Оптимизация запросов в Teradata - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Встроенный оптимизатор запросов в Teradata может значительно ускорить запрос по сравнению тем, как если бы команды выполнялись ровно так, как подает пользователь, однако, он не может влиять на работу скриптов в целом.
При написании запроса следует учитывать такие факторы как первичные и вторичные индексы исходных таблиц, первичный индекс итоговой таблицы (если происходит вставка данных), распределение данных по AMP'ам, размер таблиц и условия соединения между ними.
Primary Index (PI) - первичный индекс - механизм доступа к данным в СУБД Teradata, его состав определяет, значения каких полей таблицы будут использованы при распределении данных по AMP'ам либо доступа к ним.
Первичный индекс часто путают с первичным ключом, рассмотрим эти понятия и их основные свойства.
Первичный ключ - логическая концепция. Он однозначно определяет строку в таблице [5]. Каждая таблица может иметь только один первичный ключ, нет ограничения на количество колонок, которое в него входят. Teradata не требуется, чтобы он был указан. В значениях первичного ключа не может встречаться NULL.
Первичный индекс - механизм доступа к данным. Каждая таблица может иметь не более одного первичного индекса (может быть определен NO PRIMARY INDEX - индекса нет). Индексы имеют ограничение на количество используемых колонок - 64. Индекс может быть как уникальным, так и неуникальным, может содержать в том числе NULL-значения.
По значению PI на этапе обработки запроса диспетчером Parsing Engine определяется, на каком AMP лежат нужные данные, либо куда надо положить новые. Делается с помощью собственного алгоритма хэширования, разработанного компанией Teradata, работающего на разных типах данных - числа, строки, даты...
AMP определяется следующим образом [6]:
- - вычисляем 32-битный хэш от значений PI данной строки (в PI может быть как одна колонка, так и несколько) - согласно значениям первых 16 или 20 бит (в зависимости от того, сколько бит определяют ячейку) получаем ячейку в хэш-карте (bucket) - получаем из найденной ячейки значение, соответствующее номеру AMP'а.
На схеме (рис. 3) это выглядит так:

Рис. 3 Определение AMP по значению PI
Пример хэш-карты для данного случая показан в таблице 3:
Таблица 3 Пример hash-карты для определения AMP
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F | |
|
CE86 |
16 |
3 |
8 |
15 |
9 |
7 |
14 |
15 |
2 |
8 |
12 |
1 |
4 |
6 |
11 |
14 |
|
CE87 |
9 |
16 |
6 |
4 |
3 |
2 |
8 |
13 |
9 |
5 |
10 |
7 |
4 |
13 |
5 |
1 |
|
CE88 |
12 |
6 |
10 |
11 |
2 |
10 |
15 |
3 |
14 |
1 |
11 |
7 |
16 |
5 |
13 |
7 |
Хэш-карты формируются стандартными алгоритмами Teradata. Для системы с 16 AMP будет одна, для систем с 64 - другая. Для второй же системы с 64 AMP будет точно такая же, если ячейка карты определяется таким же количеством бит.
Оставшиеся биты в хэше строки будут использованы для нахождения ее на AMP'е.
Такое устройство хэш-карты удобно тем, что при добавлении новых узлов в систему не будет требоваться изменение алгоритмов хэширования, просто будет скорректирована карта и перераспределены затронутые данные.
При выборе первичного индекса надо учитывать 2 основных момента: насколько равномерно с помощью него будут разложены данные по AMP'ам и будут ли использоваться все его поля для получения информации.
С распределением данных по AMP'ам тесно связано понятие "перекошенности" таблиц - skew. Эта величина представляет собой процентный показатель и вычисляется по формуле 1, где AverageAMPSize и MaximumAMPSize - соответственно, средний и максимальный объемы данных, распределенных на AMP:
Формула 1 Вычисление процентного показателя skew таблицы
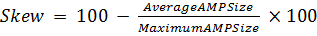
,
В СУБД Teradata каждый AMP содержит часть данных каждой таблицы (при количестве записей в таблице большем, чем количество AMP'ов).
В идеальном случае, когда PI подобран правильно, распределение строк по узлам системы будет равномерным. В такой ситуации при полном просмотре таблицы каждый узел будет выполнять одинаковую часть работы. Степень уникальности первичного индекса тут играет важную роль.
Если первичный индекс не уникален и на какие-то значения приходится во много раз большее количество строк (рис. 4), чем на другие, на соответствующих им AMP'ам закончится место для хранения информации.
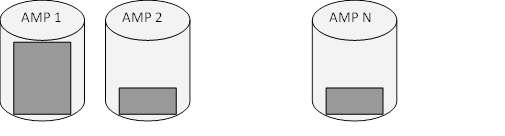
Рис. 4 Неравномерное распределение данных
В данной ситуации AMP 1 заполнен полностью, в то время как остальные - примерно на 30%. Несмотря на то, что свободное место в системе, фактически, еще имеется, из-за его отсутствия на одном AMP при попытке добавить новые данные будет выведена ошибка о недостатке дискового пространства.
Второй момент, который надо учитывать при выборе индекса - доступ к данным. Не всегда уникальное по значению поле будет лучшим кандидатом для PI.
Parsing Engine во время составления команд определяет самый лучший метод доступа к данным - задействовать один AMP, несколько или все.
Если в запросе имеется условие равенства на поля из PI (причем задействованы должны быть именно все поля), то будет выбран самый удобный метод - по индексу, если же такого условия нет или задействованы не все поля, будет необходим полный просмотр таблицы.
Предположим, что у нас есть таблица "Заказы клиента". Помимо прочих полей в нем есть ID заказа и ID клиента. ID заказа - PK, значения уникальны. ID клиента может повторяться, но тоже достаточно уникально. Мы знаем, что заказы нам интересны только в разрезе клиента - самый частый случай использования таблицы будет с фильтром "WHERE CUSTOMER_ID = ... ". В таком случае будет удобнее создать таблицу с первичным индексом "CUSTOMER_ID".
В зависимости от выбора индексов будут меняться и алгоритмы физического соединения таблиц. СУБД Teradata использует 3 основных варианта соединений - product join, hash join и merge join.
Product join (другое название - nested loops join) - алгоритм соединения вложенными циклами. Самый простой, хорошо работает, если обе таблицы маленькие. Он выбирается оптимизатором, когда в условии соединения не используется PI, либо используется, но с условием неравенства.
Hash join - алгоритм соединения таблиц, который строит по меньшей таблице хэш-карту, проходит по большей и по карте выбирает соответствующие строки. Удобен при соединении небольших таблиц на большие.
Merge join - алгоритм соединения, сначала сортирующий данные в таблицах (используется сортировка слиянием), после этого проходится по отсортированным данным и соединяет по совпадающим значениям. Является наименее ресурсоемким алгоритмом соединения, особенно при работе с большими таблицами.
Для объединения таблиц может потребоваться переложить данные одной из них по другому условию. Встроенный оптимизатор при выборе географии соединения оценивает размеры таблиц и может выбрать один из следующих вариантов:
- - Не перекладывать данные - наилучший вариант, в таком случае PI у соединяемых таблиц совпадает, и можно сразу приступать к соединению, т. к. нужные уже лежат на нужных AMP'ах. - Перераспределить данные - такой вариант будет использован, если обе таблицы большие, а PI у них разный. Данные из меньшей таблицы будут скопированы и переложены под другой индекс, а после того, как отработает соединение, вычищены из временного пространства. - Дублировать данные - этот вариант будет использован, если одна из таблиц существенно меньше, чем другая, причем в соединении не используется PI большей. Такой способ обычно применяется для обогащения информации большей таблицы данными из сравнительно маленьких справочных витрин.
Похожие статьи
-
Оптимизатор - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Задача оптимизатора в рамках данной дипломной работы - исправлять части SQL-кода, которые могут приводить к дополнительным тратам памяти и ресурсов. На...
-
СУБД Teradata имеет встроенный оптимизатор, который отвечает за выбор: интерфейс teradata парсер ? Способа доступа к данным - будет ли обращение к...
-
Заключение - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Оптимизация потребления ресурсов (хранение данных, ресурсы CPU) - важная задача при реализации ETL-процессов. Чем больше ресурсов системы будет свободно,...
-
Парсер - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
В приложении можно выделить 2 основных функциональных блока: парсер и оптимизатор. Данная глава посвящена первому из них. Задача парсера - разобрать...
-
Обзор аналогов - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Создание оптимизирующего препроцессора ограничивается несколькими условиями: 1. Частично написание и тестирование программы проводится на рабочих местах,...
-
Архитектура Teradata Teradata Database - система массовой параллельной обработки данных. Поставляется она в виде комплекса оборудования и программного...
-
Введение - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Актуальность. В настоящее время трудно найти фирму, которая не использовала бы базы данных в той или иной форме - учет сотрудников, клиентов, продаж....
-
Запросы на выборку - Банки и базы данных. Системы управления базами данных
Запросы используются для получения пользователем информации, содержащейся в БД, в удобном для него виде. Результат запроса отображается для пользователя...
-
Источники - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
1. William H. Inmon. Building the data warehouse. - 4Th edition. - Wiley Publishing, Inc., 2005. - С. 546. 2. Lawrence Corr, Jim Stagnitto, Agile Data...
-
Выбор средств реализации информационной системы Названные в параграфе 1.4. настоящей работы задачи могут быть решены тремя типами средств автоматизации:...
-
Основные термины теории баз данных - БД (База данных) - совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы...
-
Основным достоинством интерфейса Centronics является его стандартность - он есть на каждом компьютере и на всех компьютерах работает одинакового (правда...
-
Для написания АИС использовались следующие языки программирования, программные средства и библиотеки: - Язык программирования PHP 5.4; -...
-
При работе над проектом разрабатывались два основных компонента системы: база данных (далее - БД) и интерфейс клиентского приложения. Затем необходимо...
-
Оптимизация запросов к базе данных - Теория экономических информационных систем
Возможности оптимизатора запросов в значительной мере определяют способности сервера эффективно обрабатывать SQL-операторы, затрагивающие несколько...
-
Самым традиционным и широко известным из структурированных типов данных является массив (иначе называемый регулярным типом) - однородная упорядоченная...
-
2.1 Среды разработки для построения программных агентов Инструментальные средства разработки программных агентов формируют среду, которая оптимизирована...
-
Общие сведения Данное программное средство должно помочь в расчете коммунальных услуг, упростить ввод данных о квартиросъемщике и ЖЭС, осуществлять...
-
Для разработки программного продукта нами была выбрана СУБД Microsoft Access 2010, которая позволяет выполнять простейшие операции с данными: Ѕ добавить...
-
Учебный процесс в ННГАСУ сопровождается значительной информационной базой, развитием компьютерного парка и внедрением в образовательный процесс...
-
Microsoft Access База данных разработана в среде Microsoft Access. Microsoft Access - реляционная СУБД корпорации Microsoft. Имеет широкий спектр...
-
Функциональные требования: - Поиск и обработка информации в текстовых файлах при появлении файлов в соответствующей директории по запросу администратора...
-
Основные компоненты и структура приложения Прежде чем приступить к установке и настройке среды программирования, построению технического задания и...
-
Разработка интерфейса, Разработка запросов - Высокоуровневые методы информатики и программирования
Программа, будет начинать работу с вывода главной формы, на которой будет располагаться самое главное меню, т. е. другими словами "панель навигации"....
-
Постановка задачи на разработку программного обеспечения Для того чтобы предлагаемая схема была интегрирована в САПР, который не имеет функции интеграции...
-
После обмена данными с АЦП происходит преобразование считанных данных в одно целое число, характеризующее уровень сигнала на входе АЦП. Т. к. АЦП имеет...
-
Общее описание программного обеспечения, реализующего разработанный алгоритм Основной идеей дипломного проекта, является реализация алгоритма...
-
Проектирование и разработка сайта Средства разработки Язык гипертекстовой разметки HTML В Интернете сосредотачивается и передается достаточно большое...
-
В данной выпускной квалификационной работе разработан прототип умного почтового ящика, удаленного сетевого устройства для контроля почтовой...
-
Базы данных (БД) составляют в настоящее время основу компьютерного обеспечения информационных процессов, входящих практически во все сферы человеческой...
-
В этом разделе описаны запросы, выполняемых всеми компонентами, а также типы данных, используемые при описании запросов. Стандарт типов данных При...
-
Вирусы и антивирусное программное обеспечение
Реферативная часть Что такое вирус? Один из известных "докторов" Д. Н Лозинский дал определение вируса на примере клерка. Представим себе аккуратного...
-
Обоснование выбранного метода При дизайне системы согласно требованиям или при оптимизации существующей необходимо ввести модель, позволяющую не только...
-
Кодированием называется представление символов одного алфавита средствами другого алфавита. Алфавит содержащий два символа называется двоичным (часто их...
-
АНТИВИРУСНЫЕ СРЕДСТВА ЗАЩИТЫ - Разработка модели программно-аппаратной защиты на предприятии
Массовое распространение вредоносного ПО вызвало необходимость разработки и использования антивирусов. Антивирусные средства применяются для решения...
-
Для работы с базами данных созданы системы управлением базами данных. Существует довольно большое количество СУБД, особенно предназначенных для работы с...
-
Защита информации на бумажных (машинных) носителях и содержащейся в отходах и браке научной и производственной деятельности организации предусматривает...
-
Основой системы будут два независимых модуля. Первый будет разрабатываться для формирования контента системы, этот модуль будем называть Редактор. Второй...
-
Обоснование выбора средств для разработки В качестве платформы была взята платформа NET, потому что платформа NET на текущий момент самая передовая и...
-
3.1 Описание программного модуля Jadex - это агент, ориентированный на собственный механизм принятия решений, взаимодействуя с XML и Java файлами,...
Оптимизация запросов в Teradata - Разработка программного средства, позволяющего оптимизировать SQL-скрипты