Методология общесистемного проектирования
14
Курсовая работа
По курсу
Методология общесистемного проектирования
Задача 1
Постановка задачи.
Пусть задана универсальная схема отношений R:
R = A - курс, дисциплина,
B - преподаватель,
C - час начала занятия,
D - аудитория,
E - студент,
T - оценка
Пусть также задано множество функциональных зависимостей:
F= (
|
CDB |
- в аудитории одновременно может быть только один преподаватель; |
|
ACD |
- каждый курс одновременно может читаться только в одной аудитории; |
|
CEA |
- каждый студент одновременно может слушать только один курс; |
|
AB |
- каждый курс ведет только один преподаватель; |
|
CDA |
- в аудитории в один и тот же момент времени может читаться только один курс; |
|
CBD |
- преподаватель в один и тот же момент времени может находиться только в одной аудитории; |
|
AET |
- по каждому курсу каждый студент имеет только одну оценку; |
|
CED |
- студент в один и тот же момент времени может находиться только в одной аудитории |
Задача:
Построить с - хорошую схему БД.
- 1.1. Решение задачи. 1. Положим =0, где - множество схем отношений, которые образуют схему БД. 2. Определим минимальное покрытие G для F: 1) G = (CDB, ACD, CEA, AB, CDA, CBD, AET, CED) 2) A. Проверяем принадлежность XA замыканию (G - XA)+, где XA G:
A) CDB:
G - CDB = (ACD, CEA, AB, CDA, CBD, AET, CED)
(CD)+=CDAB => B (CD)+ => CD>B (G - CD>B) +
Т. о. данная зависимость принадлежит замыканию (G - CDB)+, т. е.
Данная зависимость убирается из G:
G= (ACD, CEA, AB, CDA, CBD, AET, CED)
B) ACD:
G - ACD = (CEA, AB, CDA, CBD, AET, CED)
(AC)+=ACBD => D (AC)+ => ACD (G - ACD) +
Т. о. данная зависимость принадлежит замыканию (G - ACD)+, т. е.
Данная зависимость убирается из G:
G= (CEA, AB, CDA, CBD, AET, CED)
C) CEA:
G - CEA = (AB, CDA, CBD, AET, CED)
(CE)+=CEDATB => A (CE)+ => CEA (G - CEA) +
Т. о. данная зависимость принадлежит замыканию (G - CEA)+, т. е.
Данная зависимость убирается из G:
G= (AB, CDA, CBD, AET, CED)
D) AB:
G - AB = (CDA, CBD, AET, CED)
(A)+=A => B (A)+ => AB (G - AB)
Т. о. данная зависимость не принадлежит замыканию (G - AB)+, т. е. данная зависимость остается в G:
G= (AB, CDA, CBD, AET, CED)
E) CDA:
G - CDA = (AB, CBD, AET, CED)
(CD)+=CD => A (CD)+ => CDA (G - CDA) +
Т. о. данная зависимость не принадлежит замыканию (G - CDA)+, т. е. данная зависимость остается в G:
G= (AB, CDA, CBD, AET, CED)
F) CBD:
G - CBD = (AB, CDA, AET, CED)
(CB)+=CB => D (CB)+ => CBD (G - CBD) +
Т. о. данная зависимость не принадлежит замыканию (G - CBD)+, т. е. данная зависимость остается в G:
G= (AB, CDA, CBD, AET, CED)
G) AET:
G - AET = (AB, CDA, CBD, CED)
(AE)+=AEB => T (AE)+ => AET (G - AET) +
Т. о. данная зависимость не принадлежит замыканию (G - AET)+, т. е. данная зависимость остается в G:
G= (AB, CDA, CBD, AET, CED)
H) CED:
G - CED = (AB, CDA, CBD, AET)
(CE)+= CE => D (CE)+ => CED (G - CED) +
Т. о. данная зависимость не принадлежит замыканию (G - CED)+, т. е. данная зависимость остается в G:
G= (AB, CDA, CBD, AET, CED)
В дальнейшем замыкание атрибутов рассматривается для полученного G.
Б. Проверяем принадлежность ZA замыканию G, где Z X:
A) AB:
Данную функциональную зависимость рассматривать не будем, так как у нее в обеих частях только по одному атрибуту.
B) CDA:
Рассмотрим следующие две зависимости:
CA:
(C)+= C => A (C)+ => CA (G) +. Следовательно, зависимость не заменяется
DA:
(D)+= D => A (D)+ => DA (G) +. Следовательно, зависимость не заменяется
C) CBD:
Рассмотрим следующие две зависимости:
CD:
(C)+= C => D (C)+ => CD (G) +. Следовательно, зависимость не заменяется
BD:
(B)+= B => D (B)+ => BD (G) +. Следовательно, зависимость не заменяется
D) AET:
Рассмотрим следующие две зависимости:
AT:
(A)+= AB => T (A)+ => AT (G) +. Следовательно, зависимость не заменяется
ET:
(E)+= E => T (E)+ => ET (G) +. Следовательно, зависимость не заменяется
E) CED:
Рассмотрим следующие две зависимости:
CD:
(C)+= C => D (C)+ => CD (G) +. Следовательно, зависимость не заменяется
ED:
(E)+= E => D (E)+ => ED (G) +. Следовательно, зависимость не заменяется
Таким образом, G остается без изменений:
G= (AB, CDA, CBD, AET, CED)
3) Данный шаг не выполняется, так как в G нет зависимостей с одинаковой левой частью.
Итак, минимальное покрытие G для F:
G= (AB, CDA, CBD, AET, CED)
3. Получим множество схем отношений Q, заменив каждую зависимость VW из G на VW:
Q=(AB, CDA, CBD, AET, CED)
- 4. Так как ABCDET Q, оставляем без изменений и продолжаем выполнение алгоритма. 5. В Q вошли все атрибуты, следовательно остается без изменений. 6. Добавляем в все схемы отношений из Q:
=(AB, CDA, CBD, AET, CED).
- 7. Определяем ключ для R: 1) i:=0, x0=ABCDET; 2) (BCDET)+=BCDETA=R => x1= BCDET, i:=1; 3) i возросло; 4) (CDET)+=CDETAB=R => x2= CDET, i:=2; 5) i возросло; 6) (DET)+=DETR; (CET)+=CETDAB=R => x3= CDE, i:=3; 7) i возросло; 8) (ET)+=ETR; (CT)+=CTR; (CE)+=CEDATBR => x4= CE, i:=4; 9) i возросло; 10) (C)+=CR; (E)+=ER; 11) i не возросло. Следовательно, x4= CE - ключ схемы отношений R.
Так как ключ найден, то в качестве новой схемы отношений добавлять в какой-либо ключ для R не требуется.
Итак, получаем, что =(AB, CDA, CBD, AET, CED) - "хорошая" схема БД.
Подставляя исходные данные, получим пять таблиц искомой БД:
- 1. {читаемый курс, преподаватель} 2. {час начала занятия, аудитория, читаемый курс} 3. {час начала занятия, преподаватель, аудитория} 4. {читаемый курс, студент, оценка по курсу} 5. {час начала занятия, студент, аудитория}
Ответ:
=(AB, CDA, CBD, AET, CED) - "хорошая" схема БД.
Задача 2
Постановка задачи
Пусть задана грамматика арифметического выражения:
<Z>::=<E>
<E>::=<T>|<T>+<E>|T>-<E>
<T>::=<F>|<F>*<T>|<F>/<T>
<F>::=(<E>) | i
Здесь: +,-,*,/,(,) - операторы,
I - константа или идентификатор,
<Z>,<E>,<T>,<F>- нетерминальные символы.
Задача:
Разработать спецификацию программы восходящего распознавателя для грамматики арифметического выражения. На вход распознавателя подается строка с предложением грамматики. На выходе должны получить результат арифметического выражения. Для описания использовать FlowForm или структурированный естественный язык.
Решение задачи
Прежде чем разрабатывать спецификацию программы распознавателя необходимо определить отношения между операторами. Сведем эти отношения в таблицу:
|
Rs |
+ |
- |
* |
/ |
( |
) | |
|
+ |
?> |
?> |
?< |
?< |
?< |
?> |
?> |
|
- |
?> |
?> |
?< |
?< |
?< |
?> |
?> |
|
* |
?> |
?> |
?> |
?> |
?< |
?> |
?> |
|
/ |
?> |
?> |
?> |
?> |
?< |
?> |
?> |
|
( |
?< |
?< |
?< |
?< |
?< |
?= |
Ошибка |
|
) |
?> |
?> |
?> |
?> |
Ошибка |
?> |
?> |
На основании таблицы отношений между операторами можно ввести следующие функции предшествования:
|
Функция |
+ |
- |
* |
/ |
( |
) | |
|
F |
10 |
10 |
12 |
12 |
8 |
12 |
0 |
|
G |
9 |
9 |
11 |
11 |
13 |
8 |
0 |
Теперь напишем на структурированном естественном языке спецификацию программы восходящего распознавателя в соответствии с алгоритмом входящего распознавателя для любой операторной грамматики.
Спецификация программы
@Вход-строка арифметического выражения
@Выход-результат вычисления арифметического выражения
@Спецификация программы восходящего распознавателя для грамматики арифметического выражения
Создать стек stack1, stack2;
Создать символ S1, S2;
Создать число N1, N2, T;
1: считать символ строки и записать в S2;
ЕСЛИ S2?'+' И S2?'-' И S2?'*' И S2?'/' И S2?'(' И S2?')' И S2?'' ТО
Поместить S2 в stack2;
Перейти к метке 1;
КОНЕЦ ЕСЛИ
2: ЕСЛИ S2='+' ИЛИ S2='-' ИЛИ S2='*' ИЛИ S2='/' ИЛИ S2='(' ИЛИ S2=')' ИЛИ S2=''
Считать последний из stack1 в S1;
ЕСЛИ f(S1) < g(S2) ТО
Поместить S2 в stack1;
Перейти к метке 1;
КОНЕЦ ЕСЛИ
ЕСЛИ f(S1) > g(S2) ТО
Вызвать программу обработки S1;
Считать последний из stack2 в N1;
Считать последний из stack2 в N2;
ЕСЛИ S1 ='+' ТО
T = N1 + N2;
КОНЕЦ ЕСЛИ
ЕСЛИ S1 ='-' ТО
T = N1 - N2;
КОНЕЦ ЕСЛИ
ЕСЛИ S1 = '*' ТО з
T = N1 * N2;
КОНЕЦ ЕСЛИ
ЕСЛИ S1 = '/' ТО
T = N1 / N2;
КОНЕЦ ЕСЛИ
Удалить S1 из stack1;
Удалить N1 из stack2;
Удалить N2 из stack2;
Поместить T в stack2;
ЕСЛИ S1 = '' и stack1 пуст ТО
Перейти к метке 3;
КОНЕЦ ЕСЛИ
Перейти к метке 2;
КОНЕЦ ЕСЛИ
ЕСЛИ f(S1) = g(S2) ТО
Удалить S1 из stack 1;
Перейти к метке 1;
КОНЕЦ ЕСЛИ
КОНЕЦ ЕСЛИ
3: считать stack2 в T;
Выйти с результатом T;
@Конец спецификации
Задача 3
Постановка задачи
Пусть задана схема БД с = (S, P, J, SPJ)
В схеме содержатся следующие таблицы, имеющие указанные поля:
- S - Поставщик; S = (Номер_поставщика, имя, состояние, город)
P - Деталь;
P = (Номер_детали, Название, цвет, вес, город)
J - Изделие;
J = (Номер_изделия, Название, город)
SPJ - Сборка;
SPJ = (Номер_поставщика, номер_детали, номер_изделия, Количество деталей)
Задача:
Написать следующие запросы SQL:
- 1. Выдать номера изделий и названия городов, где они изготавливаются, такие, что второй буквой названия города является буква 'е'. 2. Выдать номера деталей, поставляемых для какого-либо изделия поставщиком, проживающим в том же городе, где изготавливается это изделие. 3. Выдать номера поставщиков, поставляющих детали с номером 'P1' для какого-либо изделия в количестве большим, чем средний объем поставок детали с номером 'P1' для этого изделия. 4. Выдать номера изделий, для которых детали поставляет только поставщик с номером 'S1'.
Решение задачи
SELECT номер_изделия, город
FROM J
WHERE город LIKE '_е%';
SELECT DISTINCT SPJ. деталь
FROM J, S, SPJ
WHERE S. номер=SPJ. поставщик AND J. номер=SPJ. изделие AND S. город=J.[город изготовления];
SELECT DISTINCT номер_поставщика
FROM SPJ SX
WHERE номер_детали = 'P1' AND
Количество>(SELECT AVG(количество)
FROM SPJ
WHERE номер_изделия = SX. номер_изделия AND
Номер_детали = 'P1');
SELECT DISTINCT номер_изделия
FROM SPJ SX
WHERE NOT EXISTS
(SELECT *
FROM SPJ
WHERE номер_изделия = SX. номер_изделия AND
Номер_поставщика!= 'S1' );
Задача 4
Постановка задачи
Пусть заданы следующие отношения:
S - поставщик детали; S = (Номер_поставщика, фамилия, состояние, город)
P - деталь; P = (Номер_детали, Название, цвет, вес, город)
J - изделие; J = (Номер_изделия, Название, город)
SPJ - поставщик, который поставляет детали для изделия в определенном количестве;
SPJ = (Номер_поставщика, номер_детали, номер_изделия, Количество)
Пусть на сервер базы данных поступает оператор SELECT, соответствующий следующему запросу: "Выдать имена поставщиков из Лондона, которые поставляют для изделия с номером 'J1', по крайне мере, одну красную деталь".
- 1. Написать соответствующий оператор SELECT и построить логический план выполнения этого оператора. 2. Определить оптимальный физический план выполнения оператора при следующих исходных данных: 1) Количество записей в таблицах: T(S) = 10000, T(P) = 100000, T(SPJ) = 1000000; 2) Количество записей в одном блоке таблицы: LJ = 500, LP = 500, LJoin = 2000, LSPJ =1000; 3) Индексы по атрибутам и число записей таблицы в одном блоке индекса (L):
Таблица S - 1) индекс по атрибуту "номер поставщика", L=200
Таблица Р - 1) индекс по атрибуту "номер детали", L=200
Таблица SPJ - 1) индекс по атрибуту "номер поставщика", L=200
- 2) индекс по атрибуту "номер детали", L=200 3) индекс по атрибуту "номер изделия", L=200
Примечания:
- - записи таблиц могут читаться в отсортированном виде по своим индексированным атрибутам; - записи во всех таблицах не сгруппированы(нет кластеризации). 4) Мощности атрибутов:
I(S, город)=50, I(S, номер поставщика)=10000,
I(Р, цвет)=20, I(Р, номер детали)=100000,
I(SPJ, номер поставщика)=5000, I(SPJ, номер детали)=100000,
I(SPJ, номер изделия)= 10000
- 5) Число блоков b = 10, CСomp = СMove = CFilter = 0.01 мс, СВ = 10 мс; 6) Предполагается, что используются левосторонние деревья для поиска оптимального плана и применяются каналы.
Примечание:
Метод хешированного соединения не рассматривать.
Решение задачи
Оператор SELECT, соответствующий исходному запросу:
SELECT имя
FROM S, P, SPJ
WHERE S. город = 'Лондон' AND
P. цвет = 'красный' AND
SPJ. номер_изделия = 'J1' AND
S. номер_поставщика = SPJ. номер_поставщика AND
P. номер_детали = SPJ. номер_детали ;
Этому запросу соответствует следующая формула реляционной алгебры:
Р S. имя (у S. город='Лондон' AND (S?P?SPJ)) .
P. цвет = 'красный' AND
SPJ. номер_изделия = 'J1' AND
S. номер_поставщика = SPJ. номер_поставщика AND
P. номер_детали = SPJ. номер_детали
Программа запрос реляционный алгебра
Введем следующие обозначения для условий:
FS::= (S. город = 'Лондон')
FP::= (P. цвет = 'красный')
FSPJ::= (SPJ. номер_изделия = 'J1')
JFS::= (S. номер_поставщика = SPJ. номер_поставщика)
JFP::= (P. номер_детали = SPJ. номер_детали)
Оптимизируем приведенную выше формулу, используя законы реляционной алгебры:
Р S. имя (у FS AND FP AND FSPJ AND JFS AND JFP (S?P?SPJ)) = р S. имя (у JFS AND JFP (у FS AND FP AND FSPJ (S?P?SPJ)) = р S. имя (у JFS AND JFP (у FS(S) ? у FP(P) ? у FSPJ(SPJ))) =
= р S. имя (у JFS AND JFP (р S. имя, (у FS(S) ? у FP(P) ? у FSPJ(SPJ)))) =
S. номер_поставщика,
P. номер_детали,
SPJ. номер_поставщика,
SPJ. номер_детали
= р S. имя (у JFS AND JFP (р S. имя, (у FS(S)) ? р P. номер_детали(у FP(P)) ? р SPJ. номер_поставщика,(у FSPJ(SPJ)))) .
S. номер_поставщикаSPJ. номер_детали
Заменяя введенные выше обозначения FS, FP, FSPJ, JFS и JFP соответствующими им условиями, получим следующий логический план выполнения запроса.

Определение методов выбора записей из исходных таблиц
1) Таблица S.
J = 1 - чтение всей таблицы:
С1 = СCPU1+ СI/O1= T(S)-CFilter + B(S)-CB .
Учитывая, что B(S) = T(S) / LS, и подставляя значения исходных данных, получим:
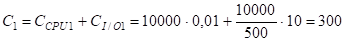
(мс).
J = 2 - чтение по индексу - не рассматривается, так как нет индекса по атрибуту "Город".
С = С1 = 300 мс - стоимость выбора записей из таблицы S; метод выбора k=1.
СI/O = СI/O1 = 200 мс - составляющая ввода-вывода.
Определим характеристики таблицы Q1, являющейся результатом выполнения подзапроса.
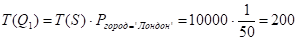
- число записей в таблице Q1.
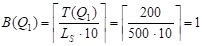
- число блоков в таблице Q1.
I(Q1, номер_поставщика) = min {T(Q1), I(S, номер_поставщика)} = min {200, 10000} = 200 - мощность атрибута "Номер_поставщика" в таблице Q1 (этот атрибут потребуется при соединении таблиц).
Заполним экземпляр структуры str[1]:
Str[1]= { {Q1}, O, O, // W, X, Y
300, 200,// Z, ZIO
{ 200, 1, {200}, 1}// V: T(Q1), B(Q1), {I(Q1, номер_поставщика)}, k
}.
2) Таблица P.
J = 1 - чтение всей таблицы:
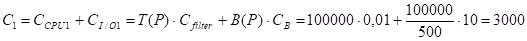
.
С1 = 3000 мс
J = 2 - чтение по индексу - не рассматривается, так как нет индекса по атрибуту "Цвет".
С = С1 = 3000 мс ; k=1.
СI/O = СI/O1 = 200 мс.
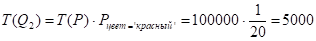
.
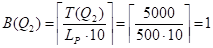
.
I(Q2, номер_детали) = min {T(Q2), I(P, номер_детали)} = min {5000, 100000} = 5000 .
Экземпляр структуры str[2]:
Str[2]= { {Q2}, O, O, // W, X, Y
3000, 2000,// Z, ZIO
{ 5000, 1, {5000}, 1}// V: T(Q2), B(Q2), {I(Q2, номер_детали)}, k
}.
3) Таблица SPJ.
J = 1 - чтение всей таблицы:
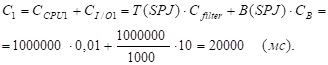
J = 2 - чтение по индексу; используется индекс по атрибуту "Номер_изделия":
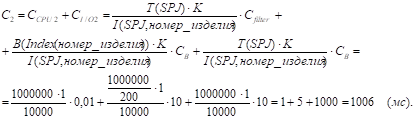
Здесь K=1 - мощность атрибута "Номер_изделия" в запросе, B(Index(номер_изделия)) - число блоков листьевого уровня индекса по атрибуту "Номер_изделия". Записи таблицы SPJ не сгруппированы по атрибуту "Номер_изделия", поэтому в последнее слагаемое входит T(SPJ).
С = min {С1, C2} = C2 =1006 мс ; k=2.
СI/O = СI/O2 = 1005 мс.
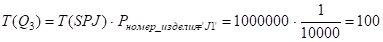
.
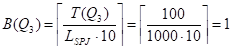
.
I(Q3, номер_поставщика) = min {T(Q3), I(SPJ, номер_поставщика)} = min {100, 5000} = 100.
I(Q3, номер_детали) = min {T(Q3), I(SPJ, номер_детали)} = min {100, 100000} = 100 .
Экземпляр структуры str[3]:
Str[3]= { {Q3}, O, O, // W, X, Y
1006, 1005,// Z, ZIO
{ 100, 1, {100, 100}, 2}// V: T(Q3), B(Q3), { I(Q3, номер_поставщика),
// I(Q3, номер_детали)}, k
}.
Определение методов соединения
- 1) I = 2. Рассматриваем такие подмножества P множества таблиц {Q1, Q2, Q3}, мощность которых равна 2. Подмножество {Q1, Q2} не рассматриваем, поскольку у таблиц Q1 И Q2 нет общих атрибутов и поэтому выполнять их соединение нецелесообразно. 2) Рассматриваем подмножество P={Q1, Q3}.
QJ = Q1.
R = P - QJ = Q3, S=Q1 - аргументы соединения.
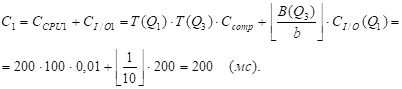
M1=3, m2=1 - номера экземпляров структуры str, соответствующих аргументам соединения.
- А) Метод NLJ, i1=1. Б) Метод SMJ, i1=2.
Поскольку таблицы Q3 и Q1 уже отсортированы по атрибуту "Номер_поставщика" (имеются соответствующие индексы) и I(Q3, номер_поставщика) < I(Q1, номер_поставщика) (эти мощности равны 100 и 200 соответственно), получим:
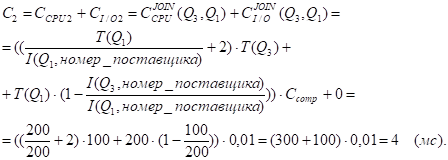
Значение СI/OJOIN(Q3, Q1) равно 0, поскольку B(Q1) < I(Q1, номер_поставщика) (1 < 200).
С = min {С1, C2} = C2 =4 мс ; k=2.
СI/O = СI/O2 = 0 .
Полученные значения C и CI/O учитывают только соединение таблиц. Добавляя к ним стоимости получения аргументов соединения, получим:
C = str[3].Z + str[1].Z + C = 1006 + 300 + 4 = 1310 (мс);
СI/O = str[3].ZIO + str[1].ZIO + СI/O = 1005 + 200 + 0 =1205 (мс).
Определим характеристики таблицы, являющейся результатом соединения.
Число записей:
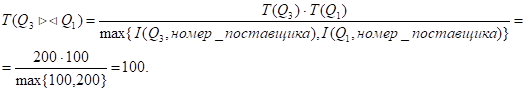
Число блоков:
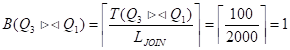
.
Мощность атрибута соединения:
Мощность атрибута "Номер_детали", который потребуется для соединения данной таблицы с таблицей Q2:
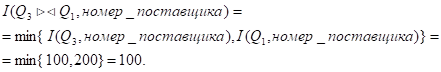
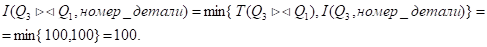
Экземпляр структуры str[4]:
Str[4]= { {Q1, Q3}, {Q3}, {Q1}, // W, X, Y
1310, 1205,// Z, ZIO
{ 100, 1, {100, 100}, 2}// V: T(Q3><Q1), B(Q3><Q1),
// { I(Q3><Q1, номер_поставщика),
// I(Q3><Q1, номер_детали)}, k
}.
3) QJ = Q3.
R = P - QJ = Q1, S=Q3 .
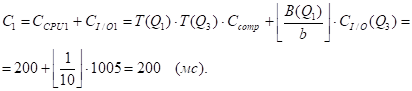
M1=1, m2=3 .
- А) Метод NLJ, i1=1. Б) Метод SMJ, i1=2.
Таблицы Q1 и Q3 уже отсортированы по атрибуту "Номер_поставщика"; кроме того, I(Q3, номер_поставщика) < I(Q1, номер_поставщика), поэтому
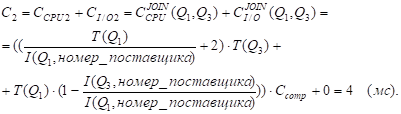
Значение СI/OJOIN(Q1, Q3) равно 0, поскольку B(Q3) < I(Q3, номер_поставщика) (1 < 100).
С = min {С1, C2} = C2 =4 мс ; k=2.
СI/O = СI/O2 = 0 .
C = str[3].Z + str[1].Z + C = 1006 + 300 + 4 = 1310 (мс).
Это значение С совпадает с рассчитанным выше значением str[4].Z, поэтому экземпляр структуры str[4] не изменяется.
2) Рассматриваем подмножество P={Q2, Q3}.
QJ = Q3.
R = P - QJ = Q2, S=Q3 .
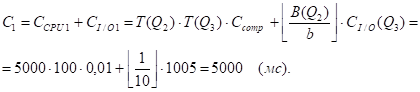
M1=2, m2=3 .
- А) Метод NLJ, i1=1. Б) Метод SMJ, i1=2.
Поскольку таблицы Q2 и Q3 уже отсортированы по атрибуту "Номер_детали" (имеются соответствующие индексы) и I(Q3, номер_детали) < I(Q2, номер_детали) (эти мощности равны 100 и 5000 соответственно), получим:
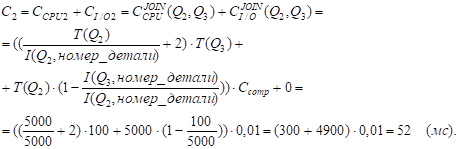
Значение СI/OJOIN(Q2, Q3) равно 0,
Поскольку B(Q3) < I(Q3, номер_детали) (1 < 100).
С = min {С1, C2} = C2 = 52 мс ; k=2.
СI/O = СI/O2 = 0 .
C = str[2].Z + str[3].Z + C = 3000 + 1006 + 52 = 4058 (мс);
СI/O = str[2].ZIO + str[3].ZIO + СI/O = 2000 + 1005 + 0 =3005 (мс).
Определим характеристики таблицы, являющейся результатом соединения.
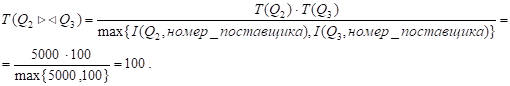
.
Мощность атрибута соединения:
Мощность атрибута "Номер_поставщика", который потребуется для соединения данной таблицы с таблицей Q1:
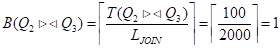

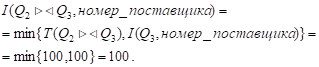
Экземпляр структуры str[5]:
Str[5]= { {Q2, Q3}, {Q2}, {Q3}, // W, X, Y
4058, 3005,// Z, ZIO
{ 100, 1, {100, 100}, 2}// V: T(Q2><Q3), B(Q2><Q3),
// { I(Q2><Q3, номер_поставщика),
// I(Q2><Q3, номер_детали)}, k
}.
QJ = Q2.
R = P - QJ = Q3, S=Q2 .
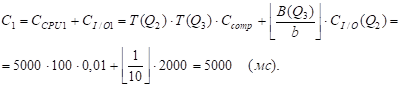
M1=3, m2=2 .
- А) Метод NLJ, i1=1. Б) Метод SMJ, i1=2.
Таблицы Q2 и Q3 уже отсортированы по атрибуту "Номер_поставщика"; кроме того, I(Q3, номер_ детали) < I(Q2, номер_детали), поэтому
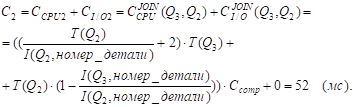
Значение СI/OJOIN(Q3, Q2) равно 0, поскольку B(Q2) < I(Q2, номер_детали) (1 < 5000).
С = min {С1, C2} = C2 = 52 мс ; k=2.
СI/O = СI/O2 = 0 .
C = str[3].Z + str[2].Z + C = 3000 + 1006 + 52 = 4058 (мс).
Это значение С совпадает с рассчитанным выше значением str[5].Z, поэтому экземпляр структуры str[5] не изменяется.
1) i = 3. Рассматриваем подмножества P множества таблиц {Q1, Q2, Q3}, мощность которых равна 3. Такое подмножество одно - это само множество {Q1, Q2, Q3}.
P={Q1, Q2, Q3}.
QJ = Q1.
R = P - QJ ={Q2, Q3}, S=Q1 .
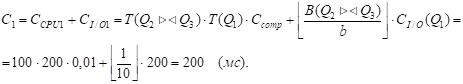
M1=5, m2=1 .
- А) Метод NLJ, i1=1. Б) Метод SMJ, i1=2.
Таблица Q1 уже отсортирована по атрибуту "Номер_поставщика"; результат соединения таблиц Q2 и Q3 нужно отсортировать.
Соотношение мощностей атрибутов:
I(Q2><Q3, номер_поставщика) < I(Q1, номер_ поставщика) (100 < 200 соответственно).
Исходя из этого, рассчитываем стоимость соединения следующим образом:
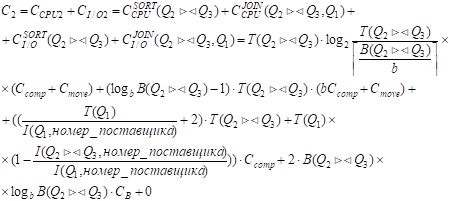
Значение СI/OJOIN(Q2><Q3, Q1) равно 0, поскольку B(Q1) < I(Q1, номер_поставщика) (1 < 200).
Подставляя числовые значения величин, получим:
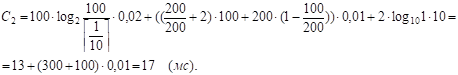
Слагаемое, содержащее множитель (log BB(Q2><Q3) - 1), не учитываем, поскольку B(Q2><Q3) = 1.
С = min {С1, C2} = C2 = 17 мс ; k=2.
СI/O = СI/O2 = 0 .
C = str[5].Z + str[1].Z + C = 4058 + 300 + 17 = 4375 (мс);
СI/O = str[5].ZIO + str[1].ZIO + СI/O = 3005 + 200 + 0 =3205 (мс).
Определим характеристики таблицы, являющейся результатом соединения.
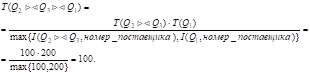
.
Мощность атрибута соединения:
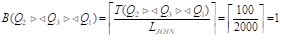
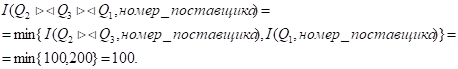
Экземпляр структуры str[6]:
Str[6]= { { Q1, Q2, Q3}, { Q2, Q3}, {Q1}, // W, X, Y
4375, 3205,// Z, ZIO
{ 100, 1, {100}, 2}// V: T(Q2><Q3><Q1), B(Q2><Q3><Q1),
// { I(Q2><Q3><Q1, номер_поставщика)}, k
}.
QJ = Q2.
R = P - QJ ={Q1, Q3}, S=Q2 .
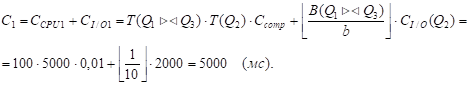
M1=4, m2=2 .
- А) Метод NLJ, i1=1. Б) Метод SMJ, i1=2.
Таблица Q2 уже отсортирована по атрибуту "Номер_детали"; результат соединения таблиц Q1 и Q3 нужно отсортировать.
Соотношение мощностей атрибутов:
I(Q1><Q3, номер_детали) < I(Q2, номер_детали) (100 < 5000).
Исходя из этого, рассчитываем стоимость соединения следующим образом:
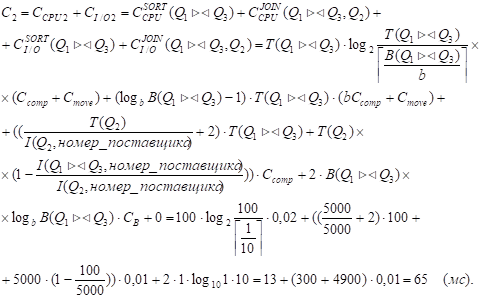
Слагаемое, содержащее множитель (log BB(Q1><Q3) - 1), не учитываем, поскольку B(Q1><Q3) = 1.
Значение СI/OJOIN(Q1><Q3, Q2) равно 0, поскольку B(Q2) < I(Q2, номер_детали) (1 < 5000).
С = min {С1, C2} = C2 = 65 мс ; k=2.
СI/O = СI/O2 = 0 .
C = str[4].Z + str[2].Z + C = 1310 + 3000 + 65 = 4375 (мс).
Это значение С совпадает с рассчитанным выше значением str[6].Z, поэтому экземпляр структуры str[6] не изменяется.
Оптимальный план найден.
Выводы
В результате оптимизации получен следующий физический план выполнения запроса.
- (Q1, Q2, Q3) = (Q2, Q3) >< Q1, метод SMJ (Q2, Q3) = Q2 >< Q3, метод SMJ
Q2 = метод TableScan(P) + Filter(P. цвет = 'красный', рP. номер_детали)
Q3 = метод IndexScan(SPJ, номер_изделия = 'J1') + Filter(рSPJ. номер_поставщика, SPJ. номер_детали)
Q1 = метод TableScan(S) + Filter(S. город = 'Лондон', рS. имя, S. номер_поставщика)
Похожие статьи
-
При работе над проектом разрабатывались два основных компонента системы: база данных (далее - БД) и интерфейс клиентского приложения. Затем необходимо...
-
Возрастающая сложность современных автоматизированных систем управления и повышение требовательности к ним обуславливает применение эффективных...
-
Целью дипломного проекта "Калькулятор коммунальных услуг" является разработка программного средства "Calculation. exe". Для достижения цели дипломного...
-
Каждая СУБД имеет особенности в представлении структуры таблиц, связей, определении типов данных и т. д. которую необходимо учитывать при проектировании....
-
Даталогическое проектирование - Банки и базы данных. Системы управления базами данных
Даталогической моделью БД называется модель логического уровня, построенная в рамках конкретной СУБД, в среде которой проектируется БД. Описание...
-
Все IP-адреса в автономных системах имеют "серый" адрес, то есть адрес, которым нельзя воспользоваться для выхода в Интернет (классы таких адресов были...
-
Высокая плотность размещения элементов ЭВА создает большие трудности при реализации соединений между ними. В этой связи задача размещения элементов на...
-
Логический уровень описания базы данных (логическая модель) отражает логические связи между таблицами. Логическая модель базы данных "Прокат автомобилей"...
-
Описание входной и выходной информации "Учет продаж футбольной атрибутики и спортивных товаров". Входная информация задачи: 1. Условно постоянная...
-
Введение - Проектирование и разработка базы данных "Прокат автомобилей"
В настоящее время большинство организаций используют различные базы данных для автоматизации процессов обработки информации, удобства ее эксплуатации,...
-
Инфологическое проектирование Стандартным способом представления концептуальной модели базы данных являются диаграммы "сущность-связь" (ERD),...
-
Обоснование выбора СУБД База данных - это совокупность сведений о реальных объектах, процессах, событиях или явлениях, относящихся к определенной теме...
-
Выбор интерфейса Пользовательский интерфейс представляет собой совокупность программных и аппаратных средств, обеспечивающих взаимодействие пользователя...
-
Значение сигнала A в течение 5 тактов = 1, 1 такта - 0 . Далее идет повторение. Период сигнала составляет 6 тактов. Таблица 1 Q2 Q1 Q0 A 1 0 0 0 1 0 0 0...
-
Разработать и создать аналог системной утилиты "Диспетчер задач" по дисциплине "Системное программирование". "Диспетчер задач" должен содержать следующие...
-
Для реализации устройства управления потребуются: генератор слов, логические элементы (И, ИЛИ, НЕ), счетчики и логический анализатор. Ниже приведены...
-
Методы разработки вычислительной сети: 1. Экспериментальный метод - персонал предприятия закупает "новинки" рынка компьютерной техники. Такой метод -...
-
Исходя из результатов, полученных на предыдущем шаге, была построена общая функциональная схема информационно-поисковой системы (рис. 3.12)....
-
Заключение - Проектирование автоматизированной информационной системы
В любой компании возникает проблема такой организации управления данными, которая обеспечила бы наиболее эффективную работу. Проектирование рациональных...
-
Цель создания САПР - Состав систем автоматизированного проектирования
Под автоматизацией проектирования понимают систематическое применение ЭВМ в процессе проектирования при научно обоснованном распределении функций между...
-
В разработке системы принимал участие один инженер-программист. Длительность выполнения работ по проектированию и разработке системы представлена в...
-
Проектирование и разработка таблиц - База данных "Кинотеатр"
Для создания базы данных мы должны спроектировать таблицы, где будем задавать необходимые поля с соответствующим типом данных. Таблица 1 "Сотрудники" Имя...
-
Проектирование систем видеонаблюдения и используемые компоненты Рассмотрим первый тип систем видеонаблюдения - специализированый комплект оборудования....
-
Физическая модель базы данных определяет способ размещения данных в среде хранения и способ доступа к этим данным, которые поддерживаются на физическом...
-
Пользовательский интерфейс обеспечивает взаимодействие между пользователем и компьютером, обмен действиями и ответными реакциями на них. Стоит начать с...
-
Этапы проектирования и создания БД - Система управления базами данных
При разработке БД можно выделить следующие этапы работы. I этап. Постановка задачи. На этом этапе формируется задание по созданию БД. В нем подробно...
-
Распечатки экранов ПК Рис.5. Форма "Главное меню" Рис.6. Форма "Специальности" Рис.7. Форма "Личные карточки" Рис.8. Форма "Поощрения" Рис.9. Форма...
-
Модульное проектирование - Теоретические основы информационных технологий
Реализация метода Нисходящего проектирования тесно связана с другим понятием программирования - Модульным проектированием , так как на практике при...
-
Расчет диаметра сети - Проектирование учебной локальной вычислительной сети
Методика определения диаметра сети может быть оформлена в виде таблицы. Номера строк и столбцов в ней соответствуют индиентификаторам рабочих станций на...
-
- установить свойство Align в значение AlBottom ; - выбрать свойство Panels и с помощью кнопки в левом верхнем углу разбить панель на две части (рисунок...
-
Входная информация разделяется на условно-постоянную и оперативно-учетную информацию. - Условно-постоянная информация включает в себя справочные данные о...
-
Метод представления знаний при проектировании модели - Искусственный интеллект
Предлагаемая модель ИИ основывается на когнитивных картах - некотором базовом знании о мире. Ключевые идеи, положенные в основу этой концепции, сходны с...
-
Методы и средства проектирования - Автоматизированные системы обработки экономической информации
Проектирование - процесс создания проекта-прототипа, прообраза предполагаемого или возможного объекта, его состояния. Современная технология создания АИС...
-
Разработка логической модели АИС - Проектирование автоматизированной информационной системы
Логическая модель данных является начальным прототипом будущей базы данных. Логическая модель строится в терминах информационных единиц, но без привязки...
-
В настоящее время существует несколько видов СУБД. Для создания базы данных "Учет посещаемости в детском саду" была выбрана СУБД Paradox. Выбор...
-
Предлагаемая библиотека хранит все данные в отдельных таблицах, таким образом он не обязан использовать ту же СУБД, что и основное приложение. В качестве...
-
Самым традиционным и широко известным из структурированных типов данных является массив (иначе называемый регулярным типом) - однородная упорядоченная...
-
В процессе выполнения данного курсового проекта были получены уравнения заданных последовательностей сигналов, проведена минимизация полученных в...
-
Рисунок 6. Логическая схема сети жилых зданий. (AS4200 и 4300) Switch - коммутатор 2-го уровня. Router - маршрутизатор 3 уровня. Server-PT - Веб сервер,...
-
Исходя из рисунка 2.1.1 и технического задания видно, что: - Требуется подключить три компьютера на три рабочих места в приемной; - Один компьютер...
Методология общесистемного проектирования