Два подхода к хранилищам данных - Разработка объектов Хранилища
На сегодняшний день существует два основных подхода к моделям Хранилищ данных. Это так называемая корпоративная информационная фабрика Билла Инмона и Хранилище данных с архитектурой шины Ральфа Кимбалла[3].
В обоих подходах есть общие моменты, в которых оба автора соглашаются друг с другом[8]. Во-первых, безусловно то, что практически любая организация только выиграет от создания хранилища данных для принятия решений. Ни одна организация не сможет существовать без полностью функционирующей OLTP системы. Точно так же нужны и дополнительные аналитические системы, которые дополняют OLTP.
Во-вторых, целью любого хранилища является хранение "правильной" информации, к которой несложно получить доступ людям, ответственным за принятие решений. Два основных компонента этой среды - подготовка данных и ее представление. Процесс подготовки информации состоит из ETL процессов и процессов технической поддержки. После того, как вся необходимая информация была собрана, она загружается в область презентации данных, где возможен ее последующий анализ, создание отчетов и ее использование в различных аналитических приложениях.
Так же, оба подхода говорят о том, что при разработке хранилища необходимо охватить взглядом всю систему целиком. И не смотря на то, что система будет внедряться по частям, важно видеть конечную цель на этапе планирования.
И наконец, оба автора соглашаются в том, что подход, при котором различные хранилища и витрины разрабатываются отдельно и независимо друг от друга заранее неправильный. Такой подход может быть выигрышным в краткосрочном периоде, но в долгосрочном он приведет к многочисленным дублированиям и некорректности данных.
А теперь будут рассмотрены основные различия этих подходов.
Корпоративная информационная фабрика
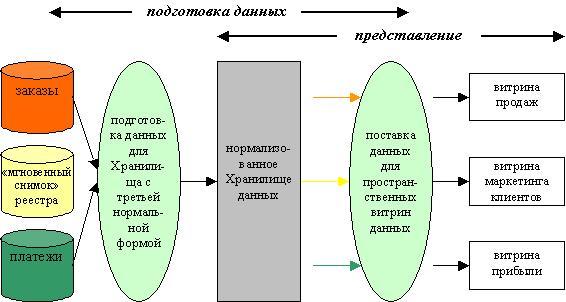
Рисунок 1. Корпоративная информационная фабрика
Как видно из рисунка, разработка данного хранилища начинает со скоординированного извлечения данных из существующей OLTP системы. После этого, данные загружаются в реляционную базу данных с третьей нормальной формой. Получившееся нормализованное Хранилище используется для того, чтобы наполнить информацией витрины данных, т. е. данных, подготовленных для анализа.
При таком сценарии конечные витрины данных создаются для обслуживания бизнес-отделов или для реализации бизнес-функций и используют пространственную модель для структурирования суммарных данных. Атомарные данные тем не менее остаются доступными через нормализованное Хранилище данных.
Итак, отличительные характеристики подхода [10]:
Использование реляционной модели организации атомарных данных и пространственной - для организации суммарных данных.
Использование итеративного или "спирального" подхода при создании больших Хранилищ данных, т. е. "строительство" Хранилища не сразу, а по частям. Это позволяет при необходимости вносить изменения в небольшие блоки данных или программных кодов и избавляет от необходимости перепрограммировать значительные объемы данных в Хранилище.
В хранилище используется третья нормальная форма для атомарных данных, что обеспечивает высокую степень детальности интегрированных данных и, соответственно, предоставляет корпорациям широкие возможности для манипулирования ими и изменения формата и способа представления данных по мере необходимости.
Хранилище данных - является целым физическим объектом, а не коллекцией витрин данных.
В данном подходе хранилище данных сразу проектируется так, чтобы удовлетворять потребности сразу всех отраслей компании, например маркетинг и продажи. Хранилище создается как единое целое, и витрина данных является не более, чем финальным этапом визуализации всей информации для пользователя.
Основные плюсы данного подхода:
Достаточно простая реализация хранилища, так как существующая OLTP система обычно тоже нормализована.
Быстрая доработка витрин данных
Основным минусом является достаточно долгий срок разработки хранилища (от года).
Данный подход применим скорее для очень крупных организаций.
Хранилище данных с архитектурой шины
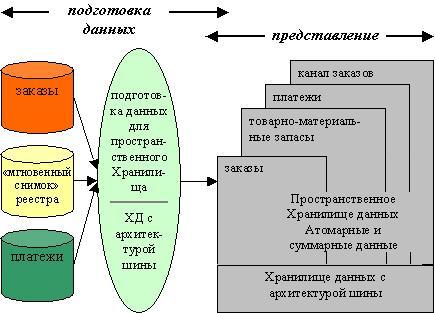
Рисунок 2. Хранилище данных с архитектурой шины
В данной модели, как и в предыдущей, первичные данные преобразуются в информацию, пригодную для использования, на этапе подготовки данных. Ключевым факторами при разработке процесса загрузки являются требования к скорости обработки информации и качеству данных.
В данном подходе вместо централизованного нормализованного хранилища используется множество витрин данных, каждая из которых спроектирована с архитектурой "звезда" или "снежинка".
Хранилище данных не является единым физическим репозиторием (в отличие от подхода Билла Инмона)[9]. Это "виртуальное" Хранилище. Это коллекция витрин данных. В данном подходе каждая витрина данных проектируется отдельно и не особо зависит от остальных. Все витрины соединяются "шиной". Такое хранилище содержит точно такую же информацию как и нормализованное, но она по-особому структурирована для более удобной работы с конечными данными.
Хранилище данных с архитектурой шины обладает следующими характеристиками[10]:
Оно пространственное
Оно включает как данные о транзакциях, так и суммарные данные
Оно включает витрины данных, посвященные только одной предметной области или имеющие только одну таблицу фактов
Оно может содержать множество витрин данных в пределах одной базы данных.
Главное достоинство данной методологии это скорость создания витрин. Первая рабочая витрина может быть создана за пару месяцев и будет полностью функциональной. Основной недостаток может возникнуть, после многочисленных и долгих по времени изменений в хранилище. Вполне вероятно, что после внесений многочисленных изменений, информация будет дублироваться в различных витринах или наоборот одни и те же показатели будут считаться по-разному. Именно поэтому для данного подхода процесс загрузки данных является ключевым и лежит в самой основе. Далее будет дано более подробное описание процесса загрузки данных.
Этот подход больше подходит для малых и средних предприятий, и именно он будет использован в данной работе.
Загрузка и преобразование данных (ETL)
ETL система является основой для хранилища данных. Правильным образом спроектированная ETL система выгружает данные из всех источников, обеспечивает целостность и качество данных, объединяет данные из разных источников так, чтобы их было удобно использовать и, наконец, загружает данные в формате, который подходит для дальнейшей работы с ними на презентационном слое. [6]
Именно от системы загрузки зависит успешность хранилища данных. Несмотря на то, что загрузка происходит в backend и не видна пользователю, работа на ETL системой обычно занимает 70% всего времени разработки хранилища данных.
ETL включает в себя:
Извлечение данных из внешних источников в один, для дальнейшей работы с этими данными
Очистку данных и избавление от возможных ошибок
Сохранение изменений в данных
Структурирование данных для удобства конечных объектов хранилища данных
Загрузку преобразованных данных в целевую систему
Несмотря на кажущуюся простоту, каждый из этапов проекта в реальности достаточно сложен. Во-первых, в качестве внешних источников информации могут выступать различные информационные системы, форматы хранения данных которых и процедуры их извлечения могут существенно разниться. Во-вторых, ETL-процесс не сводится исключительно к техническому преобразованию форматов -- данные из разнородных источников должны быть унифицированы и с точки зрения бизнес-правил, единства применяемых систем кодирования информации, классификаторов и справочников. В-третьих, процесс должен учитывать и особенности бизнес-процессов компании, в том числе, функционирования выступающих в качестве источников данных отдельных информационных систем, периодичности обновления данных в них и т. д. [6]
Традиционный процесс ETL представляет собой последовательность шагов, вызываемых в виде пакетного задания. Время цикла процесса ETL ограничивает актуальность данных в хранилище данных; трудно добиться, чтобы это время было меньше нескольких минут. Например, большая часть шагов, требующих переработки большого объема данных, выполняется на основе запросов к хранилищу данных: поиск существующих значений в таблице измерений (например, клиентов, совершивших предыдущую покупку) и заполнение сводных таблиц. Система обработки запросов к потоковым данным может кэшировать информацию, требуемую для выполнения этих шагов, снимая излишнюю нагрузку с хранилища данных, в то время как процесс ETL является слишком кратковременным, чтобы в нем было выгодно производить кэширование.
Во время разработки ETL системы необходимо держать в голове сразу два параллельных процесса: планирование и дизайн, и работа с данными. [6]
Процесс планирования и дизайна в общем виде состоит из четырех этапов и может быть представлен следующим образом:

Рисунок 3. Планирование и дизайн
На первом этапе происходит сбор всех существующих требований к системе и оценка возможности их выполнения. На втором этапе разрабатывается непосредственно архитектура процесса загрузки. Третий этап состоит из реализации полученной схемы и последний этап это тестирование получившейся системы и ее внедрение.
Работа с данными происходит в виде последовательности различных потоков данных (Data Flow). Она так же может быть представлена в виде четырех основных этапов и в целом отражает сам процесс ETL.
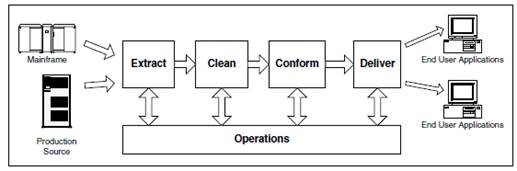
Рисунок 4. Потоки данных
На первом этапе происходит выгрузка данных из существующих источников. На втором этапе данные очищаются - проверяются на наличие ошибок или пропусков. На этом этапе все данные проходят процедуру подтверждения их правильности и соответствия бизнес-требованиям. Далее, происходит интеграция информации из несовместимых источников, так чтобы все одинаковые поля назывались одинаково, и все поля с одинаковым названием означали одно и то же. И на последнем этапе эти данные загружаются в конечное хранилище.
Правильное и последовательное выполнение этих процессов приведет к стабильной и быстрой ETL системе, что в свою очередь улучшит качество всего хранилища данных.
Проектирование хранилища данных с архитектурой шины
Ральф Кимбалл (Ralph Kimball), автор данного подхода, описывал хранилище данных как "место, где люди могут получить доступ к своим данным". Он так же сформулировал основные требования к хранилищам данных[5]:
- *Хранилище данных должно сделать информацию об организации легко доступной. Содержимое хранилища данных должно быть понятным. Процесс извлечения информации должен быть интуитивно понятным для бизнес пользователя, а не только для разработчика. Бизнес пользователь будет использовать информацию во всех возможным комбинациях и вариациях (срезы данных). Все инструменты для доступа к данным должны быть простыми в использовании. Время отклика для запросов пользователя так же должно быть минимальным. *Информация, представленная в хранилище должна быть непротиворечивой. Пользователь должен доверять информации. Прежде чем информация попадет в общий доступ, она должна быть аккуратно собрана из всех различных источников, очищена и проверена. Если два показателя означают одно и то же они должны называться одинаково и наоборот. Непротиворечивая информация это информация высокого качества. *Хранилище должно быть легко изменяемым. Невозможно избежать изменений, поэтому хранилище данных должно легко перестраиваться при необходимости. Изменение в хранилище не должно влиять на все работающие приложения. Существующая информация и приложения не должны изменяться, если пользователь задает новые вопросы или добавляет новую информацию. *Информация в хранилище данных должна быть хорошо защищена. В хранилище может храниться крайне деликатная информация. В нем как минимум хранится информация о том что и по каким ценам покупает компания. Это означает, что доступ к информации в хранилище должен быть ограничен. *Хранилище данных должно быть основой для улучшения и ускорения процесса принятия решений. Существует только один важных итог работы хранилища данных: решения которые было принято после того, как были получены данные из хранилища. Именно эти решения и являются ценностью, которую привносит хранилище данных. Лучшее описание того, что мы разрабатываем - это система поддержки принятия решений. *Для того чтобы хранилище данных можно было назвать успешным, оно должно быть принято на всех уровнях компании. Неважно создали ли мы элегантное решение, если оно не используется спустя шесть месяцев после обучения. В отличии от внедрения новой OLTP системы, когда у пользователей просто нет выбора, кроме как пользоваться новой системой, использование хранилища не является обязательным. А это означает, что системой будут пользоваться, только если она проста и удобна.
Для проектирования хранилища данных которые отвечают всем требованиям, представленным выше необходимо продумать основные четыре составляющие[5].
Выбрать бизнес-процесс, который будет моделироваться. Процесс это естественная активность, которая происходит в организации. Ее результаты чаще всего записываются в существующую OLTP систему. Лучший способ выбрать процесс это прислушаться к мнению пользователей. Важно отличать бизнес-процесс от бизнес отдела или функции. Так, например правильно будет спроектировать единую систему для процесса заказа услуг, чем две системы для двух отделов продаж и маркетинга. Такой подход к проектированию позволяет построить единую схему и сделать для нее одну загрузку данных и тем самым избежать дублирования информации. Так же этот подход позволяет снизить затраты на процессы загрузки и представления данных.
Правильно выделить самый нижний уровень детализации, который лежит в основе процесса. Выделение нижнего уровня означает точную формулировку того, что будет подразумеваться под таблицей фактов. Данный шаг процесса проектирования очень легко пропустить, посчитав его слишком очевидным, но этого делать ни в коем случае не стоит. Именно от того, насколько правильно выбрано событие в основе факта зависят дальнейшие возможности по использованию хранилища данных. Может получится так, что на дальнейших шагах проектирования станет понятно, что уровень выбран неправильно. В таком случае, следует еще раз выбрать нижний уровень детализации.
Выбрать все измерения, которые соответствуют факту. Выбор измерений это ответ на вопрос "Как лучше описать данные, полученные в результате бизнес-процесса?". Измерения это подробные описания каждой строчки, которая входит в факт.
Выделить количественные показатели, которые будут привязаны к каждой строке в таблице фактов. Факты легко выделить отвечая на вопрос "Что мы измеряем?". Именно эти значения чаще всего интересны бизнес-пользователям в процессе принятия решений. Важно то, что все выбранные показатели должны подходить под элементарное событие, которые мы выбрали на втором шаге.
Итак, в данной главе были рассмотрены основные понятия области хранилищ данных, были рассмотрены основные подходы к проектированию хранилищ данных и выбранный подход был рассмотрен более подробно. Этого достаточно для того, чтобы перейти к проектированию и разработке хранилища данных.
Похожие статьи
-
Введение - Разработка объектов Хранилища
Ни для кого не секрет, что проблема хранения и обработки информации является одной из самых важных на данный момент во всем мире. Особенно актуальной эта...
-
Основные понятия баз данных. Цели использования баз данных - Разработка базы данных
В широком смысле слова база данных (БД) - это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Для удобной...
-
Ключевые понятия - Разработка объектов Хранилища
База данных - представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений и иных...
-
Теоретические предпосылки исследования Системы поддержки принятия решений Системы поддержки принятия решений (СППР), представляют собой приложения узкого...
-
Организация парольной защиты - Проектирование и разработка базы данных "Прокат автомобилей"
По мере того как деятельность организаций все больше зависит от компьютерных информационных технологий, проблемы защиты баз данных становятся все более...
-
Описание деятельности ИТ-отдела компании в рамках разработки ключевых показателей эффективности является одной из важнейших частей процесса. Однако...
-
Разработка базы данных мониторинга окружающей среды
ВВЕДЕНИЕ Информация о состоянии окружающей природной среды, об изменениях этого состояния давно используется человеком для планирования своей...
-
Хранилище данных - Разработка аналитического приложения
Как система управления базами данных (СУБД) был выбран Microsoft SQL Management Studio. Данная СУБД обладает понятным интерфейсом, она проста в...
-
Общие требования Прежде чем начинать формулировать требования к пользовательскому интерфейсу, было принято решение, что необходимо ознакомиться с...
-
В связи с увеличением числа сотрудников, работающих в компании, а также с расширением рабочего проекта, возникла проблема, связанная с версионностью...
-
Аналитическая часть - Разработка программ преобразования форматов двоичных данных и сортировок
Язык - множество символов и совокупность правил, определяющих способы составления из этих символов осмысленных сообщений. Семантика - система правил и...
-
Архитектура построения баз данных - Разработка базы данных
СУБД имеют свою архитектуру. В процессе разработки и совершенствования СУБД предлагались различные архитектуры, но самой удачной оказалась трехуровневая...
-
Пользовательский интерфейс должен позволять заводить в базе данных информацию о новых охранниках, обслуживаемых объектах, автоматизировать составление...
-
Трансформация данных, Выводы - Разработка аналитического приложения
Процесс трансофрмации в целом соответствует ETL процессу. ETL расшифровывается как "Extract, Transform, Load", что переводится на русский примерно как...
-
Обоснование выбора СУБД База данных - это совокупность сведений о реальных объектах, процессах, событиях или явлениях, относящихся к определенной теме...
-
Разработка концептуальной модели базы данных При проектировании программ выясняются запросы и пожелания клиента и определяется возможный подход к решению...
-
Хранилище данных, Рассмотрение источников данных - Разработка аналитического приложения
Рассмотрение источников данных Данные для работы были взяты с сайта Международного валютного фонда (МВФ). МВФ - это организация, которая состоит из 189...
-
Структура и процесс функционирования системы управления базами данных - Разработка базы данных
СУБД является прикладным программным обеспечением, предназначенным для решения конкретных прикладных задач и выполнения системных функций, расширяющих...
-
Основные термины теории баз данных - БД (База данных) - совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы...
-
Информационная система (ИС) ГИБДД должна обеспечивать хранение информации об автомобилях (марка, номер кузова, номер двигателя, цвет кузова, гос. номер),...
-
Основные конструкции для разработки базы данных - База данных "Кинотеатр"
База данных - это организованная структура, предназначенная для хранения информации. Систему управления базой данных (СУБД) можно определить, как...
-
Структурированное хранилище данных Windows Azure Table - Введение в облачные решения Microsoft
Любое приложение вне зависимости от способа его размещения должно где-то хранить данные. При этом данные могут хранить локально, либо удаленно....
-
2.1. ИСПДн класса К3 Заказчика характеризуются сосредоточенностью на территории занимаемого Заказчиком помещения без подключения к сетям общего...
-
В процессе выполнения дипломной работы было проведено ознакомление с принципами построения баз данных. Мною изучена СУБД "MS SQL Server", которая на...
-
Предложенный подход к решению задач исследования Используя в качестве основы присутствующее в наличии программное обеспечение, которое применимо к...
-
В данной главе представлено описание возможных вариантов совершенствования архитектуры предприятия в части гибкого подключения сторонних систем и их...
-
Защита персональных данных регламентируется Федеральным Законом РФ № 152-ФЗ "О персональных данных", принятым 27 июля 2006 года. Целью настоящего...
-
Интерфейс Пользовательский интерфейс программного обеспечения является неотъемлемой его частью. Именно через интерфейс конечный пользователь будет...
-
Для того чтобы выполнить монтаж видеосистемы, вовсе не надо быть дилетантом, так как самыми сложными инструментами, которые понадобятся в данном случае,...
-
Подход NoSQL - Технологии больших данных: анализ и выбор решения для реализации проекта
Понятие NoSQL означает "Не только SQL" или "Не SQL". Термин получил известность, начиная с 2009 год, когда развитие интернет-технологий и социальных...
-
Типы записей в базе данных DNS-сервера - Компьютерные сети
DNS-сервер, отвечающий за имена хостов в своей зоне, должен хранить информацию о хостах в базе данных и выдавать ее по запросу с удаленных компьютеров....
-
Дипломная работа посвящена проектированию базы данных (БД), а также разработке интерфейса к ней на примере потребностей охранного предприятия ООО...
-
ИИС "Шлаковые расплавы" позволяет вести моделирование КЭ в нескольких "режимах", с полным набором получаемых свойств. 1. Моделирование комплекса свойств...
-
Каждая СУБД имеет особенности в представлении структуры таблиц, связей, определении типов данных и т. д. которую необходимо учитывать при проектировании....
-
Уровни и типы моделей БД - Банки и базы данных. Системы управления базами данных
Любая БД отражает информацию об определенной предметной области. В зависимости от уровня абстракции, на котором представляется предметная область,...
-
В современной технологии баз данных предполагается, что создание базы данных, ее поддержка и обеспечение доступа пользователей к ней осуществляются...
-
"WWWSQLDesigner" позиционируется как абсолютно бесплатный, доступный для пользователей, универсальный веб-редактор, значительно упрощающий процесс...
-
Логический уровень описания базы данных (логическая модель) отражает логические связи между таблицами. Логическая модель базы данных "Прокат автомобилей"...
-
Постановка задачи Составить инфологическую модель базы данных (БД), необходимой для предоставления информации программе расчета предельно-допустимых...
-
Проектирование базы данных было Подробно описано в главе 7. Благодаря графической оболочке MySQL Workbench для MySQL все SQL запросы на создание таблиц...
Два подхода к хранилищам данных - Разработка объектов Хранилища