Deductor Studio 5.1 - Разработка программного обеспечения для реализации и тестирования алгоритма нахождения частых множеств в транзакционных данных вертикального формата
Так как разработанное ранее приложение LargeItem выводит в выходном файле "большие предметы", то используя специальный аналитический инструмент возможно проверить совпадение "больших предметов", выведенных программой, и частых множеств найденных в той же самой БД.
Одним из способов проверки корректности работы приложения LargeItem может являтся сравнение ее результатов с результатом работы аналитической платформы Deductor Studio 5.1. Платформа разработана рязанской фирмой "BaseGroup Labs".
Deductor Studio - предоставляет аналитикам инструментальные средства, необходимые для решения самых разнообразных аналитических задач. В области Data Mining, например:
- - Прогнозирование - выполняет прогнозирование временного ряда. - Автокорреляция - выполняет автокорреляционный анализ данных. - Линейная регрессия - строит модель данных в виде набора коэффициентов линейного преобразования. - Нейросеть - выполняет обработку данных с помощью многослойной нейронной сети. - Дерево решений - выполняет обработку данных с помощью деревьев решений. - Самоорганизующиеся карты - выполняет кластеризацию данных. - Ассоциативные правила - обнаружение зависимостей между связанными событиями. Поиск частых множеств. - Пользовательская модель - задание модели вручную по формулам.
Вышеперечисленное является малой частью возможностей платформы.
В данной работе нас интересует возможность Deductora находить частые множества в процессе вывода ассоциативных правил. При поиске частых множеств Deductor, так же как и мое приложение, использующее алгоритм Diffsets, считывает всю базу данных в оперативную память. Далее Deductor ищет с помощью одного из горизонтальных алгоритмов частые множества.
К сожалению, Deductor не работает при поиске частых множеств в базах объемах больше 12000 транзакций. При поиске выдается ошибка, и обработка данных прекращается. Возможно, эта ошибка конкретной версии программы, скачанной с официального сайта. Или данная лицензия имеет ограничение на объем данных.
Тем не менее, мы будем использовать Deductor для тестирования небольших баз.
Далее рассмотрим процесс поиска частых множеств с помощью Deductora:
Запускаем Deductor Studio 4.4. Вначале мы настраиваем источник данных, то есть средство, с помощью которого Deductor будет подключаться к базе данных транзакций.
Для этого необходимо перейти в вид "Источники данных". Вызываем меню "Вид" и выбираем в нем пункт "Источники данных". В правом окошке открывшегося вида находится дерево источников данных по типам.
Типов источников три:
- 1) Базы данных 2) Хранилище данных 3) Бизнес-приложение
Для импорта базы данных транзакций нам подходит первый тип. Щелкаем правой кнопкой мыши по дереву. В открывшемся списке выбираем пункт "Добавить источник данных". В данном пункте выбираем подпункт "Добавить базу данных" (рисунок 29).
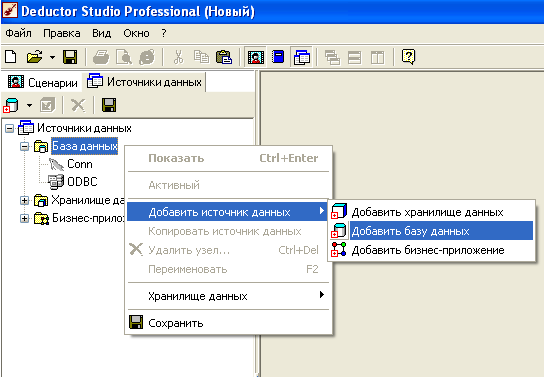
Рис. 29 Создание источника данных
Далее вам предлагается список баз данных, которых можно подключить. Для подключения MySql нам подходят два варианта из списка: "MySql" и "ODBC".Если вы выберете "MySql", то соединение будет создано для одной конкретной базы. И для каждой базы придется создавать свое подключение, что может быть неудобно.
Если выбрать вариант "ODBC", то соединение будет создано для сервера, а конкретную базу данных мы будем выбирать при непосредственном импорте данных. Последний вариант мне кажется более удобным.
После выбора появится окно настроек подключения рисунок 30. Для тестирования нам понадобится минимум настроек:
- - Имя - Название подключение - Описание - описание подключения. Фактически, является комментарием, можно не заполнять. - Описание подключения - заполняется автоматически. - База данных - здесь необходимо выбрать подключение, настроенное подключение к ODBC драйверу.
Логин и пароль у нас уже прописан в выбранном подключении к ODBC драйверу. Другие настройки в нашем тестировании не понадобятся.
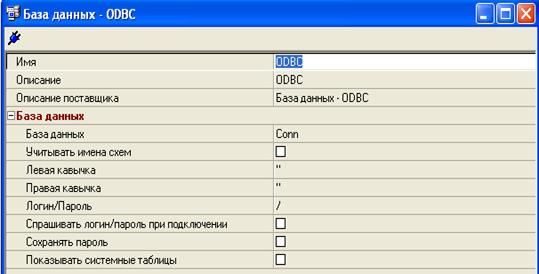
Рис. 30 Окно настроек подключения
Работоспособность подключения можно проверить, щелкнув по иконке штекера в левом верхнем углу окна настроек.
Соединение создано, далее необходимо импортировать базу данных транзакций. Переходим в вид "Сценарии": открываем меню "Вид" и выбираем в нем пункт "Сценарии".
В открывшемся виде щелкаем правой кнопкой мыши по левому окну, содержащему список сценариев. В открывшемся меню выбираем "Мастер импорта". На экран выводится список типов объектов импорта. Выбираем пункт: "База данных - настроенный источник данных".
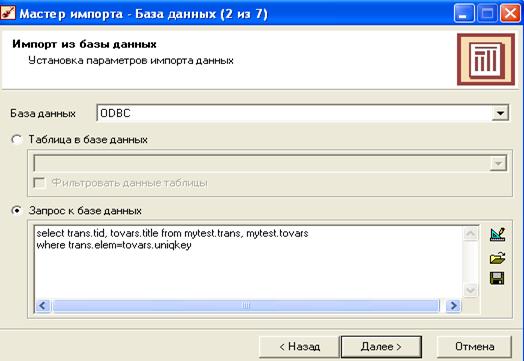
В окне настроек импорта (Рисунок 31) в поле "База данных" выбираем настроенный нами в начале пункта 4.2 источник данных. Можно импортировать целиком таблицу из базы данных, но поскольку таблица товаров в базе данных содержит не названия товаров, а всего лишь их ключи, придется формировать запрос. Формула запроса выглядит так:
Select trans. tid, tovars. title from <название базы>.trans, <название базы>.tovars where trans. elem=tovars. uniqkey
Где tovars - название таблицы товаров, trans - название таблицы транзакций.
В следующем окне запускаем импорт, и, если подключение настроено правильно и формула запроса введена без ошибок, то импорт пройдет успешно.
После окончания импорта пользователю будет предложено настроить вид отображения полученных данных (Рисунок 32).
В первом окне на рисунке 32 мы задаем параметры столбцов, то есть, указываем, какой столбец содержит ID транзакций (идентификатор), а какой элемент. Импортированная база данных представлена на рисунке 26
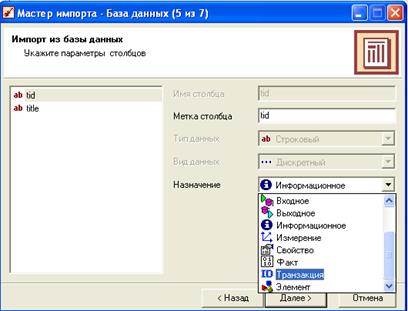
Рис. 32 Настройка внешнего вида импортированных данных
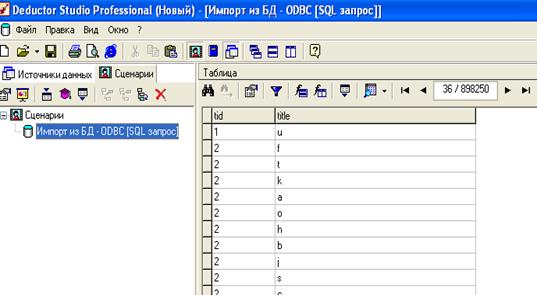
Рис. 33 Импортированная в Deductor база данных
Кластеризация алгоритм транзакция
Для начала обработки импортированных данных нужно кликнуть правой кнопкой мыши на лист импорта в левом окне в списке сценариев. В открывшемся меню выбрать "Мастер обработки". Платформа Deductor предложит способ обработки. Выбираем в списке "Ассоциативные правила". Система предложит еще раз определить типы столбцов, аналогично верхнему экрану на рисунке 33. Определяем и нажимаем "далее".
Откроется окно настройки параметров поиска ассоциативных правил (Рисунок 34).
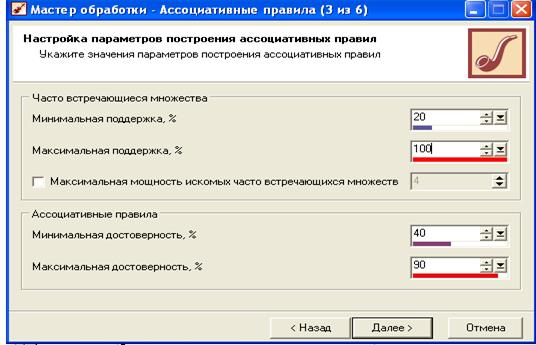
Рис. 34 Настройка параметров построения ассоциативных правил
Ассоциативные правила мы строить не собираемся, поэтому настройки раздела "Ассоциативные правила" не трогаем. Указываем минимальную поддержку, скажем, 20%. А максимальную поддержку устанавливаем на 100%. В следующем окне запускаем процесс поиска частых множеств.
Когда поиск закончен, предлагается выбрать способ представления результатов. Наиболее подходящий нам способ называется "Популярные наборы - отображение текста часто встречающихся множеств". На экран будут выведены результаты поиска (Рисунок 35)
Сравнив результаты работы Deductor и результаты работы программы LargeItem можно видеть, что популярные наборы выдаваемые Deductorом совпадают с "большими предметами", получаемыми после работы программы LargeItem, что говорит о корректности работы алгоритма.
Рис. 35 Результаты поиска частых множеств в Deductor
Похожие статьи
-
Термин "транзакция" относится к подмножеству предметов из общей совокупности с переменным числом предметов (мощностью подмножества). Транзакциями...
-
Для разработки программного обеспечения использован язык Java. Разработка проводилась в среде Eclipse Ganymede 3.2. В качестве СУБД для тестирования...
-
Для запуска кластеризации пользователю нужно ввести 4 параметра: А) Название ODBC драйвера с созданным подключением. Как создать Такое подключение,...
-
Рис. 7 Пример двоичного дерева поиска Двоичное дерево поиска (binary search tree, BST) -- это двоичное дерево, для которого выполняются следующие...
-
Понятие Data Mining Средства Data Mining включают в себя очень широкий класс различных технологий и инструментов. Средства Data Mining на рынке...
-
В наше время все большее количество компаний, стремясь к повышению эффективности и прибыльности бизнеса пользуются цифровыми (автоматизированными)...
-
При тестировании корректности работы алгоритма будем опираться на экспериментальные данные работы алгоритма с предварительно сгенерированными базами...
-
Коллекция транзакций хранится в файле на диске. Алгоритм читает каждую транзакцию t последовательно и присоединяет t к существующему кластеру, или...
-
Рис. 9 Пример B+ дерева, связывающего ключи 1-7 с данными d1-d7. Связи (выделены красным) позволяют быстро обходить дерево в порядке возрастания ключей....
-
Базовый интерфейс двоичного дерева поиска состоит из трех операций: - FIND(K) -- поиск узла, в котором хранится пара (key, value) с key = K. - INSERT(K,...
-
Подход, основанный на "больших" предметах и функциональный критерий кластеризации Поддержка предмета в кластере Ci есть относительное число транзакций в...
-
Допустим, что MinSupi = и * |Ci|. Поддержка данного предмета в Ci характеризует число транзакций в этом кластере, которые содержат этот предмет. Поэтому...
-
Кластеризация (или кластерный анализ) -- это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться...
-
Алгоритм для обновления дан на рис.6. Для каждого предмета е в t отыскивается Hashi. Если е найдено хэше кластера, то увеличиваем на 1 его sup в Btreei....
-
Разработка структур БД Информационная структура БД (Рисунок 2.1) Рисунок 2.1 - Структура БД. Разработка интерфейса для работы с БД В проект в первую...
-
Вычислительная сложность алгоритмов Алгоритм кластеризации Вычислительная сложность Иерархический O(n2) K-средних O(nkl), где k - число кластеров, l -...
-
Модернизация обобщенного алгоритма кластеризации состоит в использовании вместо обычных бинарных деревьев сбалансированных бинарных деревьев(B+ tree)....
-
В то время как цель проекта заключалась в оценке эффективности автоматизации тестирования функционала ядра, работа стала своего рода подведением итогов...
-
В течении года от команды разработчиков пришло 6 пакетов, содержащих изменения в ядре программы. Для каждого пакета составлялось в среднем от 1-ого до...
-
В данном разделе была разработана функциональная схема работы программного комплекса, которая в общем виде описывает состав комплекса, характер и виды...
-
Структура системы В ходе разработки выпускной квалификационной работы использовались базы данных, созданные в среде MySQL Workbench, и создано клиентское...
-
Алгоритм работы. В результате работы АИС генерируются три xml документа - два со структурой сравниваемых баз данных и один с результатами сравнения. В...
-
Если в результате поиска на схеме по данным из таблицы будет найдено несколько экземпляров оборудования (т. е. с одинаковой маркировкой или...
-
В настоящее время существует большое количество поисковых систем, но большинство из них основано на методе, в соответствии с которым документы...
-
Общее описание программного обеспечения, реализующего разработанный алгоритм Основной идеей дипломного проекта, является реализация алгоритма...
-
Тестируемый программный продукт является высокопроизводительным приложением, которое предоставляет возможность создания и настройки сетей беспроводного...
-
Преимущества, которые дает тестировщику автоматизация тестирования: - Исключен "человеческий фактор". Существует некоторая гарантия того, что не один...
-
Для того, чтобы вынести решение об оправданности или неоправданности внедрения автоматизированного тестирования вместо ручного, необходимо...
-
Компания MERA Networks - является одним из крупнейших мировых поставщиков услуг в сфере информационно-коммуникационных технологий. MERA предлагает...
-
Поскольку клиентская часть представляет собой приложение на базе операционной системы Android, то для ее разработки был выбран рекомендуемый...
-
Процесс тестирования, Разработка тест-кейсов - Тестирование программного обеспечения
Тестирование представляет собой процесс проверки того, насколько программное обеспечение соответствует требованиям, заявленным заказчиком. Он...
-
Гражданский кодекс Российской Федерации в части четвертой регулирует вопросы охраны результатов интеллектуальной деятельности и средств индивидуализации....
-
Обоснование выбора средств разработки проекта Для реализации корпоративной информационной системы "Бюджетное планирование и отчетность" в исследуемой...
-
Для того, чтобы строить диаграммы в соответствии с рисунком 2.7, необходимо реализовать алгоритм соединения двух объектов линией. Для отображения линии...
-
При перезагрузке Raspbery счетчик counter сбрасывается и файлы начинают перезаписываться. Для того, чтобы обойти данную проблему воспользуемся переносом...
-
Цель Работы - изучить основные способы работы с пользовательским типом данных "класс", его объектами, методами и способы доступа к ним. - Теоретические...
-
При запуске программы с входными параметрами {"-makexls" "filename. xls" "температурная_точка" "отклонение" "элемент"} происходит извлечение результатов...
-
Работа программы представлена на рисунке 2.3 Рис. 2.3 Кодирование и тестирование программы Программа кодировалась на языке Си++, используя библотеку Qt5x...
-
1. НА 7 ПК ИСПОЛЬЗУЕТСЯ microsoft Windows xp sp2. 2. на 1 используется Altlinux 5 3. Программы офисного назначения: A) Microsoft Office Excel 2003 B)...
-
В процессе разработки программного средства было создано 12 таблиц. Для их создания использовалось графическое средство SqlYong и кодирование на языке...
Deductor Studio 5.1 - Разработка программного обеспечения для реализации и тестирования алгоритма нахождения частых множеств в транзакционных данных вертикального формата