрозы: Физическое воровство, которое включает подключение к различным...
-
ДОУ представляет собой взаимосвязанную совокупность средств, методов и персонала, используемых для хранения, обработки данных и выдачи документов для...
-
Техническое обеспечение (ТО) - совокупность технических средств, предназначенных для работы информационной системы, а также соответствующая документация...
-
Повторитель (repeater) Усиливает сигнал сетевого кабеля, который затухает на расстоянии более 100 м. Он работает на физическом уровне стека протоколов,...
-
Восстановление файлов - Компьютерные сети. Защита и резервирование компьютерной информации
Существуют несколько способов восстановления файлов, ошибочно удаленных с диска, либо поврежденных из-за логических ошибок в файловой структуре или...
-
История развития компьютерных технологий в России Компьютеры проникли во все сферы деятельности человека, начиная с начального образования и заканчивая...
-
Основные понятия баз данных. Цели использования баз данных - Разработка базы данных
В широком смысле слова база данных (БД) - это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Для удобной...
-
Обработка информации - Теоретические основы информационных технологий
Обработка информации производится на ПЭВМ, как правило, децентрализовано, в местах возникновения первичной информации, где организуются...
-
Угроза - целенаправленное действие, которое повышает уязвимость накапливаемой, хранимой и обрабатываемой системы информации и приводит к ее случайному...
-
Резервирование файлов - Компьютерные сети. Защита и резервирование компьютерной информации
Необходимость резервирования информации в ЭВМ может быть вызвана нехваткой места на диске или защитой от возможной порчи и разрушения информации (при...
-
Компьютерный вирус - это небольшая программа, написанная в машинных кодах, которая способна внедряться в другие программы, сама себя копировать и...
-
Понятие о компьютерном математическом моделировании Модель - материальный объект, система математических зависимостей или программа, имитирующая...
-
Хранение и накопление информации - Теоретические основы информационных технологий
Хранение и накопление информации вызвано многократным ее использованием, применением условно-постоянной, справочной и других видов информации,...
-
Работа с текстовыми документами с помощью Word, Excel и др. В настоящее время практически все офисы оснащены средствами вычислительной техники,...
-
Сервисы и протоколы. World Wide Web (WWW) - Интернет технологии
World Wide Web (WWW, Всемирная паутина) - это наиболее популярный вид информационных услуг Internet, основанный на архитектуре клиент-сервер. В конце...
-
Стандарты современных сетей, Эталонная модель OSI. - Сетевые стандарты и протоколы
Эталонная модель OSI. Перемещение информации между компьютерами различных схем является чрезвычайно сложной задачей. В начале 1980 гг. Международная...
-
Чернобыль - опасный компьютерный вирус - Компьютерные вирусы
Компьютерный вирус Чернобыль - относится к резидентным вирусам, поражающим системы Windows 95, Windows 98. Размер вируса ничтожен, всего 1 Кб. Внедряясь,...
-
Уровни программного обеспечения. - Основы теории информации
1. Базовый уровень - самый низкий уровень ПО представляет базовое ПО. Оно отвечает за взаимодействие с базовыми аппаратными средствами. Как правило,...
-
ПО развивается исходя из требований других подсистем. ПО при обработке данных является связующим звеном между комплексом технических средств и другими...
-
Структурирование информации - Информационные системы: понятия и характеристика
Системы управления базами данных выполняют следующие две основные функции: А) хранение и ведение представления структурной информации (данных); Б)...
-
Электронная цифровая подпись (ЭЦП) - одна из криптографических систем зашиты контроля и подлинности информации. Значение ЭЦП усилилось при передаче...
-
Многоуровневые сетевые модели, Сетевая модель - Компьютерные сети
Глобальные сети объединяют в себе огромное количество географически распределенных узлов. Множество вариантов программно-технической реализации передачи...
-
Сбор и регистрация информации - Теоретические основы информационных технологий
Сбор и регистрация информации происходят по-разному и в различных объектах. Процесс перевода информации в выходные данные в технологических системах...
-
Выбор способа объединения подсетей на магистрали, например, с помощью маршрутизации, с помощью шлюзов или же с помощью транслирующих коммутаторов. При...
-
Резервное копирование и восстановление информации - Эксплуатация объектов сетевой инфраструктуры
Резервное копирование - это процесс создания когерентной (непротиворечивой) копии данных. Резервное копирование становится все более важным на фоне...
-
АРМ - это рабочее место, которое оснащено вычислительной техникой и другими инструментальными средствами, обеспечивающими автоматизацию большей части...
-
Использование информационных технологий в образовании создают предпосылки для перехода в перспективе к виртуальной форме обучения. Это значит, что...
-
Понятие процесса архивации файлов - Архивация информации и программы-архиваторы
Одним из наиболее широко распространенных видов сервисных программ являются программы-архиваторы, предназначенные для архивации, упаковки файлов путем...
-
МЕТОДЫ ДОСТУПА К ПЕРЕДАЮЩЕЙ СРЕДЕ В ЛВС - Компьютерные сети и телекоммуникации
Несомненные преимущества обработки информации в сетях ЭВМ оборачиваются немалыми сложностями при организации их защиты. Отметим следующие основные...
-
Геймификация Когда рестораны принимают решения встраивать инновационные услуги в свой бизнес для привлечения аудитории, следует учитывать не только...
-
Наиболее распространенная форма - ЭВМ. Раньше чаще использовались вычислительные центры (ВЦ). Вычислительный центр - организуется и специализируется на...
-
Концентраторы вместе с сетевыми адаптерами, а также кабельной системой представляют тот минимум оборудования, с помощью которого можно создать локальную...
Базовые понятия информации - Компьютерные и сетевые технологии