Интерфейс программы, Пример работы алгоритма и проверка функционального критерия - Разработка программного обеспечения для реализации и тестирования алгоритма нахождения частых множеств в транзакционных данных вертикального формата
Для запуска кластеризации пользователю нужно ввести 4 параметра:
А) Название ODBC драйвера с созданным подключением. Как создать
Такое подключение, говорится в приложении 1.
Б) Название базы.
В) Коэффициент минимальной поддержки в процентах.
Г) Путь к конечной базе в виде текстового файла с расширением. txt (например, с:klaster. txt).
При нажатии на кнопку "Кластеризовать", при корректно заполненных полях, описанных выше, результат кластеризации будет записан в текстовый файл.
В выходном файле (Рисунок 20) имеется 3 столбца:
- - Номер транзакции, а также предметы в данной транзакции - Номер кластера, к которому принадлежит данная транзакции - "Большие предметы" принадлежащие данному кластеру
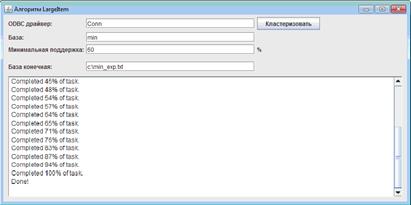
Рис.19 Приложение LargeItem
Рис.20 Выходной файл приложения
Пример работы алгоритма и проверка функционального критерия
Для начала проверим правильность расчета штрафа(costC) за неправильную кластеризацию. При начальной стадии кластеризации возникает вопрос, как формируются кластеры, будет ли вторая транзакция присоединена к первой, образовав кластер из 2 транзакция, или образуется 2 кластера.
Рассмотрим несколько возможных случаев:
1)Имеется 2 транзакции по 5 предметов. Общих транзакций нет.
Если поместить их в разные кластеры, то получим 2 кластера, в каждом из которых все предметы большие, независимо от поддержки. Таким образом сумма больших предметов по кластерам равна 10.
2) Имеется 2 транзакции по 5 предметов. Один предмет общий.
Если не объединять их в один кластер, то получим 2 кластера с суммой больших предметов 10, но один предмет общий и малых нет. Получим штраф 0+10-1=9.
При объединении все предметы, кроме одного становятся малыми, т. е штраф за малые 8. Больших предметов 1, но т. к в кластере он повторен, то и число повторов необходимо вычесть. Получается, что общий штраф не меняется и составит 8.
Как видно - объединение транзакций выгодно.
3)Тот же случай, что и в пункте 2, но общих предметов в транзакциях два.
Из расчета получаем, что при образовании 2 кластеров - общий штраф 8 (10-2=8).
При объединении все предметы, кроме двух в каждой транзакции становятся малыми, т. е штраф за малые предметы - 16. Больших предметов 2, при этом каждый повторяется дважды. Т. о общий штраф получается 16.
Это еще одно подтверждение выгодности объединения транзакций с общими предметами в один кластер.
Проверим выгодность добавления транзакций с общими предметами в кластер.
1) Допустим, имеется кластер, содержащий две транзакции по 10 предметов с 2 общими предметами. Добавляем транзакцию с 10 элементами, в которой нет общих с кластером предметов.
Если образовать 2 кластера, то число больших предметов в первом кластере не изменится и так и будет равно 2. В новом кластере число больших предметов станет 10. Т. о число малых предметов в первом кластере - 16, а общий штраф будет равен - 28.
При добавлении транзакции в существующий кластер количество малых предметов увеличится на 10 и станет 26 (16+10=26).Общий штраф будет равен 28 (26+2=28).
Т. о в данном случае объединение не дает выгоды.
2) Проверим аналогичный случай, но в добавляемой транзакции один предмет является общим с кластером.
Если не объединять транзакцию и существующий кластер в новый кластер, то число больших предметов будет равно 3+10-1 (поскольку 1 предмет является общим). Малых предметов в первом кластере 16. Общий штраф составляет 28 (3+10-1+16=28).
При объединении транзакции и кластера в новый кластер общее число малых предметов составит 15+9=24. Число больших предметов 3, но т. к один является общим, при конечном расчета штрафа будем отнимать единицу.
Общий штраф в данном случае будет равен 24+3-1=26.
Видно, что объединение дает выгоду.
Из всего вышеперечисленного можно сделать простой вывод - наличие общих предметов в транзакциях стимулирует их объединение в один кластер.
Теперь рассмотрим принцип работы алгоритма на тестовом примере.
Основными этапами работы алгоритма является:
- - Первичный проход по базе транзакций и их объединение в кластеры. - Вторичный проход по базе кластеров и расчет возможного улучшения кластеризации.
Разберем эти этапы более подробно.
Первичный проход по базе транзакций и их объединение в кластеры
Предположим, что на начальном этапе имеется гипотетическая база, состоящая из девяти транзакций. Обозначим их цифрами от 1 до 9.
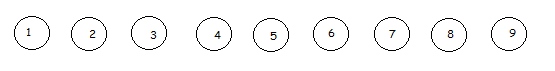
Рис. 21 Транзакции 1-9
Будем поочередно брать каждую транзакций и сравнивать со следующими, пока не дойдем до момента, когда в двух рассматриваемых транзакциях будем иметь один или несколько одинаковых элементов.
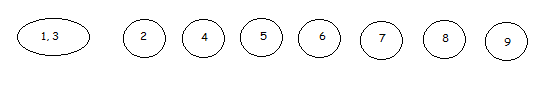
Рис. 22 Транзакции 2, 4-9 и новообразованный кластер (1,3)
Данная пара транзакций объединяется в кластер и для нее будет составлено бинарное дерево, таблица учета предметов, а также данные о количестве транзакций в новообразованном кластере будут добавлены в специальную таблицу (для каждого нового кластера добавляется новая строка таблицы). Ниже приведен произвольный пример структуры такой таблицы.
|
Номер кластера |
Количество транзакций |
|
1 |
3 |
|
2 |
4 |
|
3 |
1 |
|
4 |
0 |
|
5 |
2 |
Как мы видим выше, в процессе выполнения программы, может возникнуть случай, когда количество транзакций в кластере становится равным 0 или 1 (случаи, когда так происходит будут описаны ниже). В таких случаях необходимо удалить данные строки из таблицы, и провести перенумерацию оставшихся кластеров (Рисунок 24).
|
Номер кластера |
Количество транзакций |
|
1 |
3 |
|
2 |
4 |
|
3 |
2 |
Смысл существования данной таблицы состоит в следующем. Т. к пользователь имеет возможность вводить "минимальную поддержку", то необходимо рассчитывать ее для каждого кластера. Минимальная поддержка необходима для разделения элементов кластера на большие и малые предметы и рассчитывается она исходя из количества транзакций в кластере. Именно произведение минимальной поддержки и количества транзакций в кластере и является делителем бинарного дерева на левую и правую ветвь.
Рассмотрим механизм построения бинарного дерева для новообразованного кластера.
Бинарное дерево строится на основе таблицы учета предметов и делителя бинарного дерева, расчет которого описан выше.
Таблица учета предметов в кластере состоит из двух столбцов. В левом находится имя предмета, а в правом число раз, сколько данный предмет содержится в данном кластере.
Листьями в бинарном дереве являются списки элементов транзакций, для которых количество нахождения раз в кластере равно.
Например, имеем кластер, состоящий из двух транзакций ([a, b, c, d, e] , [c, d, e, f]). Также имеем минимальную поддержку 70%, введенную пользователем.
Предмет считается большим, если существует в 2х транзакциях (0,7*2 = 1,4 округляем в большую сторону).
Таблица учета предметов будет выглядеть таким образом:
|
A |
1 |
|
B |
1 |
|
C |
2 |
|
D |
2 |
|
E |
2 |
|
F |
1 |
На основе данной таблицы строится бинарное дерево (Рисунок 25).

Рис. 25
Расчет штрафа за неправильную кластеризацию происходит на основе данных таблицы и дерева. Так, для данного кластера штраф будет равен 3.
При прохождении первичной кластеризации может возникнуть случай, когда одна транзакция имеет общие предметы с несколькими другими. Например, транзакция 1 будет иметь общие предметы как с транзакцией 3, так и с транзакцией 7. В таком случае происходит построение двух предварительных кластеров и сравнение их штрафов за неправильную кластеризацию. Соответственно, более удачным кластером будет являться тот кластер, у которого данный штраф будет ниже. Тогда, худший кластер удаляется, т. е удаляется дерево для этого кластера, таблица предмета учета предметов для данного кластера, а также запись о нем в таблице учета количества транзакций в кластере. В случае, если транзакция не имеет общих предметов ни с одной из существующих транзакций, то из нее образуется кластер, содержащий только эту транзакцию. Что произойдет с этими кластерами будет описано позднее.
Вторичный проход по базе кластеров и расчет возможного улучшения кластеризации
После завершения первичной кластеризации необходимо произвести вторичный проход и возможную вторичную кластеризацию. Для этого будем пытаться объединять кластеры в более крупные, аналогично с тем, как мы это делали с транзакциями.
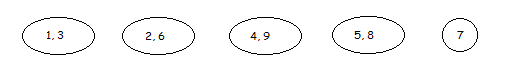
Рис. 26 Кластеры до вторичной кластеризации
Как это делалось с транзакциями, берем кластер и ищем, существует ли другой кластер с хотя бы одним общим предметом. Если таких кластеров не существует, то переходим к следующему и производим ту же операцию. В случае если в ходе повторной кластеризации обнаруживается, что кластер, состоящий из одной транзакции не имеет возможности объединиться с другим кластером (т. е не имеет ни с одним кластером общих предметов), то такой кластер удаляется, т. к является одиночным.
Так же, как и на предыдущем шаге, необходимо рассчитывать штраф за неправильную кластеризацию, чтобы на его основе разрешить спорные моменты при образовании новых кластеров.
Рассмотрим пример образования нового кластера на основе двух уже существующих.
Например, попытаемся объединить ранее рассмотренный кластер ([a, b, c, d, e] , [c, d, e, f]), состоящий из двух транзакций и новый кластер ([c, d, l, z], [y, l, z]), также состоящий из двух транзакций. Для нового кластера таблица учета предметов будет иметь следующий вид:
|
A |
1 |
|
B |
1 |
|
C |
3 |
|
D |
3 |
|
E |
2 |
|
F |
1 |
|
L |
2 |
|
Y |
1 |
|
Z |
1 |
Также, в связи с добавлением новых элементов, будет перестроено бинарное дерево (Рисунок 27).

Рис. 27
В данном случае частота встречаемости больших предметов будет не менее 3х (0,7*4 = 2,8 округляем в большую сторону). Рассчитаем штраф для новообразованного кластера, а также для двух кластеров отдельно.
В новом кластере количество "больших предметов" 2, остальные 7 являются "малыми". Следовательно, по формуле, штраф в данном случае будет равен 7.
Теперь проверим, является ли эффективной кластеризация, т. е посчитаем возможный штраф, если данные кластеры не будут объединяться в один.
Кластер ([a, b, c, d, e] , [c, d, e, f]) имеет 3 "больших" и 3 "малых" предмета, кластер ([c, d, l, z], [y, l, z]) - 2 "больших" и 3 "малых". Исходя из этих значений, получаем штраф равный 11, что еще раз доказывает, что даже один общий предмет стимулирует объединение в общий кластер.
Алгоритм кластеризации заканчивает свою работу в том случае, если больше не существует кластеров, имеющих общие предметы, т. е когда эффективная кластеризация больше невозможна.
Настройка JavaДля программ, написанных на языке Java, по умолчанию выделяется 128Mb оперативной памяти. Для обработки некоторых наборов данных этого количества памяти недостаточно. Что бы увеличить количество выделяемой памяти при запуске из командной строки Windows надо добавить параметр - Xmx256m, где 256 - это количество выделяемой памяти. Так же можно поставить 512 и 1024 в зависимости от размера набора данных.
Похожие статьи
-
Термин "транзакция" относится к подмножеству предметов из общей совокупности с переменным числом предметов (мощностью подмножества). Транзакциями...
-
Модернизация обобщенного алгоритма кластеризации состоит в использовании вместо обычных бинарных деревьев сбалансированных бинарных деревьев(B+ tree)....
-
Для разработки программного обеспечения использован язык Java. Разработка проводилась в среде Eclipse Ganymede 3.2. В качестве СУБД для тестирования...
-
Коллекция транзакций хранится в файле на диске. Алгоритм читает каждую транзакцию t последовательно и присоединяет t к существующему кластеру, или...
-
Подход, основанный на "больших" предметах и функциональный критерий кластеризации Поддержка предмета в кластере Ci есть относительное число транзакций в...
-
Допустим, что MinSupi = и * |Ci|. Поддержка данного предмета в Ci характеризует число транзакций в этом кластере, которые содержат этот предмет. Поэтому...
-
Алгоритм для обновления дан на рис.6. Для каждого предмета е в t отыскивается Hashi. Если е найдено хэше кластера, то увеличиваем на 1 его sup в Btreei....
-
Понятие Data Mining Средства Data Mining включают в себя очень широкий класс различных технологий и инструментов. Средства Data Mining на рынке...
-
Рис. 9 Пример B+ дерева, связывающего ключи 1-7 с данными d1-d7. Связи (выделены красным) позволяют быстро обходить дерево в порядке возрастания ключей....
-
В наше время все большее количество компаний, стремясь к повышению эффективности и прибыльности бизнеса пользуются цифровыми (автоматизированными)...
-
Рис. 7 Пример двоичного дерева поиска Двоичное дерево поиска (binary search tree, BST) -- это двоичное дерево, для которого выполняются следующие...
-
Вычислительная сложность алгоритмов Алгоритм кластеризации Вычислительная сложность Иерархический O(n2) K-средних O(nkl), где k - число кластеров, l -...
-
Кластеризация (или кластерный анализ) -- это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться...
-
Базовый интерфейс двоичного дерева поиска состоит из трех операций: - FIND(K) -- поиск узла, в котором хранится пара (key, value) с key = K. - INSERT(K,...
-
При работе над проектом разрабатывались два основных компонента системы: база данных (далее - БД) и интерфейс клиентского приложения. Затем необходимо...
-
Встроенный оптимизатор запросов в Teradata может значительно ускорить запрос по сравнению тем, как если бы команды выполнялись ровно так, как подает...
-
Основные термины теории баз данных - БД (База данных) - совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы...
-
Подход NoSQL - Технологии больших данных: анализ и выбор решения для реализации проекта
Понятие NoSQL означает "Не только SQL" или "Не SQL". Термин получил известность, начиная с 2009 год, когда развитие интернет-технологий и социальных...
-
Описание исходных данных На текущий момент (в силу большой загрузки IT-отдела) не реализован доступ к серверу с ХД, маркетинговые данные выгружаются в...
-
Базы данных (БД) составляют в настоящее время основу компьютерного обеспечения информационных процессов, входящих практически во все сферы человеческой...
-
Полное наименование разрабатываемой системы - корпоративная информационная система "Бюджетное планирование и отчетность" группы компаний, занимающейся...
-
Выбор программ и алгоритмы реализации базы данных - База данных "Кинотеатр"
Microsoft Office Access - мощное приложение Windows. При этом производительность СУБД органично сочетаются со всеми удобствами и преимуществами Windows....
-
Антивирусные программы, их классификация и принципы работы - Программное обеспечение компьютера
Самыми популярными и эффективными антивирусными программами являются Антивирусные сканеры (другие названия: доктора, фаги, полифаги). Следом за ними по...
-
Для написания АИС использовались следующие языки программирования, программные средства и библиотеки: - Язык программирования PHP 5.4; -...
-
Для того чтобы оценить экономическую выгоду от внедрения АИС необходимо вычислить трудозатраты компании направленные непосредственно на реализацию...
-
Обоснование выбора средств разработки проекта Для реализации корпоративной информационной системы "Бюджетное планирование и отчетность" в исследуемой...
-
Предлагаемая библиотека хранит все данные в отдельных таблицах, таким образом он не обязан использовать ту же СУБД, что и основное приложение. В качестве...
-
Выбор средств реализации информационной системы Названные в параграфе 1.4. настоящей работы задачи могут быть решены тремя типами средств автоматизации:...
-
Функциональные требования: - Поиск и обработка информации в текстовых файлах при появлении файлов в соответствующей директории по запросу администратора...
-
Постановка задачи на разработку программного обеспечения Для того чтобы предлагаемая схема была интегрирована в САПР, который не имеет функции интеграции...
-
В процессе разработки программного средства было создано 12 таблиц. Для их создания использовалось графическое средство SqlYong и кодирование на языке...
-
Общее описание программного обеспечения, реализующего разработанный алгоритм Основной идеей дипломного проекта, является реализация алгоритма...
-
Разработка структур БД Информационная структура БД (Рисунок 2.1) Рисунок 2.1 - Структура БД. Разработка интерфейса для работы с БД В проект в первую...
-
В то время как цель проекта заключалась в оценке эффективности автоматизации тестирования функционала ядра, работа стала своего рода подведением итогов...
-
Для того, чтобы вынести решение об оправданности или неоправданности внедрения автоматизированного тестирования вместо ручного, необходимо...
-
Цель Работы - изучить основные способы работы с пользовательским типом данных "класс", его объектами, методами и способы доступа к ним. - Теоретические...
-
Поскольку клиентская часть представляет собой приложение на базе операционной системы Android, то для ее разработки был выбран рекомендуемый...
-
В данном разделе была разработана функциональная схема работы программного комплекса, которая в общем виде описывает состав комплекса, характер и виды...
-
В течении года от команды разработчиков пришло 6 пакетов, содержащих изменения в ядре программы. Для каждого пакета составлялось в среднем от 1-ого до...
-
Модели транзакций - Банки и базы данных. Системы управления базами данных
Под транзакциями понимаются действия, производимые над базой данных и переводящие ее из одного согласованного состояния в другое согласованное состояние....
Интерфейс программы, Пример работы алгоритма и проверка функционального критерия - Разработка программного обеспечения для реализации и тестирования алгоритма нахождения частых множеств в транзакционных данных вертикального формата