Синтез речи (TTS - Text-to-Speech). Преобразование произвольной текстовой информации в речь - Кодировщики голоса
Синтез устной речи - это преобразование заранее не известной текстовой информации в речь. Речевой вывод информации - это речевого интерфейса, без которой общение не может состояться. Фактически, благодаря синтезу речи предоставляется еще один канал передачи данных от компьютера, мобильного телефона к человеку, аналогично монитору. Конечно, передать рисунок голосом невозможно, но вот прослушать электронную почту или расписание на день в ряде случаев довольно удобно, особенно если в это время взгляд занят чем-либо другим. Например, придя утром на работу, готовясь к переговорам, Вы могли бы поправлять у зеркала галстук или прическу, в то время как компьютер читает вслух последние новости, почту или напоминает важную информацию для переговоров.
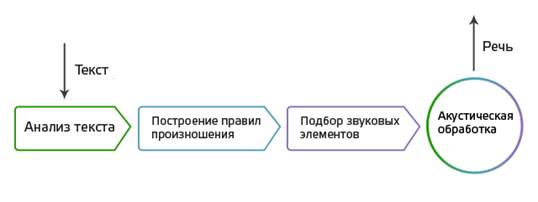
Технология синтеза устной речи нашла широкое применение для людей, имеющих проблемы со зрением. Для всех остальных она создает новое измерение удобства пользования техникой и значительно снижает нагрузку на зрение, на нервную систему, позволяет задействовать слуховую память.
Любой текст состоит из слов, разделенных пробелами и знаками препинания. Произнесение слов зависит от их расположения в предложении, а интонация фразы - от знаков препинания. Наконец, произнесение зависит и от смысла слова! Соответственно, для того чтобы синтезированная речь звучала натурально, необходимо решить целый комплекс задач, связанных как с обеспечением естественности голоса на уровне плавности звучания и интонации, так и с правильной расстановкой ударений, расшифровкой сокращений, чисел, аббревиатур и специальных знаков с учетом особенностей грамматики русского языка.
Существует несколько подходов к решению поставленных задач:
Системы аллофонного синтеза - обеспечивают стабильное, но недостаточно естественное, роботизированное звучание.
Системы, основанные на подходе Unit Selection - обеспечивают гораздо более естественное звучание, однако могут содержать фрагменты речи с резкими провалами качества, вплоть до потери разборчивости.
Гибридная технология, основанная на подходе Unit Selection и дополненная единицами аллофонного синтеза.
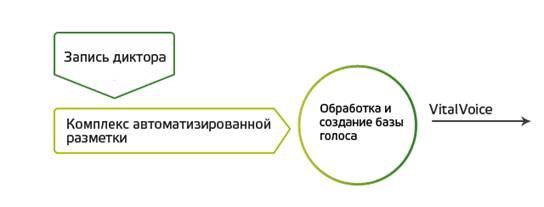
На основе этой технологии была создана система VitalVoice, которая обеспечивает стабильное и естественное звучание на акустическом уровне.
Области применения:
- -Корпоративные решения:
- А) Построение автоматизированных информационно-справочных телефонных систем голосового самообслуживания в Контакт-центрах (СГС - система голосового самообслуживания) Б) Интеграция в корпоративные информационные системы В) Системы оповещения Г) Озвучивание информации, размещенной на сайтах (Голосовой интернет)
- А)Навигационные системы Б)Чтение информации с интернет сайтов (новостные ленты, блоги и т. д.) В)Автоматические переводчики Г)Портативные устройства для людей с ограниченными возможностями по зрению и речи
- А)Чтение электронной почты, быстрый доступ к бизнес информации Б)Программы обучения русскому языку В)Создание аудиокниг Г)Компьютерные игры Д)Интеграция в устройства (терминалы оплаты, автоматические газетные киоски)
- А)Владельцы и разработчики новостных сайтов, а также сайтов с часто обновляемым содержанием Б)Государственные органы, размещающие в сети Интернет сайты, информация которых должны быть максимально доступна всем категория граждан В)Частные компании, чьи сайты нацелены на наибольшую доступность информации о деятельности компании широкой аудитории Г)Компании, заинтересованные в создании и размещении собственных подкастов из неограниченного объема контента без использования дикторов и специальных акустических условий
Похожие статьи
-
Использование в продукция. VitalVoice. Синтез русской речи - Кодировщики голоса
Назначение и области применения: VitalVoice реализует основное требование пользователей к системам синтеза речи: она позволяет озвучить любые, пусть даже...
-
Дискретизация речи с последующим шифрованием (цифровое скремблирование) - Кодировщики голоса
Альтернативным аналоговому скремблированию методом передачи речи в закрытом виде является шифрование речевых сигналов, преобразованных в цифровую форму,...
-
Mobile. Синтез русской речи для мобильных устройств на базе MS Windows Mobile - Кодировщики голоса
Назначение и области применения: VitalVoice Mobile предназначен для автоматического преобразования произвольного текстового файла в речь на мобильном...
-
Новые подходы к защите передачи информации - Кодировщики голоса
Однако с выходом Постановления "Об утверждении положений о лицензировании отдельных видов деятельности, связанных с шифровальными (криптографическими)...
-
Система закрытия речи - Кодировщики голоса
Посредством дискретного кодирования речи с последующим шифрованием всегда достигалась высокая степень закрытия, но в прошлом этот метод не находил...
-
Аналоговое скремблирование - Кодировщики голоса
Наибольшая часть аппаратуры засекречивания речевых сигналов использует в настоящее время метод аналогового скремблирования, поскольку, во-первых, это...
-
Проблемы организации транкинговых систем - Кодировщики голоса
Для организации радиосетей специализированного пользования (имеется в виду категория обслуживаемых абонентов - связь с подразделениями ОВД на транспорте,...
-
Рассмотрим несколько конкретных примеров измерения параметров фильтра в полосных и гомоморфных вокодерах, а также в вокодерах с линейным предсказанием...
-
Формантные вокодеры. Вокодеры с линейным предсказанием (липредеры) - Кодировщики голоса
Вокодеры с линейным предсказанием - липредеры (linear prediction) создают отсчеты звукового сигнала на основе предыдущего отсчета сигнала и вычисленных в...
-
Эта технология находит применение в военных системах связи, в диспетчерских службах, а также в системах пейджерной связи. Разработчики преобразователей...
-
В каждый исторический период жизни общества и, шире - историческую эпоху - человечество вырабатывает и отрабатывает систему передачи информации,...
-
Информация всегда играла в жизни человека большую роль. Однако значимость информации в современном обществе принципиально иная. Дело в том, что...
-
ВВЕДЕНИЕ, Системы визуального отображения информации (видеосистемы) - Внешние устройства ЭВМ
Персональный компьютер (ПК)- это не один электронный аппарат, а Небольшой комплекс взаимосвязанных устройств, каждое из которых выполняет определенные...
-
Клавиатура - основное устройство для ввода информации. - Понятие экспертных систем (ЭС)
Существуют также устройства, облегчающие работу оператора, такие, как мышь, световое перо и пр. Также для ввода информации широко используются сканеры....
-
Характеристики шлюзов IP-телефонии - IP-телефония и традиционные телефонные сети
В общем случае IP-телефония опирается на две основных операции: преобразование двунаправленной аналоговой речи в цифровую форму внутри...
-
Аналого-цифровые преобразователи (АЦП) являются устройствами, которые принимают входные аналоговые сигналы и генерируют соответствующие им цифровые...
-
Введение - Проектирования магистральной волоконно-оптической системы передачи информации
В настоящее время системы связи стали одной из основ развития общества. Рост потребностей в передаче информации привлек к тому что в конце 1990-х годов...
-
МЕЖДУНАРОДНЫЕ СИСТЕМЫ БАЙТОВОГО КОДИРОВАНИЯ - Кодирование информации
Информатика и ее приложения интернациональны. Это связано как с объективными потребностями человечества в единых правилах и законах хранения, передачи и...
-
Принципы пакетной передачи речи - IP-телефония и традиционные телефонные сети
"Классические" телефонные сети основаны на технологии коммутации каналов, которая для каждого телефонного разговора требует выделенного физического...
-
Места формирования и потребления информации - Логистические системы и логистическая стратегия
Прежде всего, на наш взгляд, следует отметить тот факт, что управление функциями глобального распределения, а также потоком материалов и информации...
-
Анализ характеристик объекта проектирования трудовой деятельности человека, производственной среды Фотоприемное устройство является модулем приемной...
-
Метод временного мультиплексирования (TDM) Суть TDM: процесс передачи разбивается на ряд временных циклов, каждый из которых в свою очередь разбивается...
-
Для активной защиты речевой информации от необнаруженных закладных устройств и съема по другим каналам используется аппаратура активной защиты:...
-
Способы осуществления атак. - Пути реализации угроз компьютерной информации
Реализация угроз компьютерной информации может осуществляться как: А - непосредственное несанкционированное воздействие на информационные ресурсы в...
-
Термином оптимальный синтез определяют процесс построения устройства с заданными свойствами, оптимально учитывающий совокупность технико-экономических...
-
ЛИТЕРАТУРА - Аналого-цифровые преобразователив системах передачи и преобразования информации
Лидовский В. И. Теория информации. - М., "Высшая школа", 2002г. - 120с. Метрология и радиоизмерения в телекоммуникационных системах. Учебник для ВУЗов. /...
-
Параллельные АЦП - Аналого-цифровые преобразователив системах передачи и преобразования информации
АЦП этого типа осуществляют квантование сигнала одновременно с помощью набора компараторов, включенных параллельно источнику входного сигнала. На рис. 3...
-
Анализируя исходные данные технического задания: скорость передачи 10 Гбит/с и л=1550 нм, можно сделать вывод, что система передачи подходит под уровень...
-
В результате сравнения производителей систем передач были выбраны две наиболее подходящие это система Cisco ONS 15808 и система ПУСК, выпущенная в России...
-
Выбор оборудования WDM Обзор аппаратуры фирм, выпускающих оборудование DWDM. Tехнология DWDM (Dense Wavelength Division Multiplexing) обеспечивает...
-
Для сетей доступа разработаны оптические волновые коммутаторы и маршрутизаторы. Основой этих устройств являются волновые конверторы: л-конверторы,...
-
КОДИРОВАНИЕ ИНФОРМАЦИИ., АБСТРАКТНЫЙ АЛФАВИТ - Кодирование информации
АБСТРАКТНЫЙ АЛФАВИТ Информация передается в виде сообщений. Дискретная информация записывается с помощью некоторого конечного набора знаков, которые...
-
Практика коммерческой эксплуатации сотовых сетей связи почти всех без исключения операторов России, вне зависимости от видов стандартов, особенно в...
-
Исходными данными для разработки геометрической информации являются: - сборочные и детальные чертежи самолета (изделия); - электронные геометрические...
-
Кодирование и передача информации - Характеристика изделия 9C467-2
Сопряжение КСА с РЛС и ПРВ осуществляется с помощью устройства коммутации сигналов "СССП" УКМ (коробка КР14), устройства коммутации и усиления...
-
Обработка информации - Характеристика изделия 9C467-2
Обработка РЛИ аппаратурой изделия 9С467-1м заключается в том, что по сигналам, поступающим от сопрягаемых РЛ средств, определяются параметры движения СЦ....
-
Устройство числового программного управления 2Р22, именуемое в дальнейшем "устройство", предназначено для управления металлообрабатывающими станками. По...
-
Системы исчисления - Кодирование информации в микропроцессорных системах
Любое неотрицательное число в позиционной системе счисления может быть представлено в виде: Где А - основание системы счисления, Х I - разряды (числа от...
-
ПОНЯТИЕ О ТЕОРЕМАХ ШЕННОНА - Кодирование информации
Ранее отмечалось, что при передаче сообщений по каналам связи могут возникать помехи, способные привести к искажению принимаемых знаков. Так, например,...
-
Разработка протокола обмена информацией и форматов сообщений - Радиосистема пожарной сигнализации
В системе, содержащей несколько устройств, для обмена информацией необходимо составить протокол обмена, который определяет очередность установления связи...
Синтез речи (TTS - Text-to-Speech). Преобразование произвольной текстовой информации в речь - Кодировщики голоса