Основные операции в двоичном дереве поиска - Разработка программного обеспечения для реализации и тестирования алгоритма нахождения частых множеств в транзакционных данных вертикального формата
Базовый интерфейс двоичного дерева поиска состоит из трех операций:
- - FIND(K) -- поиск узла, в котором хранится пара (key, value) с key = K. - INSERT(K, V) -- добавление в дерево пары (key, value) = (K, V). - REMOVE(K) -- удаление узла, в котором хранится пара (key, value) с key = K.
По сути, двоичное дерево поиска -- это структура данных, способная хранить таблицу пар (key, value) и поддерживающая три операции: FIND, INSERT, REMOVE.
Кроме того, интерфейс двоичного дерева включает еще три дополнительных операции обхода узлов дерева: INFIX_TRAVERSE, PREFIX_TRAVERSE и POSTFIX_TRAVERSE. Первая из них позволяет обойти узлы дерева в порядке неубывания ключей.
Поиск элемента (FIND)
Дано: дерево Т и ключ K.
Задача: проверить, есть ли узел с ключом K в дереве Т, и если да, то вернуть ссылку на этот узел.
Алгоритм:
- (1)Если дерево пусто, сообщить, что узел не найден, и остановиться. (2)Иначе сравнить K со значением ключа корневого узла X.
(3)Если K=X, выдать ссылку на этот узел и остановиться.
(4)Если K>X, рекурсивно искать ключ K в правом поддереве Т.
(5)Если K<X, рекурсивно искать ключ K в левом поддереве Т.
Добавление элемента (INSERT)
Дано: дерево Т и пара (K, V).
Задача: добавить пару (K, V) в дерево Т.
Алгоритм:
- (1)Если дерево пусто, заменить его на дерево с одним корневым узлом ((K, V), null, null) и остановиться. (2)Иначе сравнить K с ключом корневого узла X.
(3)Если K>=X, рекурсивно добавить (K, V) в правое поддерево Т.
(4)Если K<X, рекурсивно добавить (K, V) в левое поддерево Т.
Удаление узла (REMOVE)
Дано: дерево Т с корнем n и ключом K.
Задача: удалить из дерева Т узел с ключом K (если такой есть).
Алгоритм:
- (1)Если дерево T пусто, остановиться; (2)Иначе сравнить K с ключом X корневого узла n.
(3)Если K>X, рекурсивно удалить K из правого поддерева Т;
(4)Если K<X, рекурсивно удалить K из левого поддерева Т;
(5)Если K=X, то необходимо рассмотреть три случая.
(6)Если обоих детей нет, то удаляем текущий узел и обнуляем ссылку на него у родительского узла;
(7)Если одного из детей нет, то значения полей ребенка m ставим вместо соответствующих значений корневого узла, затирая его старые значения, и освобождаем память, занимаемую узлом m;
(8)Если оба ребенка присутствуют, то
(9)найдем узел m, являющийся самым левым узлом правого поддерева с корневым узлом Right(n);
(10)скопируем данные (кроме ссылок на дочерние элементы) из m в n;
(11)рекурсивно удалим узел m.
Обход дерева (TRAVERSE)
Есть три операции обхода узлов дерева, отличающиеся порядком обхода узлов.
Первая операция -- INFIX_TRAVERSE -- позволяет обойти все узлы дерева в порядке возрастания ключей и применить к каждому узлу заданную пользователем функцию обратного вызова f. Эта функция обычно работает только с парой (K, V), хранящейся в узле. Операция INFIX_TRAVERSE реализуется рекурсивным образом: сначала она запускает себя для левого поддерева, потом запускает данную функцию для корня, потом запускает себя для правого поддерева.
- - INFIX_TRAVERSE ( f ) -- обойти все дерево, следуя порядку (левое поддерево, вершина, правое поддерево). - PREFIX_TRAVERSE ( f ) -- обойти все дерево, следуя порядку (вершина, левое поддерево, правое поддерево). - POSTFIX_TRAVERSE ( f ) -- обойти все дерево, следуя порядку (левое поддерево, правое поддерево, вершина).
INFIX_TRAVERSE:
Дано: дерево Т и функция f
Задача: применить f ко всем узлам дерева Т в порядке возрастания ключей
Алгоритм:
- (1)Если дерево пусто, остановиться. (2)Иначе
(3)Рекурсивно обойти левое поддерево Т.
(4)Применить функцию f к корневому узлу.
(5)Рекурсивно обойти правое поддерево Т.
В простейшем случае, функция f может выводить значение пары (K, V). При использовании операции INFIX_TRAVERSE будут выведены все пары в порядке возрастания ключей. Если же использовать PREFIX_TRAVERSE, то пары будут выведены в порядке, соответствующим описанию дерева, приведенного в начале статьи.
Разбиение дерева по ключу
Операция "разбиение дерева по ключу" позволяет разбить одно дерево поиска на два: с ключами <K0 и ?K0.
Балансировка дерева
Всегда желательно, чтобы все пути в дереве от корня до листьев имели примерно одинаковую длину, т. е. чтобы глубина и левого, и правого поддеревьев была примерно одинакова в любом узле. В противном случае теряется производительность.
В вырожденном случае может оказаться, что все левое дерево пусто на каждом уровне, есть только правые деревья, и в таком случае дерево вырождается в список (идущий вправо). Поиск (а значит, и удаление и добавление) в таком дереве по скорости равен поиску в списке и намного медленнее поиска в сбалансированном дереве.
Для балансировки дерева применяется операция "поворот дерева". Поворот направо выглядит так:
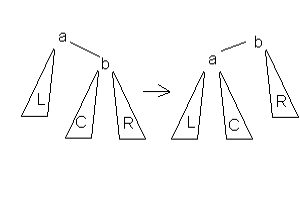
Рис. 8
- - было Left(A) = L, Right(A) = B, Left(B) = C, Right(B) = R - поворот меняет местами A и B, получая Left(A) = L, Right(A) = C, Left(B) = A, Right(B) = R - также меняется в узле Parent(A) ссылка, ранее указывавшая на A, после поворота она указывает на B.
Поворот направо выглядит так же, достаточно заменить в вышеприведенном примере все Left на Right и обратно.
Достаточно очевидно, что поворот не нарушает упорядоченность дерева, и оказывает предсказуемое (+1 или -1) влияние на глубины всех затронутых поддеревьев.
Для принятия решения о том, какие именно повороты нужно совершать после добавления или удаления, используются такие алгоритмы, как "красно-черное дерево" и АВЛ.
Оба они требуют дополнительной информации в узлах - 1 бит у красно-черного или знаковое число у АВЛ.
Красно-черное дерево требует <= 2 поворотов после добавления и <= 3 после удаления, но при этом худший дисбаланс может оказаться до 2 раз (самый длинный путь в 2 раза длиннее самого короткого).
АВЛ-дерево требует <= 2 поворотов после добавления и до глубины дерева после удаления, но при этом идеально сбалансировано (дисбаланс не более, чем на 1).
Похожие статьи
-
Рис. 7 Пример двоичного дерева поиска Двоичное дерево поиска (binary search tree, BST) -- это двоичное дерево, для которого выполняются следующие...
-
Допустим, что MinSupi = и * |Ci|. Поддержка данного предмета в Ci характеризует число транзакций в этом кластере, которые содержат этот предмет. Поэтому...
-
В наше время все большее количество компаний, стремясь к повышению эффективности и прибыльности бизнеса пользуются цифровыми (автоматизированными)...
-
ДВОИЧНЫЙ ПОИСК, АВЛ-Дерево - Структуры и алгоритмы обработки данных
Алгоритм двоичного поиска в упорядоченном массиве сводится к следующему. Берем средний элемент отсортированного массива и сравниваем с ключом X. Возможны...
-
Понятие Data Mining Средства Data Mining включают в себя очень широкий класс различных технологий и инструментов. Средства Data Mining на рынке...
-
Подход, основанный на "больших" предметах и функциональный критерий кластеризации Поддержка предмета в кластере Ci есть относительное число транзакций в...
-
Термин "транзакция" относится к подмножеству предметов из общей совокупности с переменным числом предметов (мощностью подмножества). Транзакциями...
-
Вычислительная сложность алгоритмов Алгоритм кластеризации Вычислительная сложность Иерархический O(n2) K-средних O(nkl), где k - число кластеров, l -...
-
Алгоритм для обновления дан на рис.6. Для каждого предмета е в t отыскивается Hashi. Если е найдено хэше кластера, то увеличиваем на 1 его sup в Btreei....
-
Коллекция транзакций хранится в файле на диске. Алгоритм читает каждую транзакцию t последовательно и присоединяет t к существующему кластеру, или...
-
Кластеризация (или кластерный анализ) -- это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться...
-
Объект ориентированный класс программирование Цель Работы - изучить методику создания одномерных динамических символьных массивов при помощи...
-
ОСОБЕННОСТИ РЕАЛИЗАЦИИ АЛГОРИТМОВ - Структуры и алгоритмы обработки данных
В ходе выполнения курсовой работы, помимо основных алгоритмов, потребовалось реализовать также несколько вспомогательных, необходимых для корректной...
-
1. НА 7 ПК ИСПОЛЬЗУЕТСЯ microsoft Windows xp sp2. 2. на 1 используется Altlinux 5 3. Программы офисного назначения: A) Microsoft Office Excel 2003 B)...
-
Тестируемый программный продукт является высокопроизводительным приложением, которое предоставляет возможность создания и настройки сетей беспроводного...
-
Выбор программного обеспечения для внедрения KPI целиком и полностью упирается в потребности конкретной компании. Благодаря все большей и большей...
-
Поскольку клиентская часть представляет собой приложение на базе операционной системы Android, то для ее разработки был выбран рекомендуемый...
-
2.1 Описание структуры базы данных Реляционная схема базы данных для ЦЗН представлена следующими таблицами: "ПО" - содержит список единиц программного...
-
Для того, чтобы строить диаграммы в соответствии с рисунком 2.7, необходимо реализовать алгоритм соединения двух объектов линией. Для отображения линии...
-
Данный процесс отражает регламент работ по разработке программных продуктов в рамках учебных проектов, который будет использован при создании исполяемой...
-
Программная модель данных, получившая название "MapReduce", была создана несколько лет назад в компании Google, и там же была осуществлена первая...
-
В программе присутствуют следующие основные модули: - PlatformManager - DeviceManager - ScenariosManager - ScenarioEngine - ExportManager - ImportManager...
-
Расчет затрат, связанных с организацией рабочих мест для исполнителей проекта, проводится на основе требований СНИПа (санитарные нормы и правила) и...
-
Автоматизированное тестирование программного обеспечения - это процесс проверки программного обеспечения, который включает в себя такие шаги как запуск,...
-
В то время как цель проекта заключалась в оценке эффективности автоматизации тестирования функционала ядра, работа стала своего рода подведением итогов...
-
Для того, чтобы вынести решение об оправданности или неоправданности внедрения автоматизированного тестирования вместо ручного, необходимо...
-
Компания MERA Networks - является одним из крупнейших мировых поставщиков услуг в сфере информационно-коммуникационных технологий. MERA предлагает...
-
Общее описание программного обеспечения, реализующего разработанный алгоритм Основной идеей дипломного проекта, является реализация алгоритма...
-
При запуске программы с входными параметрами {"-makexls" "filename. xls" "температурная_точка" "отклонение" "элемент"} происходит извлечение результатов...
-
В данной части работы будет рассмотрено моделирование спроектированного ранее бизнес-процесса. Выбор инструмента моделирования бизнес-процессов Сейчас на...
-
Цель Работы - изучить основные способы работы с пользовательским типом данных "класс", его объектами, методами и способы доступа к ним. - Теоретические...
-
Цель Работы - научиться использовать операции динамического выделения и освобождения памяти на примере работы с одномерными и двумерными массивами, а...
-
Выбор средств реализации информационной системы Названные в параграфе 1.4. настоящей работы задачи могут быть решены тремя типами средств автоматизации:...
-
Процесс тестирования, Разработка тест-кейсов - Тестирование программного обеспечения
Тестирование представляет собой процесс проверки того, насколько программное обеспечение соответствует требованиям, заявленным заказчиком. Он...
-
В данной части будет рассмотрена работа пользователей с симулируемой моделью через веб-интерфейс. Для публикации модели необходимо экспортировать ее на...
-
В данной части работы будут рассмотрены основные бизнес-процессы этапа разработки программного обеспечения в рамках учебных проектов в университете. В...
-
Постановка задачи на разработку программного обеспечения Для того чтобы предлагаемая схема была интегрирована в САПР, который не имеет функции интеграции...
-
Помимо этапа разработки ПО, также немаловажным являются этапы накопления и передачи знаний, а также взаимодействия членов проектной команды. На...
-
Необходимо исследовать зависимость влияния различных факторов на параметр, характеризующий производство. В качестве такого параметра было выбрано...
-
Если в результате поиска на схеме по данным из таблицы будет найдено несколько экземпляров оборудования (т. е. с одинаковой маркировкой или...
Основные операции в двоичном дереве поиска - Разработка программного обеспечения для реализации и тестирования алгоритма нахождения частых множеств в транзакционных данных вертикального формата