Идея алгоритма Лемпеля-Зива, Алгоритм LZ77 - Анализ алгоритма Лемпеля-Зива
Основная идея алгоритма Лемпеля-Зива состоит в замене появления фрагмента в данных (группы байт) ссылкой на предыдущее появление этого фрагмента. Существуют два основных класса методов, названных в честь Якоба Зива (Jakob Ziv) и Абрахама Лемпеля (Abraham Lempel), впервые предложивших их в 1977 (алгоритм LZ77) и 1978 годах (алгоритм LZ78).
Алгоритм LZ77
LZ77 [2] использует уже просмотренную часть сообщения как словарь. Чтобы добиться сжатия, он пытается заменить очередной фрагмент сообщения на указатель в содержимое словаря. Алгоритм LZ77 предлагает оригинальное решение для устройства словаря. Вместо построения словаря для хранения фрагментов в виде отдельной структуры данных LZ77 предлагает использовать предшествующий фрагмент исходных данных конечной длины как готовый словарь.
Метод LZ77 оперирует двумя элементами данных:
- 1) Буфер предыстории - уже обработанный фрагмент исходных данных фиксированной длины; 2) Буфер предпросмотра - еще не обработанный фрагмент данных, следующий за буфером предыстории.
Метод LZ77 пытается найти в буфере предыстории, фрагмент текста максимальной длины из буфера предпросмотра и когда это удается, то на выход выдается пара значений, соответствующая позиции фрагмента в буфере предыстории и длине фрагмента, иначе выводится первый символ буфера предпросмотра и повторяется попытка поиска для следующего фрагмента. В упрощенном виде алгоритм можно записать, как это показано на рис.1.
Это утверждение возможно справедливо при стремлении словаря к бесконечному размеру, но при сжатии конкретного файла может наблюдаться обратный эффект, когда размер сжатого файла увеличивается с ростом словаря.
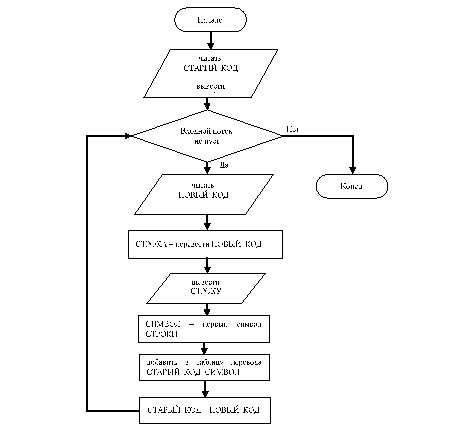
Рис. 1. Упрощенный алгоритм кодирования LZ77
LZ77 передвигает окно фиксированного размера (буфер предыстории) по данным. Очевидно, что наилучшего результата можно было бы достичь, если бы буфер предыстории был бы по размеру равен данным, но на практике используют ограниченный буфер (обычно16 или32 кБайт). Это обусловлено, как очевидными ограничениями по размерам ОЗУ, так и необходимостью ограничить время поиска фрагмента в буфере.
Поскольку метод не требует построения словаря, а для поиска фрагмента в буфере существуют очень эффективные алгоритмы, то LZ77 широко применяется на практике. Большинство коммерческих архиваторов (ace, arj, lha, zip, zoo) являются комбинацией LZ77 и метода Хаффмана (или арифметического кодирования). Наиболее используемые алгоритмы происходят от метода LZSS, описанного Джеймсом Сторером (James Storer) и Томасом Шимански (Thomas Szymanski) в 1982 г.
Похожие статьи
-
Алгоритм LZ78 - Анализ алгоритма Лемпеля-Зива
Этот алгоритм генерирует на основе входных данных словарь фрагментов, внося туда фрагменты данных (последовательности байт) по определенным правилам (см....
-
Модификации алгоритма Лемпеля-Зива, предложенная Терри Уэлчем - Анализ алгоритма Лемпеля-Зива
В 1984 году Терри Уэлч (Terry Welch) предложил адаптивный сброс словаря для алгоритма LZ78 [3]. В этом случае при заполнении словаря сброс словаря не...
-
Сжатие данных можно разделить на два основных типа: 1) Сжатие без потерь или полностью обратимое; 2) Сжатие с потерями, когда несущественная часть данных...
-
ЗАКЛЮЧЕНИЕ, СПИСОК ЛИТЕРАТУРЫ - Анализ алгоритма Лемпеля-Зива
В данной курсовой работе был подробно рассмотрен один из алгоритмов Лемпеля-Зива (LZW) для упаковки-распаковки произвольных данных. В процессе изучения...
-
ВВЕДЕНИЕ - Анализ алгоритма Лемпеля-Зива
Одна из задач любой информационной системы обеспечивать хранение и передачу информации. Причем хранение и передача информации занимают определяющее место...
-
МЕТОДОВ МЕТОД СОРТИРОВКИ Пирамидальная сортировка Пирамидальная сортировка основана на алгоритме построения пирамиды. Последовательность aI, aI+1,...,aK...
-
Криптография, аутентификация - Анализ средств защиты информации в ЛВС
Проблемой защиты информации путем ее преобразования занимается криптология (kryptos - тайный, logos - наука). Криптология разделяется на два направления...
-
Предложенный подход к решению задач исследования Используя в качестве основы присутствующее в наличии программное обеспечение, которое применимо к...
-
Определение методов реинжиниринга информационных систем Основные задачи, которые стоят перед проектировщиком, занимающимся реинжинирингом информационных...
-
Формы и характеристики параллелизма Параллелизм -- это возможность одновременного выполнения нескольких арифметико-логических или служебных операций. На...
-
Обновленная база данных должна иметь продвинутую структуру пользователей для использования на информационном портале под управлением новой CMS. Для...
-
Обзор протокола Multi-Touch технологий передачи данных TUIO [7] - основной кроссплатформенный протокол с открытым исходным кодом Multi-Touch передачи...
-
Выходные данные для работы программы представляют собой матрицу типа "функции-данные", где связь бизнес-функций и элементов данных описывается большим...
-
Общее описание программного обеспечения, реализующего разработанный алгоритм Основной идеей дипломного проекта, является реализация алгоритма...
-
Теоретические предпосылки исследования Системы поддержки принятия решений Системы поддержки принятия решений (СППР), представляют собой приложения узкого...
-
Для ускорения процесса конструирования регулятора в пространстве состояний в Matlab была разработана функция, которая, при должной настройке, позволяет...
-
Работа алгоритма LBFS начинается с заданной вершины графа, которая в общем случае выбирается случайно. Получаемый порядок вершин также может быть основан...
-
Данный алгоритм (англ. Maximal Neighborhood Search - MNS) [7] в отличие от алгоритма BFS позволяет дополнительно упорядочить вершины в найденных...
-
Введение - Алгоритмы нескольких махов
Теория графов в последнее время широко используется в различных отраслях науки и техники, особенно в экономике и социологии, а также в генетике,...
-
Постановка задачи Необходимо разработать программу для поиска автобусных маршрутов. В качестве среды разработки должна использоваться Delphi 7. В...
-
С целью выбора платформы для внедрения программного модуля необходимо сравнить интеграционные платформы Интернета вещей с помощью определенных критериев....
-
Анализ принципа работы БП адаптера связи ОП - Работка буферной памяти адаптера связи
Буферная память этопамять для промежуточного хранения данных. Применяется при обмене данными между двумя устройствами, обладающими различной скоростью...
-
Программная модель данных, получившая название "MapReduce", была создана несколько лет назад в компании Google, и там же была осуществлена первая...
-
Анализ требований к информационной системе - Отдел кадров Internet-провайдера
Разрабатываемая ИС "Учет кадров Internet-провайдера" должна обеспечивать автоматизацию деятельности специалиста по кадрам. Для этого создаваемая система...
-
Прогнозирование оттока клиентов Отделом маркетинга компании ELEMENTAREE было выявлено, что практически все клиенты, у которых отсутствовали заказы в...
-
Для перехода к описанию выбора средств разработки, необходимо выделить этапы работы программы. Алгоритм работы программы представлен ниже: Пользователь...
-
Процедуры и переменные Таблица с описание процедур: Вызов Название процедуры Предназначение Кнопка "Записать уравнение" TForm1.Button1Click Составление и...
-
Цель Работы - изучить основные способы работы с пользовательским типом данных "класс", его объектами, методами и способы доступа к ним. - Теоретические...
-
ОПИСАНИЕ ПРОГРАММЫ, ОСНОВНЫЕ ПЕРЕМЕННЫЕ И СТРУКТУРЫ - Структуры и алгоритмы обработки данных
ОСНОВНЫЕ ПЕРЕМЕННЫЕ И СТРУКТУРЫ Struct BD { char FIO[32]; // фоpмат <Фамилия>_<Имя>_<Отчество> int numberO; char dolzhnost[32]; char dateB[8]; }...
-
ОСОБЕННОСТИ РЕАЛИЗАЦИИ АЛГОРИТМОВ - Структуры и алгоритмы обработки данных
В ходе выполнения курсовой работы, помимо основных алгоритмов, потребовалось реализовать также несколько вспомогательных, необходимых для корректной...
-
ДВОИЧНЫЙ ПОИСК, АВЛ-Дерево - Структуры и алгоритмы обработки данных
Алгоритм двоичного поиска в упорядоченном массиве сводится к следующему. Берем средний элемент отсортированного массива и сравниваем с ключом X. Возможны...
-
С увеличением размерности таблицы существенно возрастает вероятность появления некорректных данных, так как таблица заполняется вручную. При средней...
-
Так как матрица типа "функции-данные" является подвидом CRUD-матриц, сначала необходимо разобраться, что из себя представляет данный метод; затем...
-
Корпоративная интеграционная подсистема на базе IBM WebSphere Business Integration Message Broker [28] отвечает за выстраивание корпоративной...
-
Брандмауэр - Анализ средств защиты информации в ЛВС
Наверное, лучше всего начать с описания того, что НЕ является брандмауэром: брандмауэр - это не просто маршрутизатор, хост или группа систем, которые...
-
Прогнозируемая оценка проекта после реализации единой шины данных как прослойки между всеми компонентами ИТ-ландшафта компании выполняется по методу...
-
Для того, чтобы разработать оптимальный метод интеграции сторонних систем в существующую ИТ-инфраструктуру систем компании, требуется точно поставить...
-
По результатам данного исследования необходимо выявить недостатки и ограничения существующих технологий интеграции. Для проведения исследования...
-
Информационная система крупной организации, как правило, представляет собой исторически сложившуюся совокупность отдельно работающих систем, которые...
-
В этом разделе намеренно допущено отступление от общей методики - не смешивать разные компоненты. Это сделано для облегчения демонстрации построения...
Идея алгоритма Лемпеля-Зива, Алгоритм LZ77 - Анализ алгоритма Лемпеля-Зива