Построение модели с помощью метода деревьев решений - Моделирование вероятности банкротства
В отличие от логистической регрессии, при использовании метода деревьев решений ограничения для независимых переменных отсутствуют, поэтому для построения модели использовались все первоначально отобранные финансовые и нефинансовые переменные.
Дерево, построенное на основе обучаемой выборки, представлено на Рисунке 1. Значимость каждой из переменных представлена на Рисунке 2. Категория - это статус предприятия (1 - банкрот, 0 - небанкрот).
Одним из самых значимых показателей в модели оказался размер компании, а вслед за ним идет уровень оборачиваемости запасов, оказавшийся незначимым в логит-модели. Значимыми также оказались показатель ликвидности компании cash/cl, а также показатели прибыльности ret/ta и ebit/sales, который отражает процент средств, остающихся в компании, после покрытия операционных расходов. Возраст компании, как и в логит-регрессии, оказался незначимым.
Количество правильно классифицированных компаний на обучающей выборке составило 88, 37%.
Полученная модель также была протестирована на контрольных подвыборках за 2014 и 2013 годы. Прогнозная сила модели составила 66,38% и 80,16%, соответственно.
Таким образом, надежность модели значительно уменьшилась на подвыборке за 2014 год, как и в случае с логит-моделью. При этом доля правильно классифицированных предприятий на контрольной подвыборке 2013 года не опустилась ниже 80%.
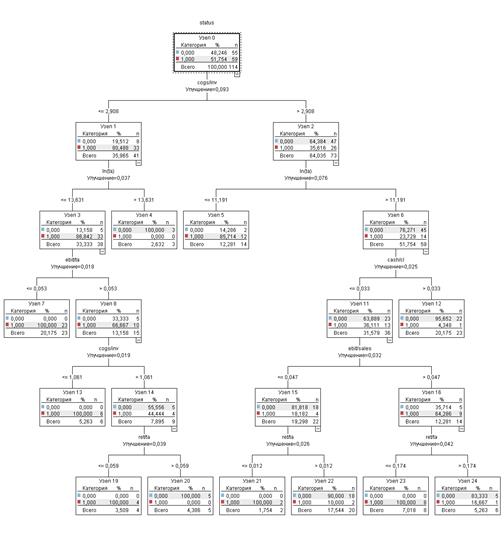
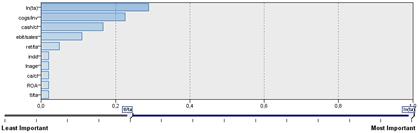
Рисунок 2. Классификационное дерево, построенное на обучающей выборке, и важность переменных для его построения
Похожие статьи
-
По итогам проведенного исследования можно прийти к выводу о том, что и логит-регрессия и деревья решений позволили построить модели, которые с...
-
Проблема прогнозирования вероятности банкротства существует уже несколько десятков лет - все началось с работ Ramser, Foster (1931), Fitzpatrick (1932) и...
-
Построение модели с помощью логистической регрессии Прежде чем строить логистическую регрессию, необходимо выбрать конечный набор финансовых и...
-
На следующем этапе в модель были добавлены дамми-переменные годов и отраслей. Таблицы соотношения переменных и данных приведены ниже. Кроме дамми...
-
Описание используемых методов - Моделирование вероятности банкротства
В данной работе было принято решение использовать логистический анализ с помощью пакета STATA, а также алгоритм CART с помощью SPSS Modeler. Бинарная...
-
Искусственные нейронные сети (ИНС) рассматриваются исследователями как возможная альтернатива статистическим методам. Исследования, использующие ИНС, как...
-
В разделе 1 курсовой работы требуется: Определить количество закупаемого заданным филиалом фирмы сырья у каждого АО, (xj), максимизируя прибыль филиала....
-
Среди современных исследований на тему предсказания банкротства можно выделить группу работ, которые не ставят своей целью сравнение предсказательной...
-
Заключение - Моделирование вероятности банкротства
Целью данного исследования являлось моделирование вероятности банкротства российских нефинансовых компаний на основе наиболее значимых показателей...
-
Основной целью исследования является сравнение предсказательной силы моделей, построенных на основе различных методов. В условиях несбалансированности...
-
Нефинансовые факторы, влияющие на вероятность банкротства - Моделирование вероятности банкротства
Как было отмечено выше, важность финансовых показателей для определения вероятности банкротства фирмы была замечена в самых ранних работах. Однако...
-
Описание данных - Моделирование вероятности банкротства
Данные для исследования были взяты из базы Ruslana (Bureau van Dijk), содержащей финансовую и некоторую нефинансовую информацию об организациях из...
-
Введение - Моделирование вероятности банкротства
В настоящее время в условиях экономической стагнации и ухудшения финансового состояния бизнеса тема кредитоспособности и оценки устойчивости предприятий...
-
Отбор и классификация объясняющих переменных Для всесторонней оценки строительной компании в ходе анализа будут использоваться финансовые,...
-
Методы построения решений по математическим моделям - Математическое моделирование в электромеханике
Системы дифференциальных уравнений, полученные для конкретных ти-пов электрических машин, содержат в скрытом виде исчерпывающую инфор-мацию о всех...
-
Решение симплекс-методом с помощью симплекс-таблиц - Математические методы и модели в экономике
Определим оптимальный план выпуска продукции, решив задачу линейного программирования (ЗЛП). Для этого сначала приведем модель к каноническому виду...
-
Теоретическое обоснование математического моделирования - Математические методы и модели в экономике
Коммерческая деятельность в том или ином виде сводится к решению таких задач: как распорядиться имеющимися ресурсами для достижения наибольшей выгоды или...
-
Методология исследования, Постановка гипотез - Моделирование вероятности банкротства
Постановка гипотез Целью данного исследования является построение модели вероятности банкротства, которая будет обладать надежностью не менее 80%. По...
-
Для прогнозирования банкротства, некоторые исследователи создают модели, основанные на использовании искусственных нейронных сетей. Как правило,...
-
Построение модели на реальных данных - Ранговый метод оценивания параметров регрессионной модели
Для построения линейной регрессионной модели на основе реальных данных при помощи рангового метода оценивания параметров был выбран достаточно известный...
-
Итак, модели, которые будут дальше анализироваться, и получены с помощью Первого метода - проведения теста для выделения наиболее дескриптивных...
-
Большинство современных исследований, посвященных предсказанию банкротства, используют больше одного метода моделирования и делают выводы о сравнительной...
-
Заключение - Влияние значений финансовых коэффициентов на вероятность банкротства компании
В рамках данного исследования были построены и оценены модели предсказания банкротства на базе логистической регрессии и искусственных нейронных сетей...
-
В большинстве реальных больших систем не обойтись без учета "состояний природы" -- воздействий Стохастического типа, случайных величин или случайных...
-
Модели и моделирование - Экономико-математические методы
Одним из основных методов научного познания является эксперимент, а самой распространенной его разновидностью - метод моделирования систем. В процессе...
-
Методы исследования математических моделей - Математическое моделирование в менеджменте и маркетинге
Все методы математического моделирования можно разделить на четыре класса: -аналитические (априорные); -имитационные (априорно-апостериорные) модели;...
-
Экономическая сущность банкротства На сегодняшний день не сложилось единой точки зрения на то, что понимается под банкротством компании. Существует...
-
Выбор переменных - Моделирование вероятности банкротства
Как уже было отмечено выше, единого набора финансовых и нефинансовых показателей, которые необходимо включать в модели, не существует, поэтому было...
-
Основные понятия теории экономико-математического моделирования Кибернетический подход к исследованию экономико-математических систем Обычно...
-
Пусть Dl, r() соответственно левые (правые) границы интервалов I, отвечающих на криволинейной трапеции ОИО значениям 0< < 1. Тогда интересующая нас...
-
Вычисляют выборочную дисперсию, характеризующую меру разброса опытных данных (x I ; Y I ) вокруг значений регрессии, то есть дисперсию остатков ....
-
Основные этапы построения эконометрической модели - Моделирование в эконометрике
Построение эконометрической модели является основой эконометрического исследования. Оно основывается на предположении о реально существующей зависимости...
-
Классификация экономико-математических моделей Математические модели экономических процессов и явлений более кратко можно назвать...
-
Оптимизация, Верификация модели - Синтез скоринговой модели методом системно-когнитивного анализа
Оптимизируем полученную модель с помощью удаления признаков, по которым имеется недостаточно данных. За пороговое значение встреч признаков в модели...
-
Построение многофакторной корреляционно-регрессионной модели производительности труда
Построение многофакторной корреляционно-регрессионной модели производительности труда Данная работа направлена на выявление факторов, от которых зависит...
-
Знаменитая теория полимолекулярной адсорбции Брунауэра, Эммета и Теллера, получившая название теории БЭТ (по первым буквам фамилий ученых), основана на...
-
Матрица сопряженности и другие показатели предсказательной силы логит-модели на данных контрольной подвыборки (2014 год): True Classified D ~D Total +...
-
Адсорбция активированный уголь Развитие теории адсорбционных сил еще не достигло такой стадии, когда по известным физико-химическим свойствам газа и...
-
Моделирование. Детерминизм. Требования к моделированию В процессе исследования объекта часто бывает нецелесообразно или даже невозможно иметь дело...
-
Решение задачи графическим методом - Математическое моделирование в менеджменте и маркетинге
Необходимо найти максимальное значение целевой функции L(x)= 2x1+2x2 > max, при системе ограничений: 6x1+8x2?48, (1) 8x1+11x2?88, (2)...
Построение модели с помощью метода деревьев решений - Моделирование вероятности банкротства