Лабораторная работа №2, Цель работы, Теоретическое введение - Интеллектуальные информационные системы
Деревья решений - общие принципы работы
Цель работы
Изучить принцип построения деревьев решений и построить дерево решений на основе имеющейся выборки примеров.
Теоретическое введение
Деревья решений - это способ представления правил в иерархической, последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение.
Под правилом понимается логическая конструкция, представленная в виде "если... то...".
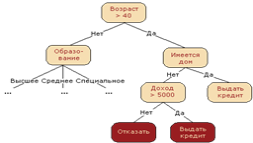
Рис.3 Пример дерева решений
Введем основные понятия из теории деревьев решений:
Название Описание
Объект Пример, шаблон, наблюдение
Атрибут Признак, независимая переменная, свойство
Метка класса Зависимая переменная, целевая переменная, признак определяющий класс объекта
Узел Внутренний узел дерева, узел проверки
Лист Конечный узел дерева, узел решения
Проверка (test) Условие в узле
Пусть нам задано некоторое обучающее множество T, содержащее объекты (примеры), каждый из которых характеризуется m атрибутами (атрибутами), причем один из них указывает на принадлежность объекта к определенному классу.
Идею построения деревьев решений из множества T, впервые высказанную Хантом, приведем по Р. Куинлену (R. Quinlan).
Пусть через {C1, C2, ... CK} обозначены классы(значения метки класса), тогда существуют 3 ситуации:
- 1. множество T содержит один или более примеров, относящихся к одному классу CK. Тогда дерево решений для Т - это лист, определяющий класс CK; 2. множество T не содержит ни одного примера, т. е. пустое множество. Тогда это снова лист, и класс, ассоциированный с листом, выбирается из другого множества отличного от T, скажем, из множества, ассоциированного с родителем; 3. множество T содержит примеры, относящиеся к разным классам. В этом случае следует разбить множество T на некоторые подмножества. Для этого выбирается один из признаков, имеющий два и более отличных друг от друга значений O1, O2, ... ON. T разбивается на подмножества T1, T2, ... TN, где каждое подмножество TI содержит все примеры, имеющие значение OI для выбранного признака. Это процедура будет рекурсивно продолжаться до тех пор, пока конечное множество не будет состоять из примеров, относящихся к одному и тому же классу.
При использовании данной методики, построение дерева решений будет происходит сверху вниз.
Поскольку все объекты были заранее отнесены к известным нам классам, такой процесс построения дерева решений называется обучением с учителем (supervised learning). Процесс обучения также называют индуктивным обучением или индукцией деревьев (tree induction).
Этапы построения деревьев решений
При построении деревьев решений особое внимание уделяется следующим вопросам: выбору критерия атрибута, по которому пойдет разбиение, остановки обучения и отсечения ветвей. Рассмотрим все эти вопросы по порядку.
Правило разбиения. Каким образом следует выбрать признак?
Для построения дерева на каждом внутреннем узле необходимо найти такое условие (проверку), которое бы разбивало множество, ассоциированное с этим узлом на подмножества. В качестве такой проверки должен быть выбран один из атрибутов. Общее правило для выбора атрибута можно сформулировать следующим образом: выбранный атрибут должен разбить множество так, чтобы получаемые в итоге подмножества состояли из объектов, принадлежащих к одному классу, или были максимально приближены к этому, т. е. количество объектов из других классов ("примесей") в каждом из этих множеств было как можно меньше.
Рассмотрим теоретико-информационный критерий разбиения.
Для выбора наиболее подходящего атрибута, предлагается следующий критерий:

Где, Info(T) - энтропия множества T
- количество примеров из некоторого множества S, относящихся к одному и тому же классу CJ. Тогда вероятность того, что случайно выбранный пример из множества S будет принадлежать к классу CJ

Согласно теории информации количество содержащейся в сообщении информации зависит от ее вероятности

Поскольку используется логарифм с двоичным основанием, то выражение дает количественную оценку в битах.


Множества T1, T2, ... Tn получены при разбиении исходного множества T по проверке X. Выбирается атрибут, дающий максимальное значение по критерию (1).
Впервые эта мера была предложена Р. Куинленом в разработанном им алгоритме ID3. Кроме вышеупомянутого алгоритма C4.5, есть еще целый класс алгоритмов, которые используют этот критерий выбора атрибута.
Правило остановки. Разбивать дальше узел или отметить его как лист?
В дополнение к основному методу построения деревьев решений были предложены следующие правила:
- - Использование статистических методов для оценки целесообразности дальнейшего разбиения, так называемая "ранняя остановка" (prepruning). В конечном счете "ранняя остановка" процесса построения привлекательна в плане экономии времени обучения, но здесь уместно сделать одно важное предостережение: этот подход строит менее точные классификационные модели и поэтому ранняя остановка крайне нежелательна. Признанные авторитеты в этой области Л. Брейман и Р. Куинлен советуют буквально следующее: "Вместо остановки используйте отсечение". - Ограничить глубину дерева. Остановить дальнейшее построение, если разбиение ведет к дереву с глубиной превышающей заданное значение. - Разбиение должно быть нетривиальным, т. е. получившиеся в результате узлы должны содержать не менее заданного количества примеров.
Этот список эвристических правил можно продолжить, но на сегодняшний день не существует такого, которое бы имело большую практическую ценность. К этому вопросу следует подходить осторожно, так как многие из них применимы в каких-то частных случаях.
Правило отсечения. Каким образом ветви дерева должны отсекаться?
Очень часто алгоритмы построения деревьев решений дают сложные деревья, которые "переполнены данными", имеют много узлов и ветвей. Такие "ветвистые" деревья очень трудно понять. К тому же ветвистое дерево, имеющее много узлов, разбивает обучающее множество на все большее количество подмножеств, состоящих из все меньшего количества объектов.
Ценность правила, справедливого скажем для 2-3 объектов, крайне низка, и в целях анализа данных такое правило практически непригодно.
Гораздо предпочтительнее иметь дерево, состоящее из малого количества узлов, которым бы соответствовало большое количество объектов из обучающей выборки.
Для решения вышеописанной проблемы часто применяется так называемое отсечение ветвей (pruning).
Пусть под точностью (распознавания) дерева решений понимается отношение правильно классифицированных объектов при обучении к общему количеству объектов из обучающего множества, а под ошибкой - количество неправильно классифицированных. Предположим, что нам известен способ оценки ошибки дерева, ветвей и листьев. Тогда, возможно использовать следующее простое правило:
- - построить дерево; - отсечь или заменить поддеревом те ветви, которые не приведут к возрастанию ошибки.
В отличии от процесса построения, отсечение ветвей происходит снизу вверх, двигаясь с листьев дерева, отмечая узлы как листья, либо заменяя их поддеревом.
Путь дерева - совокупность вершин от корня дерева до листа. Путь - это фактически одно продукционное правило.
Достоверность пути (правила) - это отношение количества записей в облучающей выборке, которые подходят как под условие, так и под следствие этого правила, к количеству записей, подходящих только под условие этого правила. Если достоверность ниже требуемой - такой путь отсекается.
Похожие статьи
-
Изучение возможностей экспертных систем Цель работы Целью является проектирование и разработка фрагмента экспертной системы. Теоретическое введение...
-
Введение - Интеллектуальные информационные системы
Чаще всего искусственным интеллектом, или ИИ (Artificial Intelligence - AI), называют процесс создания машин, которые способны действовать таким образом,...
-
Деревья решений - это способ представления иерархической, последовательной структуры организованной по определенным правилам, где каждому объекту...
-
В связи с увеличением числа сотрудников, работающих в компании, а также с расширением рабочего проекта, возникла проблема, связанная с версионностью...
-
Основные термины теории баз данных - БД (База данных) - совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы...
-
Типы экспертных систем - Теоретические основы информационных технологий
Можно назвать несколько Типов современных экспертных систем . 1) Экспертные системы первого поколения. Предназначены для решения хорошо структурированных...
-
Цель Работы - изучить приемы создания и использования шаблонов классов. - Теоретические сведения Достаточно часто встречаются классы, объекты которых...
-
Цель Работы - изучить одну из базовых концепций ООП, наследование классов в С++, заключающуюся в построении цепочек классов, связанных иерархически,...
-
Геоинформационные системы и технологии - Теоретические основы информационных технологий
Геоинформационные системы (ГИС) и ГИС - технологии объединяют компьютерную картографию и системы управления базами данных. Концепция технологии ГИС...
-
Классификация компьютерных сетей - Теоретические основы информационных процессов и систем
Для классификации компьютерных сетей используются разные признаки, выбор которых заключается в том, чтобы выделить из существующего многообразия такие,...
-
Инфологическое проектирование Стандартным способом представления концептуальной модели базы данных являются диаграммы "сущность-связь" (ERD),...
-
Цель Работы - использовать принципы архитектуры "Документ-Представление" для выборки и сохранения данных в файлах, а также взаимодействия элементов меню,...
-
Основные понятия СУБД Microsoft Access Microsoft Access - это система управления базами данных, предназначенная для создания и обслуживания баз данных,...
-
Подсистема интеллектуального анализа данных используется специальной категорией пользователей-аналитиков, которые на основе ИХ обнаруживают...
-
Цель Работы - изучить основные способы работы с пользовательским типом данных "класс", его объектами, методами и способы доступа к ним. - Теоретические...
-
Описание запуска, Инструкции по работе, Сообщения пользователю - Информационная система Вуза
Для запуска разработанного программного продукта необходимо открыть запускной файл (файл с расширением *.exe) (см. рис. 6). Рисунок 5- Запуск...
-
Введение - Информационная система Вуза
Одним из важнейших условий обеспечения эффективного функционирования любой организации является наличие развитой автоматизированной информационной...
-
Сегодня положение дел в рассматриваемой области характеризуется крайней неопределенностью. Во-первых, это связано с непрерывным увеличением объема...
-
Введение - Корпоративные информационные системы
Актуальность работы. Внедрение корпоративной информационной системы на предприятии любого размера и профиля деятельности дает предприятию следующие...
-
Из универсальных языков программирования сегодня наиболее популярны следующие: Бейсик (Basic), Паскаль (Pascal), Си++ (C++), Ява (Java). Для каждого из...
-
Современные табличные процессоры имеют очень широкие функциональные и вспомогательные возможности, обеспечивающие удобную и эффективную работу...
-
Поколения языков программирования Языки программирования принято делить на пять поколений. В первое поколение входят языки, созданные в начале 50-х...
-
Технологии распределенных вычислений (РВ) Современное производство требует высоких скоростей обработки информации, удобных форм ее хранения и передачи....
-
Введение - Поверка и калибровка информационно измерительных систем
На сегодня метрологическая деятельность регулируется Законом Российской Федерации "Об обеспечении единства измерений". Из этого следует, что эта...
-
SimpleXML. В PHP версии 5.0 и выше появилось расширение для работы с xml структурой. Библитека SimpleXML содержит большое количество методов для работы с...
-
"РЕШЕНИЕ ЗАДАЧ ЛИНЕЙНОГО ПРОГРАММИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ MICROSOFT EXCEL" Цель работы Приобретение навыков решения задач линейного программирования...
-
Трудности разработки экспертных систем - Разработка интеллектуальных подсистем САПР
При разработке ЭС разработчиков поджидают различные трудности: Глобальные, имеющие отношение ко всему процессу разработки или к нескольким этапам...
-
Наименование программы Полное наименование программы - Модуль ипотечного кредитования банковской информационной системы "БИС". Краткое наименование...
-
Класс ЭС сегодня объединяет несколько тысяч различных программных комплексов, которые можно классифицировать по различным критериям. Классификация по...
-
Классификация массивов - История создания и развития автоматизированных информационных систем
Организационная подборка сведений о каком-либо объекте или процессе либо о ряде однородных объектов или процессов называется массивом информации. 1. По...
-
Источники информации в информационной системе. Информационные модели объекта правления. Информационные массивы и потоки От решений, которые принимает...
-
Информационно-логические модели данных, Иерархическая модель - Система управления базами данных
Иерархическая модель Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Графическим способом...
-
Наименование и область применения Наименование: Автоматизированная информационная система "Отель" в дальнейшем именуемая АИС "Отель". Область применения:...
-
Введение в экспертные системы. Определение и структура - Разработка интеллектуальных подсистем САПР
В качестве рабочего определения экспертной системы примем следующее. Экспертные Системы это сложные программные комплексы, аккумулирующие знания...
-
ВВЕДЕНИЕ - Разработка проекта информационной системы "Учет оборудования"
На сегодняшний день нет единого понятия информационной системы и информационных технологий. Тем не менее, во множестве источников информационная система...
-
Введение, Медицинские информационные системы - Информационные медицинские системы
В медицине, как в фокусе, концентрируется множество различных проблем. В первую очередь это касается гетерогенных источников информации, где нет единства...
-
Введение - Информационная система "Автосервис"
За последние годы в нашей стране произошли значительные перемены, которые не могли не затронуть области информатики и вычислительной техники. Десять лет...
-
Основная цель системы ДИСКОР - совершенствование оперативного управления работой железных дорог на основе более эффективного использования пропускной...
-
В современном городе с его бешеным ритмом жизни и постоянной нехваткой времени, многие люди стараются экономить каждый час своего дня. Все чаще в поисках...
-
Информационная система (ИС) ГИБДД должна обеспечивать хранение информации об автомобилях (марка, номер кузова, номер двигателя, цвет кузова, гос. номер),...
Лабораторная работа №2, Цель работы, Теоретическое введение - Интеллектуальные информационные системы