Упорядочение и классификация объектов с противоречивыми признаками
Упорядочение и классификация объектов с противоречивыми признаками
Мультимножество или множество с повторяющимися элементами служит удобной математической моделью для представления объектов, которые характеризуются многими разнородными (количественными и качественными) признаками и могут существовать в нескольких экземплярах с отличающимися, в частности, противоречивыми значениями признаков. В работе рассматриваются новые методы упорядочения и классификации таких многопризнаковых объектов, основанные на теории метрических пространств мультимножеств. Методы применены для решения практических задач: построения рейтинга компаний и конкурсного отбора проектов, оцененных несколькими экспертами по многим критериям.
В проблемах многокритериального принятия решений, распознавания образов, классификации, обработки разнородной информации, теории кодирования других предметных областях часто возникает необходимость сгруппировать или упорядочить анализируемые объекты, основываясь на их свойствах, выраженных признаками (атрибутами) объектов. Вместе с тем имеется достаточно широкий круг задач, где изучаемые объекты характеризуются многими разнородными признаками, которые могут быть и количественными, и качественными, и, кроме того, одни и те же объекты могут существовать в нескольких экземплярах с отличающимися значениями признаков, свертка которых или невозможна, или математически некорректна. В качестве примеров таких задач укажем классификацию и ранжирование объектов, оцененных несколькими экспертами по многим качественным критериям, распознавание графических символов, обработку текстовых документов. Множественность и повторяемость факторов, описывающих объекты, усложняет и затрудняет решение таких задач. Главные трудности обусловлены необходимостью одновременно учитывать большое количество вербальных и числовых данных и обрабатывать эти данные, не прибегая к дополнительным преобразованиям типа усреднения, смешивания, взвешивания, которые могут привести к необоснованным и необратимым искажениям исходных данных.
Удобной математической моделью для представления многопризнаковых объектов является мультимножество или множество с повторяющимися элементами. Кратность элементов - существенная особенность мультимножества, позволяющая отличать его от множества и рассматривать мультимножество как качественно новое математическое понятие. В работе предложены методы упорядочения и классификации совокупности многопризнаковых объектов, которые базируются на теории метрических пространств мультимножеств. Метод упорядочения объектов основан на оценке их близости по отношению к некоторому "идеальному" объекту в многопризнаковом пространстве. Метод классификации объектов позволяет строить обобщенное решающее правило для их отбора, которое аппроксимирует различные, в том числе и противоречивые, правила экспертной сортировки объектов.
Способы представления многопризнаковых объектов. Выбор той или иной модели для представления рассматриваемых объектов и исследования структуры их связей определяется свойствами этих объектов, которые выражаются признаками (атрибутами) объектов. Признаки, характеризующие свойства объектов, могут быть непрерывными и дискретными, количественными и качественными, или смешанными.
Обычно совокупность объектов представляется множеством точек в некотором многомерном (как правило, метрическом) пространстве, оси которого соотносятся с соответствующими признаками. В прикладных задачах в качестве такого пространства достаточно часто (но, заметим, не всегда обоснованно) выбирается пространство типа евклидового. Задание расстояния между объектами позволяет оценивать близость или удаленность этих объектов относительно друг друга вне зависимости от их природы, исследовать структурные особенности совокупности объектов и всего пространства в целом.
В различных предметных областях рассматриваются совокупности A ={A1,...,AK} объектов, которые описываются M дискретными признаками Q1,...,QM, имеющими конечное число, ES=1,...,HS, S=1,...,M количественных (числовых) или качественных (номинальных, либо порядковых) значений. Каждый объект AI, I=1,...,K из совокупности A можно представить как точку QI в M-мерном векторном пространстве Q=Q1Q2...QM, являющемся прямым произведением шкал значений признаков QS, и поставить объекту AI в соответствие M-мерный вектор AI =(,,...,) [1], [2], [3], [4].
Ситуация существенным образом усложняется, если одному и тому же объекту AI может соответствовать не один, а несколько M-мерных векторов с различающимися значениями признаков. Подобная ситуация возникает, например, когда необходимо одновременно учесть M параметров объекта AI, измеренных N различными способами, либо когда объект AI оценивается N независимыми экспертами по m критериям. В таком случае объект AI представляется в M-мерном пространстве Q уже не одной точкой QI, а группой ("облаком"), состоящей из N точек {QI(1),...,QI(N)} вида
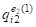
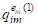

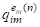
AI={(,,...,),...,(,,...,)}

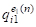
Которая должна рассматриваться и анализироваться как единое целое. При этом, очевидно, измеренные разными способами значения параметров, как и индивидуальные оценки экспертов, могут быть похожими, различающимися и даже противоречивыми, что в свою очередь может приводить к несравнимости M-мерных векторов
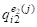
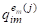
QI(J)=(,,...,)
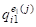
Характеризующих один и тот же объект AI.
Совокупность таких многомерных объектов может иметь в пространстве Q сложную структуру, достаточно трудную для анализа. Непросто ввести в этом пространстве и метрику для измерения расстояний между объектами. Указанные трудности можно преодолеть, воспользовавшись иным способом представления многопризнаковых объектов, основанным на формализме мультимножеств [5], [6], который позволяет одновременно учесть все комбинации значений количественных и качественных признаков, а также число значений каждого из этих признаков. Вместо прямого произведения M шкал значений признаков Q=Q1Q2...QM введем обобщенную шкалу признаков - множество G=Q1,Q2,...,QM, состоящее из M групп признаков, и представим объект AIA в таком символическом виде:
AI = {kAi(q11)*q11,...,kAi()*,...,kAi(qM1)*qM1,..., kAi()*} (1)
Где число KAi() указывает, сколько раз признак QS встречается в описании объекта AI, знак * обозначает кратность вхождения признака. Например, при многокритериальной оценке объекта AI несколькими экспертами число KAi() равно числу экспертов, давших объекту AI оценку по критерию QS. Объект AI можно записать и более единообразно как AI={KAi(X1)*X1,...,KAi(XH)*XH}, определив элементы множества G={X1,...,XH} следующим образом:
X1=Q11,X2=Q12,...,=
=Q21,...,=,...,
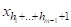
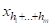
=QM1,...,=
Где H=H1+...+HM. Множество G определяет свойства совокупности объектов A ={A1,...,AK}. Такие объекты AI суть множества с повторяющимися элементами XJG или мультимножества, и их можно представлять точками в метрических пространствах мультимножеств.
Мультимножества и операции над ними. Дадим краткий обзор теории мультимножеств и метрических пространств мультимножеств [5], [6]. Мультимножеством A, порожденным обычным множеством U={X1,X2,...}, все элементы которого различны, называется совокупность групп элементов вида
А={KA(Х)*X|XU, KA(Х)Z+}
Здесь KA:UZ+={0,1,2,...} называется функцией числа экземпляров мультимножества, определяющей кратность вхождения элемента XIU в мультимножество А, что обозначено символом *.
Если
KA(X)=A(X)
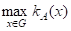
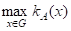
Где A(Х)=1 при XА и A(Х)=0 при XА, то мультимножество А становится обычным множеством. Если все мультимножества семейства A ={A1,A2,...} образуются из элементов множества G, то G называется доменом для семейства A , а множество SuppA={X|XG, SuppA(Х)=А(Х)} - опорным множеством или носителем мультимножества А. Мощность мультимножества |А|=XKA(Х) определяется как общее число экземпляров всех его элементов; размерность мультимножества /А/=XA(Х)=|SuppA| - как общее число различных элементов. Максимальное значение функции кратности hgtA= называется высотой, а элемент XA*=arg - пиком мультимножества А. Мультимножество называется пустым, если K(X)=0, и максимальным Z, если
KZ(Х)=KA(Х), XU
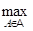
Рассмотрим возможные способы сопоставления мультимножеств, обусловленные особенностями их различных характеристик. Мультимножества А и В называются равными (А=В), если KA(Х)=KB(Х) для всех элементов XG, и неравными (АВ), если KA(Х)KB(Х) хотя бы для одного ХG. Для равных мультимножеств имеем |А|=|В|, /A/=/B/, hgtA=hgtВ, XA*=XB*, SuppA=SuppB. Мультимножества А и В будем называть равномощными, если |А|=|В|; равноразмерными, если /A/=/B/; равновеликими, если они равномощны и равноразмерны. Равные мультимножества равновелики, обратное утверждение, вообще говоря, неверно.
Будем говорить, что мультимножество В содержится или включено в мультимножество А (ВА), если KВ(Х)KА(Х), для каждого элемента XG. Мультимножество В называется тогда подмультимножеством мультимножества А, а мультимножество А - надмультимножеством мультимножества В. В этом случае |В||А|, /В//А/, hgtВHgtА, SuppBSuppA, а XA*=XB*, либо XA*?XB*. Как и в случае обычных множеств, одновременное выполнение условий ВА и АВ влечет равенство мультимножеств А=В. Включение мультимножества обладает свойствами рефлексивности (AА) и транзитивности (АВ, ВC АC), а значит, является отношением предпорядка.
Мультимножества А и В будем называть одноименно или S-эквивалентными (АВ), если их носители совпадают (SuppA=SuppB) и существует взаимно однозначное соответствие F между одноименными компонентами: KВ(Х)=F(KА(Х)), X G; разноименно или D-эквива-лентными (АВ), если их носители эквивалентны (SuppA~SuppB) и существует взаимно однозначное соответствие F между разноименными компонентами:
KВ(ХI)=F(KА(ХJ)), XI,xJG
Где F - целочисленная функция с областью значений Z+. S- и D-эквивалентные мультимножества равноразмерны /В/=/А/, их мощности и высоты связаны равенствами |В|=F(|А|), hgtВ=F(hgtА). Одно из S-эквивалентных мультимножеств всегда является подмультимножеством другого, а для D-эквивалентных мультимножеств это утверждение не выполняется. D-эквивалентные мультимножества становятся S-эквивалентными, если в одном из мультимножеств переобозначить элементы XIXJ. Частными случаями S-эквивалентности будут равные мультимножества; сдвинутые мультимножества, для которых KВ(Х)=KА(Х)+P, P0 - целое; растянутые или пропорциональные мультимножества, для которых KВ(Х)=QkА(Х), Q1 - целое. Важным частным случаем D-эквивалентности являются равносоставленные мультимножества, чьи разноименные компоненты равны kA(ХI)=KB(ХJ), XI,xJG. Равные мультимножества равносоставлены, обратное утверждение неверно.
Введем следующие основные операции над мультимножествами:
Объединение AB = {KAB (X)*X | KAB (X)=Max(KA(X), KB(X))};
Пересечение AB = {KAB (X)*X | KAB (X)=Min(KA(X), KB(X))};
Арифметическое сложение A+B = {KA+B(X)*X KA+B(X)=KA(X)+KB(X)};
Арифметическое вычитание AB = {KAB(X)*X KAB(X)=KA(X)KA?B (X)};
Симметрическая разность AB = {KAB(X)*X KAB(X)=|KA(X)KB(X)|};
Дополнение = ZA = *X =KZ(X)KA(X);
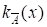
Умножение на число (репродукция) H*A = {KH*A(X)*X KH*A(X)=HkA(X), HZ+};
Арифметическое умножение А*В = {KА*В(X)*X KА*В(X) = KA(X)KB(X)};
Арифметическая П-ая степень АП = {*X = (KA(X))П};
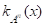
Прямое произведение AB = {KAB*XI, XJ KAB=KA(XI)KB(XJ), XIA, XJB};
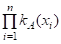
Прямая П-ая степень (A)N = {*X1,...,XП | =, XIA}.
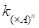
Носители операций над мультимножествами определяются следующими выражениями:
Supp(AB) = Supp(A+B) = (SuppA)(SuppB);
Supp(AB) = Supp (А*В) = (SuppA)(SuppB);
Supp(AB) = (Supp(AB))(Supp(BА));
(SuppA)(SuppВ) = (SuppASuppВ)(SuppВSuppА);
Supp(H*A) = SuppA = Supp(АП);Supp(AB) = (SuppA)(SuppB).
В теории множеств операции арифметического сложения, умножения на число, арифметического умножения и возведения в степень множеств в общем случае не определяются. Аналогами этих операций могут служить соответственно покомпонентное сложение и умножение на скаляр векторов
A+B=(A1+B1,...,AN+BN), HA=(Ha1,...,HaN)
И матриц
А+В=||AIj+BIj||Mn, HА=||H aIj||Mn
Поэлементное умножение матриц АВ=||AIjBIj||Mn. Последняя операция, введенная в алгебраической теории распознавания образов [7], отличается от традиционной операции умножения матриц. При переходе к множествам арифметическое умножение и возведение в степень мультимножеств вырождаются в пересечение множеств, а арифметическое сложение множеств и умножение множества на число будут неосуществимы.
Семейство мультимножеств, замкнутое относительно операций объединения, пересечения, сложения и дополнения, называется алгеброй мультимножеств L (Z), где максимальное мультимножество Z является единицей алгебры, а пустое мультимножество - нулем. Действительная неотрицательная функция M(A), определенная на алгебре L (Z) и удовлетворяющая условию коаддитивности: M(A)+M(B)=M(A+B), называется мерой мультимножества. Мера мультимножества m(A) обладает следующим свойствами: M()=0; монотонность M(A)M(B)AB; непрерывность M(AI)=M(AI); симметричность M(A)+M()=M(Z); эластичность M(H*A)=Hm(A). Меру мультимножества можно определить различными способами, например, как линейную комбинацию функций кратности: M(A)=JWJKA(XJ), WJ>0. Заметим, что мощность мультимножества A также будет мерой мультимножества
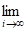
Метрические пространства мультимножеств (A, d) введены в [5], где определены следующие виды расстояний между мультимножествами:
D1(A, B) = m(AДB); D2(A, B) = m(AДB)m(Z); D3(A, B) = m(AДB)m(AB). (2)
Функции D2(A,B) и D3(A,B) удовлетворяют условию нормировки 0D(A,B)1. По определению принимается D3(,)=0. Основное расстояние D1(A,B) является метрикой типа Хемминга, традиционно используемым во многих приложениях. Полностью усредненное расстояние D2(A,B) характеризует различие между двумя мультимножествами A и B, отнесенное к расстоянию, максимально возможному в исходном пространстве. Локально усредненное расстояние D3(A,B) задает различие, отнесенное к максимально возможной "общей части" только этих двух мультимножеств в исходном пространстве.
Построение рейтинга компаний. Одним из весьма распространенных подходов к структуризации совокупности объектов A ={A1,...,AK} является их строгое или нестрогое упорядочение, которое представляет собой введение между объектами бинарных отношений строгого или нестрогого порядка, эквивалентности или несравнимости, заданных на множестве свойств объектов. Сравнение объектов по их свойствам производится на основе признаков, характеризующих объекты.
Рассмотрим достаточно часто встречающуюся практическую задачу нахождения рейтинга компаний, занимающихся бизнесом в некоторой области. Решить такую задачу, можно, например, голосованием - рейтинг компаний определяется тогда по количеству поданных за нее голосов. Но в этом случае получается оценка компании "в целом" без каких-либо деталей.
Более сложной является задача построения рейтинга компаний, основываясь на фактических показателях их деятельности и/или экспертных оценках по многим критериям. Перечень таких критериев формируется заранее, он зависит от целей анализа. Например, компании, действующие в некотором секторе рынка, можно оценивать по следующим критериям: Q1. Уровень деловой активности; Q2. Объем прибыли от реализации продукции; Q3. Объем продаж; Q4. Число выполненных проектов; Q5. Квалификация персонала; Q6. Численность сотрудников компании; и тому подобное. Шкалы критериев оценки могут быть как количественными, так и качественными. Для удобства оценки и сравнения компаний количественные критерии можно трансформировать в качественные с небольшим числом упорядоченных градаций шкал. Шкалы критериев Q4. "Число выполненных проектов" и Q6. "Численность сотрудников компании" могут иметь, например, такой вид:
Q41 - очень высокое (больше ста);
Q42 - высокое (от пятидесяти до ста);
Q43 - среднее (от десяти до пятидесяти);
Q44 - низкое (меньше десяти).
Пусть каждая компания из некоторой совокупности оценивается несколькими экспертами по всем критериям. В частности, возможна ситуация, когда представитель каждой компании является экспертом, ставящим свои оценки всем рассматриваемым компаниям, в том числе и своей собственной. При этом оценки разных экспертов могут отличаться друг от друга и даже быть противоречивыми. В таком случае каждую компанию можно рассматривать как многопризнаковый объект, а определение рейтинга компаний представляет собой тогда задачу упорядочивания многопризнаковых объектов. Основной трудностью при решении таких задач является необходимость учета всех описаний объекта - различающихся оценок, сделанных разными экспертами.
К числу наиболее популярных методов упорядочения объектов относятся непосредственная порядковая классификация, ранжирование, парные сравнения.
Наименее трудоемким для эксперта методом упорядочения объектов является метод непосредственной классификации с именованными и упорядоченными классами - метод сортировки [8]. В этом методе эксперт непосредственно относит объект AI к одному из выделенных классов, назначая объекту одну из оценок по порядковой или номинальной шкале критериев. При коллективной экспертизе сортировка объектов проводится обычно на основе распределений экспертных оценок. Если согласованность оценок оказывается приемлемой, то в качестве коллективной средней оценки используется медиана Кемени-Снелла [9], [10], которая практически достаточно часто совпадает с модой распределения. Итоговое упорядочение объектов строится на основе средних оценок.
При упорядочении объектов с помощью метода ранжирования для каждого объекта AI тем или иным образом, например, на основе предпочтений лица, принимающего решение (ЛПР), или оценок эксперта вычисляется натуральное число RI, называемое рангом. Упорядочению объектов соответствует упорядочение рангов R1R2...RI...RC. Возможны различные способы ранжирования объектов. Например, объекты могут предъявляться эксперту все сразу или поочередно. При небольшом числе объектов и одном признаке (критерии) оценке объектов ранжирование не представляет больших трудностей для экспертов. При увеличении числа объектов, критериев и экспертов, оценивающих объекты, количество связей между оценками резко возрастает. Поэтому эксперты могут допускать в таких случаях существенные ошибки при определении рангов объектов. В силу ограниченных возможностей человека при обработке информации методы ранжирования объектов являются для экспертов более трудоемкими по сравнению с методами непосредственной классификации.
В методах парных сравнений итоговое упорядочение объектов строится на основе сравнения всех пар объектов. ЛПР или эксперту предъявляется пара объектов и предлагается указать, какой из объектов более предпочтителен. В случае сравнения всех пар объектов и транзитивности предпочтений эксперта, получается полное упорядочение объектов. Если эксперт считает некоторые из объектов несравнимыми, то упорядочение будет частичным. Для каждого эксперта и признака (критерия) составляется своя матрица парных сравнений "объект-объект". Таким образом, появляется набор матриц, обработка которых для получения итогового упорядочения требует создания специальных вычислительных алгоритмов.
ЛПР и эксперты могут быть не всегда последовательными в своих ответах, могут допускать неточности, особенно в трудных случаях, предпочтения ЛПР могут быть противоречивыми. Для преодоления таких трудностей при построении итоговых упорядочений разрабатываются специальные процедуры. Так, например, в группе методов ЗАПРОС (Замкнутые Процедуры у Опорных Ситуаций) [1] для упорядочения многокритериальных объектов используется процедура выявления цепочек сравнений, образующих нетранзитивные триады. Выявленные нарушения предъявляются ЛПР для изменения его оценок с тем, чтобы устранить противоречия и построить единую порядковую шкалу оценок. В группе методов ELECTRE (Elimination et Choix Traduisant la Realite) [11] упорядочение многокритериальных объектов осуществляется путем их попарного сравнения с использованием специальных индексов согласия и несогласия, рассчитываемых на основе предпочтений ЛПР.
Когда объекты имеют многопараметрическое описание, а сами объекты должны рассматриваться и анализироваться как единое целое, например, когда объекты оцениваются несколькими экспертами по многим качественным критериям Q1,...,QM, построение итогового упорядочения K объектов на основании M отдельных ранжировок, полученных по каждому из параметров вызывает значительные трудности. Исторически сложились два подхода к их преодолению, которые можно условно назвать статистическим и алгебраическим [8]. При статистическом подходе каждое из индивидуальных упорядочений, к примеру, заданное экспертом, рассматривается как одна из возможных реализаций одного и того же наиболее вероятного упорядочения объектов. Известны различные модели для построения такого вероятностного упорядочения, например, модели Льюса, Терстоуна и другие.
В алгебраическом подходе итоговое упорядочение ищется как наиболее близкое ко всем индивидуальным упорядочениям. Близость ранжировок оценивается по некоторому расстоянию, обычно вводимому аксиоматически. Одним из широко используемых видов таких компромиссных решений является медиана Кемени-Снелла. Другим часто употребляемым методом построения итогового упорядочения служит упорядочение объектов по средним рангам, то есть по среднему арифметическому значению рангов, присвоенных каждому объекту разными экспертами. Как отмечается в работе [10], со статистической точки зрения и медиана Кемени-Снелла, и упорядочение по средним рангам представляют собой упорядочения, наиболее коррелированные в среднем с индивидуальными экспертными предпочтениями. В первом случае корреляции ищутся с использованием в качестве коэффициента ранговой корреляции коэффициента Кендалла, а во втором - коэффициента Спирмена. При упорядочении несравнимых объектов необходимо учитывать дополнительную информацию, например, предпочтения ЛПР [1] или относительную важность критериев [4].
В перечисленных выше подходах построение итогового упорядочения объектов производится либо на основе информации, полученной от одного источника, либо путем согласования или усреднения различных оценок. Однако, если имеются различные источники информации, например, объекты оцениваются несколькими экспертами, которые работают независимо и не знают оценок друг от друга, то получить согласованное мнение экспертов крайне сложно или вообще невозможно. Поэтому необходимы методы упорядочения многопризнаковых объектов, которые позволяли бы одновременно учитывать оценки, в том числе и противоречивые, всех экспертов без поиска компромисса между мнениями отдельных экспертов.
Упорядочение многопризнаковых объектов. Дадим формальную постановку задачи упорядочения многопризнаковых объектов. Пусть A ={A1,...,AK} - совокупность объектов, которые оцениваются N экспертами по M критериям Q1,...,QM. Каждый критерий QS имеет порядковую шкалу количественных или качественных оценок {}, ES=1,...,HS, S=1,...,M, которые упорядочены от лучшего значения к худшему QS1QS2.... Предполагается, что разные критерии могут иметь различную относительную важность, но значения оценок, относящихся к одному и тому же критерию, равноценны. Будем также считать, что каждый объект оценивается всеми N экспертами по всем M критериям, не существует "главного" эксперта и мнения всех экспертов одинаково важны, экспертные оценки независимы. Можно выделить два объекта (возможно, гипотетических) - абсолютно лучший и абсолютно худший, которым все эксперты дали соответственно наивысшие и наинизшие оценки по всем критериям. Требуется, исходя из многокритериальных оценок объектов, упорядочить объекты от лучшего к худшему.
Представим объект AI как мультимножество вида (1) над доменом G={Q1,...,QM}, являющимся множеством критериальных оценок, где функция кратности KAi() мультимножества характеризует количество экспертов, давших объекту AI оценку. Наилучшему и наихудшему объектам соответствуют мультимножества
Мультимножество математический объект метрический
AMax = {n*q11,0,...,0, n*q21,0,...,0,..., n*qM1,0,...,0} (3)
AMin = {0,...,0,n*, 0,...,0,n*,..., 0,...,0,n*} (4)
И их принято называть идеальным и антиидеальным решениями. В дальнейшем мы не будем делать различия между объектом AI и представляющим его мультимножеством AI. Задача упорядочения многопризнаковых объектов сводится, таким образом, к упорядочению мультимножеств. Рассмотрим возможные подходы к ее решению.
Простейший способ сравнения и упорядочения объектов состоит в упорядочении мультимножеств по включению. В этом случае I-ый объект AI будет лучше J-ого объекта AJ (AIAJ), если для мультимножеств выполняется включение AI AJ, что равносильно условию KAi()KAj() для всех G. Однако такая возможность на практике встречается достаточно редко.
Мультимножество A в определенном смысле эквивалентно целочисленному вектору CA=(KA1,...,KAh1,..., KAm1,...,KAhm), различные компоненты KAs которого являются значениями функции кратности KA() мультимножества A. Используя представление объекта A с помощью вектора CA, мы возвращаемся к методам группового сравнения и упорядочения многопризнаковых объектов, рассмотренным выше. Важнейшим недостатком этих методов является их малая пригодность для противоречиво описанных объектов, а также трудоемкость процедур сбора и обработки информации об объектах.
Будем теперь считать многопризнаковые объекты точками метрического пространства мультимножеств (A , D), например, с основной метрикой (типа Хемминга), которая задается формулой (2), принимающей вид
D1(A, B) = m(AДB) = (5)
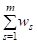
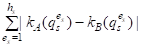
Где WS 0 - коэффициенты относительной важности критериев QS. Будем сравнивать объекты по их близости к идеальному решению AMax и говорить, что объект AI лучше объекта AJ (AIAJ), если он находится ближе к идеальному решению AMax, то есть выполняется условие
D1(AMax, AI) d1(AMax, AJ) (6)
Упорядочим все объекты по величине их расстояния от идеального решения. Если для некоторых объектов D1(AMax,AI)=D1(AMax,AJ), то объекты AI и AJ будут или эквивалентными, или несравнимыми. Тем самым полученное ранжирование объектов окажется нестрогим.
Так как каждый объект AI оценивается N экспертами по всем M критериям, то нетрудно убедиться, что выполняются равенства
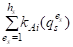
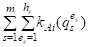
= N, = Mn
Отсюда, в частности, для любого критерия QS следует соотношение
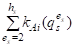
= N KAi(QS1) (7)
Воспользовавшись формулами (3), (5), условием равноценности оценок по каждому критерию и учитывая равенство (7), запишем выражение для расстояния от идеального решения AMax до объекта AI в виде:
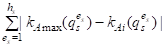
D1(AMax, AI) = = 2[n kAi(qS1)]
Условие (6) сравнения многопризнаковых объектов приобретает тогда следующую форму: объект AI лучше объекта AJ (AI AJ), если
KAi(qS1) KAj(qS1) (8)
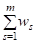
Таким образом, правило упорядочения многопризнаковых объектов сводится к сравнению взвешенных сумм SAi1 =S WS KAi(QS1) первых (наилучших) оценок объектов по всем критериям QS. Лучшим будет тот объект AI, у которого эта сумма SAi1 будет больше.
Для некоторых объектов AIr вместо неравенств (6) или (8) выполняются равенства D1(AMax, AI1)=...=D1(AMax, AIt), R=1,...T. В таком случае получим частичное упорядочение объектов, в котором объекты AI1,...,AIt "делят" одно и то же место. Чтобы упорядочить эти объекты внутри группы воспользуемся следующим приемом. Подсчитаем для объектов взвешенные суммы SAir2 =S WS KAir(QS2) вторых оценок по всем критериям, и будем считать, что объект AIu лучше объекта AIv, если выполняется условие
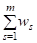
KAiu(QS2) KAiv(QS2) (9)
Если для каких-то объектов AIrp и эти суммы окажутся одинаковыми, то упорядочим объекты из этой подгруппы по суммам SAirp3 =S WS KAirp(QS3) третьих оценок по всем критериям. И так далее, пока не расставим по своим местам все объекты AI1,...,AIt данной группы и всей совокупности A ={A1,...,AK} в целом.
Представим рассмотренную процедуру упорядочения совокупности многопризнаковых объектов в виде следующего алгоритма [12].
Шаг 1. Вычислить для каждого объекта AI из совокупности A ={A1,...,AK} взвешенную сумму SAi1 =S WS KAi(QS1) всех первых (наилучших) оценок по всем критериям QS и упорядочить объекты от лучшего к худшему по величинам SAi1 сумм первых оценок. Если найдутся группы эквивалентных или несравнимых объектов AI1,...,AIt, имеющих одинаковые суммы SAi1, перейти к шагу 2.
Шаг 2. Вычислить для каждого объекта AIr, R=1,...T в соответствующей группе взвешенную сумму SAir2 =S WS KAir(QS2) всех вторых оценок по всем критериям QS и упорядочить объекты внутри каждой группы от лучшего к худшему по величинам SAir2 сумм вторых оценок. Если останутся подгруппы эквивалентных или несравнимых объектов AIru,...,AIrv, имеющих одинаковые суммы SAir2, перейти к шагу 3.
Шаг 3. Вычислить для каждого объекта AIrp в соответствующей подгруппе взвешенную сумму SAirp3 =S WS KAirp(QS3) всех третьих оценок по всем критериям QS и упорядочить объекты внутри каждой подгруппы от лучшего к худшему по величинам сумм SAirp3 третьих оценок. Продолжить процедуру до полного упорядочения всех объектов из совокупности A={A1,...,AK}. Если число HS значений оценок у некоторых критериев QS окажется меньше требуемого на данном B-ом шаге алгоритма, то следует считать KAir...p(QSB)=0. _
В приведенном выше алгоритме предполагалась различная относительная важность критериев QS, выражаемая коэффициентами WS 0, на которые могут накладываться некоторые условия, например, S WS =1. Проблема определения важности критериев имеет самостоятельное значение и в контексте данной работы не рассматривается. В случае, когда все критерии одинаково важны, все коэффициенты WS считаются равными 1.
Аналогичным образом можно построить процедуру упорядочения многопризнаковых объектов AI по отношению к антиидеальному решению AMin, заданному выражением (4), считая, что объект AI лучше объекта AJ (AI AJ), если он находится дальше от антиидеального решения AMin, то есть D1(AMin, AI)D1(AMin, AJ). Как и выше, объекты AI и AJ будут эквивалентными или несравнимыми, если D1(AMin,AI)=D1(AMin,AJ). Подчеркнем, что упорядочение совокупности многопризнаковых объектов A ={A1,...,AK} по отношению к антиидеальному решению может не совпадать с упорядочением по отношению к идеальному решению.
Данный метод упорядочения многопризнаковых объектов был применен для построения рейтинга российских компаний, работающих в секторе информационно-коммуникацион-ных технологий [13]. Экспертная оценка деятельности компаний давалась по специально разработанным критериям с качественными оценками, аналогичным указанным выше, а результаты обрабатывались по описанной процедуре. Всего было оценено около 50 компаний, из которых были выделены 30 ведущих высокотехнологичных компаний, а также составлены рейтинги 10 ведущих разработчиков программного обеспечения и 10 наиболее динамично развивающихся компаний.
Классификация многопризнаковых объектов. Рассмотрим еще одну практическую задачу, в которой, исходя из некоторой предварительной сортировки совокупности многопризнаковых объектов, требуется распределить эти объекты по нескольким классам. Допустим, что для решения какой-либо важной проблемы (научно-технической, экономической, производственной, экологической) необходимо сформировать программу, которая будет состоять из отдельных работ, проектов, заданий и тому подобное, отобранных на конкурсной основе. Каждая представленная на конкурс заявка оценивается несколькими экспертами по специально разработанным качественным критериям. Основываясь на заключениях экспертов, орган, ответственный за формирование программы, принимает решение о включении того или иного проекта в программу.
Например, при формировании государственной научно-технической программы по высокотемпературной сверхпроводимости [14] экспертная оценка и конкурсный отбор проектов проводился по следующим качественным критериям: Q1. Важность проекта для программы; Q2. Перспективность проекта; Q3. Новизна подхода к решению поставленных задач; Q4. Квалификация исполнителей проекта; Q5. Ресурсное обеспечение работ; Q6. Возможность быстрого выхода результатов в практику.
Каждый критерий имел порядковую или номинальную шкалу оценок с развернутыми словесными формулировками градаций качества. Так, шкала критерия Q4. "Квалификация исполнителей проекта" имела вид:
Q41 - по опыту и квалификации исполнители проекта являются одним из лучших научных коллективов;
Q42 - опыт и квалификация исполнители находятся на уровне, достаточном для проведения работ;
Q43 - исполнители не обладают необходимыми опытом и квалификацией;
Q44 - опыт и квалификация исполнителей неизвестны.
Шкала оценок по критерию Q6. "Возможность быстрого выхода результатов в практику" выглядела следующим образом:
Q61 - результаты будут обладать достаточной степенью технологичности, обеспечивающей их быстрое использования в практике;
Q62 - для использования запланированных результатов на практике потребуются дополнительные исследования и разработки;
Q63 - результаты будут носить в основном теоретический характер.
Экспертиза заявок осуществлялась экспертами независимо друг от друга без согласования их мнений. Каждый эксперт, наряду с оценкой заявки по всем критериям, давал одну из следующих рекомендаций:
R1 - включить проект в программу;
R2 - отклонить проект;
R3 - отложить рассмотрение заявки и отправить проект на доработку.
Указанные рекомендации экспертов являются, по существу, правилами предварительной классификации (сортировки) рассматриваемых заявок. В других задачах критерии оценки объектов и правила их сортировки могут быть и иными.
Если бы заявка оценивалась только одним экспертом, то найти на множестве многокритериальных оценок обобщенное решающее правило для отбора предложений не составило бы особого труда. Известно большое число разных подходов к решению подобного рода задач классификации, например, [1], [2], [10], [15]. Однако когда заявка рассматривается несколькими экспертами, то появляется несколько различных вариантов ("экземпляров") одной и той же заявки, поскольку и многокритериальные экспертные оценки, и заключения экспертов могут быть как схожими, так и противоречивыми. В силу качественного характера экспертных данных их агрегирование тем или иным способом представляет самостоятельную, достаточно сложную проблему. Помимо этого, вырабатывая решение о включении заявки в программу, необходимо учесть все, даже и не совпадающие заключения экспертов по принятию или отклонению заявки. Желательно поэтому иметь некое единое решающее правило для отнесения заявки к какому-либо классу, которое, во-первых, базировалось бы на характеристиках заявок, выраженных их многокритериальными оценками, а во-вторых, в наибольшей степени соответствовало бы индивидуальным экспертным правилам сортировки. Прежде, чем переходить к изложению путей решения этой задачи, напомним некоторые общие положения.
Наиболее общим определением класса является следующее: класс - это совокупность (семейство) объектов, обладающих общими свойствами. Информация о свойствах объекта может быть получена путем наблюдений, измерений, оценок и тому подобное и представлена совокупностью признаков, значения которых выражаются в числовых и/или вербальных шкалах. Входящие в один и тот же класс объекты считаются неразличимыми (эквивалентными), а каждый класс объектов характеризуется некоторым качеством, отличающим его от других классов. Все классы вместе должны составлять исходную совокупность объектов.
Свойство сходства и различимости объектов, относящихся к одному и тому же классу, широко используется при построении различных методов классификации. Так, например, в ряде методов сортировки объектов, основанных на теориях нечетких [16], [17] и грубых [18] множеств, допускается неоднозначность классификации объектов, связанная с разной степенью принадлежности объекта к классу, то есть объекты, которые "несомненно" и "возможно" принадлежат к некоторому классу, считаются различающимися.
Процедура классификации объектов в рамках формальной логики может быть описана как совокупность (последовательность) решающих правил, которые представляются выражениями вида:
ЕСЛИ условия, ТО решение. (10)
При прямой классификации терм условия включает названия объектов или перечень значений признаков, описывающих объекты класса, что часто считается эквивалентным. При непрямой классификации один или несколько термов условия конструируются как отношения между различными признаками и/или их значениями. Терм решение в обоих случаях означает, что объект принадлежит к определенному классу. Заметим, что подобным же образом формируются базы знаний экспертных систем продукционного типа.
При достаточно небольшом числе классифицируемых объектов и признаков, их описывающих, семейство решающих правил легко обозримо и доступно для анализа. Чем больше количество рассматриваемых объектов и разнообразнее решающее правила их классификации, тем труднее становится анализ этих правил. Могут существовать различные причины, обусловливающие неоднозначность классификации, к примеру, если объекты сортируются разными экспертами. Эксперты могут относить сильно различающиеся объекты в один и тот же класс, а объекты со сходными значениями признаков - в разные классы. Несогласованность индивидуальных решающих правил может быть вызвана неоднозначностью понимания экспертами решаемой задачи, ошибками или неточностями, допущенными экспертами при первоначальной классификации объектов, субъективным различием решающих правил, используемых разными экспертами, специфичностью знаний самих экспертов, нетранзитивностью отдельных экспертных суждений и многими другими причинами. В итоге может появиться семейство решающих правил, среди которых будут одинаковые, сходные, различающиеся и противоречивые правила.
В этом случае возникает проблема: построить такое обобщенное решающее правило или небольшую группу правил, которые наилучшим (в некотором смысле) образом аппроксимируют совокупность всех индивидуальных правил сортировки объектов, включают минимальный набор признаков и относят объекты в заданные классы с допустимой точностью.
Аппроксимация индивидуальных правил сортировки. Перейдем к формальной постановке задачи аппроксимации большого числа правил сортировки многопризнаковых объектов компактным набором простых решающих правил. Пусть A ={A1,...,AK} - совокупность объектов, которые описываются M дискретными признаками Q1,...,QM, имеющими качественные значения. Каждая группа признаков QS={}, ES=1,...,HS, S=1,...,M отражает содержательное качество объектов, например, может быть значением показателя, характеризующего какое-либо свойство объекта, или оценкой объекта по критерию, и тому подобное. Объекты AI, I=1,...,K предварительно рассортированы по нескольким классам XT, T=1,...,F путем прямой классификации. Принадлежность объекта AI к некоторому классу XT выражается правилом сортировки R, которое может считаться еще одним качественным признаком со шкалой значений R={RT}. Любой объект AI может существовать в N экземплярах, которые отличаются наборами признаков, его характеризующих. Однако в описании каждого экземпляра объекта присутствует только одно какое-то значение признака из каждой группы Q1,...,QM,R. Других дополнительных предположений об особенностях классов, признаков объектов и их значений (важности, предпочтительности, характерности, упорядоченности и прочее) не делается. Требуется построить одно или несколько решающих правил, составленных из небольшого числа значений признаков, которые относили бы объекты к заданным классам наилучшим (в смысле близости к предварительной сортировке) образом. Само понятие близости также должно быть определено.
Сопоставим каждый многопризнаковый объект с мультимножеством вида, аналогичного выражению (1)
AI = {(kAi()*), (kAi(rT)*rT)} (11)
Над доменом G={Q1,...,QM,R}. Запись объекта AI в таком виде может трактоваться как еще один способ выражения индивидуальных правил сортировки (10). А именно: терм условия ассоциируется тогда с различными комбинациями значений признаков, описывающими свойства объекта AI, а терм решение - с принадлежностью объекта AI к классу XT. В терм решение входит также некоторое правило, позволяющее говорить о принадлежности объекта AI к какому-то определенному классу XT. Это может быть, например, правило простого большинства голосов, в соответствии с которым объект AI будет считаться принадлежащим к классу XT, если KAi(RT)KAi(RP) для всех Pt, или правило квалифицированного большинства голосов, по которому должно выполняться условие KAi(RT)Pt KAi(RP), или любое другое правило. При этом предполагается, что каждый объект оценивается всеми N экспертами.
Вся совокупность объектов A ={A1,...,AK}, представленных мультимножествами (11), порождает семейство первичных решающих правил сортировки. Правила совпадают или являются похожими, когда различные объекты с идентичными или схожими (близкими) значениями признаков включаются в один класс. Противоречивые правила относят слабо различимые объекты в разные классы.
Для простоты будем считать, что результатом классификации должно быть разложение совокупности объектов A только на два класса XA и XB. Требование бинарной декомпозиции A ={XA, XB} не является принципиальным ограничением. Если необходимо рассортировать объекты на большее число классов, можно сначала разбить совокупность объектов на две группы, затем одну из них или обе группы - на подгруппы, и так далее. Например, заявки можно разделить на принятые и отклоненные, отклоненные заявки - на отложенные для дальнейшей доработки и окончательно не принятые, и так далее.
Рассмотрим наиболее простой и типичный случай, когда все группы объектов формируются как суммы соответствующих им мультимножеств. Тогда каждое из мультимножеств XT, T=A,B, представляющее свой класс объектов, можно записать в виде следующего разложения на мультимножества по группам признаков:
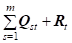
XT = (12)
Где каждое слагаемое есть в свою очередь разложение
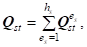
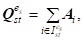
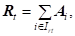
Подмножества индексов =IT и IRt=IRIT; IT - подмножество индексов I для объектов AI, имеющих функции кратности KAi(RT)PtKAi(RP) или kAi(RT)KAi(RP),Pt; - подмножество индексов I для объектов AI, имеющих KAi()0, KAi()=0, Vs, KAi(RT)=0; IR - подмножество индексов I для объектов AI, имеющих KAi(RT)0, KAi()=0. Так как каждый экземпляр объекта AI может обладать только единственными значениями KAi() и KAi(RT) из каждой группы признаков QS и R, то выполняются следующие условия для мощностей мультимножеств:
|QSa| + |QSb| = k, |RA| + |RB| = k, |XA| + |XB| = k(m+1)
Где, напомним, K равно числу объектов, а M - числу групп признаков.
Очевидно, что объекты AI, которые попали в разложение {RA, RB}, сделанное только по правилам сортировки, образуют наилучшую из всех возможных декомпозиций рассматриваемой совокупности объектов A ={A1,...,AK} на два класса для имеющегося набора первичных правил сортировки. Обозначим через D*=D(RA, RB) расстояние между мультимножествами RA и RB в метрическом пространстве мультимножеств (A, D) с метрикой D, определяемой одним из выражений (2) или (5). В каждой конкретной задаче классификации расстояние D* является предельно возможным расстоянием между объектами, входящими в разные классы. При идеальной предварительной сортировке объектов противоречия в индивидуальных правилах отсутствуют. В этом случае максимально возможное расстояние в метрическом пространстве мультимножеств (A , D), на котором могут находиться объекты, принадлежащие разным классам, будет равно соответственно D1*=Kn, D2*=1/H, d3*=1. Здесь N есть число индивидуальных правил сортировки, приходящихся на один объект, совпадающее, в частности, с числом экспертов, H - общее число значений всех признаков, описывающих объекты, равное для задачи классификации H=H1+...+HM+F.
Сформулируем теперь основную идею нахождения обобщенного решающего правила, аппроксимирующего большое семейство противоречивых правил сортировки многопризнаковых объектов. Для каждой группы признаков QS нужно сгенерировать пары новых мультимножеств таким образом, чтобы мультимножества внутри каждой пары были удалены друг от друга в метрическом пространстве (A , D) как можно больше и с достаточной точностью совпадали с первоначальной сортировкой объектов по классам XA и XB, заданной разложением {RA, RB}. Разные комбинации признаков, определяющих границы между сгенерированными мультимножествами внутри каждой пары, дадут желаемые обобщенные решающие правила для классификации объектов.
Решение задачи аппроксимации решающих правил для классификации многопризнаковых объектов сводится, таким образом, к решению m оптимизационных задач вида
D(QSa, QSb) max d(QSa, QSb) = d(QSa*, QSb*) (13)
Где мультимножества QSa* и QSb* принадлежат к разным классам и находятся на максимально возможном расстоянии в метрическом пространстве мультимножеств (A , D). Решение каждой из задач (13) является наилучшей бинарной декомпозиций {QSa*, QSb*} имеющейся совокупности многопризнаковых объектов A ={A1,...,AK} по S-ой группе признаков. Когда число HS значений каждого из признаков невелико (HS=25), решение задачи (13) не вызывает существенных трудностей и может быть получено даже путем простого перебора.
Каждое мультимножество QSt* (T=A, b), относящееся к одному и тому же классу, представляет собой сумму двух подмультимножеств QSt* = QSt*1 + QSt*2. Значение признака QS*, которое определяет границу между слагаемыми QSt*1 и QSt*2, назовем аппроксимирующим признаком. Комбинации аппроксимирующих признаков {QS*} для разных номеров S групп признаков QS задают условия отнесения объекта AI к соответствующему классу XT и образуют в совокупности искомые обобщенные правила классификации объектов вида (11).
Аппроксимирующие признаки QS* для различных групп признаков можно упорядочить по величине расстояния D(QSa*, QSb*). Для построения обобщенных правил классификации следует использовать признаки QS*, занимающие первые места в такой ранжировке. Чем ближе значения расстояний D(QSa*, QSb*) к расстоянию D*=D(RA, RB), тем более точной будет аппроксимация первоначальной индивидуальной сортировки объектов. Оценить точность аппроксимации по S-ой группе признаков можно, например, выражением
S = d(QSa*, QSb*)d(RA, RB) (14)
В обобщенное решающее правило должны тогда включаться аппроксимирующие признаки QS*, имеющие показатель точности S, превышающей некоторый желаемый пороговый уровень 0. Заметим, что величина S показателя точности аппроксимации характеризует в определенном смысле относительную важность S-ой группы признаков QS в обобщенном правиле классификации.
Конкурсный отбор проектов. Соотношения между совокупностью объектов A ={A1,...,AK} и множеством их признаков G={X1,...,XH} удобно выражать с помощью матрицы C=||CIj||Kh, которая часто используется в анализе данных, теории принятия решений, распознавании образов, других приложениях и называется таблицей "объекты-признаки", информационной таблицей или таблицей решений [2], [18]. Строки этой матрицы соответствуют объектам, столбцы - признакам, а элементы матрицы являются значениями признаков. Таким образом, каждая строка матрицы C характеризует свойства рассматриваемого объекта, а каждый столбец дает информацию об объектах, обладающих данным свойством. Свойства совокупности A ={A1,...,AK} многопризнаковых объектов AI, представленных мультимножествами, и их принадлежность к некоторому классу решений XT также можно описать с помощью таблиц решений. В исходной таблице решений C=||CIj||Kh, элементы которой задаются как CIj =KAi(XJ), XJ=,RT, каждая строка является аргументом выражения (11). Разложению совокупности объектов A на два класса XA и XB, которые задаются формулой (12), соответствует преобразованная таблица решений C'=||KXt'(XJ)||2H, состоящая из двух строк KXa'(XJ) и KXb'(XJ). Матрицы C и C' состоят из 2(M+1) блоков, которые соответствуют мультимножествам признаков QSa, QSb и решений RA, RB.
Процедура построения обобщенного решающего правила для классификации многопризнаковых объектов включает следующие основные этапы.
Шаг 1. Построить таблицу решений C=||KAi(XJ)||Kh для рассматриваемой совокупности многопризнаковых объектов A ={A1,...,AK}, строки которой соответствуют мультимножествам AI вида (11).
Шаг 2. Объединить объекты AI, относящиеся к заданным классам XA и XB, воспользовавшись формулами (12). Получить преобразованную таблицу решений C'=||KXt'(XJ)||2H, строки которой соответствуют мультимножествам XA и XB.
Шаг 3. Решить задачу оптимизации (13) для каждого бинарного разложения {QSa*, QSb*} по S-ой группе признаков QS и найти аппроксимирующий признак QS* в каждом S-ом блоке преобразованной матрицы C'.
Шаг 4. Проранжировать аппроксимирующие признаки QS* по убыванию величины расстояния D*=D(RA, RB) или показателя точности S (14).
Шаг 5. Выбрать аппроксимирующие признаки QS*, которые обеспечивают необходимую точность аппроксимации S0, и сформировать из них обобщенное решающее правило для классификации многопризнаковых объектов. _
Проиллюстрируем предложенный подход к построению обобщенного решающего правила для классификации многопризнаковых объектов, которое аппроксимирует большое число противоречивых правил сортировки, на примере конкурсного отбора проектов для формирования государственной научно-технической программы по высокотемпературной сверхпроводимости [14]. Каждая представленная на конкурс заявка независимо оценивалась 3 экспертами по 6 качественным критериям, которые давали также свое заключение по принятию или отклонению заявки. Всего было подано более 250 заявок и около 170 из них было отобрано для включения в программу.
Приведем некоторые данные, иллюстрирующие рассматриваемый пример: часть решающей таблицы C=||KAi(XJ)||Kh, характеризующей поданные на конкурс проекты AI; преобразованная решающая таблица C'=||KXt'(XJ)||2H, соответствующая классам принятых XA и отклоненных XB проектов; значения расстояний между бинарными разложениями D1(QSa*,QSb*) и D1(RA,RB) в пространстве мультимножеств (A , D1) с метрикой (5) при WS=1; значения показателей точности S для аппроксимирующих признаков QS* по каждому S-ому блоку матрицы.
Объекты / Признаки
|
Q11 Q12 Q13 |
Q21 Q22 Q23 |
Q31 Q32 Q33 |
Q41 Q42 Q43 Q44 |
Q51 Q52 Q53 Q54 |
Q61 Q62 Q63 |
RA RB | |
|
A1 ... AI |
1 2 0 1 1 1 |
2 1 0 0 2 1 |
3 0 0 1 2 0 |
2 1 0 0 0 2 1 0 |
0 2 1 0 0 1 2 0 |
2 1 0 0 0 3 |
3 0 2 1 |
|
AI+1 ... AK |
1 1 1 0 2 1 |
0 2 1 0 1 2 |
1 2 0 0 3 0 |
0 2 1 0 0 1 1 1 |
0 1 2 0 0 0 2 1 |
0 0 3 0 3 0 |
1 2 0 3 |
Классы / Признаки
|
Q11 Q12 Q13 |
Q21 Q22 Q23 |
Q31 Q32 Q33 |
Q41 Q42 Q43 Q44 |
Q51 Q52 Q53 Q54 |
Q61 Q62 Q63 |
RA RB | |
|
XA XB |
144 360 21 45 156 51 |
|
|
219 297 9 0 51 132 63 6 |
|
126 300 99 45 135 72 |
510 15 78 174 |
|
D1 S |
|
|
|
|
|
|
591 |
Принятые проекты A1-AI входят в класс XA, отклоненные проекты AI+1-AK относятся к классу XB. Обратим внимание читателя, что хотя проекты AI и AI+1 имеют одинаковые значения оценок {QS} по всем признакам, но наборы их индивидуальных правил сортировки не совпадают, и поэтому AIXA, а AI+1XB. Множество аппроксимирующих признаков QS*, упорядоченное по величине расстояния D1(QSa*,QSb*), выглядит следующим образом:
{qS*} = {q41, q42; q11, q12; q51, q52; q31, q32; q21, q22} (15)
Заметим, что задача (13) не имеет оптимального решения по критерию Q6, то есть любое значение признака Q6 является неаппроксимирующим. Выбрав некоторое желаемое значение точности аппроксимации 0, получим следующие обобщенные решающие правила для отбора проектов.
"Исполнители проекта должны быть одними из лучших или обладать опытом и квалификацией, достаточными для проведения работ" (оценки Q41 или Q42; точность аппроксимации S0,66).
"Проект должен быть крайне важным или важным для достижения одной из основных целей программы; исполнители проекта должны быть одними из лучших или обладать опытом, квалификацией и материально-техническими ресурсами, достаточными для проведения работ" (оценки Q41 или Q42; и Q11 или Q12; и Q51 или Q52; точность аппроксимации S0,55).
Отметим, что последнее правило полностью совпадает с решающим правилом для отбора проектов, приведенным ранее в работе [14]. Обобщенное решающее правило классификации объектов позволяет также выявить расхождения в индивидуальных правилах сортировки, применявшихся экспертами, и при необходимости скорректировать их. Ранжирование (15) аппроксимирующих признаков по величине расстояния D1 показывает, что наиболее важным для отбора проектов оказывается критерий Q4, характеризующий опыт и квалификацию исполнителей, а следующими по важности - критерии Q1, оценивающий важность проекта для достижения целей программы, и Q5, отражающий ресурсное обеспечение работ.
Заключение
Проблемы классификации и упорядочения объектов, которые описываются многими количественными и качественными признаками, причем каждый из объектов может существовать в нескольких различающихся, но равноправных "экземплярах", являются достаточно трудными. Эти трудности имеют и содержательные основания (например, некорректность применения процедур "усреднения" качественных признаков), и формальные причины (например, противоречивость данных, большая размерность задачи). Главные из перечисленных трудностей оказалось возможным преодолеть благодаря использованию нового теоретического инструментария, основанного на понятии мультимножества. Применение теории мультимножеств позволяет разрабатывать новые методы анализа данных и решения новых классов задач, которые не содержат необоснованных преобразований исходной информации и не приводят к потере или искажению данных.
Литература
[1]. О. И.Ларичев, Е. М.Мошкович. Качественные методы принятия решений. Вербальный анализ решений. - М.: Наука, Физматлит, 1996.
[2]. Б. Г.Миркин. Анализ качественных признаков и структур. - М.: Статистика, 1980.
[3] Л. Г.Евланов. Теория и практика принятия решений. - М.: Экономика, 1984.
[4]. В. Д.Ногин. Принятие решений в многокритериальной среде: количественный подход. - М.: Физматлит, 2002.
[5]. А. Б.Петровский. Метрические пространства мультимножеств.//Доклады Академии наук, 1995, Т.344, №2, 175-177.
[6]. А. Б.Петровский. Основные понятия теории мультимножеств. - М.: Едиториал УРСС, 2002.
[7]. Ю. И.Журавлев. Корректные алгебры над множествами некорректных (эвристических) алгоритмов. I,II, III.//Кибернетика, 1977, №4, 14-21; 1977, №6, 21-27; 1978, №2, 35-43.
[8]. Ю. Н.Тюрин. Экспертная классификация.//Экспертные методы в современных исследованиях. Сборник трудов. - М.: ВНИИСИ, 1979, 5-15.
[9]. J. G.Kemeni, J. L.Snell. Mathematical models in the social sciences. - Ginn, Boston, 1962. (Дж. Кемени, Дж. Снелл. Кибернетическое моделирование./Пер. с англ. - М.: Советское радио, 1972).
[10]. Б. Г.Литвак. Экспертная информация: методы получения и анализа. - М.: Радио и связь, 1982.
[11]. B. Roy. Multicriteria methodology for decision aiding. - Kluwer Academic Publishers, Dordrecht, 1996.
[12]. А. В.Литвинова. Упорядочивание многопризнаковых объектов на основе теории мультимножеств.//Дипломная работа на соискание степени магистра. Московский физико-технический институт (государственный университет), М., 2002.
[13]. Кто в России самый интеллектуальный? Рейтинг ведущих российских разработчиков высоких технологий.//Компания, 2000, №47(143), 38-39.
[14]. О. И.Ларичев, А. С.Прохоров, А. Б.Петровский, М. Ю.Стернин, Г. И.Шепелев. Опыт планирования фундаментальных исследований на конкурсной основе.//Вестник АН СССР, 1989, №7, 51-61.
[15]. А. А.Дорофеюк. Алгоритмы автоматической классификации.//Автоматика и телемеханика, 1971, №12, 78-113.
[16]. С. А.Орловский. Проблемы принятия решений при нечеткой исходной информации. - М.: Наука, 1981.
[17]. H. J.Zimmerman, L. A.Zadeh, B. R.Gaines. Fuzzy sets and decision analysis. - North-Holland, Amsterdam, 1984.
[18]. Z. Pawlak, R. Slowinsky. Rough set approach to multi-attribute decision analysis.//European Journal of Operational Research, 1994, №72, 443-459.
Похожие статьи
-
Формальная классификация моделей Формальная классификация моделей основывается на классификации используемых математических средств. Часто строится в...
-
Формальная классификация моделей Формальная классификация моделей основывается на классификации используемых математических средств. Часто строится в...
-
Методы классификации - неотъемлемая часть математических методов исследования, интересная теоретически и важная практически. Обзоры этой научной области...
-
Автоматизированная обработка на ЭВМ позволяет составлять различные сводки, таблицы, ведомости, где информация сгруппирована по каким-либо...
-
Методы изучения связи качественных признаков - Основы эконометрики
При наличии соотношения между вариацией качественных признаков говорят об их ассоциации, взаимосвязанности. Для оценки связи в этом случае используют ряд...
-
Важным этапом изучения явлений предметов процессов является их классификация, выступающая как система соподчиненных классов объектов, используемая как...
-
Основные методы экономическо-математического прогнозирования Кратко рассмотрим различные методы прогнозирования (предсказания, экстраполяции),...
-
Понятие и классификация нематериальных активов
Понятие и классификация нематериальных активов В последние годы тенденция увеличения доли нематериальных активов в составе имущества предприятия...
-
Сначала обсудим один из широко применяемых методов кластер-анализа - с метода k-средних. Он предназначен для разбиения исходного множества элементов...
-
Отбор проб воды является очень существенным этапом в экоаналитическом контроле. Ошибки, возникающие при отборе проб, как правило, исправить не удается....
-
Классификация экономико-математических методов - История развития методов и моделей в экономике
Велика роль математических моделей при описании экономических объектов и процессов, что, безусловно, подтверждается историей развития этого направления...
-
Объект исследования и его модель - Основы научных исследований
Объект исследования - это первичное, не сводимое к более простым, понятие. Поэтому дать его общее определение невозможно. Однако можно указать примеры...
-
Классификация природных вод и их примесей - Природные воды. Классификация примесей
Природные воды классифицируют по ряду признаков, простейший из них - солесодержание воды: пресная вода - солесодержание до 1 г/кг; солоноватая -...
-
Важной задачей статистики является разработка методики статистической оценки социально-экономических явлений, которая осложняется тем, что многие...
-
В качестве меры априорной неопределенности системы (или прерывной случайной величины Х) в теории информации применяется специальная характеристика,...
-
Классификация по типу задач. - Виды моделей
Описательные (дескриптивные) модели (к ним часто приводят, постановки задач типа. А) предназначены для описания изучаемого процесса, объяснения...
-
Часто используют такой показатель качества алгоритма диагностики, как "вероятность (или доля) правильной классификации (диагностики)" [12, 13] - чем этот...
-
Классификация СМО и их основные элементы - Задачи линейного програмирования
СМО классифицируются на разные группы в зависимости от состава и от времени пребывания в очереди до начала обслуживания, и от дисциплины обслуживания...
-
Диэлектрическая проницаемость (ДП) раствора е относится к важнейшим факторам из числа оказывающих наиболее сильное влияние на характеристики протекающего...
-
Внутри каждого направления выделяются отдельные группы прогнозов. Так, в направлении дифференциации прогнозов по масштабности объекта прогнозирования...
-
Модели и моделирование. Классификация моделей - Моделирование экономических систем
Первоначально моделью называли некое вспомогательное средство, объект, который в определенных ситуациях заменял другой объект. Например, манекен в...
-
Объяснение результатов исследований во Вьетнаме, Объекты. - Токсичные вещества
Во Вьетнаме одновременно проводилось изучение в двух направлениях; целью было оценить связь между подверганием гебрицидам, распыляемым в течение войны, и...
-
В настоящей работе предлагается классификация задач многокритериальной оценки эффективности систем различного назначения. В качестве факторов...
-
В данном случае анализируемые системы характеризуются не одним набором показателей эффективности, а несколькими: (18) Где - группа показателей...
-
Содержание и классификация динамических эконометрических моделей - Эконометрика как наука
Можно выделить два основных типа динамических эконометрических моделей. К модели первого типа относятся модели авторегрессии и модели с распределенным...
-
Если брать за основу качественный состав молекул, то все рассматриваемые вещества можно определить в три группы. - Органические - это те, в состав...
-
Общая характеристика. - Витамины: общая характеристика и классификация
Витамины (от лат. VITA - жизнь) - группа органических соединений разнообразной химической природы, необходимых для питания человека и животных и имеющих...
-
Классификация. - Полимерные соединения
По происхождению полимеры делятся на природные (биополимеры), например белки, нуклеиновые кислоты, смолы природные, и синтетические, например полиэтилен,...
-
Признак, частота признака, кумулятивная частота - Математическая статистика
Основной величиной в статистических измерениях является единица статистической совокупности. Единица статистической совокупности характеризуется набором...
-
1. Ознакомиться с методами регрессионного анализа и планирования эксперимента; 2. Определить коэффициенты статистической характеристики объекта...
-
Уравнение динамики теплообменника: Передаточные функции объекта получим по его уравнению динамики. Для этого запишем уравнение по заданному каналу. Затем...
-
Основные понятия информационного моделирования - Понятие об информационном моделировании
Остановимся на информационных моделях, отражающих процессы возникновения, передачи, преобразования и использования информации в системах различной...
-
Прогностическая сила - Базовые результаты математической теории классификации
С целью поиска приемлемого показателя качества диагностики рассмотрим восходящую к Р. Фишеру [20] широко известную параметрическую вероятностную модель...
-
Классификация моделей - Математическое моделирование в менеджменте и маркетинге
Классифицировать модели можно по разным критериям. Например, по характеру решаемых проблем модели могут быть разделены на функциональные и структурные. В...
-
Принцип Дирихле - Разработка контрольных работ по математике
В математике большое значение имеют так называемые доказательства существования. Самый простой способ доказать существование объекта с заданными...
-
ПРИНЦИПЫ ИЗМЕРЕНИЙ И ШКАЛИРОВАНИЯ - Многомерный статистический анализ
Измерение шкалирование кластерный регрессионный Измерение - это Присвоение чисел или других символов характеристикам объектов по заранее определенным...
-
Лист бумаги - Бумага. Классификация бумаги, ее свойства
Бумагой и картоном называют материалы, изготовленные пре-имущественно из специально обработанных растительных волокон, связанных между собой силами...
-
Моносахариды - Классификация углеводов
Из шестиуглеродных моносахаридов - гексоз - важное значение имеют глюкоза, фруктоза и галактоза. Глюкоза Основные понятия . Строение молекулы. Для...
-
Введение, Объект, система, модель - Виды моделей
Моделированием называют построение модели того или иного явления реального мира. В общем виде модель - это абстракция реального явления, сохраняющая его...
-
Большинство систем классификации растворителей по химическим признакам в явной либо неявной формах учитывает их кислотно-основные свойства. Поэтому самая...
Упорядочение и классификация объектов с противоречивыми признаками