Парсер - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
В приложении можно выделить 2 основных функциональных блока: парсер и оптимизатор. Данная глава посвящена первому из них.
Задача парсера - разобрать исходный SQL-скрипт и уложить каждый его шаг в объект специально разработанного класса, список таких объектов будет представлять собой направленный граф.
Разрабатываемая программа рассчитана на то, чтобы оптимизировать скрипты, на основе которых далее будут строиться ETL-процессы, это ограничивает утверждения, которые надо разбирать до "create table as select". Остальные операции, присутствующие в скрипте, как правило, носят разовый характер и не должны учитываться.
Ранее, в разделе "Цели и задачи", говорилось о том, что программа должна работать в трех режимах.
Первый - самый простой, анализ скрипта только лишь на основе имеющегося кода. Используется в случае, если из программы нельзя подключиться к базе, а у пользователя нет возможности предоставить нужные исходные данные - DDL исходных таблиц, размер и степень неравномерности распределения промежуточных.
При данном режиме накладываются ограничения и на разбор SQL-скриптов. Так, при выборе из исходных таблиц (не промежуточных) не допускается конструкция "select *".
Второй - анализ скрипта на основе имеющегося кода и дополнительных исходных данных. Если у программы нет возможности подключиться к базе самостоятельно, для парсера дополнительным преимуществом будет "знание" DDL объектов - определение исходных таблиц со списком их полей и индексами. При наличии такой информации можно разобрать конструкцию "select *".
Третий режим - программа может подсоединиться к базе сама. В данном случае пользователю не надо будет дополнительно собирать данные, что является куда более удобным решением.
В программе есть 3 основных типа объектов, представляющих собой таблицы - TableNode (таблица-узел), TableStep (таблица-шаг) и TableStepUnion (шаг-объединение).
Все объекты этих типов хранятся в списке, по которому можно построить направленный граф (пример на рис. 5).
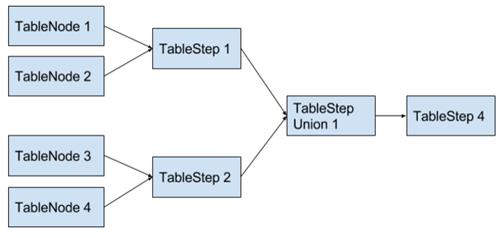
Рис. 5 Способ представления SQL-скрипта в виде графа
Класс TableStep наследуется от класса TableNode и расширяет его. Класс TableStepUnion также наследует класс TableNode, но в качестве исходных таблиц он использует только TableStep-объекты.
Рассмотрим атрибуты, необходимые в объектах этих классов для полного разбора и дальнейшей оптимизации.
TableNode - класс, представляющий таблицу без учета того, из каких источников и как она собирается.
- - Название схемы БД, в которой лежит таблица - Имя таблицы - Список колонок - PI
Все атрибуты представляют собой строки (имя схемы или таблицы) или списки строк (список колонок, PI)
Класс TableStep наследует атрибуты класса TableNode и добавляет новые, чтобы сохранить то, как именно создается данная таблица.
До описания атрибутов объектов этого класса рассмотрим структуру SQL-запросов на выборку данных в СУБД Teradata.
- - SELECT - список выражений - FROM - список исходных таблиц и условий их соединения - WHERE - дополнительные условия на отдельные строки итогового результата - GROUP BY - список полей/выражений, по которым надо группировать - HAVING - условия на группы - ORDER BY - упорядочивание вывода строк (только в простом select) - QUALIFY - условия на аналитические функции
QUALIFY - особенность диалекта SQL, используемого в Teradata. Выражения, использующиеся в этой части - аналог части having, но для аналитических функций. Такой вид функций позволяет работать с группой данных, при этом не прибегая к группировке, что в некоторых ситуациях значительно упрощает скрипты, уменьшая количество необходимых для достижения результата шагов. Конструкция qualify же позволяет отфильтровать неподходящие записи при том же чтении из таблицы, тогда как в oracle, например, для этого понадобится дополнительная выборка с условием where на результат аналитической функции.
Еще одна особенность диалекта SQL Teradata - возможность использования в GROUP BY номеров колонок из части SELECT. Это позволяет сократить длину запроса, но иногда делает его менее удобным для чтения, особенно если SELECT-список достаточно длинный. Так вместо GROUP BY FIELD_1, FIELD_2, FIELD_3 можно написать GROUP BY 1,2,3. Цифры, названия колонок и выражения можно использовать в произвольном сочетании.
Из представленной выше структуры в исходных SQL-скриптах могут встречаться все конструкции, кроме ORDER BY. Из остальных обязательно должны присутствовать только SELECT и FROM, а HAVING может быть только при наличии GROUP BY.
Класс TableStepUnion наследует класс TableNode. Кроме атрибутов основного класса он содержит только список TableStep-шагов (приведенных к типу TableNode) и то, какой именно операцией эти исходные таблицы объединяются: union (all) - объединение (all - не убирая дубли из финального результата), except (all) - исключение результата второй выборки из первой, intersect (all) - данные, совпадающие в витринах, minus аналог Teradata для except. На практике очень часто intersect, except и minus реализовываются с помощью inner или left объединений, тогда основным случаем использования типа таблиц TableStepUnion становится именно объединение данных.
Считается, что скрипт, который подается на оптимизацию, синтаксически корректен. Парсер не должен заниматься проверкой синтаксиса, однако, если что-то не получится разобрать, он выдаст ошибку с указанием примерного места и части запроса/скрипта, в которой произошла ошибка.
В таблице 5 приведено описание основных классов, используемых для реализации хранения в программе SQL-кода (часть TableStep), и их назначения:
Таблица 5 Краткое описание основных классов в TableStep
|
Класс |
Краткое описание |
|
TableSelect |
"Обертка" для класса TableNode, к таблице приписывается псевдоним. |
|
TableColumn |
Название колонки и таблица (TableSelect), из которой она выбирается |
|
Expression |
Выражение - текст и список колонок, которые в этом выражении используются. В самом тексте колонки заменены на маркеры вида "[0]". |
|
SelectColumn |
Колонки в select-списке. Представляет собой выражение (Expression) и псевдоним (при наличии). |
|
Condition |
Условие. Объекты данного класса могут использоваться в QUALIFY, WHERE, HAVING и внутри FROM в соединениях таблиц |
|
JoinCondition |
Условие соединения таблиц. Тип Join'а и список условий (Condition) при их наличии. |
После выделения из шага скрипта select-части она представляется в следующем виде:
- - select expression_list: - expression alias - ... - from join_list: - left table join right table on condition_list - left_expression condition right_expression - where condition_list - left_expression condition right_expression - group by expression_list (ссылки на выражения из select) - having condition_list - qualify condition_list
Для разбора SQL-скриптов были разработаны 2 класса: SQLСleanUp и SQLParser. Первый принимает на вход текст скрипта целиком, очищает его от мусора (в т. ч. не интересующие нас для оптимизации шаги).
Такая структура близка к способу хранения информации о ETL-процессе в инструменте для их построения - SAS Data Integration Studio, поэтому данный парсер может быть в дальнейшем использован и для других проектов, в частности - автоматической сборки простейших ETL по SQL-коду.
Похожие статьи
-
Оптимизатор - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Задача оптимизатора в рамках данной дипломной работы - исправлять части SQL-кода, которые могут приводить к дополнительным тратам памяти и ресурсов. На...
-
СУБД Teradata имеет встроенный оптимизатор, который отвечает за выбор: интерфейс teradata парсер ? Способа доступа к данным - будет ли обращение к...
-
Встроенный оптимизатор запросов в Teradata может значительно ускорить запрос по сравнению тем, как если бы команды выполнялись ровно так, как подает...
-
Введение - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Актуальность. В настоящее время трудно найти фирму, которая не использовала бы базы данных в той или иной форме - учет сотрудников, клиентов, продаж....
-
Цель Работы - изучить приемы создания и использования шаблонов классов. - Теоретические сведения Достаточно часто встречаются классы, объекты которых...
-
Выбор средств реализации информационной системы Названные в параграфе 1.4. настоящей работы задачи могут быть решены тремя типами средств автоматизации:...
-
Заключение - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Оптимизация потребления ресурсов (хранение данных, ресурсы CPU) - важная задача при реализации ETL-процессов. Чем больше ресурсов системы будет свободно,...
-
Проектирование модели - Разработка программного приложения "Калькулятор коммунальных услуг"
При проектировании информационных систем предметная область отображается моделями данных нескольких уровней. Число используемых уровней зависит от...
-
Обзор аналогов - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Создание оптимизирующего препроцессора ограничивается несколькими условиями: 1. Частично написание и тестирование программы проводится на рабочих местах,...
-
Архитектура Teradata Teradata Database - система массовой параллельной обработки данных. Поставляется она в виде комплекса оборудования и программного...
-
Введение - Технология разработки программного обеспечения систем управления
С++ является языком объектно-ориентированного программирования (ООП). Объект - абстрактная сущность, наделенная характеристиками объектов реального мира....
-
Microsoft Access База данных разработана в среде Microsoft Access. Microsoft Access - реляционная СУБД корпорации Microsoft. Имеет широкий спектр...
-
Учебный процесс в ННГАСУ сопровождается значительной информационной базой, развитием компьютерного парка и внедрением в образовательный процесс...
-
2.1 Среды разработки для построения программных агентов Инструментальные средства разработки программных агентов формируют среду, которая оптимизирована...
-
Тестируемый программный продукт является высокопроизводительным приложением, которое предоставляет возможность создания и настройки сетей беспроводного...
-
Можно выделить три основных метода разработки программного обеспечения: 1. Конструкторы программ (Аlgoritm2, Devel Studio, MnCreator, Game Maker и др.)....
-
Для написания АИС использовались следующие языки программирования, программные средства и библиотеки: - Язык программирования PHP 5.4; -...
-
Разработка приложений ведется на языке Java, для этого потребуется специальное программное обеспечение. Самые новые версии системного программного...
-
Общее описание программного обеспечения, реализующего разработанный алгоритм Основной идеей дипломного проекта, является реализация алгоритма...
-
Защита информации на бумажных (машинных) носителях и содержащейся в отходах и браке научной и производственной деятельности организации предусматривает...
-
Обоснование выбора средств для разработки В качестве платформы была взята платформа NET, потому что платформа NET на текущий момент самая передовая и...
-
Основой системы будут два независимых модуля. Первый будет разрабатываться для формирования контента системы, этот модуль будем называть Редактор. Второй...
-
Для разработки программного продукта нами была выбрана СУБД Microsoft Access 2010, которая позволяет выполнять простейшие операции с данными: Ѕ добавить...
-
Функциональные требования: - Поиск и обработка информации в текстовых файлах при появлении файлов в соответствующей директории по запросу администратора...
-
Источники - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
1. William H. Inmon. Building the data warehouse. - 4Th edition. - Wiley Publishing, Inc., 2005. - С. 546. 2. Lawrence Corr, Jim Stagnitto, Agile Data...
-
Разработка интерфейса, Разработка запросов - Высокоуровневые методы информатики и программирования
Программа, будет начинать работу с вывода главной формы, на которой будет располагаться самое главное меню, т. е. другими словами "панель навигации"....
-
Цель Работы - научиться использовать элемент управления ListBox а также основные методы класса СListBox. Использование возможности контроля правильности...
-
Adobe Dreamweaver Adobe Dreamweaver - это HTML-редактор от компании Adobe, который на сегодняшний день очень известный. Первая его версия была выпущена в...
-
Цель Работы - изучить основные способы работы с пользовательским типом данных "класс", его объектами, методами и способы доступа к ним. - Теоретические...
-
Постановка задачи на разработку программного обеспечения Для того чтобы предлагаемая схема была интегрирована в САПР, который не имеет функции интеграции...
-
При составлении бизнес-плана решаются задачи, которые можно сгруппировать в два раздела: собственно планирование, анализ результатов/ подготовка...
-
При разработке практически всех инструментальных средств за основу принимается методология автоматизации проектирования на базе использования прототипов....
-
Объекты области временного хранения классифицируются по предметным областям. Аутентичность исходным данным Заказчика в объектах DF , TD и R достигается...
-
Антивирусные программы Для обнаружения, удаления и защиты от компьютерных вирусов разработано несколько видов специальных программ, которые позволяют...
-
Схема организации подсистемы хранения данных с указанием потоков данных представлена на рисунке 5. Рисунок 5. Схема хранения данных Область Временного...
-
1. Изучение теоретических аспектов использования: MS Word, MS Excel, MS Access, Paint и Photoshop... (ППО) Часть 1 : Руководство по выполнению...
-
Основным достоинством интерфейса Centronics является его стандартность - он есть на каждом компьютере и на всех компьютерах работает одинакового (правда...
-
В данной выпускной квалификационной работе разработан прототип умного почтового ящика, удаленного сетевого устройства для контроля почтовой...
-
Базы данных (БД) составляют в настоящее время основу компьютерного обеспечения информационных процессов, входящих практически во все сферы человеческой...
-
АНТИВИРУСНЫЕ СРЕДСТВА ЗАЩИТЫ - Разработка модели программно-аппаратной защиты на предприятии
Массовое распространение вредоносного ПО вызвало необходимость разработки и использования антивирусов. Антивирусные средства применяются для решения...
Парсер - Разработка программного средства, позволяющего оптимизировать SQL-скрипты