Модификации алгоритма Лемпеля-Зива, предложенная Терри Уэлчем - Анализ алгоритма Лемпеля-Зива
В 1984 году Терри Уэлч (Terry Welch) предложил адаптивный сброс словаря для алгоритма LZ78 [3]. В этом случае при заполнении словаря сброс словаря не производится и новые фрагменты в словарь не добавляются, пока степень сжатия данных остается "достаточно" высокой. Степень "достаточности" определяется субъективно, но простейший вариант "достаточности": пока степень сжатия не меньше, чем на момент заполнения словаря. В этом случае резко возрастает скорость компрессии, поскольку операция вставки новых фрагментов в словарь не производится.
Алгоритм известен под названием LZW. Алгоритм на удивление прост. Если в двух словах, то LZW-сжатие заменяет строки символов некоторыми кодами. Это делается без какого-либо анализа входного текста. Вместо этого при добавлении каждой новой строки символов просматривается таблица строк. Сжатие происходит, когда код заменяет строку символов. Коды, генерируемые LZW-алгоритмом, могут быть любой длины, но они должны содержать больше бит, чем единичный символ. Первые 256 кодов (когда используются 8-битные символы) по умолчанию соответствуют стандартному набору символов. Остальные коды соответствуют обрабатываемым алгоритмом строкам.
Расширенным вариантом адаптивного сброса словаря является частичный сброс - удаление из словаря только части фрагментов, например тех, повторов которых в данных не обнаружено к моменту заполнения словаря. Этот вариант адаптивного сброса требует хранения дополнительной информации в словаре и усложняет конструкцию словаря, но приводит к выигрышу в степени сжатия.
Алгоритм LZW-сжатия в простейшей форме приведен на рис. 2.
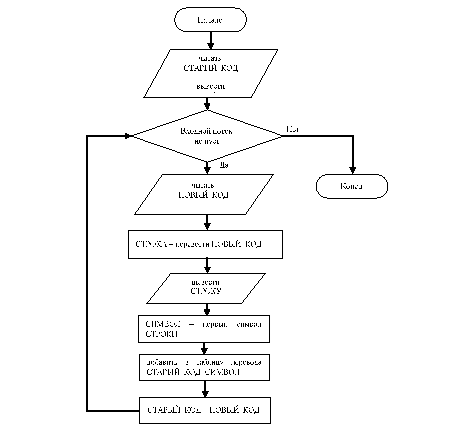
Рис. 2. Алгоритм сжатия
Каждый раз, когда генерируется новый код, новая строка добавляется в таблицу строк. LZW постоянно проверяет, является ли строка уже известной, и, если так, выводит существующий код без генерации нового.
Простая строка, использованная для демонстрации алгоритма, приведена на рис.3.
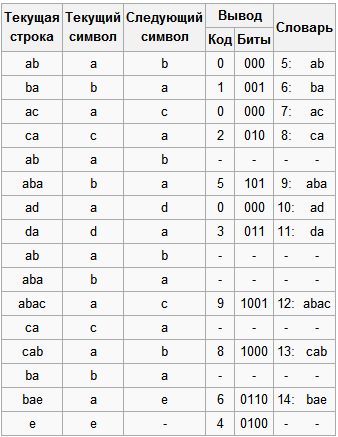
Рис. 3. Процесс сжатия
Входная строка : abacabadabacabae
Сначала создадим начальный словарь единичных символов. В стандартной кодировке ASCII имеется 256 различных символов, поэтому, для того, чтобы все они были корректно закодированы (если нам неизвестно, какие символы будут присутствовать в исходном файле, а какие -- нет), начальный размер кода будет равен 8 битам. Если нам заранее известно, что в исходном файле будет меньшее количество различных символов, то вполне разумно уменьшить количество бит. Чтобы инициализировать таблицу, мы установим соответствие кода 0 соответствующему символу с битовым кодом 00000000, тогда 1 соответствует символу с кодом 00000001, и т. д., до кода 255.
Больше в таблице не будет других кодов, обладающих этим свойством.
По мере роста словаря, размер групп должен расти, с тем чтобы учесть новые элементы. 8-битные группы дают 256 возможных комбинации бит, поэтому, когда в словаре появится 256-е слово, алгоритм должен перейти к 9-битным группам. При появлении 512-ого слова произойдет переход к 10-битным группам, что дает возможность запоминать уже 1024 слова и т. д.
В нашем примере алгоритму заранее известно о том, что будет использоваться всего 5 различных символов, следовательно, для их хранения будет использоваться минимальное количество бит, позволяющее нам их запомнить, то есть 3 (8 различных комбинаций).
|
Символ |
Битовый код |
Код |
|
A |
000 |
0 |
|
B |
001 |
1 |
|
C |
010 |
2 |
|
D |
011 |
3 |
|
E |
100 |
4 |
- § Шаг 1: Тогда, согласно изложенному выше алгоритму, мы добавим к изначально пустой строке A и проверим, есть ли строка A в таблице. Поскольку мы при инициализации занесли в таблицу все строки из одного символа, то строка A есть в таблице. § Шаг 2: Далее мы читаем следующий символ B из входного потока и проверяем, есть ли строка Ab в таблице. Такой строки в таблице пока нет.
Добавляем в таблицу (5) ab. В поток: (0);
- § Шаг 3: ba -- нет. В таблицу: (6) ba. В поток: (1); § Шаг 4: ac -- нет. В таблицу: (7) ac. В поток: (0); § Шаг 5: ca -- нет. В таблицу: (8) ca. В поток: (2); § Шаг 6: ab -- есть в таблице; aba -- нет. В таблицу: (9) aba. В поток: (5); § Шаг 7: ad -- нет. В таблицу: (10) ad. В поток: (0); § Шаг 8: da -- нет. В таблицу: (11) da. В поток: (3); § Шаг 9: aba -- есть в таблице; abac -- нет. В таблицу: (12) abac. В поток: (9); § Шаг 10: ca -- есть в таблице; cab -- нет. В таблицу: (13) cab. В поток: (8); § Шаг 11: ba -- есть в таблице; bae -- нет. В таблицу: (14) bae. В поток: (6); § Шаг 12: И, наконец последняя строка e, за ней идет конец сообщения, поэтому мы просто выводим в поток
Итак, мы получаем закодированное сообщение 01025039864 и его битовый эквивалент 0000010100101000000111001100001100100 . Каждый символ исходного сообщения был закодирован группой из трех бит, сообщение содержало символов, следовательно длина сообщения составляла
3* 16=48 бит.
Закодированное же сообщение так же сначала кодировалось трехбитными группами, а при появлении в словаре восьмого слова -- четырехбитными, итого длина сообщения составила 4*3+7*4=40 бит, что на 8 бит короче исходного.
Конечно, этот пример был выбран только для демонстрации.
В действительности сжатие обычно не начинается до тех пор, пока не будет построена достаточно большая таблица, обычно после прочтения порядка 100 входных байт.
Алгоритму сжатия соответствует свой алгоритм распаковки. Он получает выходной поток кодов от алгоритма сжатия и использует его для точного восстановления входного потока. Одной из причин эффективности LZW-алгоритма является то, что он не нуждается в хранении таблицы строк, полученной при сжатии. Таблица может быть точно восстановлена при распаковке на основе выходного потока алгоритма сжатия. Это возможно потому, что алгоритм сжатия выводит СТРОКОВУЮ и СИМВОЛЬНУЮ компоненты кода прежде чем он поместит этот код в выходной поток. Это означает, что сжатые данные не обременены необходимостью тянуть за собой большую таблицу перевода.
Алгоритм распаковки представлен на рис. 4.
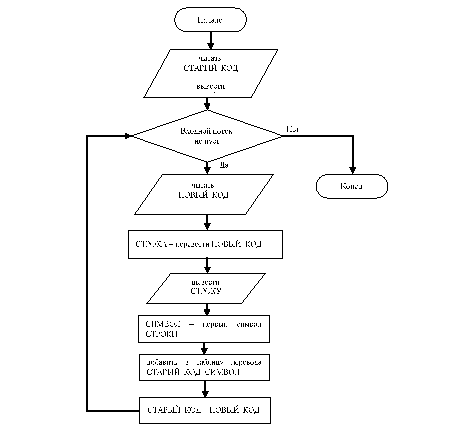
Рис. 4. Алгоритм распаковки
В соответствии с алгоритмом сжатия, он добавляет новую строку в таблицу строк каждый раз, когда читает из входного потока новый код. Все, что ему необходимо сделать в добавок - это перевести каждый входной код в строку и переслать ее в выходной поток.
На рис. 5 приведена схема работы алгоритма на основе сжатых данных, полученных в выше приведенном примере.
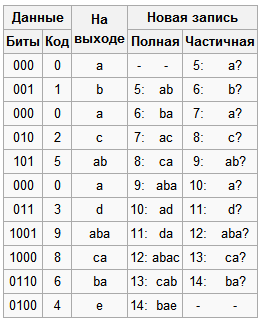
Рис. 5. Процесс распаковки
Выходные коды: 01025039864
Важно отметить, что построение таблицы строк алгоритмом распаковки заканчивается как раз тогда, когда построена таблица строк алгоритма сжатия.
Выходной поток идентичен входному потоку алгоритма сжатия.
К несчастью прекрасный, простой алгоритм распаковки, приведенный на рис. 4, является все таким слишком простым. В алгоритме сжатия существуют некоторые исключительные ситуации, которые создают проблемы при распаковке. Если существует строка, представляющая пару (СТРОКА СИМВОЛ) и уже определенную в таблице, а просматриваемый входной поток содержит последовательность СТРОКА+СИМВОЛ+СТРОКА +СИМВОЛ+СТРОКА, алгоритм сжатия выведет код прежде, чем распаковщик получит возможность определить его.
Простой пример иллюстрирует это. Предположим, строка "JOEYN" определена в таблице с кодом 300. Когда последовательность "JOEYNJOEYNJOEY" появляется в таблице, выходной поток алгоритма сжатия выглядит подобно тому, как показано на рис. 6.
|
Вход(символы) |
Выход(коды) |
Новые коды и соотв. Строки |
|
JOEYN |
288 = JOEY |
300 = JOEYN |
|
A |
N |
301 = NA |
|
. |
. |
. |
|
. |
. |
. |
|
. |
. |
. |
|
JOEYNJ |
300 = JOEYN |
400 = JOEYNJ |
|
JOEYNJO |
400 |
401 = JOEYNJO |
Рис. 6. Некоторые проблемы
Входная строка: ...JOEYNJOEYNJOEY...
Когда распаковщик просматривает входной поток, он сначала декодирует код 300, затем выводит строку "JOEYN" и добавляет определение для, скажем, кода 399 в таблицу, хотя он уже мог там быть. Затем читает следующий входной код, 400, и обнаруживает, что его нет в таблице. Это уже проблема. К счастью, это произойдет только в том случае, если распаковщик встретит неизвестный код. Так как это фактически единственная коллизия, то можно без труда усовершенствовать алгоритм.
Модифицированный алгоритм предусматривает специальные действия для еще неопределенных кодов. В примере на рис. 7 распаковщик обнаруживает код 400, который еще не определен. Так как этот код не известен, то декодируется значение СТАРОГО_КОДА, равное 300. Затем распаковщик добавляет значение СИМВОЛА, равное "J", к строке. Результатом является правильный перевод кода 400 в строку "JOEYNJ".

Рис. 7. Модифицированный алгоритм распаковки
Концепции, использованные в алгоритме сжатия, настолько просты, что весь алгоритм может быть записан в несколько строк. Но так как управление построением таблицы требует некоторых специальных действий, реализация несколько более сложна.
Похожие статьи
-
Идея алгоритма Лемпеля-Зива, Алгоритм LZ77 - Анализ алгоритма Лемпеля-Зива
Основная идея алгоритма Лемпеля-Зива состоит в замене появления фрагмента в данных (группы байт) ссылкой на предыдущее появление этого фрагмента....
-
Сжатие данных можно разделить на два основных типа: 1) Сжатие без потерь или полностью обратимое; 2) Сжатие с потерями, когда несущественная часть данных...
-
Алгоритм LZ78 - Анализ алгоритма Лемпеля-Зива
Этот алгоритм генерирует на основе входных данных словарь фрагментов, внося туда фрагменты данных (последовательности байт) по определенным правилам (см....
-
ВВЕДЕНИЕ - Анализ алгоритма Лемпеля-Зива
Одна из задач любой информационной системы обеспечивать хранение и передачу информации. Причем хранение и передача информации занимают определяющее место...
-
ЗАКЛЮЧЕНИЕ, СПИСОК ЛИТЕРАТУРЫ - Анализ алгоритма Лемпеля-Зива
В данной курсовой работе был подробно рассмотрен один из алгоритмов Лемпеля-Зива (LZW) для упаковки-распаковки произвольных данных. В процессе изучения...
-
Свойства алгоритмов - Алгоритм
Данное выше определение алгоритма нельзя считать строгим - не вполне ясно, что такое "точное предписание" или "последовательность действий,...
-
Прогнозируемая оценка проекта после реализации единой шины данных как прослойки между всеми компонентами ИТ-ландшафта компании выполняется по методу...
-
Предложенный подход к решению задач исследования Используя в качестве основы присутствующее в наличии программное обеспечение, которое применимо к...
-
Процедуры и переменные Таблица с описание процедур: Вызов Название процедуры Предназначение Кнопка "Записать уравнение" TForm1.Button1Click Составление и...
-
Для перехода к описанию выбора средств разработки, необходимо выделить этапы работы программы. Алгоритм работы программы представлен ниже: Пользователь...
-
Криптография, аутентификация - Анализ средств защиты информации в ЛВС
Проблемой защиты информации путем ее преобразования занимается криптология (kryptos - тайный, logos - наука). Криптология разделяется на два направления...
-
Описание используемых методов и алгоритмов - Выбор оптимального маршрута для строительства дороги
В данном пункте нужно проанализировать используемый алгоритм поиска кратчайшего пути. Алгоритм Дейкстры Находит кратчайший путь от одной из вершин графа...
-
Выбор программ и алгоритмы реализации базы данных - База данных "Кинотеатр"
Microsoft Office Access - мощное приложение Windows. При этом производительность СУБД органично сочетаются со всеми удобствами и преимуществами Windows....
-
Встроенный оптимизатор запросов в Teradata может значительно ускорить запрос по сравнению тем, как если бы команды выполнялись ровно так, как подает...
-
Программа реализует алгоритм четырех махов. Входным параметром является имя файла. На выходе печать: является ли граф единичным интервальным,...
-
Теоретические предпосылки исследования Системы поддержки принятия решений Системы поддержки принятия решений (СППР), представляют собой приложения узкого...
-
Программа задания случайных графов Эрдеша - Реньи - Алгоритмы нескольких махов
Программа реализует алгоритм задания случайных графов Эрдеша - Реньи. В качестве входных параметров задаются число вершин и число ребер. Вершины ребер...
-
Работа алгоритма LBFS начинается с заданной вершины графа, которая в общем случае выбирается случайно. Получаемый порядок вершин также может быть основан...
-
Введение - Алгоритмы нескольких махов
Теория графов в последнее время широко используется в различных отраслях науки и техники, особенно в экономике и социологии, а также в генетике,...
-
Итерационные алгоритмы разрезания графа на куски
Лекция Итерационные алгоритмы разрезания графа на куски Суть Итерационных Алгоритмов Разрезания Графов заключается в выборе первого случайного разрезания...
-
Программная модель данных, получившая название "MapReduce", была создана несколько лет назад в компании Google, и там же была осуществлена первая...
-
Постановка задачи, Описание программы, Алгоритм работы - Алгоритм кодировки RSA
Реализовать клиент серверное приложение для пересылки закодированной информации. В качестве алгоритма реализовать алгоритм RSA. Описание программы...
-
Общее описание программного обеспечения, реализующего разработанный алгоритм Основной идеей дипломного проекта, является реализация алгоритма...
-
Методы изображение алгоритмов - Алгоритм
На практике наиболее распространены следующие формы представления алгоритмов: 12. словесная (записи на естественном языке); 13. графическая (изображения...
-
В данном параграфе описывается процесс "Управление ОРД", детальная модель которого представлена в Приложении А. Для наглядной демонстрации была создана...
-
Описание исходных данных На текущий момент (в силу большой загрузки IT-отдела) не реализован доступ к серверу с ХД, маркетинговые данные выгружаются в...
-
Брандмауэр - Анализ средств защиты информации в ЛВС
Наверное, лучше всего начать с описания того, что НЕ является брандмауэром: брандмауэр - это не просто маршрутизатор, хост или группа систем, которые...
-
SPSS Modeler [29] - это программный комплекс, позволяющий строить прогностические модели и применять эту информацию при принятии решений на уровне...
-
Алгоритм для определения силы комбинации - Программа построения равновесных стратегий для игры
В играх типа Omaha для определения силы комбинации необходимо учитывать 9 карт: 4 стартовых карты игрока и 5 общих карт. По стандартным правилам покера...
-
Анализ содержания учебного материала - Освоение среды текстового процессора Word
Содержание курса информатики сегодня претерпевает изменения, продиктованные, прежде всего, расширением его целей и задач. Начиная с 1985 года, основной...
-
Численные эксперименты были проведены для следующих целей: Подтверждение корректности алгоритмов. Подтверждение линейности временных затрат алгоритмов. В...
-
Стек технологий При выборе стека технологий основное внимание уделялось следующим факторам, в порядке убывания значимости: § Кроссплатформенность; §...
-
Для иллюстрации последовательности проводимых работ приведем диаграмму Гантта данного проекта, на которой по оси Х изображены календарные дни от начала...
-
Для ускорения процесса конструирования регулятора в пространстве состояний в Matlab была разработана функция, которая, при должной настройке, позволяет...
-
Сервисы и протоколы. World Wide Web (WWW) - Интернет технологии
World Wide Web (WWW, Всемирная паутина) - это наиболее популярный вид информационных услуг Internet, основанный на архитектуре клиент-сервер. В конце...
-
Межпроцессное взаимодействие - Файловая система Windows 2000
Для общения друг с другом потоки могут использовать широкий спектр возможностей, включая каналы, именованные каналы, почтовые ящики, вызов удаленной...
-
Электронные таблицы. Формулы в MSExcel
1. Электронные таблицы. Формулы в MSExcel Для представления данных в удобном виде используют таблицы. Компьютер позволяет представлять их в электронной...
-
Тема доклада: Файловый ввод/вывод. Функциональный язык программирования Лисп поддерживает широкие возможности для работы с файлами. При этом вводится...
-
Запросы на выборку - Банки и базы данных. Системы управления базами данных
Запросы используются для получения пользователем информации, содержащейся в БД, в удобном для него виде. Результат запроса отображается для пользователя...
-
Кодированием называется представление символов одного алфавита средствами другого алфавита. Алфавит содержащий два символа называется двоичным (часто их...
Модификации алгоритма Лемпеля-Зива, предложенная Терри Уэлчем - Анализ алгоритма Лемпеля-Зива