Лабораторная работа №4, Цель работы, Теоретическое введение - Интеллектуальные информационные системы
Обучение нейронной сети
Цель работы
Изучить принципы проектирования и обучения нейронных сетей с помощью пакета Matlab. Изучить на практике работу алгоритма обратного распространения ошибки.
Теоретическое введение
Способность к обучению является фундаментальным свойством мозга. В контексте искусственных нейронных сетей (ИНС) процесс обучения может рассматриваться как настройка архитектуры сети и весов связей для эффективного выполнения специальной задачи. Обычно нейронная сеть должна настроить веса связей по имеющейся обучающей выборке. Функционирование сети улучшается по мере итеративной настройки весовых коэффициентов. Свойство сети обучаться на примерах делает их более привлекательными по сравнению с системами, которые следуют определенной системе правил функционирования, сформулированной экспертами.
Правило коррекции по ошибке. При обучении с учителем для каждого входного примера задан желаемый выход d. Реальный выход сети y может не совпадать с желаемым. Принцип коррекции по ошибке при обучении состоит в использовании сигнала (d-y) для модификации весов, обеспечивающей постепенное уменьшение ошибки. Обучение имеет место только в случае, когда перцептрон ошибается. Известны различные модификации этого алгоритма обучения.
Свойства алгоритма обратного распространения ошибки (Back Propagation - ВР)
ВР - это итеративный градиентный алгоритм обучения многослойной НС без обратных связей. В такой сети на каждый нейрон первого слоя подаются все компоненты входного вектора. Все выходы скрытого слоя m подаются на слой m+1 и т. д., т. е. сеть является полносвязной.
Согласно методу наименьших квадратов, минимизируемой целевой функцией ошибки нейронной сети является величина:

(13)

Где - реальное выходное состояние нейрона у выходного слоя нейронной сети при подаче на ее входы k-го образа; dJ, k - требуемое выходное состояние этого нейрона.
Суммирование ведется по всем нейронам выходного слоя и по всем обрабатываемым сетью образам. Минимизация методом градиентного спуска обеспечивает подстройку весовых коэффициентов следующим образом:

(14)
Где wIj - весовой коэффициент синаптической связи, соединяющей i-й нейрон слоя (q-1) с j-м нейроном слоя q; з - коэффициент скорости обучения, 0 < з <1.
В соответствии с правилом дифференцирования сложной функции:

, (15)
Где sJ - взвешенная сумма входных сигналов нейрона j, т. е. аргумент активационной функции. Так как производная активационной функции должна быть определена на всей оси абсцисс, то функция единичного скачка и прочие активационные функции с неоднородностями не подходят для рассматриваемых нейронных сетей. В них применяются такие гладкие функции, как гиперболический тангенс или классический сигмоид с экспонентой. Например, в случае гиперболического тангенса:

(16)
Третий множитель ?sJ / ?wIj равен выходу нейрона предыдущего слоя.
Что касается первого множителя в (23), он легко раскладывается следующим образом:

(17)
Здесь суммирование по r выполняется среди нейронов слоя (q+1). Введя новую переменную

(18)


Получим рекурсивную формулу для расчетов величин слоя q из величин более старшего слоя (q+1):

(19)
Для выходного слоя:

(20)
Теперь можно записать (14) в раскрытом виде:

(21)
Иногда для придания процессу коррекции весов некоторой инерционности, сглаживающей резкие скачки при перемещении по поверхности целевой функции, (21) дополняется значением изменения веса на предыдущей итерации:

(22)
Где µ - коэффициент инерционности; t - номер текущей итерации.
Таким образом, полный алгоритм обучения нейронной сети с помощью процедуры обратного распространения строится следующим образом.
ШАГ 1. Подать на входы сети один из возможных образов и в режиме обычного функционирования нейронной сети, когда сигналы распространяются от входов к выходам, рассчитать значения последних. Напомним, что:

(23)

Где L - число нейронов в слое (q-1) с учетом нейрона с постоянным выходным состоянием +1, задающего смещение; - i-й вход нейрона j слоя q.

(24)
Где f(*)-сигмоид,
, (25)
Где хR - r-я компонента вектора входного образа.
ШАГ 2. Рассчитать д(Q) для выходного слоя по формуле (20).
Рассчитать по формуле (21) или (22) изменения весов ?w(Q) слоя Q.
ШАГ 3. Рассчитать по формулам (20) и (21) соответственно д(Q) и ?w(Q) для всех остальных слоев, q = (Q - 1)...1.
ШАГ 4. Скорректировать все веса в нейронной сети:

(26)
ШАГ 5. Если ошибка сети существенна, перейти на шаг 1. В противном случае - конец.
Сети на шаге 1 попеременно в случайном порядке предъявляются все тренировочные образы, чтобы сеть, образно говоря, не забывала одни по мере запоминания других.
Некоторые трудности, связанные с применением данного алгоритма в процедуре обучения НС.
Медленная сходимость процесса обучения. Сходимость ВР строго доказана для дифференциальных уравнений, т. е. для бесконечно малых шагов в пространстве весов. Но бесконечно малые шаги означают бесконечно большое время обучения. Следовательно, при конечных шагах сходимость алгоритма обучения не гарантируется.
Переобучение. Высокая точность, получаемая на обучающей выборке, может привести к неустойчивости результатов на тестовой выборке. Чем лучше сеть адаптирована к конкретным условиям (к обучающей выборке), тем меньше она способна к обобщению и экстраполяции. В этом случае сеть моделирует не функцию, а шум, присутствующий в обучающей выборке. Это явление называется переобучением. Кардинальное средство борьбы с этим недостатком - использование подтверждающей выборки примеров, которая используется для выявления переобучения сети. Ухудшение характеристик НС при работе с подтверждающей выборкой указывает на возможное переобучение. Напротив, если ошибка последовательно уменьшается при подаче примеров из подтверждающегося множества, сеть продолжает обучаться. Недостатком этого приема является уменьшение числа примеров, которое можно использовать в обучающем множестве (уменьшение размера обучающей выборки снижает качество работы сети). Кроме того, возникает проблема оптимального разбиения исходных данных на обучающую, тестовую и подтверждающую выборку. Даже при случайной выборке разные разбиения базы данных дают различные оценки.
"Ловушки", создаваемые локальными минимумами. Детерминированный алгоритм обучения типа ВР не всегда может обнаружить глобальный минимум или выйти из него. Одним из способов, позволяющих обходить "ловушки", является расширение размерности пространства весов за счет увеличения скрытых слоев и числа нейронов скрытого слоя. Другой способ - использование эвристических алгоритмов оптимизации, один из которых - генетический алгоритм.
Для создания и обучения нейронных сетей достаточно хорошо себя зарекомендовал пакет Matlab.
Описание функций пакета Matlab
Функция NEWFF - сеть прямой передачи FF
Синтаксис:
Net = newff(PR,[S1 S2...SNI],{TF1 TF2...TFNI},btf, blf, pf)
Описание:
Функция newff предназначена для создания многослойных нейронных сетей прямой передачи сигнала с заданными функциями обучения и настройки, которые используют метод обратного распространения ошибки.
Функция net = newff(PR, [SI S2 ... SN1], (TF1 TF2 ... TFN1}, btf, blf, pf) формирует многослойную нейронную сеть.
Входные аргументы:
PR - массив размера Rx2 минимальных и максимальных значений для R векторов входа;
Si - количество нейронов в слое i;
TFi - функция активации слоя i, по умолчанию tansig;
Btf - обучающая функция, реализующая метод обратного распространения, по умолчанию trainlm;
Blf - функция настройки, реализующая метод обратного распространения, по умолчанию learngdm;
Pf - критерий качества обучения, по умолчанию mse.
Выходные аргументы:
Net - объект класса network object многослойной нейронной сети.
Свойства сети:
Функциями активации могут быть любые дифференцируемые функции, например tansig, logsig или purelin.
Обучающими функциями могут быть любые функции, реализующие метод обратного распространения: trainlm, trainbfg, trainrp, traingd и др.
Функция trainlm является обучающей функцией по умолчанию, поскольку обеспечивает максимальное быстродействие, но требует значительных ресурсов памяти. Если ресурсы памяти недостаточны, воспользуйтесь следующими рекомендациями:
- * установите значение свойства net. trainParam. mеm_reduc равным 2 или более, что снизит требования к памяти, но замедлит обучение; * воспользуйтесь обучающей функцией trainbfg, которая работает медленнее, но требует меньшей памяти, чем М-функция trainlm; * перейдите к обучающей функции trainrp, которая работает медленнее, но требует меньшей памяти, чем М-функция trainbifg.
Функциями настройки могут быть функции, реализующие метод обратного распространения: learngd, learngdm.
Критерием качества обучения может быть любая дифференцируемая функция: mse, msereg.
TRAIN - обучение нейронной сети
Синтаксис:
[net, TR] = train(net, P, T, Pi, Ai)
[net, TR] = train(net, P, T, Pi, Ai, VV, TV)
Описание:
Функция [net, TR] = train(net, P, T, Pi, Ai) является методом для объектов класса network object, который реализует режим обучения нейронной сети. Эта функция характеризуется следующими входными и выходными аргументами.
Входные аргументы:
Net - имя нейронной сети;
Р - массив входов;
Т - вектор целей, по умолчанию нулевой вектор;
Pi - начальные условия на линиях задержки входов, по умолчанию нулевой вектор;
Ai - начальные условия на линиях задержки слоев, по умолчанию нулевой вектор.
Выходные аргументы:
Net - структура объекта network object после обучения;
TR - характеристики процедуры обучения:
TR. timesteps - длина последней выборки;
TR. perf - значения функции качества на последнем цикле обучения.
Заметим, что входной аргумент Т используется только при наличии целевых выходов. Аргументы Pi и Pf используются только в случае динамических сетей, имеющих линии задержки на входах или в слоях.
Примеры функций активации:
Logsig - сигмоидальная;
Purelin - линейная;
Tansig - гиперболический тангенс;
Пример 1:
Создать нейронную сеть, чтобы обеспечить следующее отображение последовательности входа Р в последовательность целей Т:
Р= [0 1 2 3 4 5 6 7 8 9 10];
Т= [0 1 2 3 4 3 2 1 2 3 4];
Архитектура нейронной сети: двухслойная сеть с прямой передачей сигнала; скрытый слой - 5 нейронов с функцией активации tansig; выходной слой - 1 нейрон с функцией активации purelin; диапазон изменения входа [0 10].
Net = newff([0 10],[5 1],{'tansig' 'purelin'});
Обучим сеть в течение 50 циклов:
Net. trainParam. epochs = 50;
Net = train(net, P, T);
Выполним моделирование сети и построим графики сигналов выхода и цели.
Y = sim(net, P);
Plot(P, Т, P, Y)
Пример 2:
Построить нейронную сеть для распознавания индексов на почтовых конвертах.
Для этих целей будет использована двухслойная структура нейронной сети. На вход будут подаваться цвета пикселей, из которых состоит изображение цифры. Количество входных нейронов - это произведение ширины изображения цифры на высоту. Выходных нейронов будет столько, сколько предполагается распознавать образов: 10 цифр - 10 образов.
1) Предположим, что распознаваться будут цифры, применяемые на конвертах.

Рис. 17 Распознаваемые символы
В данном случае их размеры: 11 на 21 пикселей.
2) Загружаем эти символы в Matlab.
File=>Import data
После загрузки в поле WorkSpace появится структура, состоящая из двух массивов. В одном из них содержится цвет каждого пикселя. С его помощью и будем формировать обучающую выборку.
A0=A0.cdata; % запишем этот массив в переменную. И так для каждой цифры. Необходимо привести массив к нужному виду.
A0=double(a0); %привести к нужному типу
A0=a0'; %транспонировать
A0=reshape(a0,231,1); % перевести в вектор-столбец. 231 = 11*21 пикселей.
Таким образом создан вектор-столбец цифры ноль. Указанные набор действий повторяется для каждой цифры.
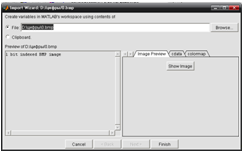
Рис. 18 Интерфейс загрузки изображений в Matlab
Далее создадим общий массив цифр: это основная часть обучающей выборки.
Chisla=[a0 a1 a2 a3 a4 a5 a6 a7 a8 a9];
Далее создается массив ожидаемых результатов - "целей" target. В нем по главной диагонали будут 1, все остальные - нули. Размер: 10*10 (так как мы распознаем 10 цифр).
Target=eye(10);
3) Затем создается программа просмотра полученных цифр. File=>New=>M-file.
Ниже приведено содержимое созданного файла-функции myplotchar. m:
Function myplotchar(c)
X1 = [-0.5 -0.5 +0.5 +0.5 -0.5];
Y1 = [-0.5 +0.5 +0.5 -0.5 -0.5];
X2 = [x1 +0.5 +0.5 -0.5];
Y2 = [y1 +0.5 -0.5 +0.5];
Newplot;
Plot(x1*11.6+2.5,y1*21.6+10.5,'m');
Axis([-1.5 11.5 -0.5 21.5]);
Axis('equal')
Axis off
Hold on
For i=1:length(c)
X = rem(i-1,11)-2.5;
Y = 6-floor((i-1)/11)+14.5;
Plot(x2*(1-c(i))+x, y2*(1-c(i))+y);
End
Hold off
%--------------------------------------------------
Результат вызова команды myplotchar(a1):
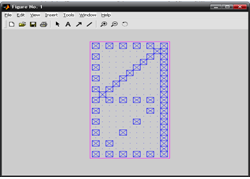
Рис.19 Результат вызова команды myplotchar(a1)
4) Создается программа, генерирующая описанную выше нейронную сеть и обучающая ее.
Содержимое m-файла letter. m:
[R, Q]=size(chisla); % берем размерности массива чисел R=231, Q=10
[S2,Q]=size(target); %S2- количество вариантов: 10 распознаваемых чисел
S1=231; % в первом слое должно быть столько нейронов, сколько пикселей в подаваемом изображении
Net=newff(minmax(chisla),[S1 S2],{'logsig' 'purelin'},'traingdx'); % %minmax(chisla) определит минимальное и максимальное число в %каждой строке. Поскольку у нас только черный и белый цвет в %изображениях цифр, минимальное число подаваемое на вход сети - 0, %максимальное - 1.
Net. LW{2,1}=net. LW{2,1}*0.01;
Net. b{2}=net. b{2}*0.01;
Gensim(net) %генерируем сеть
P=chisla; % входные сигналы обучающей выборки
T=target; % ожидаемые выходные сигналы
Net. performFcn='sse';
Net. trainParam. goal=0.01; % требуемая ошибка обучения
Net. trainParam. show=20;
Net. trainParam. epochx=5000; % количество тактов обучения
Net. trainParam. mc=0.95;
[net, tr]=train(net, P, T); % запуск процесса обучения
Далее следует набрать в командной строке matlab команду letter.
>>letter
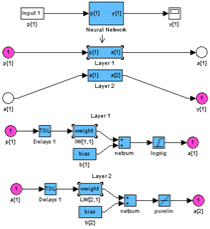
Рис. 20 Модель полученной сети
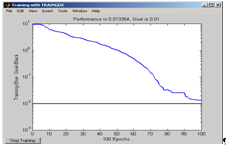
Рис. 21 График процесса обучения нейронной сети
5) Следует проверить насколько уверенно построенная нейронная сеть распознает примеры из обучающей выборки (команда sim (<имя сети>,<имя примера>)):

Рис. 22 Результаты работы сети по распознаванию примеров из обучающей выборки
Сеть уверенно распознает символы.
6) Следует проверить способность распознавания сетью зашумленных символов.
>> simvol=chisla(:,1)+randn(231,1)*0.2; % создаем символ, %зашумленный на 20%
>> myplotchar(simvol) % нарисуем его
Рис. 23 Вид зашумленного символа "0"
>> rez=sim(net, noisyJ)
Rez =
- 0.9161 -0.0745 0.0615 0.0218 0.0713 0.0061 -0.0039 0.0102 0.0453 0.0233
Сеть распознала символ "0".
Похожие статьи
-
Знакомство с нейронными сетями Цель работы Ознакомление со структурой нейронных сетей. Получение навыка программирования нейронных сетей. Теоретическое...
-
Написать программу на С++ моделирующую двухслойную нейронную сеть структуры согласно варианту, указанному в таблице 4. Таблица 4 Варианты заданий для...
-
Деревья решений - общие принципы работы Цель работы Изучить принцип построения деревьев решений и построить дерево решений на основе имеющейся выборки...
-
Построить дерево решений. Для этого необходимо: А) запустить программу deductor studio academic. Б) провести импорт статистики в программу, вызвав...
-
В связи с увеличением числа сотрудников, работающих в компании, а также с расширением рабочего проекта, возникла проблема, связанная с версионностью...
-
Изучение возможностей экспертных систем Цель работы Целью является проектирование и разработка фрагмента экспертной системы. Теоретическое введение...
-
Введение - Интеллектуальные информационные системы
Чаще всего искусственным интеллектом, или ИИ (Artificial Intelligence - AI), называют процесс создания машин, которые способны действовать таким образом,...
-
Введение - Поверка и калибровка информационно измерительных систем
На сегодня метрологическая деятельность регулируется Законом Российской Федерации "Об обеспечении единства измерений". Из этого следует, что эта...
-
Системы автоматизированного проектирования - Теоретические основы информационных технологий
Близкими по своей структуре и функциям к системам автоматизации научных исследований оказываются системы автоматизированного проектирования (САПР). САПР...
-
Прием и передача информации по сети - Теоретические основы информационных процессов и систем
Пересылка данных в вычислительных сетях от одного компьютера к другому осуществляется последовательно, бит за битом. Физически биты данных передаются по...
-
Цель Работы - научиться использовать элемент управления ListBox а также основные методы класса СListBox. Использование возможности контроля правильности...
-
Цель Работы - изучить приемы создания и использования шаблонов классов. - Теоретические сведения Достаточно часто встречаются классы, объекты которых...
-
Объект ориентированный класс программирование Цель Работы - изучить методику создания одномерных динамических символьных массивов при помощи...
-
Цель Работы - изучить основные способы работы с пользовательским типом данных "класс", его объектами, методами и способы доступа к ним. - Теоретические...
-
Основная цель системы ДИСКОР - совершенствование оперативного управления работой железных дорог на основе более эффективного использования пропускной...
-
В рамках выпускной квалификационной работы была разработана автоматизированная информационная система, предназначенная как для автоматического, так и для...
-
Введение - Корпоративные информационные системы
Актуальность работы. Внедрение корпоративной информационной системы на предприятии любого размера и профиля деятельности дает предприятию следующие...
-
Введение, Правила и порядок выполнения курсовой работы - Программирование в среде Turbo Pascal
Настоящие методические указания предназначены для выполнения курсовой работы "Расчеты на ЭВМ характеристик выходных сигналов электрических цепей" по...
-
Наименование программы Полное наименование программы - Модуль ипотечного кредитования банковской информационной системы "БИС". Краткое наименование...
-
Наименование и область применения Наименование: Автоматизированная информационная система "Отель" в дальнейшем именуемая АИС "Отель". Область применения:...
-
Классификация компьютерных сетей - Теоретические основы информационных процессов и систем
Для классификации компьютерных сетей используются разные признаки, выбор которых заключается в том, чтобы выделить из существующего многообразия такие,...
-
Современные табличные процессоры имеют очень широкие функциональные и вспомогательные возможности, обеспечивающие удобную и эффективную работу...
-
Из универсальных языков программирования сегодня наиболее популярны следующие: Бейсик (Basic), Паскаль (Pascal), Си++ (C++), Ява (Java). Для каждого из...
-
Геоинформационные системы и технологии - Теоретические основы информационных технологий
Геоинформационные системы (ГИС) и ГИС - технологии объединяют компьютерную картографию и системы управления базами данных. Концепция технологии ГИС...
-
Информатика - в настоящее время одна из фундаментальных областей научного знания, формирующая системно-информационный подход к анализу окружающего мира,...
-
Цель Работы - изучить принципы работы элементов управления Progress и Slider. Получить навыки по самостоятельному созданию модальных диалоговых окон. -...
-
Инфологическое проектирование Стандартным способом представления концептуальной модели базы данных являются диаграммы "сущность-связь" (ERD),...
-
Алгоритм работы. В результате работы АИС генерируются три xml документа - два со структурой сравниваемых баз данных и один с результатами сравнения. В...
-
Цель Работы - изучить одну из базовых концепций ООП, наследование классов в С++, заключающуюся в построении цепочек классов, связанных иерархически,...
-
Введение, Медицинские информационные системы - Информационные медицинские системы
В медицине, как в фокусе, концентрируется множество различных проблем. В первую очередь это касается гетерогенных источников информации, где нет единства...
-
Введение - Информационная система Вуза
Одним из важнейших условий обеспечения эффективного функционирования любой организации является наличие развитой автоматизированной информационной...
-
Сегодня положение дел в рассматриваемой области характеризуется крайней неопределенностью. Во-первых, это связано с непрерывным увеличением объема...
-
Для написания АИС использовались следующие языки программирования, программные средства и библиотеки: - Язык программирования PHP 5.4; -...
-
Работа со звуковой системой ПК. Вычисление информационного объема закодированного звука
Практическое занятие Работа со звуковой системой ПК. Вычисление информационного объема закодированного звука Цель работы: Ознакомиться с компьютерными...
-
Введение - Разработка справочной информационной системы "Рецепты"
Задание курсовой работы. Разработать и отладить информационную справочную систему "Рецепты", которая будет позволять хранить, выводить на экран,...
-
Введение - Разработка программного модуля ипотечного кредитования банковской информационной системы
Модуль создается в целях автоматизации ипотечного кредитования. Основными задачами разработки программного модуля являются автоматизация следующих...
-
Основные термины теории баз данных - БД (База данных) - совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы...
-
"РЕШЕНИЕ ЗАДАЧ ЛИНЕЙНОГО ПРОГРАММИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ MICROSOFT EXCEL" Цель работы Приобретение навыков решения задач линейного программирования...
-
Для обновления сайта от Филиала предоставляется новая информация, фото и медиа файлы, которые нужно заменить на какой-либо из страниц. Замена...
-
Запросы - Разработка информационной системы "Гостиница"
Одним из семи стандартных объектов Microsoft Access является запрос. Запросы используются для просмотра, анализа и изменения данных в одной или...
Лабораторная работа №4, Цель работы, Теоретическое введение - Интеллектуальные информационные системы