Процесс декомпозиции - Администрирование параллельных процессов
Распараллеливание программ сводится к процессу декомпозиции задачи на независимые процессы, которые не требуют последовательного исполнения и могут, соответственно, быть выполнены на разных процессорах независимо друг от друга.
Существует широкий спектр методов декомпозиции задачи. На следующем рисунке представлена классификация таких методов.
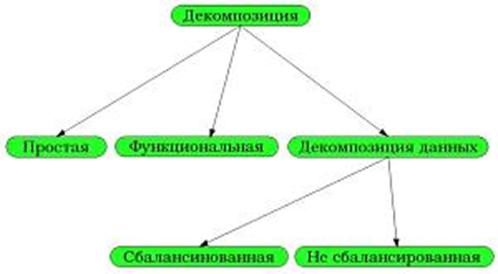
Рисунок 3.2 - Классификация методов декомпозиции
Как видно из рисунка, существует три основных варианта декомпозиции: простая декомпозиция (trival), функциональная (functional) и декомпозиция данных. Вопрос об использовании того или иного типа декомпозици при написании параллельной программы решается исходя из структуры самой задачи. Причем, в зависимости от условий, можно использовать сразу несколько типов.
Тривиальная декомпозиция. Как следует из названия, тривиальная декомпозиция наиболее простой тип декомпозиции. Применяется она в том случае, когда различные копии линейного кода могут исполняться независимо друг от друга и не зависят от результатов, полученных в процессе счета других копий кода. Проиллюстрировать подобный вариант можно на примере решения задачи методом перебора или Монте-Карло. В этом случае одна и та же программа, получив различные начальные параметры, может быть запущена на различных процессорах кластера. Как легко заметить, программирование таких параллельных процессов ничем не отличается обычного программирования на последовательном компьютере, за исключением маленького участка кода, отвечающего за запуск копий программы на процессорах кластера и затем ожидающего окончания счета запущенных программ.
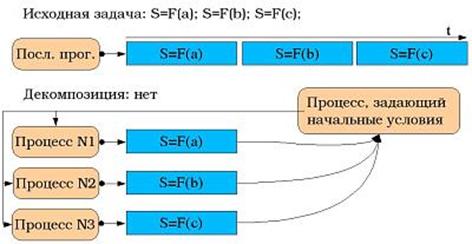
Рисунок 3.3 - Пример реализации параллельной программе
Функциональная декомпозиция. При функциональной декомпозиции исходная задача разбивается на ряд последовательных действий, которые могут быть выполнены на различных узлах кластера не зависимо от промежуточных результатов, но строго последовательно.
Предположим наша задача сводится к применению некоего функционального оператора к большому массиву данных: S[i]=F(a[i]). Предположим также, что выполнение функции F над одним элементом массива занимает достаточно большое время и нам хотелось бы это время сократить. В этом случае мы можем попытаться представить исходную функцию как композицию нескольких фунуций: S(a[i])=I(H(R(a[i]). Произведя декомпозицию мы получим систему последовательных задач:
X=r(a[i]);
Y=h(x);
B[i]=i(y);
Каждая из этих задач может быть выполнена на отдельном узле кластера. Как можно заметить общее время обработки одного элемента массива a[i] в результате не изменяется, а скорее немного увеличивается за счет межпроцессорных пересылок. Однако общее время обработки всего массива заметно снижается за счет того, что в нашем примере одновременно идет обработка сразу трех элементов массива.
У данного метода декомпозиции есть пара особенностей, о которых надо помнить.
Первая особенность состоит в том, что выход кластера на максимальную эффективность происходит не сразу после запуска задачи, а постепенно, по мере того, как происходит частичная обработка первого элемента массива. Второй и третий процессоры в нашем примере, которые отвечают за выполнение функций g(x) и f(y), будут простаивать до тех пор, пока не закончится выполнение функции h(a[1]) на первом процессоре. Третий процессор будет простаивать до окончания выполнения функции g(a[1]). По аналогичному сценарию, только в зеркальном отображении, происходит окончание работы.
Вторая особенность заключается в выборе декомпозированных функций h, g,f. Для уменьшения времени простоя процессоров в ожидании следующей порции работы необходимо таким образом подбирать декомпозированные функции, чтобы время их работы было примерно одинаковым.
По приведенному нами сценарию данные обрабатываются в режиме конвеера. На программиста, выбравшего функциональный тип декомпозиции задачи, ложится обязанность не только по выбору декомпозированных функций, но и по организации работы параллельных частей программы в режиме конвеера, то есть правильно организовать процедуры получения исходных данных от предыдущего процесса и передачи обработанных данных следующему процессу.
Декомпозиция данных. В отличие от функциональной декомпозиции, когда между процессорами распределяются различные задачи, декомпозиция данных предполагает выполнение на каждом процессоре одной и той же задачи, но над разными наборами данных. Части данных первоначально распределены между процессорами, которые обрабатывают их, после чего результаты суммируются некоторым образом в одном месте (обычно на консоли кластера). Данные должны быть распределены так, чтобы объем работы для каждого процессора был примерно одинаков, то есть декомпозиция должна быть сбалансированной. В случае дисбаланса эффективность работы кластера может быть снижена.
В случае, когда область данных задачи может быть разбита на отдельные непересекающиеся области, вычисления в которых могут идти независимо, мы имеем регулярную декомпозицию.
Похожие статьи
-
Моделирование параллельных программ Рассмотренная схема проектирования и реализации параллельных вычислений дает способ понимания параллельных алгоритмов...
-
Формы и характеристики параллелизма Параллелизм -- это возможность одновременного выполнения нескольких арифметико-логических или служебных операций. На...
-
Языки и методы параллельного программирования - Администрирование параллельных процессов
Применение параллельных архитектур повышает производительность при решении задач, явно сводимых к обработке векторов. Автоматическое распараллеливание...
-
Модели параллельных вычислений - Администрирование параллельных процессов
Параллельное программирование представляет дополнительные источники сложности необходимо явно управлять работой тысяч процессоров, координировать...
-
Передача сообщений в PVM - Администрирование параллельных процессов
Посылка сообщений в PVM предназначена для передачи данных между различными процессам и состоит из трех шагов. 1. Первый шаг состоит в том, что буфер...
-
Управление задачами в PVM - Администрирование параллельных процессов
Управление задачами в PVM осуществляется на основе некоторого набора функций. Существует два варианта (два стиля) написания параллельных задач для PVM. В...
-
Взаимодействие задач с PVM - Администрирование параллельных процессов
В системе PVM каждая задача, запущенная на некотором процессоре, идентифицируется целым числом, которое называется идентификатором задачи (TID) и по...
-
Разделение вычислений на независимые части - Администрирование параллельных процессов
Выбор способа разделения вычислений на независимые части основывается на анализе вычислительной схемы решения исходной задачи. Требования, которым должен...
-
Структура кластера и его параметры Вычислительный кластер -- это совокупность компьютеров, объединенных в рамках некоторой сети для решения одной задачи,...
-
Дистрибутивы развертывания кластера - Администрирование параллельных процессов
ParallelKnoppix - это модификация хорошо известного Linux-дистрибутива Knoppix live CD, которая позволяет установить кластер компьютеров для выполнения...
-
Параллельная виртуальная машина кластера кафедры АИС - Администрирование параллельных процессов
Так как в основе кластера АИС лежит параллельная система Beowulf, в качестве основы его вычислительной среды используем коммуникационную библиотеку PVM...
-
Коммуникационная библиотека PVM - Администрирование параллельных процессов
PVM (Parallel Virtual Machine) является продуктом исследовательского проекта по сетевым вычислениям в гетерогенной сетевой среде. Общая цель этого...
-
Распараллеливание процессов - Администрирование параллельных процессов
Старые линейные методы программирования не подходят для написания программ, эффективно использующих многопроцессорную технологию. Необходимо поменять...
-
Распределение задач между процессами - Администрирование параллельных процессов
Распределение подзадач между процессорами является завершающим этапом разработки параллельного метода. Надо отметить, что управление распределением...
-
Установка и администрирования PVM - Администрирование параллельных процессов
Для установки PVM в системе необходимо создать каталог, где будет располагаться система PVM. Будем считать, что установка PVM в каталог /pvm3. В этот...
-
ЗАКЛЮЧЕНИЕ - Администрирование параллельных процессов
В данной дипломной работе были рассмотрены вопросы, касающиеся разработки кластера для организации параллельных вычислений, а так же администрирование...
-
Цели создания проекта - Администрирование параллельных процессов
Создание кластера для организации параллельных вычислений связано с развитием и внедрением таких суперсистем, использование которых позволит упростить...
-
Масштабирование набора подзадач - Администрирование параллельных процессов
Масштабирование разработанной вычислительной схемы параллельных вычислений проводится в случае, если количество имеющихся подзадач отличается от числа...
-
Существующие принципы администрирования Кластер -- группа компьютеров, объединенных высокоскоростными каналами связи, представляющая с точки зрения...
-
Архитектура кластера кафедры АИС За основу проектирования кластера взята высокопроизводительная сетевая система Beowulf. Такой кластер имеет гетерогенную...
-
Анализ работы СЛАУ на кластере - Администрирование параллельных процессов
Системы линейных уравнений возникают при решении ряда прикладных задач, описываемых дифференциальными, интегральными или системами нелинейных...
-
Коммуникационная библиотека MPI MPI это интерфейс прикладного программирования к библиотеке пересылки сообщений, содержащий в себе спецификации к...
-
Назначение вычислительного кластера - Администрирование параллельных процессов
Кластеры используются в вычислительных целях, в частности в научных исследованиях. Для вычислительных кластеров существенными показателями являются...
-
Постановка задачи - Администрирование параллельных процессов
В рамках дипломного проекта необходимо провести работы по администрированию кластера для организации параллельных вычислений. Работа заключается в том,...
-
ВВЕДЕНИЕ - Администрирование параллельных процессов
Последние годы во всем мире происходит бурное внедрение вычислительных кластеров - локальных сетей, с узлами из рабочих станций или персональных...
-
Для администрирования кластера кафедры АИС для организации параллельных процессов было выбрано следующее программное обеспечение. 1. Intel® cluster...
-
Принцип реализации СЛАУ на кластере - Администрирование параллельных процессов
Метод Гаусса - широко известный прямой алгоритм решения систем линейных уравнений, для которых матрицы коэффициентов являются плотными. Если система...
-
Сеть кластера - Администрирование параллельных процессов
Основные типы локальных сетей, задействованные в рамках проекта Beowulf, - это Gigabit Ethernet, Fast Ethernet и 100-VG AnyLAN. В простейшем случае...
-
Вычислительные эксперименты для оценки эффективности параллельного варианта метода Гаусса для решения систем линейных уравнений проводились при следующих...
-
Выделение информационных зависимостей - Администрирование параллельных процессов
При наличии вычислительной схемы решения задачи после выделения базовых подзадач определение информационных зависимостей между ними обычно не вызывает...
-
Аппаратный состав кластера Построение кластерной системы класса Beowulf реализуется на существующих рабочих станция при лаборатории Tempus DESAS кафедры...
-
Узлы кластера - Администрирование параллельных процессов
Это или однопроцессорные ПК, или SMP-сервера с небольшим числом процессоров (2-4, возможно до 6). По некоторым причинам оптимальным считается построение...
-
Программное обеспечение кластера, Операционная система - Администрирование параллельных процессов
Операционная система При построении кластера для организации параллельных вычислений более рационально иcпользовать свободно распространяемую...
-
ПРОМЫШЛЕННАЯ ЭКОЛОГИЯ - Администрирование параллельных процессов
Источники электромагнитного излучения бывают естественные и искусственные. К естественным источникам относится магнитное поле Земли. Оно характеризуется...
-
Принимая во внимание техническую оснащенность помещения, а также требования санитарно-гигиенических норм и правил [12] были выведены следующие...
-
Анализ опасных и вредных производственных факторов - Администрирование параллельных процессов
При работе на компьютере основными опасными и вредными факторами являются: электрический ток, электромагнитные излучения, шум, пыль, освещение, нервные...
-
Определение капитальных затрат - Администрирование параллельных процессов
Капитальные вложения являются единовременными затратами, направленными на строительство, расширение и реконструкцию. Если оценивать производство, всегда...
-
ЭКОНОМИЧЕСКАЯ ЧАСТЬ - Администрирование параллельных процессов
Целью дипломного проектирования является администрирование кластера. В основе кластера лежит локальная вычислительная сеть, настроенная таким образом,...
-
Принципы построения кластера - Администрирование параллельных процессов
Архитектура вычислительных кластеров появилась как развитие принципов построения систем MPP (высокопроизводительных систем) на менее производительных и...
-
Эксплуатационные расходы, Выводы - Администрирование параллельных процессов
Эксплуатационные расходы, связанные с функционированием ЛВС, определяются по формуле: ЗЭкс = ЗМз + ЗЭ + ЗЗп + ЗАм, (4.8) Где ЗМз - затраты на материалы и...
Процесс декомпозиции - Администрирование параллельных процессов