Оптимизатор - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Задача оптимизатора в рамках данной дипломной работы - исправлять части SQL-кода, которые могут приводить к дополнительным тратам памяти и ресурсов.
На появление подобных проблем могут влиять следующие ошибки, допущенные при написании кода:
- - Наличие промежуточных шагов, которые не используются при создании финальных витрин - Протянутые в промежуточные таблицы поля, не нужные для расчета финальных показателей - Соединения на таблицы, поля из которых не используются в текущем шаге - Выбор индекса, использование которого приводит к значительному перекосу в хранении данных или к тратам дополнительных ресурсов CPU при перекладывании таблицы для ее соединения с другими объектами далее в скрипте - Повторяющийся код
Рассмотрим каждую из этих ситуаций и методы, используемые в разработанном приложении для их решения.
1. Забытые промежуточные шаги
Многие задачи имеют более одного пути решения, так и при написании SQL-кода поля финальных витрин часто могут быть получены несколькими способами: рассчитаны в другом порядке, взяты из разных исходных витрин. Если какой-то из способов оказался недостаточно точным по мнению заказчика, или проигрывает другому по каким-то иным показателям, данные промежуточного шага, рассчитывающего первое значение, могут перестать использоваться. Если при этом сама таблица не была убрана из скрипта, она будет занимать дополнительное место.
В качестве примера можно привести простой отчет по балансам новых клиентов (Приложение).
Исходные данные:
- - AGG_DB. CLIENTS - информация по клиентам - DET_DB. CLIENT_ACCOUNT - связка клиент-счет - DET_DB. ACCOUNT_BALANCE - баланс на счету (детальная информация) - AGG_DB. CLIENT_BAL_MONTHLY - баланс на счетах клиента на конец месяца (агрегированная информация)
Первый шаг, выбирает новых клиентов (TEST_DB. CLIENTS_NEW), далее надо привязать к ним балансы. Если заказчик хочет получать такой отчет раз в месяц, на конец месяца, то можно выбрать данные как из детального слоя, так и из агрегированного. В ходе тестирования решили, что использовать витрины агрегированного слоя предпочтительнее - они занимают меньший объем данных, соединения будут легче, а шаг с выбором детальной информации не убрали.
Разработанное программное средство определяет такие случаи. После разбора скрипта те таблицы, которые нигде не используются, помечаются как финальные. Далее у пользователя запрашивается (рис. 6.), какие из таблиц являются итоговыми на самом деле.
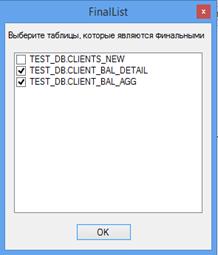
Рис. 6 Запрос на выделение финальных витрин
Если найденная таблица не является целевой и пользователь снимет отметку об этом, она будет убрана из скрипта.
2. Лишние поля в промежуточных таблицах
Иногда в процессе тестирования скрипта требуется дотянуть в промежуточные таблицы поля-источники для расчета показателей (если сами эти поля не должны отображаться в итоге) или прочую дополнительную информацию для тестирования, чтобы понять, корректным или нет получился результат. Потом эти поля могут быть оставлены и, соответственно, занимать место, особенно длинные строки.
Пример - слегка модифицированная версия отчета о балансе новых клиентов на конец месяца (Приложение).
Исходные данные:
- - AGG_DB. CLIENTS - информация по клиентам - AGG_DB. CLIENT_BAL_MONTHLY - баланс на счетах клиента на конец месяца (агрегированная информация)
В первом шаге также выбирается информация по новым клиентам, во втором - подтягивается баланс. Допустим, в какой-то момент считалось, что в отчете должно быть поле ИНН - IND_TAX_PAYER_NUM, потом же от этой идеи отказались, из финальной таблицы поле убрали, а из промежуточной - нет.
Оптимизатор, написанный в рамках этой работы, определяет список полей, которые используются во всех зависимых от таблицы витринах (если это промежуточный шаг), и убирает лишние.
3. Соединение на неиспользуемые таблицы
Если шаг прототипа содержит большое количество соединений для обогащения данных (в таком случае к основной таблице с помощью left join присоединяется другая), при тестировании, аналогично ситуации с полями, могут быть оставлены таблицы, данные из которых фактически не нужны.
Другой вид соединения - inner join - может в таком случае играть роль фильтра - отсекать записи одной из таблиц, которым нет соответствия в другой, а left join, при котором данные присоединяемой таблицы не используются ни в select, ни в последующих соединениях, ни в фильтрации, на самом деле оказывается просто лишней тратой ресурсов. Такой join может привести к слабо контролируемому дублированию данных, источник которого сложно найти, что будет влиять на результаты и сроки тестирования.
В качестве примера возьмем выборку по клиентам (Приложение).
Исходные данные:
- - AGG_DB. CLIENTS - информация по клиентам - AGG_DB. CLIENTS_DETAILED - дополнительная информация по клиентам, доступ к которой производится нечасто, из-за чего ее вынесли отдельно.
Допустим, сначала планировалось, что отчет должен содержать в себе также информацию, необходимую для расчета кредитных рисков - количество членов семьи в общем, а также детей. Позже решили вынести такую информацию в отдельный отчет, а в текущей версии скрипта соединение не убрали.
Разработанный оптимизатор определяет тип соединения, используется ли присоединяемая таблица в текущем шаге, и, если она не используется при соединении типа left join, убирает ее.
4. Неоптимальный выбор индекса
Выбор первичного индекса - один из ключевых моментов при разработке sql-скриптов для Teradata. В зависимости от него будет определено, какой метод соединения будет выбран, и где будут соединяться таблицы - будет ли дополнительное перераспределение или дублирование данных по всем узлам.
При выборе индекса для промежуточного шага надо учесть следующие факторы:
- - По каким полям будет в дальнейшем происходить обращение к таблице - По каким полям происходит соединение внутри шага - Какие поля используются при группировке - Какие поля используются в части partition by конструкции qualify (если эта часть есть, то она будет выполняться последней, и эти поля будут наиболее вероятными кандидатами для PI, особенно если таблица в дальнейшем используется по одному из них).
Для работы оптимизатора желательно иметь подключение к базе, тогда можно будет с большей точностью определить, насколько хорошо выбраны индексы для таблиц.
Если нет подключения к базе, можно приблизительно описать, какого примерно размера будут исходные таблицы. Это повлияет на выбор PI.
Так, оптимизатору подается файл с описанием шаблонов названий исходных таблиц и того, сколько они могут занимать места.
Во многих хранилищах данных производится унификация названий витрин - ручные справочники, детальная информация, агрегированная информация, факты, измерения. Таблицы справочников, которые заполняются вручную, должны быть совсем небольшими, агрегированные витрины - побольше, измерения и факты, как правило, самые большие.
Можно выделить несколько шаблонов названий и оценить по шкале (для простоты - от 1 до 3), каким будет размер этих таблиц относительно друг друга.
На работу оптимизатора также будет влиять, в каком из трех режимов работает программа. Рассмотрим, как именно.
Три режима работы (применительно к оптимизации)
- Первый - самый простой, просто анализ синтаксиса запросов.
В этом режиме работы программе можно указать только приблизительные размеры таблиц относительно друг друга. Эта настройка разовая - не требуется при каждом запуске вводить нужные значения.
- Второй - плюс чтение данных из файла
В режиме работы с чтением данных из файла появляется большая свобода действий как для парсера, так и для оптимизатора.
Файлы, которые потребуются для работы программы в данном режиме:
- Поля, имеющиеся в исходных таблицах
Этот файл представляет собой список полей в каждой из исходных таблиц. Его наличие позволяет разобрать конструкции вида "select * from" и оптимизировать их, потому как часто не все поля, которые выбираются таким образом, особенно на начальных этапах, используются далее в скрипте.
Данные по полям таблиц и представлений содержатся в системной информации Teradata - представлении DBC. ColumnsV.
- Индексы таблиц, их размеры и skew
В данном файле должна содержаться информация по каждой таблице (и исходной, и создаваемой скриптом) - ее название, индекс, размер в Мб и фактор перекоса.
Вся эта информация также содержится в системных таблицах Teradata. Индексы - DBC. Indices, размеры таблиц - DBC. TableSize. Показатель skew вычисляется на основе размеров таблиц.
- Третий - с подсоединением к базе
Данный режим позволяет учесть наибольшее количество факторов по сравнению с другими, плюс он не требует от пользователя ввода информации по индексам, размерам и полям - все это он может программа получает сама. В дополнение к разбору этой информации появляется возможность проверять кандидатов на PI с помощью функций hashamp(hashbucket(hashrow())) и group by - смотреть, на какой из AMP'ов будут попадать данные при выборе PI, и как строки будут распределены между AMP'ами.
Подходящий для таблицы PI определяется по взвешенной сумме факторов. Поля анализируются по двум критериям: входные данные для витрины, какие поля используются в самом шаге, и витрина как исходная для следующих шагов - как будет использоваться в дальнейшем.
Анализ самого шага, для которого ищем индекс. Надо проверить, какие поля из центральной таблицы (обычно - первая таблица в части from) используются в соединении. Хорошие кандидаты для PI - условия равенства на поле (поля), присоединяемые по таким условиям таблицы должны быть либо больше, либо примерно того же размера, что и основная таблица. Если присоединяемая таблица маленького размера и есть возможность установить этот факт по каким-либо из исходных файлов или с помощью запроса напрямую к базе, полю отдается меньший приоритет.
Чем больше идет соединений на поле в текущем шаге, тем большим будет его вес. Также надо учитывать, откуда берется поле-кандидат на индекс. Если оно является PI в исходной витрине, то к весу поля добавляем дополнительные баллы.
Анализ зависимых от текущего шагов.
Здесь уже анализируется, как таблица будет использована дальше, чтобы по возможности избежать перераспределения данных. Если доступ к данным идет по тому же полю, что было выбрано в первой части, это хороший кандидат для PI. Если в первой части было выбрано одно поле, а доступ идет по другому, при этом обращаемся мы к таблице всего один раз, без разницы, какой из вариантов выбрать - все равно оптимизатор будет перекладывать данные. Если же к таблице идет более одного обращения по другому полю, лучше поменять исходный индекс, чтобы минимизировать количество перекладываний данных.
Если оптимизатор находит несколько кандидатов для PI, сообщение об этом выводится в комментарии к шагу.
Пример (Приложение).
Скрипт содержит формирование двух таблиц: счета клиентов (TEST_DB. CLIENT_ACC) и балансы на счете (TEST_DB. CLIENT_BAL). Первая таблица формируется путем соединения двух исходных таблиц по полю CLIENT_ID. Во второй же используется соединение по ACCOUNT_ID. PI первой таблицы в данном примере - (ACCOUNT_ID, CLIENT_ID). Такой индекс может давать более равномерное распределение данных по AMP - у каких-то клиентов счетов может быть много, если они попадут на один AMP, может быть перекос в хранении. Однако, такой PI в данном случае - не лучший выбор, потому что в первой таблице используется соединение по CLIENT_ID, и если таблицы большие, то они обе будут переложены под этот PI, соответственно, первый шаг будет удобно сразу оставить с таким же индексом, перекос в данном случае не должен быть сильно выражен. Также первой таблице можно поставить индекс ACCOUNT_ID, т. к. далее она будет использоваться по этому полю.
5. Повторяющийся код
Данный случай является не очень частым, но иногда бывает, что соединения одних и тех же таблиц в скрипте выполняются несколько раз.
Рассмотрим пример (Приложение - Исходный код).
Данный SQL-скрипт формирует отчет по типам кредитных договоров. Рассматриваются активные договоры - есть задолженность в текущем месяце, закрытые - в прошлом месяце была задолженность, а в этом погасили, и реструктурированные - в прошлом месяце была задолженность, в этом погасили, плюс появилась запись со связкой нового договора (после реструктуризации) и старого (до нее). Для каждого типа договора выбирается информация из исходной витрины - (AGG_DB. AGREEMENT_BALANCE_MONTH), активные - те, у которых есть задолженность, закрытые и реструктурированные - нет, для определения, закрыли ли договор или нет, идет соединение на таблицу реструктуризаций (AGG_DB. AGREEMENTS_RESTRUCT). Если нашли в ней соответствие, то договор был реструктурирован, иначе - просто закрыт. Такие таблицы могут быть достаточно большими. Чтобы не читать информацию много раз, можно сначала выбрать информацию о балансах, после чего сделать одно соединение на таблицу реструктуризаций вместо двух, а условия на балансы и наличие совпадений в витринах вынести далее в скрипт. Пример того, как данный скрипт можно улучшить по количеству просмотров исходных таблиц и количеству соединений также можно посмотреть в приложении (Исправленный код).
Оптимизатор выделяет код, повторяющийся в как можно большем количестве шагов и выносит подобные соединения в отдельные таблицы, сохраняя различающиеся части.
Все приведенные выше примеры являются упрощением реальных случаев, возникавших при разработке ETL-процессов.
Похожие статьи
-
Встроенный оптимизатор запросов в Teradata может значительно ускорить запрос по сравнению тем, как если бы команды выполнялись ровно так, как подает...
-
Парсер - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
В приложении можно выделить 2 основных функциональных блока: парсер и оптимизатор. Данная глава посвящена первому из них. Задача парсера - разобрать...
-
СУБД Teradata имеет встроенный оптимизатор, который отвечает за выбор: интерфейс teradata парсер ? Способа доступа к данным - будет ли обращение к...
-
Введение - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Актуальность. В настоящее время трудно найти фирму, которая не использовала бы базы данных в той или иной форме - учет сотрудников, клиентов, продаж....
-
Заключение - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Оптимизация потребления ресурсов (хранение данных, ресурсы CPU) - важная задача при реализации ETL-процессов. Чем больше ресурсов системы будет свободно,...
-
Выбор средств реализации информационной системы Названные в параграфе 1.4. настоящей работы задачи могут быть решены тремя типами средств автоматизации:...
-
Учебный процесс в ННГАСУ сопровождается значительной информационной базой, развитием компьютерного парка и внедрением в образовательный процесс...
-
Обзор аналогов - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
Создание оптимизирующего препроцессора ограничивается несколькими условиями: 1. Частично написание и тестирование программы проводится на рабочих местах,...
-
Защита информации на бумажных (машинных) носителях и содержащейся в отходах и браке научной и производственной деятельности организации предусматривает...
-
Для разработки программного продукта нами была выбрана СУБД Microsoft Access 2010, которая позволяет выполнять простейшие операции с данными: Ѕ добавить...
-
2.1 Среды разработки для построения программных агентов Инструментальные средства разработки программных агентов формируют среду, которая оптимизирована...
-
Архитектура Teradata Teradata Database - система массовой параллельной обработки данных. Поставляется она в виде комплекса оборудования и программного...
-
Реализация с помощью средств быстрой разработки DbForge Studio for SQL Server -- среда разработки для БД SQL Server, создания отчетов по данным, их...
-
Для написания АИС использовались следующие языки программирования, программные средства и библиотеки: - Язык программирования PHP 5.4; -...
-
Программные средства защиты - Инженерно-техническая защита объектов
Системы защиты компьютера от чужого вторжения весьма разнообразны и классифицируются, как: Средства собственной защиты, предусмотренные общим программным...
-
Основные компоненты и структура приложения Прежде чем приступить к установке и настройке среды программирования, построению технического задания и...
-
При работе над проектом разрабатывались два основных компонента системы: база данных (далее - БД) и интерфейс клиентского приложения. Затем необходимо...
-
Базы данных (БД) составляют в настоящее время основу компьютерного обеспечения информационных процессов, входящих практически во все сферы человеческой...
-
Microsoft Access База данных разработана в среде Microsoft Access. Microsoft Access - реляционная СУБД корпорации Microsoft. Имеет широкий спектр...
-
Общие сведения Данное программное средство должно помочь в расчете коммунальных услуг, упростить ввод данных о квартиросъемщике и ЖЭС, осуществлять...
-
Функциональные требования: - Поиск и обработка информации в текстовых файлах при появлении файлов в соответствующей директории по запросу администратора...
-
Источники - Разработка программного средства, позволяющего оптимизировать SQL-скрипты
1. William H. Inmon. Building the data warehouse. - 4Th edition. - Wiley Publishing, Inc., 2005. - С. 546. 2. Lawrence Corr, Jim Stagnitto, Agile Data...
-
Информационная система (ИС) ГИБДД должна обеспечивать хранение информации об автомобилях (марка, номер кузова, номер двигателя, цвет кузова, гос. номер),...
-
Основные термины теории баз данных - БД (База данных) - совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы...
-
Вирусы и антивирусное программное обеспечение
Реферативная часть Что такое вирус? Один из известных "докторов" Д. Н Лозинский дал определение вируса на примере клерка. Представим себе аккуратного...
-
Каждая СУБД имеет особенности в представлении структуры таблиц, связей, определении типов данных и т. д. которую необходимо учитывать при проектировании....
-
Основные конструкции для разработки базы данных - База данных "Кинотеатр"
База данных - это организованная структура, предназначенная для хранения информации. Систему управления базой данных (СУБД) можно определить, как...
-
Цель Работы - изучить приемы создания и использования шаблонов классов. - Теоретические сведения Достаточно часто встречаются классы, объекты которых...
-
В пос. Заводском на ул. Черноморской возле дома 43 не установленными преступниками было совершено разбойное нападение на водителя такси Б.. От полученных...
-
Постановка задач на проектирование Мотивация: В настоящее время есть возможность улучшить эффективность управлением временем и коммуникацией между...
-
Структура программных средств - Автоматизация процесса работы руководства ООО "Сервис партнер"
На рисунке 10 показана принципиальная схема взаимодействия элементов разработанной системы. Рисунок 10 Схема взаимодействия элементов системы На рисунке...
-
1. Изучение теоретических аспектов использования: MS Word, MS Excel, MS Access, Paint и Photoshop... (ППО) Часть 1 : Руководство по выполнению...
-
Проектирование модели - Разработка программного приложения "Калькулятор коммунальных услуг"
При проектировании информационных систем предметная область отображается моделями данных нескольких уровней. Число используемых уровней зависит от...
-
Требования к функционированию программы Модуль функционирует в следующих режимах: Ш подготовка исходных данных; Ш заключение договора с клиентом; Ш...
-
2.2 Модель программного агента ресурсов - Средства для создания программных агентов
Программный агент в мультиагентной системе имеет свое описание в виде BDI модели, которая содержит его знания, планы и цели, которые агент выполняет по...
-
Модификацией программно-аппаратного комплекса может быть использование умного РОЕ инжектора. POE инжектор (injector или midspan) -- устройство,...
-
Adobe Dreamweaver Adobe Dreamweaver - это HTML-редактор от компании Adobe, который на сегодняшний день очень известный. Первая его версия была выпущена в...
-
1.4 Средства спецификаций типовых моделей - Средства для создания программных агентов
Рассмотрим типовую модель, которая получила название Reticular Agent Mental Model (RAMM) и является развитием модели Шохама (Shoham), где все действия...
-
1.1 Анализ существующих программных агентов Согласно классическому определению, программный агент -- это программа-посредник. Эти посредники...
-
Технические требования Конфигурация компьютера, на котором разрабатывалось программное приложение: - процессор Athlon64 X2 3800+ 2000MHz; -...
Оптимизатор - Разработка программного средства, позволяющего оптимизировать SQL-скрипты