Что происходит во время записи? - Компьютерные и сетевые технологии
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и большинство команд не пишут в память. Обычно операции записи составляют менее 10% общего трафика памяти. К счастью, общий случай является и более простым. Блок из кэш-памяти может быть прочитан в то же самое время, когда читается и сравнивается его тэг. Таким образом, чтение блока начинается сразу как только становится доступным адрес блока. Если чтение происходит с попаданием, то блок немедленно направляется в процессор. Если же происходит промах, то от заранее считанного блока нет никакой пользы, правда нет и никакого вреда.
Однако при выполнении операции записи ситуация коренным образом меняется. Именно процессор определяет размер записи (обычно от 1 до 8 байтов) и только эта часть блока может быть изменена. В общем случае это подразумевает выполнение над блоком последовательности операций чтение - модификация - запись: чтение оригинала блока, модификацию его части и запись нового значения блока. Более того, модификация блока не может начинаться до тех пор, пока проверяется тэг, чтобы убедиться в том, что обращение является попаданием. Поскольку проверка тэгов не может выполняться параллельно с другой работой, то операции записи отнимают больше времени, чем операции чтения.
Очень часто организация кэш-памяти в разных машинах отличается именно стратегией выполнения записи. Когда выполняется запись в кэш-память имеются две базовые возможности: сквозная запись (write through, store through) - информация записывается в два места: в блок кэш-памяти и в блок более низкого уровня памяти; запись с обратным копированием (write back, copy back, store in) - информация записывается только в блок кэш-памяти. Модифицированный блок кэш-памяти переписывается в основную память только тогда, когда он замещается. Для сокращения частоты копирования блоков при замещении обычно с каждым блоком кэш-памяти связывается так называемый бит модификации (dirty bit). Этот бит состояния показывает был ли модифицирован блок, находящийся в кэш-памяти. Если он не модифицировался, то обратное копирование отменяется, поскольку более низкий уровень содержит ту же самую информацию, что и кэш-память.
Оба подхода к организации записи имеют свои преимущества и недостатки. При записи с обратным копированием операции записи выполняются со скоростью кэш-памяти, и несколько записей в один и тот же блок требуют только одной записи в память более низкого уровня. Поскольку в этом случае обращения к основной памяти происходят реже, вообще говоря, требуется меньшая полоса пропускания памяти, что очень привлекательно для мультипроцессорных систем. При сквозной записи промахи по чтению не влияют на записи в более высокий уровень, и, кроме того, сквозная запись проще для реализации, чем запись с обратным копированием. Сквозная запись имеет также преимущество в том, что основная память имеет наиболее свежую копию данных. Это важно в мультипроцессорных системах, а также для организации ввода/вывода.
Обычно в кэш-памяти, реализующей запись с обратным копированием, используется размещение записи в кэш-памяти (в надежде, что последующая запись в этот блок будет перехвачена), а в кэш-памяти со сквозной записью размещение записи в кэш-памяти часто не используется (поскольку последующая запись в этот блок все равно пойдет в память).
Разновидности строения кэш-памяти
Одним из основных вопросов увеличения эффективности кэш-памяти является следующий: должны ли команды и данные находится вместе в общей кэш-памяти. Очевидно, разработать смежную кэш-память, в которой хранятся и данные и команды проще. При этом вызов команд и данных автоматически уравновешивается. Тем не менее в настоящее время преобладает тенденция к применению разделенной кэш-памяти, когда команды хранятся в одной кэш-памяти, а данные в другой. Существует три основных способа организации кэш-памяти:
В первом случае (а) кэш хранит как команды, так и адреса, а во втором случае (в) кэши разделены, но шина для данных и для команд одна общая (однофазная Гарвардская архитектура). Есть еще и третья возможность - полная Гарвардская архитектура (с), которая подразумевает не только хранение данных и команд в двух раздельных кэшах, но и наличие полностью раздельных шин. Разделенная кэш-память позволяет осуществлять параллельный доступ и к данным, и к операндам. К тому же, поскольку команды обычно не меняются во время исполнения программы, содержание командной кэш-памяти не приходится переписывать обратно в ОП.
После процессора i486, в процессорах Pentium используется раздельная кэш-память команд и данных емкостью по 8-16 Кбайт, что обеспечивает независимость обращений. За один такт из каждой кэш-памяти могут считываться два слова. При этом кэш-память данных построена на принципах двух кратного расслоения, что обеспечивает одновременное считывание двух слов, принадлежащих одной строке кэш-памяти. Для повышения эффективности перезагрузки кэш-памяти в процессоре применяется 64-битовая внешняя шина данных. В настоящее время между разделенной кэш-памятью первого уровня помещается кэш второго уровня и, даже, третьего уровня. Мы уже упоминали что наличие кэш-памяти существенно ограничивает полезную площадь кристалла (Alpha 21164 компании Digital имеет 50% площади кристалла под кэш), но это не вся правда. Для производительной работы кэша необходимы эффективные алгоритмы внеочередного и спекулятивного выполнения (выборки) команд. А это, в свою очередь, приводит к неоправданному усложнению архитектуры процессора. Сравните: процессор MIPS R5000 - простой RISC процессор, процессор MIPS R10000 - сложный CPU со всеми возможностями спекулятивного выполнения выборки и исполнения команд. Производительность его всего лишь на 1,6 раза выше, чем у R5000 , зато площадь больше в 3,4 раза. В последнее время идут интенсивные работы по интегрированию на кристалле динамической памяти с произвольной выборкой (DRAM) вместо кэшей на SRAM. Это направление получило название интеллектуальной памяти - IRAM. Интегрированная на кристалл оперативная память занимает такую же площадь, что и кэш SRAM, но способна вместить в 30-40 раз больше данных.
Память является важнейшим ресурсом, требующим тщательного управления со стороны мультипрограммной операционной системы. Распределению подлежит вся оперативная память, не занятая операционной системой. Обычно ОС располагается в самых младших адресах, однако может занимать и самые старшие адреса. Функциями ОС по управлению памятью являются: отслеживание свободной и занятой памяти, выделение памяти процессам и освобождение памяти при завершении процессов; вытеснение процессов из оперативной памяти на диск, когда размеры основной памяти не достаточны для размещения в ней всех процессов, и возвращение их в оперативную память, когда в ней освобождается место; а также настройка адресов программы на конкретную область физической памяти. Все выше перечисленное относится к логической организации памяти.
Выводы
Память - это одно из основных устройств ЭВМ, которое служит для хранения программ и данных.
Память ЭВМ - это совокупность всех запоминающих устройств, входящих в состав машины.
Память компьютера - система иерархическая, состоящая из нескольких уровней.
Внутренняя память может строиться на самых разнообразных физических принципах, но по своему функциональному назначению различается на ОЗУ, ПЗУ, ППЗУ и др.
Современные ОЗУ изготавливаются в виде полупроводниковых микросхем двух типов - статических и динамических.
Для разрешения проблемы соответствия времени обработки данных в процессоре и времени обращения к ОП применяется структура многоуровневого буфера - кэш-память.
В современных компьютерах кэш-память обычно реализуется по двух и трехуровневой схеме. При этом кэш 1-го уровня выполняется непосредственно на кристалле процессора, а кэш 2-го уровня (3-го) устанавливается на системной плате.
Память является важнейшим ресурсом, требующим тщательного управления со стороны мультипрограммной операционной системы.
Вопросы и задания
Как соотносятся между собой объем памяти и ее быстродействие и почему?
Что хранится в ПЗУ компьютера?
Что такое BIOS и каковы его функции?
Перечислите достоинства и недостатки статических и динамических МС.
Что такое кэш-память и как она работает?
Можно ли считать из памяти отдельно взятый бит?
Оцените, какая доля адресного пространства памяти вашего компьютера реально занята.
Лекция 8. Логическая организация памяти
Мы уже говорили, что размер реальной физической памяти не соответствует адресному пространству процессора, разрядности его адресной шины. Эта проблема всегда актуальна, а ранее она была просто угрожающей. Программисты тратили много времени на то, что бы впихнуть свои программы в небольшую основную память процессора.
Существовала еще одна проблема, аппаратная организация памяти в виде линейного набора ячеек не соответствует представлениям программиста о том, как организовано хранение программ и данных. Большинство программ представляет собой набор модулей, созданных независимо друг от друга. Иногда все модули, входящие в состав процесса, располагаются в памяти один за другим, образуя линейное пространство адресов. Однако чаще модули помещаются в разные области памяти и используются по-разному.
Виртуальная память
Эти проблемы решались и решаются до сих пор. Есть несколько способов, позволяющих согласовать разные объемы памяти, разные способы ее организации в представлении программистов и реально аппаратно существующей.
Традиционным решением было использование вспомогательной памяти и разделения программы на несколько частей, так называемых оверлеев, каждый из которых перемещался по мере надобности между основной и вспомогательной памятью. В дальнейшем этот метод развился в страничную организацию памяти, когда память разбивалась на блоки фиксированного объема - страницы. Именно они образовывали единое линейное пространство адресов и перемещались с диска на основную память. Однако и этот метод не вполне удовлетворил потребности программистов и эволюционировал в сегментную организацию памяти. Сегмент - область памяти определенного назначения, внутри которой поддерживается линейная адресация. В этом случае память представлялась блоками переменной длины (и большего размера, по отношению к страницам) - сегментами, иногда их называют параграфами что, на мой взгляд, больше отвечает существу дела.
Развитие методов организации вычислительного процесса в этом направлении привело к появлению метода, известного под названием - виртуальная память, о чем мы будем говорить более подробно ниже.
Таким образом, виртуальная память - это совокупность программно-аппаратных средств, позволяющих пользователям писать программы, размер которых превосходит имеющуюся оперативную память; для этого виртуальная память решает следующие задачи:
Размещает данные в запоминающих устройствах разного типа, например, часть программы в оперативной памяти, а часть на диске;
Перемещает по мере необходимости данные между запоминающими устройствами разного типа, например, подгружает нужную часть программы с диска в оперативную память;
Все эти действия выполняются автоматически, без участия программиста, то есть механизм виртуальной памяти является прозрачным по отношению к пользователю. Трансляцию виртуальных адресов в физические выполняет модуль управления памятью или же диспетчер памяти (Memory Management Unit). Когда нужные данные (или команды) отсутствуют в основой памяти, диспетчер перемещает их туда с диска, для этого используется механизм ПДП. Наиболее распространенными реализациями виртуальной памяти является страничное, сегментное и странично - сегментное распределение памяти, а также свопинг.
Страничная организация памяти
О несоответствии адресного пространства логической памяти реальному объему физической памяти мы уже говорили. Теперь посмотрим, как это противоречие преодолевается в современных процессорах, но начнем с более простого примера.
Пусть наш компьютер имеет 16-битное поле адреса и всего лишь 4096 слов оперативной памяти (PDP-1). Программа, работающая на нем, могла бы обращаться к 65536 словам (216=65536), но такого количества слов просто нет. До изобретения виртуальной памяти все адреса, которые были равны или больше адреса 4096 считались бесполезными, не существующими.
Идея разделения понятий адресного пространства и адресов памяти состоит в следующем. В любой момент времени можно получить прямой доступ к 4096 словам памяти, но это не значит, что они непременно должны соответствовать адресам от 0 до 4095. Например, мы могли бы сообщить компьютеру, что при обращении к адресу 4096 должно использоваться слово из памяти с адресом 0, при обращении к адресу 4097 - слово с адресом 1, а при обращении к адресу 8191 - слово с адресом 4095 и т. д. Другими словами, мы отобразили логическое адресное пространство на действительные адреса физической памяти (рис.7.9)
Возникает вопрос: а что произойдет, если программа совершит переход в один из адресов с 8192 по 12287? В машине без виртуальной памяти на экране появится фраза "Несуществующий адрес памяти" и выполнение программы остановится. В машине с виртуальной памятью будет иметь следующая последовательность действий:
Слова с 4096 до 8191 будут выгружены на диск.
Слова с 8102 до 12287 будут загружены с диска в основную память.
Отображение адресов изменится: теперь адреса с 8192 до 12287 соответствуют ячейкам памяти с 0 по 4095.
Выполнение программы продолжится.
Если теперь добавить в основную память еще три блока по 4 К, то мы сможемм отобразить полностью 64 К адресного пространства на всего лишь 4К физической памяти. Такая технология автоматического наложения называется страничной организацией памяти, а куски программы, которые считываются с диска, называются страницами. Необходимо подчеркнуть, что страничная организация памяти создает иллюзию большой линейной основной памяти такого же размера, как адресное пространство. Программист может писать программы и при этом ничего не знать о существовании страничной организации памяти, этот механизм называют прозрачным.
Страничное управление памятью - это общепринятый механизм организации виртуальной памяти с подкачкой страниц по запросу. Страничная трансляция адресов выполняется блоком управления памятью (Memory Management Unit - MMU), расположенным в процессоре, с использованием каталогов и таблиц дескрипторов страниц - структур в физической ОП. Блок MMU делит линейный адрес на виртуальные страницы фиксированного размера (4К, 4М, 2М). На такие же страницы делится и адресное пространство физических адресов.
Преобразование адресов
Приведем пример страничного распределения памяти. Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами. В общем случае размер виртуального адресного пространства не является кратным размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью. Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками). Размер страницы обычно выбирается равным степени двойки: 512, 1024 и т. д., это позволяет упростить механизм преобразования адресов. При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные - на диск. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. При загрузке операционная система создает для каждого процесса информационную структуру - таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в оперативную память, или делается отметка о том, что виртуальная страница выгружена на диск. Кроме того, в таблице страниц содержится управляющая информация, такая как признак модификации страницы, признак невыгружаемости (выгрузка некоторых страниц может быть запрещена), признак обращения к странице (используется для подсчета числа обращений за определенный период времени) и другие данные, формируемые и используемые механизмом виртуальной памяти.
Базовый регистр Сгенерированный процессором
Таблицы страниц виртуальный адрес
При активизации очередного процесса в специальный регистр процессора загружается адрес таблицы страниц данного процесса. При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди готовых. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из оперативной памяти.
Сегментная организация памяти.
Память может логически организовываться в виде одного или множества блоков, сегментов произвольной длины (в реальном режиме фиксированной). Мы уже говорили, что в защищенном режиме возможно разбиение логической памяти на страницы размером 4 Кбайт (до 5 Мбайт в современных процессорах), каждая из которых может отображаться на любую область физической памяти. Сегментация и страничная трансляция адресов могут применяться совместно и по отдельности. Сегментация является средством организации логической памяти на прикладном уровне, а страничная трансляция адресов на системном уровне.
Что бы лучше понять принцип сегментирования рассмотрим его на примере процессора Intel 8086. Вся память системы представляется не в виде непрерывного пространства, а в виде нескольких блоков -- сегментов заданного размера (по 64 Кбайт), положение которых в пространстве памяти можно изменять программным путем. Для хранения кодов адресов памяти используются не отдельные регистры, а пары регистров:
Сегментный регистр определяет адрес начала сегмента (база сегмента), то есть положение сегмента в памяти;
Регистр указателя (регистр смещения) определяет положение рабочего адреса внутри сегмента.
При этом физический 20-разрядный адрес памяти, выставляемый на внешнюю шину адреса, образуется путем сложения смещения, и адреса сегмента со сдвигом на 4 бита. Сегмент может начинаться только на 16-байтной границе памяти (так как адрес начала сегмента, по сути, имеет четыре младших нулевых разряда, то есть с адреса, кратного 16. Эти допустимые границы сегментов называются границами параграфов. Отметим, что введение сегментирования, прежде всего, связано с тем, что внутренние регистры процессора 16-разрядные, а физический адрес памяти 20-разрядный (16-разрядный адрес позволяет использовать память только в 64 Кбайт, что явно недостаточно).
Чтобы лучше понять, как из двух 16 битовых слов получается 20 битовый адрес еще раз покажем это на двоичном примере.
Пусть имеется 2 машинных слова:
ABCD H и 1234 H
(вспомним, что каждая 16-ричная цифра представляет 4 бита, например - 11112 = 1510 = F16); Берем первое число и приписываем 0 справа (если больше нравится - умножаем на 16), получим ABCD0, т. е. первоначальное число, но со смещением на один 16-ричный разряд. Это 20-ти разрядное число, но оно не может нам служить 20 битовым адресом, т. к. оно заканчивается на нуль и, следовательно, может представлять только адреса которые тоже заканчиваются на нуль. Другими словами оно пригодно для адресации каждого 16-го байта или сегмента.
A*164 + B*163 + C*162 + D*161 + 0*160
При изменении A, B,C, D изменяется дискретно сегмент (параграф).
Чтобы получить окончательную схему сегментированной адресации возьмем другое 16-ти битовое число - 1234 H и сложим его с модифицированным первым:
Получим ACF04 двадцати битовое число, которое может принимать любые значения от 0 до 1 048 577
Таким образом, ABCD0 - сегментная часть, которая указывает на ту область адреса которая кратна 16 (сегмент, параграф). Второе число 1234 - смещение, которое указывает конкретное расположение байта внутри сегментного параграфа (это дает 65536 или 64 Кбайт адресов внутри сегмента). Поскольку эти составляющие перекрываются, конечный адрес можно получить различными способами:
Отметим, что линейный адрес является пятиразрядным, хотя мы использовали для сегмента и смещения четырехразрядные числа. Можно констатировать, что вычисление сегментированного адреса основано на так называемом сегментном сложении, позволяющем получить (например) 20-битовое двоичное число из двух 16 битовых.
Таким образом, мы смогли адресоваться к каждой ячейке 64 Кбайтового блока из почти 1 Мбайт объема общей памяти, используя только 16 разрядную шину адреса, а не 20 разрядную, как это было бы в случае прямой адресации.
Для обращения к нужной ячейке памяти надо задать базу сегмента и 16-битное расстояние от базы называемое смещением или относительным адресом. Преобразование пары сегмент/смещение (наз. также виртуальным адресом) в физический адрес довольно простое: пусть регистр DS содержит 1234H, а регистр SI содержит 5678H, тогда физический адрес в команде MOV AX (загрузить слово в регистр AX) будет
DSx16 + SI = 12340H + 5678H = 179B8H
Базовые адреса четырех одновременно доступных программе сегментов находятся в сегментных регистрах:
Регистр команд - CS;
Регистр данных - DS;
Стека - SS
Регистр дополнительных данных - ES.
Каждый из них 16-ти битовый, но можно считать, что они 20-ти разрядные.
Обратите внимание на магическую цифру 64 Кбайт, это объем памяти внутри которого адресация осуществляется с помощью неизменного значения сегментного регистра, т. е. внутри сегмента реализуется линейно адресуемая память.
Применяются и более сложные методы сегментирования памяти. Например, в процессоре Intel 80286 в так называемом защищенном режиме адрес памяти вычисляется в соответствии с рис. 7.7. В сегментном регистре в данном случае хранится не базовый (начальный) адрес сегментов, а коды селекторов, определяющие адреса в памяти, по которым хранятся дескрипторы (то есть описатели) сегментов. Область памяти с дескрипторами называется таблицей дескрипторов. Каждый дескриптор сегмента содержит базовый адрес сегмента, размер сегмента (от 1 до 64 Кбайт) и его атрибуты. Базовый адрес сегмента имеет разрядность 24 бит, что обеспечивает адресацию 16 Мбайт физической памяти.
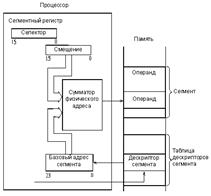
Рис. 8.5 Адресация памяти в защищенном режиме процессора Intel 80286.
Таким образом, на сумматор, вычисляющий физический адрес памяти, подается не содержимое сегментного регистра, как в предыдущем случае, а базовый адрес сегмента из таблицы дескрипторов.
Еще более сложный метод адресации памяти с сегментированием использован в процессоре Intel 80386 и в более поздних моделях процессоров фирмы Intel. Этот метод иллюстрируется рис. 7.8. Адрес памяти (физический адрес) вычисляется в три этапа. Сначала вычисляется так называемый эффективный адрес EA (32-разрядный) путем суммирования трех компонентов: базы, индекса и смещения (Base, Index, Displacement), причем возможно умножение индекса на масштаб (Scale). Эти компоненты имеют следующий смысл:
EA = BASE + (INDEX*SCALE) + DISPLACEMENT
Здесь BASE - базовый адрес массива, INDEX - номер элемента, DISPLACEMENT - смещение внутри элемента. Массив может состоять из байтов, слов, двойных слов и учетверенных слов - это учитывается коэффициентом SCALE (1,2,34 или 8).
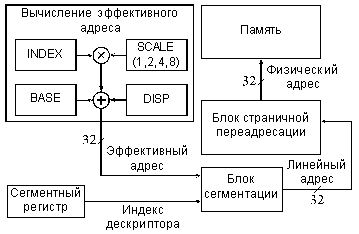
Рис. 8.6 Формирование физического адреса памяти процессора 80386 в защищенном режиме.
Смещение -- это 8-, 16- или 32-разрядное число, включенное в команду.
База -- это содержимое базового регистра процессора. Обычно оно используется для указания на начало некоторого массива.
Индекс -- это содержимое индексного регистра процессора. Обычно оно используется для выбора одного из элементов массива.
Масштаб -- это множитель (он может быть равен 1, 2, 4 или 8), указанный в коде команды, на который перед суммированием с другими компонентами умножается индекс. Он используется для указания размера элемента массива.
Затем специальный блок сегментации вычисляет 32-разрядный линейный адрес, который представляет собой сумму базового адреса сегмента из сегментного регистра с эффективным адресом. Наконец, физический 32-битный адрес памяти образуется путем преобразования линейного адреса блоком страничной переадресации, который осуществляет перевод линейного адреса в физический страницами по 4 Кбайт. В любом случае сегментирование позволяет выделить в памяти один или несколько сегментов для данных и один или несколько сегментов для программ. Переход от одного сегмента к другому сводится всего лишь к изменению содержимого сегментного регистра. Иногда это бывает очень удобно. Но для программиста работать с сегментированной памятью обычно сложнее, чем с непрерывной, несегментированной памятью, так как приходится следить за границами сегментов, за их описанием, переключением и т. д.
Свопинг
Разновидностью виртуальной памяти является свопинг. На рисунке 8.7 показан график зависимости коэффициента загрузки процессора в зависимости от числа одновременно выполняемых процессов и доли времени, проводимого этими процессами в состоянии ожидания ввода-вывода.
Рис. 8.7 Зависимость загрузки процессора от числа задач и интенсивности ввода-вывода
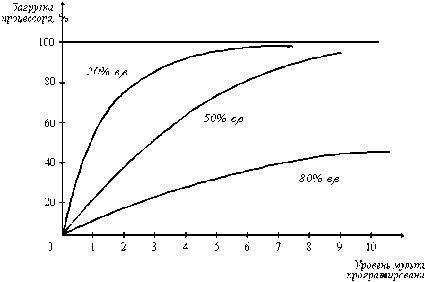
Из рисунка видно, что для загрузки процессора на 90% достаточно всего трех счетных задач. Однако для того, чтобы обеспечить такую же загрузку интерактивными задачами, выполняющими интенсивный ввод-вывод, потребуются десятки таких задач. Необходимым условием для выполнения задачи является загрузка ее в оперативную память, объем которой ограничен. В этих условиях был предложен метод организации вычислительного процесса, называемый свопингом. В соответствии с этим методом некоторые процессы (обычно находящиеся в состоянии ожидания) временно выгружаются на диск. Планировщик операционной системы не исключает их из своего рассмотрения, и при наступлении условий активизации некоторого процесса, находящегося в области свопинга на диске, этот процесс перемещается в оперативную память. Если свободного места в оперативной памяти не хватает, то выгружается другой процесс. При свопинге, в отличие от рассмотренных ранее методов реализации виртуальной памяти, процесс перемещается между памятью и диском целиком, то есть в течение некоторого времени процесс может полностью отсутствовать в оперативной памяти. Существуют различные алгоритмы выбора процессов на загрузку и выгрузку, а также различные способы выделения оперативной и дисковой памяти загружаемому процессу.
Выводы
Логическая организация памяти необходима для устранения несоответствия между адресным пространством памяти и ее реальным, физическим объемом.
Для того чтобы адресоваться к операндам и командам, не напрягая при этом адресное пространство памяти, существует много способов. Одна из идей в этой области заключается в том, что адрес ячейки памяти помещают в регистр процессора, а в команде содержится ссылка на этот регистр.
Стековая организация памяти применяется при вызове подпрограмм, временном хранении данных.
Основные разновидности логической организации памяти стековая, сегментная, косвенная, свопинг решают задачу создания виртуальной памяти.
Вопросы и задания
Оцените, какой процент адресного пространства вашего компьютера реально заполнен под память.
Какие методы адресации вы знаете?
Что такое виртуальная память?
Что такое свопинг?
В каких режимах может работать IA-32?
Как формируется физический адрес при сегментной адресации?
Как формируется физический адрес при страничной адресации?
Лекция 9. Методы адресации
Пространство памяти предназначено для хранения кодов команд и данных, для доступа к которым имеется богатый выбор методов адресации (около 24). Операнды могут находиться во внутренних регистрах процессора (наиболее удобный и быстрый вариант). Они могут располагаться в системной памяти (самый распространенный вариант). Наконец, они могут находиться в устройствах ввода/вывода (наиболее редкий случай). Определение места положения операндов производится кодом команды. Причем существуют разные методы, с помощью которых код команды может определить, откуда брать входной операнд и куда помещать выходной операнд. Эти методы называются методами адресации. Эффективность выбранных методов адресации во многом определяет эффективность работы всего процессора в целом.
Прямая или абсолютная адресация. Физический адрес операнда содержится в адресной части команды. Формальное обозначение:
Операндi = (Аi),
Где Аi - код, содержащийся в i-м адресном поле команды.
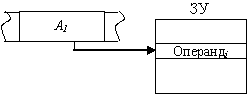
Рис. 9.1 Прямая адресация
Пример: mov al,[2000] - передать операнд, который содержится по адресу 2000h в регистр AL.
Add R1,[1000] - сложить содержимое регистра R1 с содержимым ячейки памяти по адресу 1000h и результат переслать в R1.
Допускается использование прямой адресации при обращении, как к основной, так и к регистровой памяти.
Непосредственная адресация. В команде содержится не адрес операнда, а непосредственно сам операнд.
Операндi= Аi.

Рис. 9.2 Непосредственная адресация
Непосредственная адресация позволяет повысить скорость выполнения операции, так как в этом случае вся команда, включая операнд, считывается из памяти одновременно и на время выполнения команды хранится в процессоре в специальном регистре команд (РК). Однако при использовании непосредственной адресации появляется зависимость кодов команд от данных, что требует изменения программы при каждом изменении непосредственного операнда.
Пример: mov eax,0f0f0f0f0 - загрузить константу 0f0f0f0f0h в регистр eax.
Косвенная (базовая) адресация. Адресная часть команды указывает адрес ячейки памяти (рис. 7.3,а) или номер регистра (рис. 7.3,б), в которых содержится адрес операнда:
Операндi = ((Аi)).
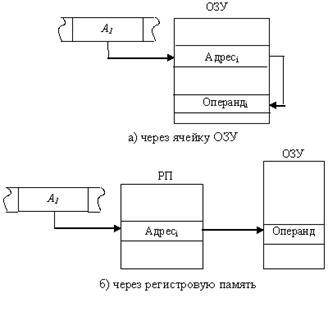
Рис. 9.3 Косвенная адресация
Применение косвенной адресации операнда из оперативной памяти при хранении его адреса в регистровой памяти существенно сокращает длину поля адреса, одновременно сохраняя возможность использовать для указания физического адреса полную разрядность регистра. Недостаток этого способа - необходимо дополнительное время для чтения адреса операнда. Вместе с тем он существенно повышает гибкость программирования. Изменяя содержимое ячейки памяти или регистра, через которые осуществляется адресация, можно, не меняя команды в программе, обрабатывать операнды, хранящиеся по разным адресам. Косвенная адресация не применяется по отношению к операндам, находящимся в регистровой памяти.
Пример: mov al,[ecx] - передать в регистр AL операнд (содержимое) ячейки памяти, адрес которой находится в регистре ECX.
Предоставляемые косвенной адресацией возможности могут быть расширены, если в системе команд ЭВМ предусмотреть определенные арифметические и логические операции над ячейкой памяти или регистром, через которые выполняется адресация, например увеличение или уменьшение их значения на единицу (и не только на 1).
В этом случае речь идет о базовой адресации со смещением.
Пример: mov eax,[eci+4] - передать в EAX операнд, который содержится по адресу ECI со смещением плюс 4.
Иногда, адресация, при которой после каждого обращения по заданному адресу с использованием механизма косвенной адресация, значение адресной ячейки автоматически увеличивается на длину считываемого операнда, называется автоинкрементной. Адресация с автоматическим уменьшением значения адресной ячейки называется автодекрементной.
Регистровая адресация. Предполагается, что операнд находится во внутреннем регистре процессора.
Например: mov eax, cr0 - передать в EAX содержимое CR0 или
Mov ecx, ecx - сбросить регистр ECX.
Индексная адресация (со смещением) - содержимое РОН используется в качестве компоненты эффективного адреса (как правило, работа с массивами).
Пример: sub array [esi],2 - вычесть 2 из элемента массива, на который указывает регистр ESI.
Относительная адресация. Этот способ используется тогда, когда память логически разбивается на блоки, называемые сегментами. В этом случае адрес ячейки памяти содержит две составляющих: адрес начала сегмента (базовый адрес) и смещение адреса операнда в сегменте. Адрес операнда определяется как сумма базового адреса и смещения относительно этой базы:
Операндi = (базаi + смещениеi).
Для задания базового адреса и смещения могут применяться ранее рассмотренные способы адресации. Как правило, базовый адрес находится в одном из регистров регистровой памяти, а смещение может быть задано в самой команде или регистре.
Рассмотрим два примера.
Адресное поле команды состоит из двух частей, в одной указывается номер регистра, хранящего базовое значение адреса (начальный адрес сегмента), а в другом адресном поле задается смещение, определяющее положение ячейки относительно начала сегмента. Именно такой способ представления адреса обычно и называют относительной адресацией.
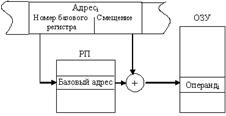
Рис. 9.4 Относительная адресация
Первая часть адресного поля команды также определяет номер базового регистра, а вторая содержит номер регистра, в котором находится смещение. Такой способ адресации чаще всего называют базово-индексным.
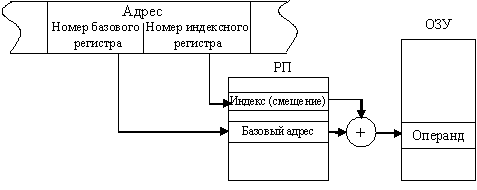
Рис. 9.5 Базово-индексная адресация
Главный недостаток относительной адресации - большое время вычисления физического адреса операнда. Но существенное преимущество этого способа адресации заключается в возможности создания "перемещаемых" программ - программ, которые можно размещать в различных частях памяти без изменения команд программы. То же относится к программам, обрабатывающим по единому алгоритму информацию, расположенную в различных областях ЗУ. В этих случаях достаточно изменить содержимое базового адреса начала команд программы или массива данных, а не модифицировать сами команды. По этой причине относительная адресация облегчает распределение памяти при составлении сложных программ и широко используется при автоматическом распределении памяти в мультипрограммных вычислительных системах.
Лекция 10. Внешняя память компьютера
Введение
У оперативной памяти есть два важных недостатка. Первый -- это цена. Второй недостаток связан с тем, что оперативная память полностью очищается при выключении компьютера, то есть ее нельзя использовать для длительного хранения программ и данных. Поэтому для длительного хранения больших объемов информации нужны другие носители. В качестве таких носителей используют магнитные, оптические, магнитооптические и другие. Скорость обращения к данным у них в тысячи раз меньше, чем у оперативной памяти, но зато меньше цена хранения одного мегабайта, сейчас цена 1 мегабайта порядка одного цента. проблем
В основе действия всех внешних накопительных устройств лежит принцип механического перемещения носителя относительно устройства, выполняющего считывание и запись информации. Чем выше скорость движения, тем быстрее работает устройство. Для достижения сверхвысоких скоростей требуется высочайшая точность изготовления механических частей и герметичное исполнение прибора, исключающее попадание пыли, дыма, влаги и прочего мусора.
Жесткий диск (Hard Disk Drive)
Пока этим требованиям в наибольшей степени удовлетворяют так называемые жесткие диски (HDD -- Hard Disk Drive), хотя не исключено появление в будущем других устройств, обладающих лучшими свойствами. Три основных требования к жесткому диску -- это емкость, быстродействие и минимальные габариты (о надежности мы не говорим, поскольку это, само собой, разумеется). Емкость жестких дисков измеряется в гигабайтах (Гбайт). По состоянию на сегодняшний день емкости жестких дисков уже перевалили за отметку 100 Гбайт.
Для создания существующих магнитных дисков применяются технологии, при которых на пластину напыляется один слой магнитного материала - носителя информации, (как на верхнем рисунке).
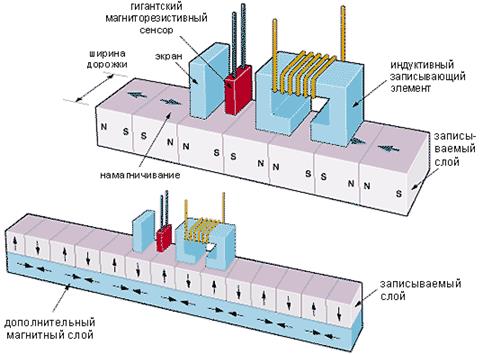
Традиционный способ записи на магнитную пластину (вверху). При уменьшении размеров единичных ячеек с горизонтальной намагниченностью резко увеличивается вероятность их спонтанного размагничивания. Новый способ, предложенный Fujitsu (внизу). Использование дополнительного подслоя и вертикального намагничивания позволяет достичь в восемь раз большей плотности записи.
Требование емкости напрямую противоречит требованию минимальных габаритов. Это противоречие снимается благодаря непрерывному улучшению технологии изготовления. Сегодня жесткий диск -- это прецизионный прибор, изготовленный с привлечением самых последних достижений технологической науки. Он хрупок, не выносит ударов и требует предельной аккуратности в обращении. По этим причинам жесткий диск стационарно помещается внутри корпуса системного блока. Жесткий диск в совокупности с механическими и электронными устройствами, обеспечивающими его функционирование, называется дисковым накопителем или НМД.
Конструкция жесткого диска
Дисковый накопитель обычно состоит из набора пластин, представляющих собой металлические диски (сегодня большое распространение получили диски из композитных материалов), покрытые магнитным материалом и соединенные между собой при помощи центрального шпинделя. Над каждой поверхностью располагается считывающая головка. При высоких скоростях вращения дисков головки "парят" над их поверхностями на воздушной подушке. Для записи данных используются обе поверхности пластины (керамические, алюминиевые, или из композитных материалов, на которые нанесено специальное магнитное покрытие). В современных дисковых накопителях используется от 4 до 9 пластин. Шпиндель вращается с высокой постоянной скоростью (обычно 3600, 5400 или 7200 оборотов в минуту, но встречаются и более высокие скорости до 15000 об/мин). Каждая пластина содержит набор концентрических записываемых дорожек. Обычно дорожки делятся на блоки данных объемом 512 байт, иногда называемые секторами. Перед данными располагается заголовок (header), состоящий из преамбулы(preamble), которая позволяет головке синхронизироваться перед чтением или записью данных и служебной адресной информацией. После данных идет код с исправлением ошибок (код Хемминга или код Рида-Соломона). Между соседними секторами находится межсекторный интервал. Так что форматированный сектор составляет уже 571 байт. Количество блоков, записываемых на одну дорожку зависит от физических размеров пластины и плотности записи. Как правило, производители указывают размер неформатированного диска (как будто каждая дорожка содержит только данные, но более честно было бы указывать вместимость форматированного диска, когда не учитываются преамбулы, исправляющие коды и межсекторные интервалы. Емкость форматированного диска обычно на 15-20% меньше емкости неформатированного диска.
Данные записываются или считываются с пластин с помощью головок записи/считывания, по одной на каждую поверхность. Линейный двигатель представляет собой электромеханическое устройство, которое позиционирует головку над заданной дорожкой. Обычно головки крепятся на кронштейнах, которые приводятся в движение каретками.
Основные узлы НМД:
Магнитные диски;
Головки записи/считывания;
Двигатель привода дисков;
Механизм привода головок;
Печатная плата с контроллером диска;
Воздушные фильтры, кабели, разъемы и т. д.
Механизм привода головок, с его помощью головки передвигаются от центра диска к его краям и устанавливаются на заданный цилиндр. Различают приводы с шаговым двигателем и сервопривод (с подвижной катушкой), использующий сигнал обратной связи для точного позиционирования над выбранной дорожкой (цилиндром). Сервопривод более дорогое и более точное устройство.
Фильтры, используется два вида фильтров:
Рециркуляции;
Барометрические, необходимые для выравнивания давления внутри устройства с атмосферным.
Накопитель на магнитных дисках (НМД) представляет собой набор пластин, магнитных головок, кареток, линейных двигателей плюс воздухонепроницаемый корпус. Дисковым устройством называется НМД с относящимися к нему электронными схемами (контроллерами). Некоторые контроллеры содержат микропроцессор, производят буферизацию совокупности секторов и кэширование данных, а также устраняют поврежденные секторы.
Основные характеристики НМД:
Тип привода головок;
Способ парковки;
Надежность;
Быстродействие, производительность, стоимость;
Вид интерфейса (IDE, EIDE, SCSI).
Производительность диска является функцией времени обслуживания, которое включает в себя три основных компонента: время доступа, время ожидания и время передачи данных. Время доступа - это время, необходимое для позиционирования головок на соответствующую дорожку, содержащую искомые данные. Оно является функцией затрат на начальные действия по ускорению головки диска (порядка 6 мс), а также функцией числа дорожек, которые необходимо пересечь на пути к искомой дорожке. Характерные средние времена поиска - время, необходимое для перемещения головки между двумя случайно выбранными дорожками, лежат в диапазоне 10-20 мс. Время перехода с дорожки на дорожку меньше 10 мс и обычно составляет 2 мс. Вторым компонентом времени обслуживания является время ожидания. Чтобы искомый сектор повернулся до совмещения с положением головки требуется некоторое время. После этого данные могут быть записаны или считаны. Для современных дисков время полного оборота лежит в диапазоне 8-16 мс, а среднее время ожидания составляет 4-8 мс.
Последним компонентом является время передачи данных, т. е. время, необходимое для физической передачи байтов. Время передачи данных является функцией от числа передаваемых байтов (размера блока), скорости вращения, плотности записи на дорожке и скорости электроники. Типичная скорость считывания информации равна 1-15 Мбайт/с.
Пример:
HAD компании Seagate Technology, объем - 9 Гбайт, среднее время доступа - 8 мс, скорость - 7200 об/мин, интерфейс Fast SCSI -2, скорость считывания - 13 Мбайт/сек.
Способы кодирования данных
В современных системах для процесса записи/считывания используется гигантский магнито-резистивный эффект (GMR - Giant magnetic Resistance), который позволяет реализовать достаточно высокую плотность записи. Сам процесс записи и считывания основан на физических явлениях, описанных еще Фарадеем. Проиллюстрируем эти процессы с помощью рисунка 8.1.
Поскольку количество зон смены знака (их называют битовые ячейки) ограничено возможностями технологии применяются различные способы кодирования, позволяющие, как бы, "втиснуть" как можно больше битов данных в отведенное количество зон.
Различают:
Частотная модуляция - FM (одинарная плотность - Single density);
Модифицированный частотный сигнал - MFM (двойная плотность - Double density);
Кодирование с ограниченной длиной поля записи - RLL (самый популярный сегодня).
Интерфейсы НМД
В состав компьютеров часто входят специальные устройства, называемые дисковыми контроллерами. К каждому дисковому контроллеру может подключаться несколько дисковых накопителей. Между дисковым контроллером и основной памятью может быть целая иерархия контроллеров и магистралей данных, сложность которой определяется главным образом стоимостью компьютера. Поскольку время передачи часто составляет очень небольшую часть общего времени доступа к диску, контроллер в высокопроизводительной системе разъединяет магистрали данных от диска на время позиционирования так, что другие диски, подсоединенные к контроллеру, могут передавать свои данные в основную память. Поэтому время доступа к диску может увеличиваться на время, связанное с накладными расходами контроллера на организацию операции ввода/вывода.
Необходимо отметить, что в последнее время все большее распространение получил интерфейс SCSI. Он не только более производителен, но и поддерживает до 16 устройств, что очень важно для файл-серверов и серверов сети.
Структура хранения информации на жестком диске
Компьютеру важно не просто записать информацию на диск, а так записать, ее, чтобы потом найти, причем быстро и безошибочно. Поэтому на жестком диске создается специальная структура для хранения данных. Операция создания такой структуры называется форматированием диска. После форматирования каждый файл, записанный на диск, может иметь собственный адрес, выраженный в числовой форме.
Несмотря на то, что физически жесткий диск состоит из п дисков и имеет 2п поверхностей, для изучения его структуры нам достаточно рассмотреть только одну поверхность. Эта поверхность разбивается на концентрические дорожки. В зависимости от конструкции диска таких дорожек может быть больше или меньше, и каждая дорожка имей свой уникальный номер.
Если мы теперь вновь вспомним, что реальный жесткий диск имеет много поверхностей, то у нас появится новый термин -- цилиндр. Дорожки с одинаковыми номерами, но принадлежащие разным поверхностям, образуют один цилиндр. Каждый цилиндр имеет номер, совпадающий с номером входящих в него дорожек.
Дорожки, в свою очередь, разбиваются на секторы. Длина каждого сектора равна 512 байтам данных. Таким образом, сектор -- наименьший элемент структуры жесткого диска. Для того чтобы записать, а затем затребовать информацию, необходимо задать адрес, состоящий из трех чисел: номера цилиндра, номера поверхности (номера головки) и номера сектора. Этот метод называется CHS (Cylinder Head Sector). Современным развитием этого метода является механизм трансляции линейных адресов и линейной адресации LBA (Logical Block Adressing), связанный однозначно с CHS.
Таблица размещения файлов
Файлы в канцелярском понимании -- это "дела", с обычными человеческими именами, пылящиеся в таком месте, куда месяцами не ступает нога человека, но установить это место всегда можно по номеру "дела", если заглянуть в амбарную книгу, называемую реестром.
Роль такого "реестра" на жестком диске выполняет специальная таблица, которая называется FAT-таблицей File Allocation Table (по-русски: таблица размещения файлов). Она находится на служебной дорожке жесткого диска и должна именовать, сохранять и производить поиск данных. Физическое повреждение секторов, в которых записана эта таблица, равносильно краху всей информации, хранящейся на жестком диске, поэтому эта таблица всегда продублирована, и операционная система компьютера бережно следит за тем, чтобы информация в разных экземплярах таблицы строго совпадала. Для ОС W.95/98 это были FAT 16 и FAT 32. В этих случаях размер кластера определялся объемом HDD. Однако FAT 32 поддерживал только 32 Гбайт (W.95) при размере кластера 16 Кбайт. Это заставило разработчиков перейти на NTFS начиная с ОС Windows 2000 (для ПК), хотя эта система успешно работала и с Win. NT. Основными преимуществами NTFS является умение управлять дисками с объемом несколько терабайт, исправлять ошибки после сбоев и защищать систему от несанкционированного доступа. Вместе с тем ограниченное количество логических дисков, потери при перезагрузке при изменении размеров кластера вынудили разработчиков к дальнейшему совершенствованию системы. Итак, улучшенная NTFS называется WinFS для ОС Windows Longhorn. Теперь структура каталогов будет давать представление не только о месте хранения файлов, но и определять его предысторию.
Кластер
Хотя острота проблемы с кластеризацией пропала, особенно с внедрением NTFS мы должны понимать откуда она возникла.
Сейчас мы узнаем, откуда эти кластеры берутся. Мы работаем с файлами, имеющими имена, записанные символами (обычными человеческими буквами). Компьютер переводит эти имена в числовые адреса секторов с помощью таблицы размещения файлов. Этим занимается неоднократно упомянутая нами операционная система. Конечно, каждая система делает это по-разному, но до последнего времени все операционные системы, работающие на компьютерах платформы IBM PC, выражали адрес шестнадцатиразрядным числом, поскольку в таблицах размещения файлов на запись адреса каждого сектора зарезервировано 2 байта.
Имея 16 двоичных разрядов, можно задать 65536 разных адресов (216). При такой системе на диск можно записать 65536 различных файлов, и у каждого будет свой уникальный адрес. В те годы, когда размеры жестких дисков не превышали 32 мегабайта, это было очень неплохо. Сегодня средний размер жесткого диска вырос в сто раз, а количество уникальных адресов для записи файлов осталось тем же, каким было. Предельный размер диска, к какому вообще в принципе может адресоваться операционная система, работающая с 16-разрядной FAT-таблицей, сегодня составляет 2 Гбайт. А если мы поделим этот размер на 65536 адресов, то получим, что минимально адресуемое пространство жесткого диска составляет 32 Кбайт. Эта единица и называется кластером.
Поскольку кластер -- это минимальное адресуемое дисковое пространство, значит, ни один файл не может занимать меньше места, чем составляет кластер. На больших дисках файл, имеющий размер 1 байт, займет все 32 Кбайт. То же произойдет и с файлом длиной 2 байта и т. д. Если файл имеет размер 32,1 Кбайт, он займет два кластера, то есть все 64 Кбайт. Даже для FAT 32 при размере диска 32 Гбайт величина кластера все еще остается большой - 16 Кбайт. Потери от кластеризации жестких дисков составляют огромную величину, в отдельных случаях достигающую 40% их объема.
Методы борьбы с кластеризацией
Как уже упоминалось, логическая структура ЖД довольно сложна: дорожки, цилиндры, сектора, которые группируются в кластеры. Реализуется логическая структура на самом диске с помощью технологической операции - форматирование.
Форматирование ЖД выполняется в три этапа:
Форматирование низкого уровня (физическое);
Разбиение диска на разделы;
Форматирование высокого уровня (логическое).
Форматирование низкого уровня - дорожки диска разбиваются на секторы (512 байт данных каждый), приписываются заголовок - преамбула (Header или preamble), концевик, в котором содержится код проверки (Trailer), т. е. добавляется служебная информация, полная емкость сектора становится равной 571 байт.
Разбиение диска на разделы - проводится в том случае, когда на одном ПК предполагается использовать несколько ОС.
Форматирование высокого уровня - операционная система создает структуры для работы с файлами и данными, собственно ФВУ не столько форматирование, сколько создание оглавления диска и таблицы размещения файлов FAT (File Allocation Table).
Самый простой метод борьбы с кластеризацией -- разбиение жесткого диска на разделы (логические диски). Эту операцию производят перед логическим форматированием диска. Для разбиения жесткого диска на разделы применяют программу FDISK. EXE для FAT, которая является приложением MS-DOS, но поставляется и в составе Windows 95, и в составе Windows 98 или Partition Magic для NTFS (W.200 и W. XP). При разбиении жесткого диска на несколько логических дисков каждый вновь образующийся диск имеет собственную структуру и свою таблицу размещения файлов, поэтому чем меньше размеры полученных логических дисков, тем меньше и размеры их кластеров.
Начиная с Windows NT быстро прогрессирует NTFS (NT File System). В этой файловой системе длина имени файла может быть до 255 символов. Имена написаны в коде Unicode, благодаря чему люди в разных странах, где не используется латинский алфавит, могут писать имена файлов на их родном языке. Самое главное в этой системе размер кластера может быть задан вручную, независимо от объема диска.
Дефрагментация дисков - операционная система не всегда располагает информацию файлов и папок в одном непрерывном пространстве. Фрагменты данных могут находится в различных кластерах ЖД, более того, при удалении файлов освобождающееся дисковое пространство становится фрагментированным. Это существенно влияет на производительность файловой системы. Для решения этой проблемы применяется Disk Defragmenter (Дефрагментация диска). В процессе дефрагментации кластеры диска организуются таким образом, чтобы файлы, папки и свободное пространство по возможности располагались равномерно. В результате значительно повышается производительность файловой системы.
Магнито-оптические диски
Другим направлением развития систем хранения информации являются магнитооптические диски. Запись на магнитооптические диски (МО-диски) выполняется при взаимодействии лазера и магнитной головки. Луч лазера разогревает до точки Кюри (температуры потери материалом магнитных свойств) микроскопическую область записывающего слоя, которая при выходе из зоны действия лазера остывает, фиксируя магнитное поле, наведенное магнитной головкой. В результате данные, записанные на диск, не боятся сильных магнитных полей и колебаний температуры. Все функциональные свойства дисков сохраняются в диапазоне температур от -20 до +50 градусов Цельсия. В то время, как вектор намагничивания при традиционной записи ориентирован в плоскости его поверхности диска, с помощью магнито-оптических технологий удается придать вектору вертикальную ориентацию, что значительно ослабляет взаимодействие доменов, а значит чувствительность к внешним полям и высоким температурам.
Конструктивно магнитооптический диск состоит из толстой стеклянной подложки, на которую наносится светоотражающая алюминиевая пленка и ферромагнитный сплав -- носитель информации, покрытый сверху защитным слоем прозрачного пластика. У таких дисков диаметром 3,5 дюйма информационная емкость одной стороны достигает 128-230 Мбайт, при диаметре 5,25 дюйма -- 600 Мбайт, с двух сторон -- 1,3 Гбайт. Дисководы могут быть как встроенными, так и внешними. МО-диски уступают обычным жестким магнитным дискам лишь по времени доступа к данным. Предельное достигнутое МО-дисками время доступа составляет 19 мс. Магнитооптический принцип записи требует предварительного стирания данных перед записью, и соответственно, дополнительного оборота МО-диска. Однако завершенные недавно исследования в SONY и IBM показали, что это ограничение можно устранить, а плотность записи на МО-дисках можно увеличить в несколько раз используя голубой лазер. Во всех других отношениях МО-диски превосходят жесткие магнитные диски.
В магнитооптическом дисководе используются сменные диски, что обеспечивает практически неограниченную емкость. Стоимость хранения единицы данных на МО-дисках в несколько раз меньше стоимости хранения того же объема данных на жестких магнитных дисках.
Сегодня на рынке МО-дисков предлагается более 150 моделей различных фирм. Одно из лидирующих положений на этом рынке занимает компания Pinnacle Micro Inc. Для примера, ее дисковод Sierra 1.3 Гбайт обеспечивает среднее время доступа 19 мс и среднее время наработки на отказ 80000 часов. Для серверов локальных сетей и рабочих станций компания Pinnacle Micro предлагает целый спектр многодисковых систем емкостью 20, 40, 120, 186 Гбайт и даже 4 Тбайт. Для систем высокой готовности Pinnacle Micro выпускает дисковый массив Array Optical Disk System, который обеспечивает эффективное время доступа к данным не более 11 мс при скорости передачи данных до 10 Мбайт/с.
Дисковые массивы и уровни RAID
Одним из способов повышения производительности ввода/вывода является использование параллелизма путем объединения нескольких физических дисков в матрицу (группу) с организацией их работы аналогично одному логическому диску. К сожалению, надежность матрицы любых устройств падает при увеличении числа устройств.
Для достижения повышенного уровня отказоустойчивости приходится жертвовать пропускной способностью ввода/вывода или емкостью памяти. Необходимо использовать дополнительные диски, содержащие избыточную информацию, позволяющую восстановить исходные данные при отказе диска. Отсюда получают акроним для избыточных матриц недорогих дисков RAID (redundant array of inexpensive disks). Существует несколько способов объединения дисков RAID. Каждый уровень представляет свой компромисс между пропускной способностью ввода/вывода и емкостью диска, предназначенной для хранения избыточной информации.
Когда какой-либо диск отказывает, предполагается, что в течение короткого интервала времени он будет заменен и информация будет восстановлена на новом диске с использованием избыточной информации. Это время называется средним временем восстановления (mean time to repair - MTTR). Этот показатель можно уменьшить, если в систему входят дополнительные диски в качестве "горячего резерва": при отказе диска резервный диск подключается аппаратно-программными средствами. Периодически оператор вручную заменяет все отказавшие диски. Четыре основных этапа этого процесса состоят в следующем:
Определение отказавшего диска,
Устранение отказа без останова обработки;
Восстановление потерянных данных на резервном диске;
Периодическая замена отказавших дисков на новые.
RAID1: Зеркальные диски.
Зеркальные диски представляют традиционный способ повышения надежности магнитных дисков. Это наиболее дорогостоящий из рассматриваемых способов, так как все диски дублируются и при каждой записи информация записывается также и на проверочный диск. Таким образом, приходится идти на некоторые жертвы в пропускной способности ввода/вывода и емкости памяти ради получения более высокой надежности. Зеркальные диски широко применяются многими фирмами. В частности компания Tandem Computers применяет зеркальные диски, а также дублирует контроллеры и магистрали ввода/вывода с целью повышения отказоустойчивости. Эта версия зеркальных дисков поддерживает параллельное считывание.
Дублирование всех дисков может означать удвоение стоимости всей системы или, иначе, использование лишь 50% емкости диска для хранения данных. Повышение емкости, на которое приходится идти, составляет 100%. Такая низкая экономичность привела к появлению следующего уровня RAID.
RAID 2: матрица с поразрядным расслоением
Один из путей достижения надежности при снижении потерь емкости памяти может быть подсказан организацией основной памяти, в которой для исправления одиночных и обнаружения двойных ошибок используются избыточные контрольные разряды. Такое решение можно повторить путем поразрядного расслоения данных и записи их на диски группы, дополненной достаточным количеством контрольных дисков для обнаружения и исправления одиночных ошибок. Один диск контроля четности позволяет обнаружить одиночную ошибку, но для ее исправления требуется больше дисков.
При записи больших массивов данных системы уровня 2 имеют такую же производительность, что и системы уровня 1, хотя в них используется меньше контрольных дисков и, таким образом, по этому показателю они превосходят системы уровня 1. При передаче небольших порций данных производительность теряется, так как требуется записать либо считать группу целиком, независимо от конкретных потребностей.
RAID 3: аппаратное обнаружение ошибок и четность
Большинство контрольных дисков, используемых в RAID уровня 2, нужны для определения положения неисправного разряда. Эти диски становятся полностью избыточными, так как большинство контроллеров в состоянии определить, когда диск отказал при помощи специальных сигналов, поддерживаемых дисковым интерфейсом, либо при помощи дополнительного кодирования информации, записанной на диск и используемой для исправления случайных сбоев. По существу, если контроллер может определить положение ошибочного разряда, то для восстановления данных требуется лишь один бит четности. Уменьшение числа контрольных дисков до одного на группу снижает избыточность емкости до вполне разумных размеров. Часто количество дисков в группе равно 5 (4 диска данных плюс 1 контрольный). Подобные устройства выпускаются, например, фирмами Maxtor и Micropolis. Каждое из таких устройств воспринимается машиной как отдельный логический диск с учетверенной пропускной способностью, учетверенной емкостью и значительно более высокой надежностью.
RAID 4: внутригрупповой параллелизм
RAID уровня 4 повышает производительность передачи небольших объемов данных за счет параллелизма, давая возможность выполнять более одного обращения по вводу/выводу к группе в единицу времени. Логические блоки передачи в данном случае не распределяются между отдельными дисками, вместо этого каждый индивидуальный блок попадает на отдельный диск.
Достоинство поразрядного расслоения состоит в простоте вычисления кода Хэмминга, что необходимо для обнаружения и исправления ошибок в системах уровня 2. В RAID уровня 3 обнаружение ошибок диска с точностью до сектора осуществляется дисковым контроллером. Следовательно, если записывать отдельный блок передачи в отдельный сектор, то можно обнаружить ошибки отдельного считывания без доступа к дополнительным дискам. Главное отличие между системами уровня 3 и 4 состоит в том, что в последних расслоение выполняется на уровне сектора, а не на уровне битов или байтов.
В системах уровня 4 для записи небольших массивов данных используются два диска, которые выполняют четыре выборки (чтение данных плюс четности, запись данных плюс четности). Производительность групповых операций записи и считывания остается прежней, но при небольших (на один диск) записях и считываниях производительность существенно улучшается. К сожалению, улучшение производительности оказывается недостаточной для того, чтобы этот метод мог занять место системы уровня 1.
RAID 5: четность вращения для распараллеливания записей
RAID уровня 4 позволяли добиться параллелизма при считывании отдельных дисков, но запись по-прежнему ограничена возможностью выполнения одной операции на группу, так как при каждой операции должны выполняться запись и чтение контрольного диска. Система уровня 5 улучшает возможности системы уровня 4 посредством распределения контрольной информации между всеми дисками группы.
Это небольшое изменение оказывает огромное влияние на производительность записи небольших массивов информации. Если операции записи могут быть спланированы так, чтобы обращаться за данными и соответствующими им блоками четности к разным дискам, появляется возможность параллельного выполнения N/2 записей, где N - число дисков в группе. Данная организация имеет одинаково высокую производительность при записи и при считывании как небольших, так и больших объемов информации, что делает ее наиболее привлекательной в случаях смешанных применений.
RAID 6: Двумерная четность для обеспечения большей надежности
Этот пункт можно рассмотреть в контексте соотношения отказоустойчивость/пропускная способность. RAID 5 предлагают, по существу, лишь одно измерение дисковой матрицы, вторым измерением которой являются секторы. Теперь рассмотрим объединение дисков в двумерный массив таким образом, чтобы секторы являлись третьим измерением. Мы можем иметь контроль четности по строкам, как в системах уровня 5, а также по столбцам, которые, в свою очередь. могут расслаиваться для обеспечения возможности параллельной записи. При такой организации можно преодолеть любые отказы двух дисков и многие отказы трех дисков. Однако при выполнении логической записи реально происходит шесть обращений к диску: за старыми данными, за четностью по строкам и по столбцам, а также для записи новых данных и новых значений четности. Для некоторых применений с очень высокими требованиями к отказоустойчивости такая избыточность может оказаться приемлемой, однако для традиционных суперкомпьютеров и для обработки транзакций данный метод не подойдет.
Лазерные компакт-диски CD - ROM
Для переноса больших объемов данных используют лазерные компакт-диски, получившие обозначение CD-ROM (Compact Disc Read Only Memory). В силу большой емкости (один диск может содержать до 650 Мбайт данных) эти носители широко используются для распространения мультимедийной информации, содержащей большие объемы графики, звука и видео. Они также не имеют конкурентов по параметру стоимости хранения мегабайта информации.
Сегодня диски CD-ROM являются основным типом носителя для распространения программного обеспечения. Если компьютер не имеет дисковода CD-ROM, установка нового программного обеспечения превращается в серьезную проблему.
Основным техническим требованием к дисководам CD-ROM является скорость доступа к данным и скорость их считывания. Этот параметр измеряется в кратных единицах. Так, например, 2-скоростные дисководы обеспечивают скорость считывания 300 Кбит в секунду. Соответственно, 4-скоростные дисководы обеспечивают скорость 600 Кбит в секунду и т. д.
Производительность дисковода CD-ROM нам чаще всего важна не сама по себе, а в сравнении с производительностью жесткого диска. Современные 24- и 32-скоростные дисководы CD-ROM по параметру скорости считывания данных намного превосходят жесткие диски, но могут уступать им во времени доступа к данным.
Лазерные компакт-диски не боятся магнитных полей и менее критичны к пыли и влаге, чем магнитные дискеты. В то же время, в большинстве случаев они не защищены пластиковым корпусом, как магнитные дискеты, и при неакуратном обращении могут получать механические повреждения: царапины, трещины, сколы и т. п. В качестве интерфейса применяются SCSI/ASPI - самый подходящий, но дорогой, иногда рекомендуется - IDI/ATAPI.
CD-R
В отличие от CD-ROM могут не только читать диски, но и записывать их. Могут устанавливаться в компьютер вместо CD-ROM. Запись на диски CD-R осуществляется благодаря наличию на нем особо светочувствительного слоя, выгорающего под воздействием высокотемпературного лазерного луча. То есть перед нами нечто похожее на обычную фотографию. Правда, считывает CD-R по нынешним временам не слишком быстро - со скоростью 8-скоростного CD-ROM (8 x 150 = 1200 кб/c = 1,17 Мб/c), но ведь чтение - не главная его функция. Главная - запись. Писать CD-R может в 2-х режимах - односессионном (когда весь диск записывается в один прием) и многосессионном. CD-R - идеален для хранения всевозможных архивов (изображений, звуков, да и просто программ, загромождающих место на вашем жестком диске). Можно сделать копию содержимого всего жесткого диска (на всякий случай). И, конечно же, копировать аудио-, видеодиски и программы.
CD-RW
Новый стандарт перезаписываемых CD-ROM. Внешне диски не отличаются от обычных CD-R, объем - тот же - 640 Мб. Но технология записи CD-R и CD-RW разная.
На дисках CD-RW также имеются поглощающие и отражающие свет участки. Однако это не бугорки или ямки, как в дисководах CD-ROM и CD-R. Диск CD-RW представляет из себя как бы слоеный пирог, где на металлической основе покоится рабочий, активный слой. Он состоит из специального материала, который под воздействием лазерного луча изменяет свое состояние. Находясь в кристаллическом состоянии, одни участки слоя рассеивают свет, а другие - аморфные - пропускают его через себя на отражающую металлическую подложку.
Достоинства:
На диск можно записывать информацию и читать ее;
Дисковод CD-RW использует как диски собственного формата, так и с диски CD-ROM и CD-R. Последние он не только читает, но и пишет, причем в любом - односессионном или многосессионном формате.
Недостатки:
Перезаписываемые диски CD-RW могут читать не все современные дисководы CD-ROM - только последние модели, соответствующие стандарту Multiread. И даже если вы запишите на CD-RW музыкальный диск, его не прочтет ни один чисто музыкальный компакт-проигрыватель.
Высокая цена: цена диска в 2 - 2,5 раза выше, чем у CD-R.
Низкая скорость: запись дисков - максимум на учетверенной скорости, а чтение - со скоростью 6х и 8х.
DVD
В свое время к 2000 году, по обещаниям разработчиков, видеокассеты, компакт-диски и другие носители информации должны были прекратить свое существование. Их должны были заменить Единые и Универсальные - DVD.
Сначала DVD расшифровывался так - Digital Video Disk - цифровой видеодиск нового поколения. Но позднее консорциум DVD отказался от этой расшифровки. Впервые слово DVD прозвучало в мире 8 декабря 1995 года. DVD может быть односторонним и двухсторонним, однослойным и многослойным. Но фирмы, входящие в консорциум так до сих пор решение и не приняли. Поэтому пока остановились на односторонних и однослойных.
По внешнему виду и способу записи DVD не очень отличаются от привычных CD-ROM. Но однослойный и односторонний DVD имеет емкость 4,7 Гбайт (в 8 раз больше объема CD-ROM). Объем двухстороннего и многослойного DVD может достигать 17 Гбайт. На одном DVD можно уместить видеофильм на 140 минут с пятью альтернативными звуковыми дорожками на разных языках и четырьмя каналами субтитров. Сравнительно недавно появились первые записывающие дисководы DVD-R, а в дальнейшем - перезаписывающие дисководы DVD-RW (DVD-RAM), работающие с односторонними однослойными дисками емкостью 4,7 Гбайт (или 5,2 Гбайт - в зависимости от производителя). В дальнейшем появились DVD-RW, работающие с многослойными дисками объемом до и более 10 Гбайт.
Можно было бы продолжить обзор устройств внешней памяти, однако как бы мы не поспешали прогресс в этой области обогнать невозможно. С каждой минутой появляются не только новые устройства, но и совершенно новые принципы хранения информации.
Выводы
Основная функция всех видов внешней памяти ЭВМ состоит в том, чтобы сохранять информацию для повторного использования, а также для использования виртуального увеличения объема памяти.
Данные на внешних носителях недоступны человеку без помощи компьютера.
Информация на носителях внешней памяти хранится в виде отдельных блоков - секторов. Сектор является неделимой единицей информации, т. е. может быть прочитан только целиком.
В обмене данными между внешней памятью и внутренней существенную роль играют контроллеры (интерфейсы), которые обслуживают диск.
В любой момент времени процессор работает только с ОП, в которую она предварительно заносится из ВП.
Все виды памяти связаны между собой, образуя общую иерархию.
Вопросы и задания
Что такое кластер? Перечислите методы борьбы с кластеризацией.
Дайте развернутую характеристику FAT 32.
В чем состоит различие между физическим и логическим форматированием7
Как и в каких случаях выполняется дефрагментация ЖД?
В чем заключается смысл и предназначение RAID-массивов?
Лекция 11. Основные принципы построения систем ввода/вывода
Функционирование любой вычислительной системы обычно сводится к выполнению двух видов работы: обработке информации и операций по осуществлению ее ввода-вывода. Содержание понятий "обработка информации" и "операции ввода-вывода" зависит от того, с какой точки зрения мы смотрим на них. С точки зрения программиста, под "обработкой информации" понимается выполнение команд процессора над данными, лежащими в памяти независимо от уровня иерархии - в регистрах, кэше, оперативной или вторичной памяти. Под "операциями ввода-вывода" программист понимает обмен данными между памятью и устройствами, внешними по отношению к памяти и процессору, такими как магнитные ленты, диски, монитор, клавиатура, таймер. С точки зрения операционной системы "обработкой информации" являются только операции, совершаемые процессором над данными, находящимися в памяти на уровне иерархии не ниже, чем оперативная память. Все остальное относится к "операциям ввода-вывода". Чтобы выполнять операции над данными, временно расположенными во вторичной памяти, операционная система, сначала производит их подкачку в оперативную память, и лишь затем процессор совершает необходимые действия.
Данная лекция будет посвящена второму виду работы вычислительной системы - операциям ввода-вывода. Мы разберем, что происходит в компьютере при выполнении операций ввода-вывода, и как операционная система управляет их выполнением. При этом для простоты будем считать, что объем оперативной памяти в вычислительной системе достаточно большой, т. е. все процессы полностью располагаются в оперативной памяти, и поэтому понятие "операция ввода-вывода" с точки зрения операционной системы и с точки зрения пользователя означает одно и то же. Такое предположение не снижает общности нашего рассмотрения, так как подкачка информации из вторичной памяти в оперативную память и обратно обычно строится по тому же принципу, что и все операции ввода-вывода.
Прежде чем говорить о работе операционной системы при осуществлении операций ввода-вывода, нам придется понять, как осуществляется передача информации между оперативной памятью и внешним устройством и почему для подключения к вычислительной системе новых устройств ее не требуется перепроектировать.
Физические принципы организации ввода-вывода
Существует много разнообразных устройств, которые могут взаимодействовать с процессором и памятью: таймер, жесткие диски, клавиатура, дисплеи, мышь, модемы и т. д., вплоть до устройств отображения и ввода информации в авиационно-космических тренажерах. Часть этих устройств может быть встроена внутрь корпуса компьютера, часть вынесена за его пределы и общаться с компьютером через различные линии связи: кабельные, оптоволоконные, радиорелейные, спутниковые и т. д. Конкретный набор устройств и способы их подключения определяются целями функционирования вычислительной системы, желаниями и финансовыми возможностями пользователя. Несмотря на все многообразие устройств, управление их работой и обмен информацией с ними строятся на относительно небольшом наборе принципов, которые мы постараемся разобрать в этом разделе.
Любая ЭВМ представляет собой сложную систему, включающую в себя большое количество различных устройств. Связь устройств ЭВМ между собой осуществляется с помощью сопряжения, которые в вычислительной технике называются интерфейсами.
Интерфейс
Интерфейс - это совокупность программных и аппаратных средств, предназначенных для передачи информации между компонентами ЭВМ и включающих в себя электронные схемы, линии, шины и сигналы адресов, данных и управления, алгоритмы передачи сигналов и правила интерпретации сигналов устройствами.
Интерфейсы характеризуются следующими параметрами:
Пропускная способность - количество информации, которая может быть передана через интерфейс в единицу времени;
Максимальная частота передачи информационных сигналов через интерфейс;
Максимально допустимое расстояние между соединяемыми устройствами;
Общее число проводов (линий) в интерфейсе;
Информационная ширина интерфейса - число бит или байт данных, передаваемых параллельно через интерфейс.
К динамическим параметрам интерфейса относится время передачи отдельного слова и блока данных с учетом продолжительности процедур подготовки и завершения передачи. Разработка систем ввода-вывода требует решения целого ряда проблем, среди которых выделим следующие:
Необходимо обеспечить возможность реализации ЭВМ с переменным составом оборудования, в первую очередь, с различным набором устройств ввода-вывода, с тем, чтобы пользователь мог выбирать конфигурацию машины в соответствии с ее назначением, легко добавлять новые устройства и отключать те, в использовании которых он не нуждается;
Для эффективного и высокопроизводительного использования оборудования компьютера следует реализовать параллельную во времени работу процессора над вычислительной частью программы и выполнение периферийными устройствами процедур ввода-вывода;
Необходимо упростить для пользователя и стандартизовать программирование операций ввода-вывода, обеспечить независимость программирования ввода-вывода от особенностей того или иного периферийного устройства;
В ЭВМ должно быть обеспечено автоматическое распознавание и реакция процессора на многообразие ситуаций, возникающих в УВВ (готовность устройства, отсутствие носителя, различные нарушения нормальной работы и др.).
Магистрально-модульный способ построения ЭВМ
Главным направлением решения указанных проблем является магистрально-модульный способ построения ЭВМ (рис.9.1) все устройства, составляющие компьютер, включая и микропроцессор, организуются в виде модулей, которые соединяются между собой общей магистралью. Обмен информацией по магистрали удовлетворяет требованиям некоторого общего интерфейса, установленного для магистрали данного типа. Каждый модуль подключается к магистрали посредством специальных интерфейсных схем (Иi).
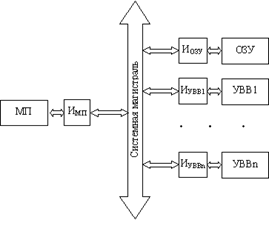
Рис. 11.1 Магистрально-модульный принцип построения ЭВМ
На интерфейсные схемы модулей возлагаются следующие задачи:
Обеспечение функциональной и электрической совместимости сигналов и протоколов обмена модуля и системной магистрали;
Преобразование внутреннего формата данных модуля в формат данных системной магистрали и обратно;
Обеспечение восприятия единых команд обмена информацией и преобразование их в последовательность внутренних управляющих сигналов.
Эти интерфейсные схемы могут быть достаточно сложными и по своим возможностям соответствовать универсальным микропроцессорам. Такие схемы принято называть контроллерами. Контроллеры обладают высокой степенью автономности, что позволяет обеспечить параллельную во времени работу периферийных устройств и выполнение программы обработки данных микропроцессором. Недостатком магистрально-модульного способа организации ЭВМ является невозможность одновременного взаимодействия более двух модулей, что ставит ограничение на производительность компьютера. Поэтому этот способ, в основном, используется в ЭВМ, к характеристикам которых не предъявляется очень высоких требований, например в персональных ЭВМ.
В простейшем случае процессор, память и многочисленные внешние устройства связаны большим количеством электрических соединений - линий, которые в совокупности принято называть локальной магистралью компьютера. Внутри локальной магистрали линии, служащие для передачи сходных сигналов и предназначенные для выполнения сходных функций, принято группировать в шины. При этом понятие шины включает в себя не только набор проводников, но и набор жестко заданных протоколов, определяющий перечень сообщений, который может быть передан с помощью электрических сигналов по этим проводникам. В современных компьютерах выделяют как минимум три шины:
Шину данных, состоящую из линий данных и служащую для передачи информации между процессором и памятью, процессором и устройствами ввода-вывода, памятью и внешними устройствами;
Адресную шину, состоящую из линий адреса и служащую для задания адреса ячейки памяти или указания устройства ввода-вывода, участвующих в обмене информацией;
Шину управления, состоящую из линий управления локальной магистралью и линий ее состояния, определяющих поведение локальной магистрали. В некоторых архитектурных решениях линии состояния выносятся из этой шины в отдельную шину состояния.
Количество линий, входящих в состав шины, принято называть разрядностью (шириной) этой шины. Ширина адресной шины, например, определяет максимальный размер оперативной памяти, которая может быть установлена в вычислительной системе. Ширина шины данных определяет максимальный объем информации, которая за один раз может быть получена или передана по этой шине.
Операции обмена информацией осуществляются при одновременном участии всех шин. Рассмотрим, к примеру, действия, которые должны быть выполнены для передачи информации из процессора в память. В простейшем случае необходимо выполнить три действия.
На адресной шине процессор должен выставить сигналы, соответствующие адресу ячейки памяти, в которую будет осуществляться передача информации.
На шину данных процессор должен выставить сигналы, соответствующие информации, которая должна быть записана в память.
После выполнения действий 1 и 2 на шину управления выставляются сигналы, соответствующие операции записи и работе с памятью, что приведет к занесению необходимой информации по нужному адресу.
Естественно, что приведенные выше действия являются необходимыми, но недостаточными при рассмотрении работы конкретных процессоров и микросхем памяти. Конкретные архитектурные решения могут требовать дополнительных действий: например, выставления на шину управления сигналов частичного использования шины данных (для передачи меньшего количества информации, чем позволяет ширина этой шины); выставления сигнала готовности магистрали после завершения записи в память, разрешающего приступить к новой операции, и т. д. Однако общие принципы выполнения операции записи в память остаются неизменными.
В то время как память легко можно представить себе в виде последовательности пронумерованных адресами ячеек, локализованных внутри одной микросхемы или набора микросхем, к устройствам ввода-вывода подобный подход неприменим. Внешние устройства разнесены пространственно и могут подключаться к локальной магистрали в одной точке или множестве точек, получивших название портов ввода-вывода. Тем не менее, точно так же, как ячейки памяти взаимно однозначно отображались в адресное пространство памяти, порты ввода-вывода можно взаимно однозначно отобразить в другое адресное пространство - адресное пространство ввода-вывода. При этом каждый порт ввода-вывода получает свой номер или адрес в этом пространстве. В некоторых случаях, когда адресное пространство памяти (размер которого определяется шириной адресной шины) задействовано не полностью (остались адреса, которым не соответствуют физические ячейки памяти) и протоколы работы с внешним устройством совместимы с протоколами работы с памятью, часть портов ввода - вывода может быть отображена непосредственно в адресное пространство памяти (так, например, поступают с видеопамятью дисплеев), правда, тогда эти порты уже не принято называть портами. Надо отметить, что при отображении портов в адресное пространство памяти для организации доступа к ним в полной мере могут быть задействованы существующие механизмы защиты памяти без организации специальных защитных устройств.
В ситуации прямого отображения портов ввода-вывода в адресное пространство памяти действия, необходимые для записи информации и управляющих команд в эти порты или для чтения данных из них и их состояний, ничем не отличаются от действий, производимых для передачи информации между оперативной памятью и процессором, и для их выполнения применяются те же самые команды. Если же порт отображен в адресное пространство ввода-вывода, то процесс обмена информацией инициируется специальными командами ввода-вывода и включает в себя несколько другие действия. Например, для передачи данных в порт необходимо выполнить следующее:
На адресной шине процессор должен выставить сигналы, соответствующие адресу порта, в который будет осуществляться передача информации, в адресном пространстве ввода-вывода;
На шину данных процессор должен выставить сигналы, соответствующие информации, которая должна быть передана в порт;
После выполнения действий 1 и 2 на шину управления выставляются сигналы, соответствующие операции записи и работе с устройствами ввода-вывода (переключение адресных пространств!), что приведет к передаче необходимой информации в нужный порт.
Существенное отличие памяти от устройств ввода-вывода заключается в том, что занесение информации в память является окончанием операции записи, в то время как занесение информации в порт зачастую представляет собой инициализацию реального совершения операции ввода-вывода. Что именно должны делать устройства, приняв информацию через свой порт, и каким именно образом они должны поставлять информацию для чтения из порта, определяется электронными схемами устройств, получившими название контроллеров. Контроллер может непосредственно управлять отдельным устройством (например, контроллер диска), а может управлять несколькими устройствами, связываясь с их контроллерами посредством специальных шин ввода-вывода (шина IDE, шина SCSI и т. д.).
Современные вычислительные системы могут иметь разнообразную архитектуру, множество шин и магистралей, мосты для перехода информации от одной шины к другой и т. п. Для нас сейчас важными являются только следующие моменты.
Устройства ввода-вывода подключаются к системе через порты.
Могут существовать два адресных пространства: пространство памяти и пространство ввода-вывода.
Порты, как правило, отображаются в адресное пространство ввода-вывода и иногда - непосредственно в адресное пространство памяти.
Использование того или иного адресного пространства определяется типом команды, выполняемой процессором, или типом ее операндов.
Физическим управлением устройством ввода-вывода, передачей информации через порт и выставлением некоторых сигналов на магистрали занимается контроллер устройства.
Именно единообразие подключения внешних устройств к вычислительной системе является одной из составляющих идеологии, позволяющих добавлять новые устройства без перепроектирования всей системы.
Структура контроллера устройства
Контроллеры устройств ввода-вывода весьма различны как по своему внутреннему строению, так и по исполнению (от одной микросхемы до специализированной вычислительной системы со своим процессором, памятью и т. д.), поскольку им приходится управлять совершенно разными приборами. Не вдаваясь в детали этих различий, мы выделим некоторые общие черты контроллеров, необходимые им для взаимодействия с вычислительной системой. Обычно каждый контроллер имеет по крайней мере четыре внутренних регистра, называемых регистрами состояния, управления, входных данных и выходных данных. Для доступа к содержимому этих регистров вычислительная система может использовать один или несколько портов, что для нас не существенно. Для простоты изложения будем считать, что каждому регистру соответствует свой порт.
Регистр состояния содержит биты, значение которых определяется состоянием устройства ввода-вывода и которые доступны только для чтения вычислительной системой. Эти биты индицируют завершение выполнения текущей команды на устройстве (бит занятости), наличие очередного данного в регистре выходных данных (бит готовности данных), возникновение ошибки при выполнении команды (бит ошибки)...
Регистр управления получает данные, которые записываются вычислительной системой для инициализации устройства ввода-вывода или выполнения очередной команды, а также изменения режима работы устройства. Часть битов в этом регистре может быть отведена под код выполняемой команды, часть битов будет кодировать режим работы устройства, бит готовности команды свидетельствует о том, что можно приступить к ее выполнению.
Регистр выходных данных служит для помещения в него данных для чтения вычислительной системой, а регистр входных данных предназначен для помещения в него информации, которая должна быть выведена на устройство. Обычно емкость этих регистров не превышает ширину линии данных (а чаще всего меньше ее), хотя некоторые контроллеры могут использовать в качестве регистров очередь FIFO для буферизации поступающей информации.
Разумеется, набор регистров и составляющих их битов приблизителен, он призван послужить нам моделью для описания процесса передачи информации от вычислительной системы к внешнему устройству и обратно, но в том или ином виде он обычно присутствует во всех контроллерах устройств.
Опрос устройств и прерывания. Исключительные ситуации и системные вызовы
Построив модель контроллера и представляя себе, что скрывается за словами "прочитать информацию из порта" и "записать информацию в порт", мы готовы к рассмотрению процесса взаимодействия устройства и процессора. Как и в предыдущих случаях, примером нам послужит команда записи, теперь уже записи или вывода данных на внешнее устройство. В нашей модели для вывода информации, помещающейся в регистр входных данных, без проверки успешности вывода процессор и контроллер должны связываться следующим образом:
Процессор в цикле читает информацию из порта регистра состояний и проверяет значение бита занятости. Если бит занятости установлен, то это означает, что устройство еще не завершило предыдущую операцию, и процессор уходит на новую итерацию цикла. Если бит занятости сброшен, то устройство готово к выполнению новой операции, и процессор переходит на следующий шаг.
Процессор записывает код команды вывода в порт регистра управления.
Процессор записывает данные в порт регистра входных данных.
Процессор устанавливает бит готовности команды. В следующих шагах процессор не задействован.
Когда контроллер замечает, что бит готовности команды установлен, он устанавливает бит занятости.
Контроллер анализирует код команды в регистре управления и обнаруживает, что это команда вывода. Он берет данные из регистра входных данных и инициирует выполнение команды.
После завершения операции контроллер обнуляет бит готовности команды.
При успешном завершении операции контроллер обнуляет бит ошибки в регистре состояния, при неудачном завершении команды - устанавливает его.
Контроллер сбрасывает бит занятости.
При необходимости вывода новой порции информации все эти шаги повторяются. Если процессор интересует, корректно или некорректно была выведена информация, то после шага 4 он должен в цикле считывать информацию из порта регистра состояний до тех пор, пока не будет сброшен бит занятости устройства, после чего проанализировать состояние бита ошибки.
Как видим, на первом шаге (и, возможно, после шага 4) процессор ожидает освобождения устройства, непрерывно опрашивая значение бита занятости. Такой способ взаимодействия процессора и контроллера получил название polling или, в русском переводе, способа опроса устройств. Если скорости работы процессора и устройства ввода-вывода примерно равны, то это не приводит к существенному уменьшению полезной работы, совершаемой процессором. Если же скорость работы устройства существенно меньше скорости процессора, то указанная техника резко снижает производительность системы и необходимо применять другой архитектурный подход. Для того чтобы процессор не дожидался состояния готовности устройства ввода-вывода в цикле, а мог выполнять в это время другую работу, необходимо, чтобы устройство само умело сигнализировать процессору о своей готовности. Технический механизм, который позволяет внешним устройствам оповещать процессор о завершении команды вывода или команды ввода, получил название механизма прерываний.
В простейшем случае для реализации механизма прерываний необходимо к имеющимся у нас шинам локальной магистрали добавить еще одну линию, соединяющую процессор и устройства ввода-вывода - линию прерываний. По завершении выполнения операции внешнее устройство выставляет на эту линию специальный сигнал, по которому процессор после выполнения очередной команды (или после завершения очередной итерации при выполнении цепочечных команд, т. е. команд, повторяющихся циклически со сдвигом по памяти) изменяет свое поведение. Вместо выполнения очередной команды из потока команд он частично сохраняет содержимое своих регистров и переходит на выполнение программы обработки прерывания, расположенной по заранее оговоренному адресу. При наличии только одной линии прерываний процессор при выполнении этой программы должен опросить состояние всех устройств ввода-вывода, чтобы определить, от какого именно устройства пришло прерывание (polling прерываний!), выполнить необходимые действия (например, вывести в это устройство очередную порцию информации или перевести соответствующий процесс из состояния ожидание в состояние готовность) и сообщить устройству, что прерывание обработано (снять прерывание).
В большинстве современных компьютеров процессор стараются полностью освободить от необходимости опроса внешних устройств, в том числе и от определения с помощью опроса устройства, сгенерировавшего сигнал прерывания. Устройства сообщают о своей готовности процессору не напрямую, а через специальный контроллер прерываний, при этом для общения с процессором он может использовать не одну линию, а целую шину прерываний. Каждому устройству присваивается свой номер прерывания, который при возникновении прерывания контроллер прерывания заносит в свой регистр состояния и, возможно, после распознавания процессором сигнала прерывания и получения от него специального запроса выставляет на шину прерываний или шину данных для чтения процессором. Номер прерывания обычно служит индексом в специальной таблице прерываний, хранящейся по адресу, задаваемому при инициализации вычислительной системы, и содержащей адреса программ обработки прерываний - векторы прерываний. Для распределения устройств по номерам прерываний необходимо, чтобы от каждого устройства к контроллеру прерываний шла специальная линия, соответствующая одному номеру прерывания. При наличии множества устройств такое подключение становится невозможным, и на один проводник (один номер прерывания) подключается несколько устройств. В этом случае процессор при обработке прерывания все равно вынужден заниматься опросом устройств для определения устройства, выдавшего прерывание, но в существенно меньшем объеме. Обычно при установке в систему нового устройства ввода-вывода требуется аппаратно или программно определить, каким будет номер прерывания, вырабатываемый этим устройством.
Организация передачи данных
В ЭВМ используются два основных способа организации передачи данных между памятью и периферийными устройствами: программно-управляемая передача и прямой доступ к памяти (ПДП).
Программно-управляемая передача данных осуществляется при непосредственном участии и под управлением процессора. Например, при пересылке блока данных из периферийного устройства в оперативную память процессор должен выполнить следующую последовательность шагов:
Сформировать начальный адрес области обмена ОП;
Занести длину передаваемого массива данных в один из внутренних регистров, который будет играть роль счетчика;
Выдать команду чтения информации из УВВ; при этом на шину адреса из МП выдается адрес УВВ, на шину управления - сигнал чтения данных из УВВ, а считанные данные заносятся во внутренний регистр МП;
Выдать команду записи информации в ОП; при этом на шину адреса из МП выдается адрес ячейки оперативной памяти, на шину управления - сигнал записи данных в ОП, а на шину данных выставляются данные из регистра МП, в который они были помещены при чтении из УВВ;
Модифицировать регистр, содержащий адрес оперативной памяти;
Уменьшить счетчик длины массива на длину переданных данных;
Если переданы не все данные, то повторить шаги 3-6, в противном случае закончить обмен.
Как видно, программно-управляемый обмен ведет к нерациональному использованию мощности микропроцессора, который вынужден выполнять большое количество относительно простых операций, приостанавливая работу над основной программой. При этом действия, связанные с обращением к оперативной памяти и к периферийному устройству, обычно требуют удлиненного цикла работы микропроцессора из-за их более медленной по сравнению с микропроцессором работы, что приводит к еще более существенным потерям производительности ЭВМ.
Альтернативой программно-управляемому обмену служит прямой доступ к памяти - способ быстродействующего подключения внешнего устройства, при котором оно обращается к оперативной памяти, не прерывая работы процессора. Такой обмен происходит под управлением отдельного устройства - контроллера прямого доступа к памяти (КПДП).
Структура ЭВМ, имеющей в своем составе КПДП, представлена на рис. 9.2
Рис. 11.2 Обмен данными в режиме прямого доступа к памяти
Перед началом работы контроллер ПДП необходимо инициализировать: занести начальный адрес области ОП, с которой производится обмен, и длину передаваемого массива данных. В дальнейшем по сигналу запроса прямого доступа контроллер фактически выполняет все те действия, которые обеспечивал микропроцессор при программно-управляемой передаче.
Последовательность действий КПДП при запросе на прямой доступ к памяти со стороны устройства ввода-вывода следующая:
Принять запрос на ПДП (сигнал DRQ) от УВВ.
Сформировать запрос к МП на захват шин (сигнал HRQ).
Принять сигнал от МП (HLDA), подтверждающий факт перевода микропроцессором своих шин в третье состояние.
Сформировать сигнал, сообщающий устройству ввода-вывода о начале выполнения циклов прямого доступа к памяти (DACK).
Сформировать на шине адреса компьютера адрес ячейки памяти, предназначенной для обмена.
Выработать сигналы, обеспечивающие управление обменом (IOR, MW для передачи данных из УВВ в оперативную память и IOW, MR для передачи данных из оперативной памяти в УВВ).
Уменьшить значение в счетчике данных на длину переданных данных.
Проверить условие окончания сеанса прямого доступа (обнуление счетчика данных или снятие сигнала запроса на ПДП). Если условие окончания не выполнено, то изменить адрес в регистре текущего адреса на длину переданных данных и повторить шаги 5-8.
Прямой доступ к памяти позволяет осуществлять параллельно во времени выполнение процессором программы и обмен данными между периферийным устройством и оперативной памятью.
Обычно программно-управляемый обмен используется в ЭВМ для операций ввода-вывода отдельных байт (слов), которые выполняются быстрее, чем при ПДП, так как исключаются потери времени на инициализацию контроллера ПДП, а в качестве основного способа осуществления операций ввода-вывода используют ПДП. Например, в стандартной конфигурации персональной ЭВМ обмен между накопителями на магнитных дисках и оперативной памятью происходит в режиме прямого доступа.
Прямой доступ к памяти (Direct Memory Access - DMA)
Использование механизма прерываний позволяет разумно загружать процессор в то время, когда устройство ввода-вывода занимается своей работой. Однако запись или чтение большого количества информации из адресного пространства ввода-вывода (например, с диска) приводят к большому количеству операций ввода-вывода, которые должен выполнять процессор. Для освобождения процессора от операций последовательного вывода данных из оперативной памяти или последовательного ввода в нее был предложен механизм прямого доступа внешних устройств к памяти - ПДП или Direct Memory Access - DMA. Давайте кратко рассмотрим, как работает этот механизм.
Для того чтобы какое-либо устройство, кроме процессора, могло записать информацию в память или прочитать ее из памяти, необходимо чтобы это устройство могло забрать у процессора управление локальной магистралью для выставления соответствующих сигналов на шины адреса, данных и управления. Для централизации эти обязанности обычно возлагаются не на каждое устройство в отдельности, а на специальный контроллер - контроллер прямого доступа к памяти. Контроллер прямого доступа к памяти имеет несколько спаренных линий - каналов DMA, которые могут подключаться к различным устройствам. Перед началом использования прямого доступа к памяти этот контроллер необходимо запрограммировать, записав в его порты информацию о том, какой канал или каналы предполагается задействовать, какие операции они будут совершать, какой адрес памяти является начальным для передачи информации и какое количество информации должно быть передано. Получив по одной из линий - каналов DMA сигнал запроса на передачу данных от внешнего устройства, контроллер по шине управления сообщает процессору о желании взять на себя управление локальной магистралью. Процессор, возможно, через некоторое время, необходимое для завершения его действий с магистралью, передает управление ею контроллеру DMA, известив его специальным сигналом. Контроллер DMA выставляет на адресную шину адрес памяти для передачи очередной порции информации и по второй линии канала прямого доступа к памяти сообщает устройству о готовности магистрали к передаче данных. После этого, используя шину данных и шину управления, контроллер DMA, устройство ввода-вывода и память осуществляют процесс обмена информацией. Затем контроллер прямого доступа к памяти извещает процессор о своем отказе от управления магистралью, и тот берет руководящие функции на себя. При передаче большого количества да нных весь процесс повторяется циклически.
При прямом доступе к памяти процессор и контроллер DMA по очереди управляют локальной магистралью. Это, конечно, несколько снижает производительность процессора, так как при выполнении некоторых команд или при чтении очередной порции команд во внутренний кэш он должен поджидать освобождения магистрали, но в целом производительность вычислительной системы существенно возрастает. При подключении к системе нового устройства, которое умеет использовать прямой доступ к памяти, обычно необходимо программно или аппаратно задать номер канала DMA, к которому будет приписано устройство. В отличие от прерываний, где один номер прерывания мог соответствовать нескольким устройствам, каналы DMA всегда находятся в монопольном владении устройств.
Логические принципы организации ввода-вывода
Рассмотренные в предыдущем разделе физические механизмы взаимодействия устройств ввода-вывода с вычислительной системой позволяют понять, почему разнообразные внешние устройства легко могут быть добавлены в существующие компьютеры. Все, что необходимо сделать пользователю при подключении нового устройства, - это отобразить порты устройства в соответствующее адресное пространство, определить, какой номер будет соответствовать прерыванию, генерируемому устройством, и, если нужно, закрепить за устройством некоторый канал DMA. Для нормального функционирования hardware этого будет достаточно. Однако мы до сих пор ничего не сказали о том, как должна быть построена подсистема управления вводом-выводом в операционной системе для легкого и безболезненного добавления новых устройств и какие функции вообще обычно на нее возлагаются.
Структура системы ввода-вывода
Если поручить неподготовленному пользователю сконструировать систему ввода-вывода, способную работать со всем множеством внешних устройств, то, скорее всего, он окажется в ситуации, в которой находились биологи и зоологи до появления трудов Линнея. Все устройства разные, отличаются по выполняемым функциям и своим характеристикам, и кажется, что принципиально невозможно создать систему, которая без больших постоянных переделок позволяла бы охватывать все многообразие видов. Вот перечень лишь нескольких направлений (далеко не полный), по которым различаются устройства.
Скорость обмена информацией может варьироваться в диапазоне от нескольких байтов в секунду (клавиатура) до нескольких гигабайтов в секунду (сетевые карты).
Одни устройства могут использоваться несколькими процессами параллельно (являются разделяемыми), в то время как другие требуют монопольного захвата процессом.
Устройства могут запоминать выведенную информацию для ее последующего ввода или не обладать этой функцией. Устройства, запоминающие информацию, в свою очередь, могут дифференцироваться по формам доступа к сохраненной информации: обеспечивать к ней последовательный доступ в жестко заданном порядке или уметь находить и передавать только необходимую порцию данных.
Часть устройств умеет передавать данные только по одному байту последовательно (символьные устройства), а часть устройств умеет передавать блок байтов как единое целое (блочные устройства).
Существуют устройства, предназначенные только для ввода информации, устройства, предназначенные только для вывода информации, и устройства, которые могут выполнять и ввод, и вывод.
В области технического обеспечения удалось выделить несколько основных принципов взаимодействия внешних устройств с вычислительной системой, т. е. создать единый интерфейс для их подключения, возложив все специфические действия на контроллеры самих устройств. Тем самым конструкторы вычислительных систем переложили все хлопоты, связанные с подключением внешней аппаратуры, на разработчиков самой аппаратуры, заставляя их придерживаться определенного стандарта.
Похожий подход оказался продуктивным и в области программного подключения устройств ввода-вывода. Подобно тому как Линнею удалось заложить основы систематизации знаний о растительном и животном мире, разделив все живое в природе на относительно небольшое число классов и отрядов, мы можем разделить устройства на относительно небольшое число типов, отличающихся по набору операций, которые могут быть ими выполнены, считая все остальные различия несущественными. Мы можем затем специфицировать интерфейсы между ядром операционной системы, осуществляющим некоторую общую политику ввода-вывода, и программными частями, непосредственно управляющими устройствами, для каждого из таких типов. Более того, разработчики операционных систем получают возможность освободиться от написания и тестирования этих специфических программных частей, получивших название драйверов, передав эту деятельность производителям самих внешних устройств. Фактически мы приходим к использованию принципа уровневого или слоеного построения системы управления вводом-выводом для операционной системы.
Два нижних уровня этой слоеной системы составляет hardware: сами устройства, непосредственно выполняющие операции, и их контроллеры, служащие для организации совместной работы устройств и остальной вычислительной системы. Следующий уровень составляют драйверы устройств ввода-вывода, скрывающие от разработчиков операционных систем особенности функционирования конкретных приборов и обеспечивающие четко определенный интерфейс между hardware и вышележащим уровнем - уровнем базовой подсистемы ввода-вывода, которая, в свою очередь, предоставляет механизм взаимодействия между драйверами и программной частью вычислительной системы в целом.
Структура системы ввода-вывода
Буферизация и кэширование
Под буфером обычно понимается некоторая область памяти для запоминания информации при обмене данных между двумя устройствами, двумя процессами или процессом и устройством. Обмен информацией между двумя процессами относится к области кооперации процессов, и мы подробно рассмотрели его организацию в соответствующей лекции. Здесь нас будет интересовать использование буферов в том случае, когда одним из участников обмена является внешнее устройство. Существует три причины, приводящие к использованию буферов в базовой подсистеме ввода-вывода.
Первая причина буферизации - это разные скорости приема и передачи информации, которыми обладают участники обмена. Рассмотрим, например, случай передачи потока данных от клавиатуры к модему. Скорость, с которой поставляет информацию клавиатура, определяется скоростью набора текста человеком и обычно существенно меньше скорости передачи данных модемом. Для того чтобы не занимать модем на все время набора текста, делая его недоступным для других процессов и устройств, целесообразно накапливать введенную информацию в буфере или нескольких буферах достаточного размера и отсылать ее через модем после заполнения буферов.
Вторая причина буферизации - это разные объемы данных, которые могут быть приняты или получены участниками обмена единовременно. Возьмем другой пример. Пусть информация поставляется модемом и записывается на жесткий диск. Помимо обладания разными скоростями совершения операций, модем и жесткий диск представляют собой устройства разного типа. Модем является символьным устройством и выдает данные байт за байтом, в то время как диск является блочным устройством и для проведения операции записи для него требуется накопить необходимый блок данных в буфере. Здесь также можно применять более одного буфера. После заполнения первого буфера модем начинает заполнять второй, одновременно с записью первого на жесткий диск. Поскольку скорость работы жесткого диска в тысячи раз больше, чем скорость работы модема, к моменту заполнения второго буфера операция записи первого будет завершена, и модем снова сможет заполнять первый буфер одновременно с записью второго на диск.
Третья причина буферизации связана с необходимостью копирования информации из приложений, осуществляющих ввод-вывод, в буфер ядра операционной системы и обратно. Допустим, что некоторый пользовательский процесс пожелал вывести информацию из своего адресного пространства на внешнее устройство. Для этого он должен выполнить системный вызов с обобщенным названием write, передав в качестве параметров адрес области памяти, где расположены данные, и их объем. Если внешнее устройство временно занято, то возможна ситуация, когда к моменту его освобождения содержимое нужной области окажется испорченным (например, при использовании асинхронной формы системного вызова). Чтобы избежать возникновения подобных ситуаций, проще всего в начале работы системного вызова скопировать необходимые данные в буфер ядра операционной системы, постоянно находящийся в оперативной памяти, и выводить их на устройство из этого буфера.
Под словом кэш (cache - "наличные"), этимологию которого мы не будем здесь рассматривать, обычно понимают область быстрой памяти, содержащую копию данных, расположенных где-либо в более медленной памяти, предназначенную для ускорения работы вычислительной системы. Мы с вами сталкивались с этим понятием при рассмотрении иерархии памяти. В базовой подсистеме ввода-вывода не следует смешивать два понятия, буферизацию и кэширование, хотя зачастую для выполнения этих функций отводится одна и та же область памяти. Буфер часто содержит единственный набор данных, существующий в системе, в то время как кэш по определению содержит копию данных, существующих где-нибудь еще. Например, буфер, используемый базовой подсистемой для копирования данных из пользовательского пространства процесса при выводе на диск, может в свою очередь применяться как кэш для этих данных, если операции модификации и повторного чтения данного блока выполняются достаточно часто. Функции буферизации и кэширования не обязательно должны быть локализованы в базовой подсистеме ввода-вывода. Они могут быть частично реализованы в драйверах и даже в контроллерах устройств, скрытно по отношению к базовой подсистеме.
С ростом частоты работы ЦП и изменения времени доступа к ОЗУ пропускная способность шины ISA в 8 Мбайт/сек стала тормозить работу процессора. Решение проблемы нашли в выделении канала передачи данных МП-ОЗУ в отдельную шину, построенную на базе внешнего интерфейса ЦП, и изолированную от медленной шины ISA посредством контроллера шины данных. Это повысило производительность работы центрального процессора. Все ПУ продолжали взаимодействовать с центральным процессором через системную шину.
С дальнейшим ростом частоты работы ЦП тормозом в работе стало ОЗУ. Тогда ввели дополнительную высокоскоростную кэш - память, что уменьшило простои ЦП. Все ПУ продолжали работать через системную шину, но кроме ISA появились более скоростные шины EISA и MCA.
По способу передачи информации интерфейсы делятся на параллельные и последовательные. Разряды данных могут передаваться в интерфейсах одновременно, т. е. параллельно. Такие интерфейсы называются параллельными, и они имеют шину данных из стольких линий, сколько разрядов передается одновременно. При передаче данных по одной линии последовательно разряд за разрядом, интерфейс называют последовательным. Кажется очевидным, что при одной и той же скорости работы линий интерфейса, пропускная способность параллельного интерфейса выше, чем у последовательного. Однако повышение производительности за счет увеличения тактовой частоты передачи и количества линий данных упирается в волновые свойства соединительных кабелей. Задержка сигналов в различных линиях не одинакова, и это особенно сказывается при увеличении длины линий, что требует для надежной передачи данных дополнительных временных и аппаратных затрат, сдерживая этим рост пропускной способности параллельного интерфейса. Кроме того, в параллельных интерфейсах с увеличением числа параллельных линий и их длины труднее реализовать компенсацию помех, наводимых за счет электрического взаимодействия линий между собой. В последовательных интерфейсах есть свои проблемы повышения производительности, но т. к. в них используется меньшее число линий, повышение пропускной способности канала связи обходится дешевле.
Поэтому важным параметром интерфейсов является допустимое удаление соединяемых устройств. Оно определяется как частотными свойствами, так и помехозащищенностью используемых каналов связи.
Для интерфейса, соединяющего два устройства (модуля), различаются три возможных режима обмена: дуплексный, полудуплексный и симплексный. Дуплексный режим позволяет по одному каналу связи, но имеющему две группы линий "туда" и "обратно", одновременно передавать информацию в обоих направлениях. Он может быть асимметричным, если пропускная способность в направлении "туда" и "обратно" имеет существенно различающееся значения, или симметричным. Полудуплексный режим позволяет передавать информацию по одним и тем же линиям "туда" и "обратно" поочередно в разные моменты времени, при этом интерфейс имеет средства переключения направлений канала. Симплексный (односторонний) режим предусматривает только одно направление передачи информации (во встречном направлении могут передаваться только вспомогательные сигналы интерфейса).
Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени), а также использовать различные схемы арбитража (то есть способа совместного использования шины несколькими устройствами).
Асинхронная шина не тактируется. Вместо этого обычно используется старт-стопный режим передачи и протокол "рукопожатия" (handshaking) между источником и приемником данных на шине. Эта схема позволяет гораздо проще приспособить широкое разнообразие устройств и удлинить шину без беспокойства о перекосе сигналов синхронизации и о системе синхронизации. Если может использоваться синхронная шина, то она обычно быстрее, чем асинхронная, из-за отсутствия накладных расходов на синхронизацию шины для каждой транзакции. Выбор типа шины (синхронной или асинхронной) определяет не только пропускную способность, но также непосредственно влияет на емкость системы ввода/вывода в терминах физического расстояния и количества устройств, которые могут быть подсоединены к шине. Асинхронные шины по мере изменения технологии лучше масштабируются. Шины ввода/вывода обычно асинхронные.
Среди применяемых в современных ПК интерфейсов можно отметить EIDI, SCSI, SSA, USB, FireWire (IEEE 1394) и DeviceBay. Среди интерфейсов передачи данных особняком стоят порты ввода/вывода, использующиеся для подключения низкоскоростных периферийных устройств: последовательный порт (COM), параллельный порт (LPT), игровой порт и инфракрасный порт (IrDA).
На определенном этапе развития компьютеров стали широко использовать мультимедиа. Сразу выявилось узкое место во взаимодействии центрального процессора и видеокарты. Потребовалась пропускная способность более 100 Мбайт/с. Имеющиеся системные шины ISA, ЕISA, МСА не удовлетворяли этим условиям. Их пропускная способность составляла от 16 до 30 Мбайт/сек.
Стоит вспомнить, как развивались средства ввода/вывода. Уже к самым первым компьютерам требовалось подключить какие-то внешние устройства, в том числе для ввода и вывода на перфокарты, на магнитные ленты, нужны были принтеры, а затем диски и множество других устройств. Однако эти подключения оставались частными решениями, выполненными без соблюдения каких-либо общепринятых стандартов. Когда началось массовое производство миниЭВМ, потребовались технологии для унификации ввода/вывода, в ответ на это появилась архитектура общей шины, которая обеспечила единообразие подключения периферии, открыв, тем самым, рынок внешних устройств. В последующем, для связи с периферией была выделена отдельная специализированная шина PCI (Peripheral Connection Interface); она оказалась настолько удобной, что сохранилась до сих пор без радикальных изменений. Идеология шины PCI, из самого названия которой следует, что она служит для подключения периферии, складывалась в то время, когда сервер рассматривался как нечто изолированное. Поэтому в нее естественным образом заложена возможность подключения ограниченного количества периферийных устройств через контроллеры, соответствующие каждому типу устройства. Традиционный ввод/вывод предполагает подключение накопителей напрямую к стандартной шине PCI; для этого широко используются параллельные интерфейсы SCSI (Small Computer Systems Interface), ATA (Advanced Technology Attachment) или Fibre Channel Arbitrated Loop (FC-AL). Одновременно постепенно происходит сериализация интерфейсов; компьютерная индустрия мигрирует на Serial Attached SCSI и Serial ATA.
Выход был найден с разработкой и внедрением локальных высокоскоростных шин, посредством которых можно было связаться с памятью, на этой же шине работали жесткие диски, что также повышало качество вывода графической информации. Первой такой шиной была шина VL-bus, практически повторявшая интерфейс МП i486. Затем появилась локальная шина РСI. Она была процессорно-независимой и поэтому получила наибольшее распространение для последующих типов МП. Эта шина имела частоту работы 33 МГц и при 32-х разрядных данных обеспечивала пропускную способность в 132 Мбайт/с. Системная шина ISA по-прежнему использовалась в компьютерах, что позволяло применять в новых компьютерах огромное количество ранее разработанных аппаратных и программных средств.
В такой системе ввода-вывода различные ПУ подключались к разным шинам. Медленные - к ISA, а высокоскоростные - к РСI. Важнейшее отличие шины PCI от шины ISA заключается в возможности динамического конфигурирования периферийных устройств, то есть система распределяет ресурсы между периферийными устройствами оптимальным образом и без постороннего вмешательства. С появление шины РСI стало целесообразным использовать высокоскоростные параллельные и последовательные интерфейсы ПУ (SCSI, ATA, USB). Появление шины РСI не сняло всех проблем по качественному выводу визуальной информации для 3-х мерных изображений, "живого" видео. Здесь уже требовались скорости в сотни Мбайт/сек. В 1996г. фирма Intel разработала новую шину AGP, предназначенную только для связи ОЗУ и процессора с видеокартой монитора. Эта шина обеспечивала пропускную способность в сотни Мбайт/сек. Она непосредственно связывала видеокарту с ОЗУ минуя шину РСI.
Все шины систем ввода-вывода объединяются в единую транспортную среду передачи информации с помощью специальных устройств: мостов и контроллеров ввода-вывода (Chipset).
Мост - устройство, применяемое для объединения шин, использующих разные или одинаковые протоколы обмена. Мост - это сложное устройство, которое осуществляет не только коммутацию каналов передачи данных, но и производит управление соответствующими шинами.
В структуре компьютера, использующего шину РСI, применяются три типа мостов. Мост шины - южный мост (РСI Bridge), производящий подключение шины РСI к другим шинам, например, ISA или ЕISA. Главный мост - северный мост (Host Bridge), соединяющий шину РСI с системной шиной, кроме того, этот мост содержит контроллер ОЗУ, арбитр и схему автоконфигурации. Одноранговый мост (Peer-to-Peer) для соединения двух шин РСI между собой. Это делается для увеличения числа устройств, подключаемых к шине.
Для управления шинами и обеспечения выполнения функций интерфейсов, входящих в систему ввода-вывода, применяются специальные контроллеры и схемы. К ним можно отнести контроллеры прерываний 8259А и прямого доступа к памяти 8237А, таймер 8254А, часы реального времени, буферы шин данных, дешифраторы, мультиплексоры, регистры и другие логические устройства.
PCI Express
По прогнозам, в ближайшие десять лет требования к пропускной способности шин ввода-вывода возрастут в 50 раз. Но традиционная архитектура параллельных шин типа PCI и AGP уже почти достигла предела своих возможностей (физический лимит для них - примерно 1 ГГц). Последовательный интерфейс PCI Express, имеющий много общего с сетевой организацией обмена данными, призван заменить шину PCI (и ее клон - AGP), исправно работающую в компьютерной технике уже более десяти лет.
В то время как процессоры уже не первый год успешно движутся в направлении параллельных архитектур (SIMD-расширения, суперскалярность, конвейеризация, HyperTreading и многоядерность), шины передачи данных не менее успешно переходят на последовательные решения. Причины обеих тенденций схожи и довольно просты - необходимо сбалансированное наращивание производительности всех компонентов компьютеров, однако не всякие существующие архитектурные решения способны эффективно масштабироваться.
PCI Express была разработана с расчетом на разнообразные применения - от полной замены шин PCI 2.2 или PCI-X в настольных компьютерах и серверах до использования в мобильных, встроенных и коммуникационных устройствах. Номинальной рабочей частотой шины PCI Express является 2,5 ГГц. Физическая реализация шины передачи данных - это две дифференциальные пары проводников с импедансом 50 Ом (первая пара работает на прием, вторая - на передачу), данные по которым передаются с использованием избыточного кодирования по схеме "8/10" с исправлением ошибок. Это позволяет исправлять многие простые ошибки, неизбежные на столь высоких частотах. Как и в любой сети, передаваемые данные дополнительно нарезаются небольшими кусочками - фреймами. При тактовой частоте шины 2,5 ГГц мы получим скорость 2,5 Гбит/с. С учетом выбранной схемы "8/10" выходит 250 Мбайт/с, однако многоуровневая сетевая иерархия не может не сказаться на скорости работы, и реальная производительность шины оказывается значительно ниже - всего лишь около 200 Мбайт/с в каждую сторону. Впрочем, даже это на 50% больше, чем теоретическая пропускная способность шины PCI. Но это далеко не предел: PCI Express позволяет объединять в шину нескольких независимых линий передачи данных. Стандартом предусмотрено использование 1, 2, 4, 8, 16 и 32 линий - передаваемые данные поровну распределяются между ними по схеме "первый байт на первую линию, второй - на вторую, ..., n-й байт на n-ю линию, n+1-й снова на первую, n+2 снова на вторую" и так далее. Это не параллельная передача данных и даже не увеличение разрядности шины (поскольку все передающиеся по линиям данные передаются абсолютно независимо и асинхронно) - это именно объединение нескольких независимых линий. Причем передача по нескольким линиям никак не влияет на работу остальных слоев "пирамиды" и реализуется сугубо на "нижнем", физическом уровне. Именно этим достигается прекрасная масштабируемость PCI Express, позволяющая организовывать шины с максимальной пропускной способностью до 32x200=6,4 Гбайт/с в одном направлении, под стать лучшим параллельным шинам сегодняшнего дня. PCI Express относится к шинам класса "точка-точка", то есть одна шина может соединять только два устройства (в отличие от PCI, где на общую шину "вешались" все PCI-слоты компьютера), поэтому для организации подключения более чем одного устройства в топологию организуемой PCI Express, как и в Ethernet-решениях на базе витой пары или устройствах USB, придется вставлять хабы и свитчи, распределяющие сигнал по нескольким шинам. Это тоже одно из главных отличий PCI Express от прежних параллельных шин.
Чипсет
В настоящее время управление потоками передаваемых данных производится с помощью мостов и контроллеров, входящих в ChipSet. Именно ChipSet определяет основные особенности архитектуры компьютера и, соответственно, достигаемый уровень производительности в условиях, когда лимитирующим фактором становится не процессор, а его окружение - память и система ввода-вывода.
В плане практической реализации шина PCI Express представляет собой целый аппаратный комплекс, затрагивающий северный и южный мосты чипсета, коммутатор и оконечные устройства. Новым термином здесь является коммутатор (switch), заменяющий одну шину со многими подключениями коммутируемой технологией.
Коммутатор обеспечивает одноранговую связь между различными оконечными устройствами, то есть снижает нагрузку на мост. Поддерживаются несколько виртуальных каналов на один физический. Примерные схемы внедрения PCI Express в настольный компьютер и сервер представлены на следующем рисунке.
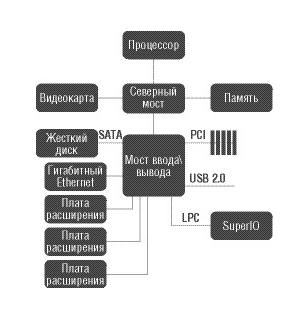
В "десктопных" системах PCI Express 16x в первую очередь вытеснит AGP 8x в качестве "графической шины", соединяющей видеокарту и северный мост чипсета. Затем на PCI Express пересадят многие интегрированные устройства - гигабитный сетевой и RAID-контроллеры. К обычным PCI-слотам добавят PCI Express x1. В качестве межчипсетной шины (соединяющей мосты чипсета) PCI Express будет выступать вместе со старыми шинами (VIA VLink, SiS MuTIOL) - некоторые производители чипсетов пока не желают отказываться от своих проприетарных шин.
Выводы
Функционирование любой вычислительной системы обычно сводится к выполнению двух видов работы: обработка информации и операции по осуществлению ее ввода-вывода. С точки зрения операционной системы "обработкой информации" являются только операции, совершаемые процессором над данными, находящимися в памяти на уровне иерархии не ниже чем оперативная память. Все остальное относится к "операциям ввода-вывода", т. е. к обмену информацией с внешними устройствами.
Несмотря на все многообразие устройств ввода-вывода, управление их работой и обмен информацией с ними строятся на относительно небольшом количестве принципов. Основными физическими принципами построения системы ввода-вывода являются следующие: возможность использования различных адресных пространств для памяти и устройств ввода-вывода; подключение устройств к системе через порты ввода-вывода, отображаемые в одно из адресных пространств; существование механизма прерывания для извещения процессора о завершении операций ввода-вывода; наличие механизма прямого доступа устройств к памяти, минуя процессор.
Механизм, подобный механизму прерываний, может использоваться также и для обработки исключений и программных прерываний, однако это целиком лежит на совести разработчиков вычислительных систем.
Для построения программной части системы ввода-вывода характерен "слоеный" подход. Для непосредственного взаимодействия с hardware используются драйверы устройств, скрывающие от остальной части операционной системы все особенности их функционирования.
Компоненты ЭВМ соединяются шинами. Большинство выводов обычного ЦПУ запускают одну линию шины. Линии шины можно подразделить на адресные, информационные и линии управления. Синхронные шины запускаются задающим генератором. В асинхронных шинах для согласования работы задающего и подчиненного устройств используется сигналы специального назначения. Современные процессоры используют все разнообразие шинных интерфейсов: PCI, ISA, USB, SCSI и т. д.
Вопросы и задания
Вычислите пропускную способность шины, необходимую для отображения на мониторе VGA (640x480) цветного фильма (30 кадров/с). Предполагается, что данные должны проходить по шине дважды: один раз от компакт диска к памяти, а второй раз от памяти к монитору.
Максимальная полезная нагрузка пакета данных, передаваемого по шине USB, составляет 1023 байта. Если предположить, что устройство может посылать только один пакет данных за кадр, какова пропускная способность для одного изохронного устройства?
Лекция 12. Особенности архитектуры современных высокопроизводительных ВС
Введение
Развитие вычислительных технологий и средств сопровождалось пониманием того, что работы надо делить между многими исполнительными устройствами. Основной критерий эффективности распараллеливания заключается в минимизации времени выполнения работы. Можно представить следующие направления развития параллельных технологий:
Параллельные структуры отображают организацию и взаимодействие исполнителей сложного комплекса взаимосвязанных работ. В вычислительной технике -- это проблема параллельного выполнения отдельных программ и целых программных комплексов, отображенная выбором архитектуры процессоров и многопроцессорных вычислительных систем. Взаимодействие исполнительных устройств должно минимизировать "накладные расходы" на организацию их взаимодействия.
Параллельное программирование объединяет проблемы оптимального статического и динамического планирования выполнения комплексов взаимосвязанных работ при заданном составе и структуре взаимодействия исполнителей.
Параллельные алгоритмы являются естественным результатом оптимального решения задач распараллеливания. Применение многопроцессорных вычислительных систем, а, в особенности, бурно развивающиеся сетевые технологии для решения задач высокой сложности.
Классификация архитектур по параллельной обработке данных
В 1966 году М. Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса.
- 1. SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако, каждый из них выполняют несвязанные потоки инструкций, что делает такие системы комплексами SIMD-систем, действующих на разных пространствах данных. Примерами компьютеров с архитектурой SISD являются большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems. 2. MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должны выполнятся над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, не было создано. В качестве аналога работы такой системы, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Поскольку база данных одна, а команд много, то мы имеем дело с множественным потоком команд и одиночным потоком данных. 3. SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров, в пределах от 1024 до 16384, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Примерами SIMD машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа является, например, компьютеры Hitachi S3600. 4. MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от многопроцессорных SISD-машин, упомянутых выше, команды и данные связаны, потому что они представляют различные части одной и той же выполняемой задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач, с целью сокращения времени выполнения основной задачи. Наличие большого разнообразия попадающих в данный класс систем, делает классификацию Флинна не полностью адекватной. Действительно и четырех-процессорный SX-5 компании NEC и тысяче-процессорный Cray T3E оба попадают в этот класс. Это заставляет использовать другой подход к классификации, иначе описывающий классы компьютерных систем. Основная идея такого подхода может состоять, например, в следующем. Считаем, что множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые обычно называют конвейерными или векторными, вторая - в параллельных компьютерах. В основе векторных компьютеров лежит концепция конвейеризации, т. е. явного сегментирования арифметического устройства на отдельные части, каждая из которых выполняет свою подзадачу для пары операндов. В основе параллельного компьютера лежит идея использования для решения одной задачи нескольких процессоров, работающих сообща, причем процессоры могут быть как скалярными, так и векторными. На рисунке 12.1 приведен пример такой классификации.
Параллелизм вычислительных процессов
Принцип организации вычислительного процесса, сформулированный фон Нейманом, называется также "управление потоком команд", поскольку стержень процесса образуется последовательностью (потоком) команд, задаваемых программой. По фон Нейману, данные занимают подчиненное положение, последовательность и способ их обработки определяется командами программы, т. е. ход выполнения вычислительного процесса определяется только потоком команд.
Довольно длительное время принцип фон Неймана предполагал единственную, как тогда казалось, архитектуру компьютера: процессор по очереди выбирает команды программы, по очереди их декодирует и также по очереди обрабатывает данные. Все строго последовательно, просто и понятно. Однако очень скоро выяснилось, что компьютерные вычисления обладают естественным параллелизмом, т. е. большая или меньшая часть команд программы может выполняться одновременно и независимо друг от друга. Вся дальнейшая история вычислительной техники развивалась в соответствии с логикой расширения параллелизма программ и компьютеров, и каждый новый шаг на этом пути предварялся теоретическим анализом.
Известный специалист по архитектуре компьютеров М. Флин (M. Flynn) обратил внимание на то, что существует всего две причины, порождающие вычислительный параллелизм - независимость потоков команд, одновременно существующих в системе, и несвязанность данных, обрабатываемых в одном потоке команд. Если первая основа
Параллелизма вычислительного процесса достаточно известна (это "обычное" мультипроцессирование) и не требует особых комментариев, то на параллелизме данных следует остановиться более подробно, поскольку в большинстве случаев он существует скрыто от программистов и используется ограниченным кругом профессионалов. Простейшим примером параллелизма данных является последовательность из двух команд:
A=B+C;
D=ExF;
Если строго следовать принципу фон Неймана, то вторая операция может быть запущена на исполнение только после завершения первой операции. Однако очевидно, что порядок выполнения этих команд не имеет никакого значения - операнды A, B и C первой команды никак не связаны с операндами D, E и F второй команды. Другими словами, обе операции являются параллельными именно потому, что операнды этих команд не связаны между собой. Можно привести множество примеров последовательности из трех и более команд с несвязанными данными, которые приведут к однозначному выводу: практически любая программа содержит группы операций над параллельными данными.
Итак - параллелизм верхнего уровня достигается за счет множества
Независимых командных потоков и реализуется с помощью
Многопроцессорной архитектуры;
- параллелизм нижнего уровня обязан своим существованием наличием
Несвязанных потоков данных и реализуется за счет конвейерной
Обработки различных фаз операций.
Параллелизм на уровне команд - однопроцессорные архитектуры
Мы уже неоднократно подчеркивали, что главным препятствием достижения высокой производительности ВС является обращение к памяти и вызов команд из памяти процессора. Для разрешения этой проблемы уже достаточно давно используется вызов команд из памяти заранее и помещение их в набор регистров (буфер выборки с упреждением), чтобы они имелись в наличии, когда это станет необходимым. В действительности процесс выборки с упреждением подразделяет выполнение команды в два этапа: вызов и собственно выполнение. Идея конвейера еще больше продвинула эту стратегию вперед. Теперь команда подразделялась уже не на два, а на несколько этапов, каждый из которых выполнялся определенной частью аппаратного обеспечения, причем все блоки могли работать одновременно и параллельно. Конвейерная обработка является "естественным" средством реализации параллелизма несвязанных операций и циклов, но в каждом случае со своими нюансами. Несвязанные операции выполняются с помощью набора самостоятельных арифметических устройств в составе ЦП (принцип многофункциональной обработки). Обычный набор таких устройств включает: устройство сложения, умножения, деления и устройства выполнения логических и сдвиговых операций.
Конвейерная обработка
Выполнение каждой команды складывается из ряда последовательных этапов (шагов, стадий), суть которых не меняется от команды к команде. С целью увеличения быстродействия процессора и максимального использования всех его возможностей в современных микропроцессорах используется конвейерный принцип обработки информации. Этот принцип подразумевает, что в каждый момент времени процессор работает над различными стадиями выполнения нескольких команд, причем на выполнение каждой стадии выделяются отдельные аппаратные ресурсы. По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую стадию обработки, выполненная команда покидает конвейер, а новая поступает в него.
Конвейеризация (или конвейерная обработка) в общем случае основана на разделении подлежащей исполнению функции на более мелкие части, называемые ступенями, и выделении для каждой из них отдельного блока аппаратуры. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах. Выполнение типичной команды можно разделить на следующие этапы:
С 1 - выборка команды (по адресу, заданному счетчиком команд, из памяти извлекается команда и помещается в буфер);
С 2 - декодирование команды (определение КОП и типа операндов);
С 3 - выборка операндов (определение местонахождения операндов и вызов их из регистров);
С 4 - выполнение команды;
С 5 - запись результата в нужный регистр.
Работу конвейера можно условно представить в виде временной диаграммы на которой обычно изображаются выполняемые команды, номера тактов и этапы выполнения команд. В качестве примера рассмотрим конвейерную машину с пятью этапами выполнения операций, которые имеют длительность 50, 50, 60, 50 и 50 нс соответственно. Пусть накладные расходы на организацию конвейерной обработки составляют 5 нс. Тогда среднее время выполнения команды в не конвейерной машине будет равно 260 нс. Если же используется конвейерная организация, длительность такта будет равна длительности самого медленного этапа обработки плюс накладные расходы, т. е. 65 нс. Это время соответствует среднему времени выполнения команды в конвейере. Таким образом, ускорение, полученное в результате конвейеризации, будет равно отношению:
Рис. 12.2 Диаграмма работы простейшего конвейера
Рис. 12.3 Эффект конвейеризации - четырехкратное ускорение
Мы уже упоминали, что параллелизм нижнего уровня реализуется на однопроцессорных машинах. Название однопроцессорные предполагает, что подобные архитектуры выполняют только один поток команд. Классическим примером однопроцессорной архитектуры является архитектура фон Неймана со строго последовательным выполнением команд. По мере развития вычислительной техники архитектура фон Неймана обогатилась сначала конвейером фаз операций, а затем многофункциональной обработкой и получила обобщенное название SISD. Оба вида средств низкоуровнего параллелизма впервые были введены в компьютерах Control Data 6600 и 7600 в начале 70-х годов и с тех пор применяются во всех компьютерах повышенного быстродействия. Наибольшее развитие идеи SISD-параллелизма получили в RISC-архитектурах.
Однако, при конвейерной обработке часто возникают конфликты, которые препятствуют выполнению очередной команды в предназначенном для нее такте. Конфликты могут иметь различное происхождение, но в целом их можно охарактеризовать как структурные, по управлению и по данным.
Структурные конфликты возникают в том случае, когда аппаратные средства процессора не могут поддерживать все возможные комбинации команд в режиме одновременного выполнения с совмещением. Эту ситуацию можно было бы ликвидировать двумя способами. Первый предполагает увеличение времени такта до такой величины, которая позволила бы все этапы любой команды выполнять за один такт. Однако при этом существенно снижается эффект конвейерной обработки, так как все этапы всех команд будут выполняться значительно дольше, в то время как обычно нескольких тактов требует выполнение лишь отдельных этапов очень небольшого количества команд. Второй способ предполагает использование таких аппаратных решений, которые позволили бы значительно снизить затраты времени на выполнение данного этапа (например, использовать матричные схемы умножения). Но это приведет к усложнению схемы процессора и невозможности реализации на этой БИС других, функционально более важных, узлов.
Наиболее эффективным методом снижения потерь от конфликтов по управлению служит предсказание переходов. Суть данного метода заключается в том, что при выполнении команды условного перехода специальный блок микропроцессора определяет наиболее вероятное направление перехода, не дожидаясь формирования признаков, на основании анализа которых этот переход реализуется. Процессор начинает выбирать из памяти и выполнять команды по предсказанной ветви программы (так называемое исполнение по предположению, или "спекулятивное" исполнение). Однако так как направление перехода может быть предсказано неверно, то получаемые результаты с целью обеспечения возможности их аннулирования не записываются в память или регистры (то есть для них не выполняется этап WB), а накапливаются в специальном буфере результатов. Если после формирования анализируемых признаков оказалось, что направление перехода выбрано верно, все полученные результаты переписываются из буфера по месту назначения, а выполнение программы продолжается в обычном порядке. Если направление перехода предсказано неверно, то буфер результатов очищается. Также очищается и конвейер, содержащий команды, находящиеся на разных этапах обработки, следующие за командой условного перехода. При этом аннулируются результаты всех уже выполненных этапов этих команд. Конвейер начинает загружаться с первой команды другой ветви программы. Так как конвейерная обработка эффективна при большом числе последовательно выполненных команд, то перезагрузка конвейера приводит к значительным потерям производительности. Поэтому вопросам эффективного предсказания направления ветвления разработчики всех микропроцессоров уделяют большое внимание.
Методы предсказания переходов делятся на статические и динамические. При использовании статических методов до выполнения программы для каждой команды условного перехода указывается направление наиболее вероятного ветвления. Это указание делается или программистом с помощью специальных средств, имеющихся в некоторых языках программирования, по опыту выполнения аналогичных программ либо результатам тестового выполнения программы, или программой-компилятором по заложенным в ней алгоритмам. Методы динамического прогнозирования учитывают направления переходов, реализовывавшиеся этой командой при выполнении программы. Например, подсчитывается количество переходов, выполненных ранее по тому или иному направлению, и на основании этого определяется направление перехода при следующем выполнении данной команды. В современных микропроцессорах вероятность правильного предсказания направления переходов достигает 90-95 %.
Конфликты по данным возникают в случаях, когда выполнение одной команды зависит от результата выполнения предыдущей команды. Устранение конфликтов по данным типов WAR и WAW достигается путем отказа от неупорядоченного исполнения команд, но чаще всего путем введения буфера восстановления последовательности команд.
Недостаточное дублирование некоторых ресурсов
Одним из типичных примеров служит конфликт из-за доступа к запоминающим устройствам. Борьба с конфликтами такого рода проводится путем увеличения количества однотипных функциональных устройств, которые могут одновременно выполнять одни и те же или схожие функции. Например, в современных микропроцессорах обычно разделяют кэш-память для хранения команд и кэш-память данных, а также используют много портовую схему доступа к регистровой памяти, при которой к регистрам можно одновременно обращаться по одному каналу для записи, а по другому - для считывания информации. Конфликты из-за исполнительных устройств обычно сглаживаются введением в состав микропроцессора дополнительных блоков. Так, в микропроцессоре Pentium-4 предусмотрено 4 АЛУ для обработки целочисленных данных. Процессоры, имеющие в своем составе более одного конвейера, называются суперскалярными.
Суперскалярные архитектуры
Смысл суперскалярной обработки - наличие в аппаратуре средств, позволяющих одновременно выполнять две и более скалярных операций, т. е. команд обработки пары чисел. В самом деле, суть этого метода довольно проста: имеется в виду дублирование устройств процессора. Так например, Pentium имеет два конвейера выполнения команд (Рис. 11.4). При этом существуют различные способы реализации суперскалярной обработки. Первый способ чаще всего применяется в RISC-процессорах и заключается в чисто аппаратном механизме выборки из буфера инструкций (или кэша команд) несвязанных команд и параллельном запуске их на исполнение. Обычно процессор выполняет две несвязанные команды одновременно, как например, в процессорах DEC серии Alpha. Этот метод хорош тем, что он "прозрачен" для программиста - составление программ для подобных процессоров не требует никаких специальных усилий, ответственность за параллельное выполнение операций возлагается в основном на аппаратные средства.
Второй способ реализации суперскалярной обработки заключается в кардинальной перестройке всего процесса трансляции и исполнения программ. Уже на этапе подготовки программы компилятор группирует не связанные операции в пакеты, содержимое которых строго соответствует структуре процессора. Например, если процессор содержит функционально независимые устройства сложения, умножения, сдвига и деления, то максимум, что компилятор может "уложить" в один пакет - это четыре разнотипные операции: сложение, умножение, сдвиг и деление. Сформированные пакеты операций преобразуются компилятором в командные слова.
Функции стадии С1 (выборка команд а также тезис - один конвейер хорошо, а два лучше) позволяют реализовать структуру с двойным конвейером.
Можно и дальше наращивать число конвейеров, но это значительно осложнило бы аппаратную часть. Вместо этого было предложено использовать один конвейер с большим количеством функциональных блоков (Pentium II - суперскалярный процессор).
До сих пор мы с вами рассматривали возможности увеличения производительности вычислительной системы на основе параллелизма на уровне команд. При этом к системе предъявлялись следующие требования:
Все обычные команды непосредственно выполняются аппаратным обеспечением, они не интерпретируются микрокомандами, устранение уровня интерпретации обеспечивает высокую скорость выполнения большинства команд;
Компьютер должен приступать к одновременному выполнению большого числа команд (при этом не имеет значения сколько времени занимает само выполнение этих команд);
Команды должны легко декодироваться (количество вызываемых команд в секунду зависит от процесса декодирования), для этого, например, используются регулярные команды с фиксированной длиной и небольшим количеством полей;
К памяти должны обращаться только команды загрузки и сохранения (операнды для большинства команд берутся из регистров и возвращаются туда же), понятно, что это требование выдвигает необходимость иметь большое количество регистров.
Недостатком суперскалярных микропроцессоров является необходимость синхронного продвижения команд в каждом из конвейеров. К тому же, как мы уже отмечали, кроме параллелизма на уровне команд существует параллелизм на уровне данных, реализация этого вида параллелизма требует применения многопроцессорной архитектуры.
Мультипроцессорные системы на кристалле
Анонсированная в 2002 году компанией Intel технология Hyper-Threading -- пример многопоточной обработки команд. Данная технология является чем-то средним между многопоточной обработкой, реализованной в мультипроцессорных системах, и параллелизмом на уровне инструкций, реализованном в однопроцессорных системах. Фактически технология Hyper-Threading позволяет организовать два логических процессора в одном физическом. Таким образом, с точки зрения операционной системы и запущенного приложения в системе существует два процессора, что дает возможность распределять загрузку задач между ними точно так же, как при SMP-мультипроцессорной конфигурации.
Технология Hyper-Threading
Посредством реализованного в технологии Hyper-Threading принципа параллельности можно обрабатывать инструкции в параллельном (а не в последовательном) режиме, то есть для обработки все инструкции разделяются на два параллельных потока. Это позволяет одновременно обрабатывать два различных приложения или два различных потока одного приложения и тем самым увеличить IPC процессора, что сказывается на росте его производительности.
В конструктивном плане процессор с поддержкой технологии Hyper-Threading состоит из двух логических процессоров, каждый из которых имеет свои регистры и контроллер прерываний (Architecture State, AS), а значит, две параллельно исполняемые задачи работают со своими собственными независимыми регистрами и прерываниями, но при этом используют одни и те же ресурсы процессора для выполнения своих задач. После активации каждый из логических процессоров может самостоятельно и независимо от другого процессора выполнять свою задачу, обрабатывать прерывания либо блокироваться. Таким образом, от реальной двухпроцессорной конфигурации новая технология отличается только тем, что оба логических процессора используют одни и те же исполняющие ресурсы, одну и ту же разделяемую между двумя потоками кэш-память и одну и ту же системную шину. Использование двух логических процессоров позволяет усилить процесс параллелизма на уровне потока, реализованный в современных операционных системах и высокоэффективных приложениях. Команды от обоих исполняемых параллельно потоков одновременно посылаются ядру процессора для обработки. Используя технологию out-of-order (исполнение командных инструкций не в порядке их поступления), ядро процессора тоже способно параллельно обрабатывать оба потока за счет использования нескольких исполнительных модулей.
Идея технологии Hyper-Threading тесно связана с микроархитектурой NetBurst процессора Pentium 4 и является в каком-то смысле ее логическим продолжением. Микроархитектура Intel NetBurst позволяет получить максимальный выигрыш в производительности при выполнении одиночного потока инструкций, то есть при выполнении одной задачи. Однако даже в случае специальной оптимизации программы не все исполнительные модули процессора оказываются задействованными на протяжении каждого тактового цикла. В среднем при выполнении кода, типичного для набора команд IA-32, реально используется только 35% исполнительных ресурсов процессора, а 65% исполнительных ресурсов процессора простаивают, что означает неэффективное использование возможностей процессора. Было бы вполне логично организовать работу процессора таким образом, чтобы в каждом тактовом цикле максимально использовать его возможности. Именно эту идею и реализует технология Hyper-Threading, подключая незадействованные ресурсы процессора к выполнению параллельной задачи.
Поясним все вышесказанное на примере. Представьте себе гипотетический процессор, в котором имеются четыре исполнительных блока: два блока для работы с целыми числами (арифметико-логическое устройство, ALU), блок для работы с числами с плавающей точкой (FPU) и блок для записи и чтения данных из памяти (Store/Load, S/L). Пусть, кроме того, каждая операция осуществляется за один такт процессора. Далее предположим, что выполняется программа, состоящая из трех инструкций: первые две -- арифметические действия с целыми числами, а последняя -- сохранение результата. В этом случае вся программа будет выполнена за два такта процессора: в первом такте задействуются два блока ALU процессора (красный квадрат на рис. 11.6), во втором -- блок записи и чтения данных из памяти S/L.
Рис. 12.6 Реализация параллелизма на уровне инструкций (Instruction Level Parallelism, ILP)
В современных приложениях в любой момент времени, как правило, выполняется не одна, а несколько задач или несколько потоков (threads) одной задачи, называемых также нитями. Давайте посмотрим, как будет вести себя наш гипотетический процессор при выполнении двух разных потоков задач (рис. 11.7). Красные квадраты соответствуют использованию исполнительных блоков процессора одного потока, а синие квадраты -- другого. Если бы оба потока исполнялись изолированно, то для выполнения первого и второго потоков потребовалось бы по пять тактов процессора. При одновременном исполнении обоих потоков процессор будет постоянно переключаться между обоими потоками, следовательно, за один такт процессора выполняются только инструкции какого-либо одного из потоков. Для исполнения обоих потоков потребуется в общей сложности десять процессорных тактов.
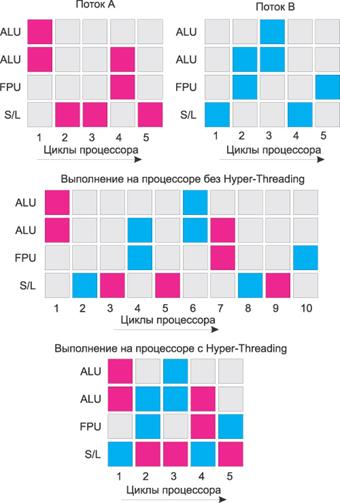
Рис. 12.7 Выполнение двух потоков на процессоре без реализации и с реализацией технологии Hyper-Threading
Теперь давайте подумаем над тем, как можно повысить скорость выполнения задачи в рассмотренном примере. Как видно из рис. 12.7, на каждом такте процессора используются далеко не все исполнительные блоки процессора, поэтому имеется возможность частично совместить выполнение инструкций отдельных потоков на каждом такте процессора. В нашем примере выполнение двух арифметических операций с целыми числами первого потока можно совместить с загрузкой данных из памяти второго потока и выполнить все три операции за один такт процессора. Аналогично на втором такте процессора можно совместить операцию сохранения результатов первого потока с двумя операциями второго потока и т. д. Собственно, в таком параллельном выполнении двух потоков и заключается основная идея технологии Hyper-Threading.
Конечно, описанная ситуация является идеализированной, и на практике выигрыш от использования технологии Hyper-Threading куда более скромен. Дело в том, что возможность одновременного выполнения на одном такте процессора инструкций от разных потоков ограничивается тем, что эти инструкции могут задействовать одни и те же исполнительные блоки процессора.
Рассмотрим еще один типичный пример работы нашего гипотетического процессора. Пусть имеется два потока команд, каждый из которых по отдельности выполняется за пять тактов процессора. Без использования технологии Hyper-Threading для выполнения обоих потоков потребовалось бы десять тактов процессора. А теперь выясним, что произойдет при использовании технологии Hyper-Threading (рис. 11.8). На первом такте процессора каждый из потоков задействует различные блоки процессора, поэтому выполнение инструкций легко совместить. Аналогичное положение вещей наличествует и на втором такте, а вот на третьем такте инструкции обоих потоков пытаются задействовать один и тот же исполнительный блок процессора, а именно блок S/L. В результате возникает конфликтная ситуация, и один из потоков должен ждать освобождения требуемого ресурса процессора. То же самое происходит и на пятом такте. В итоге оба потока выполняются не за пять тактов (как в идеале), а за семь.

Рис. 11.8 Возникновение конфликтных ситуаций при использовании технологии Hyper-Threading
Многоядерность -- следующий этап развития
Избежать конфликтных ситуаций, возникающих при использовании технологии Hyper-Threading, можно в том случае, если изолировать в пределах одного процессора выполнение различных потоков инструкций. Фактически для этого потребуется использовать не одно, а два и более ядер процессора. Тогда в идеальном варианте каждый поток инструкций утилизирует отведенное ему ядро процессора (и исполнительные блоки), что позволяет избежать конфликтных ситуаций и увеличить производительность процессора за счет параллельного выполнения потоков инструкций.
В рассмотренном примере возникновения конфликтных ситуаций при использовании технологии Hyper-Threading применение двух независимых ядер для выполнения двух потоков инструкций позволило бы выполнить весь программный код не за семь (как в случае процессора с технологией Hyper-Threading), а за пять тактов (рис. 11.9).
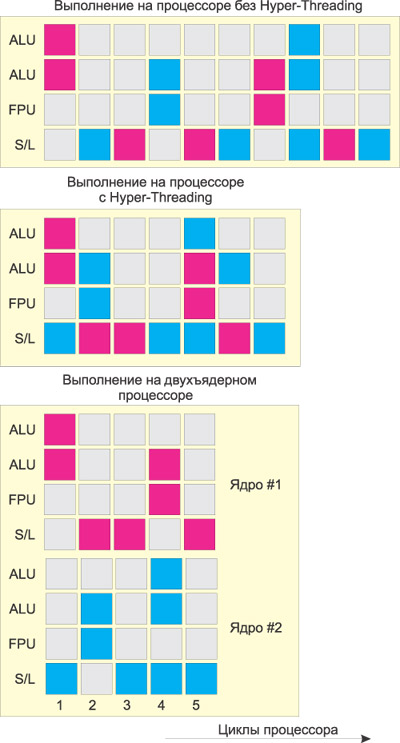
Рис. 12.9 Преимущество двухъядерной архитектуры процессора
Конечно, говорить о том, что двухъядерные процессоры в два раза производительнее одноядерных, не приходится. Причина заключается в том, что для реализации параллельного выполнения двух потоков необходимо, чтобы эти потоки были полностью или частично независимы друг от друга, а кроме того, чтобы операционная система и само приложение поддерживали на программном уровне возможность распараллеливания задач. И в связи с этим стоит подчеркнуть, что сегодня далеко не все приложения удовлетворяют этим требованиям и потому не смогут получить выигрыша от использования двухъядерных процессоров. Должно пройти еще немало времени, чтобы написание параллельного кода приложений вошло в привычку у программистов, однако первый и самый важный камень в фундамент параллельных вычислений уже заложен. Впрочем, уже сегодня существует немало приложений, которые оптимизированы для выполнения в многопроцессорной среде, и такие приложения, несомненно, позволят использовать преимущества двухъядерного процессора.
Выводы
Основным способом повышения производительности ВС является параллельное выполнение, как большого числа команд, так и многочисленного потока данных
Параллелизм вычислительного процесса базируется на независимости потока команд - верхний уровень и не связанности данных в потоке - нижний уровень.
Параллелизм на нижнем уровне реализуется однопроцессорными архитектурами с применением технологий упреждающей выборки, конвейерной обработки и суперскалярной архитектуры.
Параллелизм на верхнем уровне, уровне процессоров реализуется с помощью многопроцессорных и многомашинных архитектур.
Вопросы и задания
- 1. В некотором задании каждый последующий шаг зависит от предыдущего. Что в этом случае более уместно: векторный процессор или конвейер? 2 . Что такое суперскалярный процессор? Приведите пример. 3. Как зависит эффективность конвейерной обработки от степени загруженности конвейера?
Лекция 13. Архитектура многопроцессорных ВС
Введение
Одной из отличительных особенностей многопроцессорной вычислительной системы является сеть обмена, с помощью которой процессоры соединяются друг с другом и/или с памятью. Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти. К первой группе относятся машины с общей (разделяемой) основной памятью, объединяющие до нескольких десятков (обычно менее 32) процессоров. В многопроцессорной системе с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти.
SMP архитектура
SMP архитектура (symmetric multiprocessing) - cимметричная многопроцессорная архитектура. Главной особенностью систем с архитектурой SMP является наличие общей физической памяти, разделяемой всеми процессорами.
Сравнительно небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью одной шины. Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным. Структура подобной системы представлена на рис. 11.1.
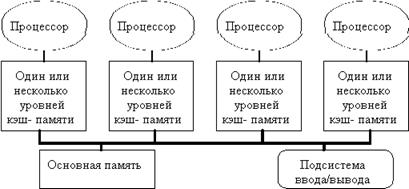
Рис. 13.1 Многопроцессорная система с общей памятью.
Память является способом передачи сообщений между процессорами, при этом все вычислительные устройства при обращении к ней имеют равные права и одну и ту же адресацию для всех ячеек памяти. Поэтому SMP архитектура называется симметричной. Последнее обстоятельство позволяет очень эффективно обмениваться данными с другими вычислительными устройствами. SMP-система строится на основе высокоскоростной системной шины (SGI PowerPath, Sun Gigaplane, DEC TurboLaser), к слотам которой подключаются функциональные блоки трех типов: процессоры (ЦП), операционная система (ОП) и подсистема ввода/вывода (I/O). Для подсоединения к модулям I/O используются уже более медленные шины (PCI, VME64). Наиболее известными SMP-системами являются SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.) Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы по процессорам. Основные преимущества SMP-систем:
- * простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель программирования, используемую при создании приложения: обычно используется модель параллельных ветвей, когда все процессоры работают абсолютно независимо друг от друга - однако, можно реализовать и модели, использующие межпроцессорный обмен. Использование общей памяти увеличивает скорость такого обмена, пользователь также имеет доступ сразу ко всему объему памяти. Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания; * легкость в эксплуатации. Как правило, SMP-системы используют систему охлаждения, основанную на воздушном кондиционировании, что облегчает их техническое обслуживание; * относительно невысокая цена.
Недостатки:
* системы с общей памятью, построенные на системной шине, плохо масштабируемы. Этот важный недостаток SMP-системы не позволяет считать их по-настоящему перспективными. Причины плохой масштабируемости состоят в том, что в данный момент шина способна обрабатывать только одну транзакцию, вследствие чего возникают проблемы разрешения конфликтов при одновременном обращении нескольких процессоров к одним и тем же областям общей физической памяти. Вычислительные элементы начинают друг другу мешать. Когда произойдет такой конфликт, зависит от скорости связи и от количества вычислительных элементов. В настоящее время конфликты могут происходить при наличии 8-24-х процессоров. Кроме того, системная шина имеет ограниченную (хоть и высокую) пропускную способность (ПС) и ограниченное число слотов. Все это с очевидностью препятствует увеличению производительности при увеличении числа процессоров и числа подключаемых пользователей. В реальных системах можно использовать не более 32 процессоров. Для построения масштабируемых систем на базе SMP используются кластерные или NUMA-архитектуры. При работе с SMP системами используют так называемую парадигму программирования с разделяемой памятью (shared memory paradigm).
MPP архитектура
MPP архитектура (massive parallel processing) - массивно-параллельная архитектура. Главная особенность такой архитектуры состоит в том, что память физически разделена. В этом случае система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти (ОП), два коммуникационных процессора (рутера) или сетевой адаптер, иногда - жесткие диски и/или другие устройства ввода/вывода. Один рутер используется для передачи команд, другой - для передачи данных. По сути, такие модули представляют собой полнофункциональные компьютеры (см. рис.). Доступ к банку ОП из данного модуля имеют только процессоры (ЦП) из этого же модуля. Модули соединяются специальными коммуникационными каналами. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами. Используются два варианта работы операционной системы (ОС) на машинах MPP архитектуры. В одном полноценная операционная система (ОС) работает только на управляющей машине (front-end), на каждом отдельном модуле работает сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения. Во втором варианте на каждом модуле работает полноценная UNIX-подобная ОС, устанавливаемая отдельно на каждом модуле.
На рис. 12.2 показана структура такой системы.
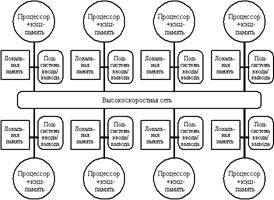
Рис. 13.2 Многопроцессорная система с распределенной памятью
С ростом числа процессоров просто невозможно обойти необходимость реализации модели распределенной памяти с высокоскоростной сетью для связи процессоров. С быстрым ростом производительности процессоров и связанным с этим ужесточением требования увеличения полосы пропускания памяти, масштаб систем (т. е. число процессоров в системе, для которых требуется организация распределенной памяти), уменьшается, также как и уменьшается число процессоров, которые удается поддерживать на одной разделяемой шине и общей памяти. Главным преимуществом систем с раздельной памятью является хорошая масштабируемость: в отличие от SMP-систем в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодняшний день устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров (ASCI Red, ASCI Blue Pacific).
Недостатки:
- * отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами. Требуется специальная техника программирования для реализации обмена сообщениями между процессорами; * каждый процессор может использовать только ограниченный объем локального банка памяти; * вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально использовать системные ресурсы. Именно этим определяется высокая цена программного обеспечения для массивно-параллельных систем с раздельной памятью.
Системами с раздельной памятью являются суперкомпьютеры МВС-1000, IBM RS/6000 SP, SGI/CRAY T3E, системы ASCI, Hitachi SR8000, системы Parsytec. Машины последней серии CRAY T3E от SGI, основанные на базе процессоров Dec Alpha 21164 с пиковой производительностью 1200 Мфлопс/с (CRAY T3E-1200), способны масштабироваться до 2048 процессоров. При работе с MPP системами используют так называемую Massive Passing Programming Paradigm - парадигму программирования с передачей данных (MPI, PVM, BSPlib).
Гибридная архитектура (NUMA)
Сегодня стало уже общепринятым, что в многопроцессорных системах с общим полем памяти для достижения наилучшего масштабирования необходимо отказаться от классической архитектуры SMP (узким местом которой является общая шина или коммутатор) в пользу ccNUMA. В последнем случае многопроцессорные системы строятся на базе SMP-узлов, содержащих процессоры и оперативную память, а узлы связываются между собой посредством общесистемного межсоединения, в роли которого обычно выступает коммутатор. Поэтому доступ процессоров к локальной оперативной памяти своего узла осуществляется быстрее, чем к оперативной памяти другого узла; таким образом, доступ оказывается "неоднородным", о чем и говорит сокращение NUMA (Non-Unifrom Memory Access), а сс означает coherent cash ("когерентный кэш"). Замедление доступа к удаленной оперативной памяти -- это плата за масштабируемость, и разработчики стремятся по возможности нивелировать различия в скорости доступа к локальной и удаленной памяти.
Главная особенность такой архитектуры - неоднородный доступ к памяти. Гибридная архитектура воплощает в себе удобства систем с общей памятью и относительную дешевизну систем с раздельной памятью. Суть этой архитектуры - в особой организации памяти, а именно: память является физически распределенной по различным частям системы, но логически разделяемой, так что пользователь видит единое адресное пространство. Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т. е. к памяти других модулей. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной. По существу архитектура NUMA является MPP (массивно-параллельная архитектура) архитектурой, где в качестве отдельных вычислительных элементов берутся SMP (cимметричная многопроцессорная архитектура) узлы.
Структурная схема компьютера с гибридной сетью: четыре процессора связываются между собой при помощи кроссбара в рамках одного SMP узла. Узлы связаны сетью типа "бабочка" (Butterfly):
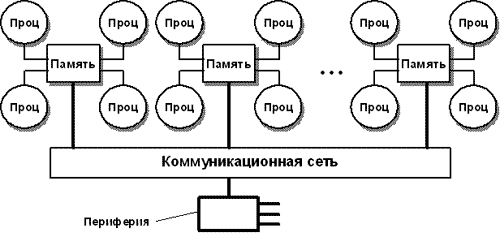
Рис. 13.4 Гибридная архитектура
Впервые идею гибридной архитектуры предложил Стив Воллох и воплотил в системах серии Exemplar. Вариант Воллоха - система, состоящая из 8-ми SMP узлов. Фирма HP купила идею и реализовала на суперкомпьютерах серии SPP. Идею подхватил Сеймур Крей (Seymour R. Cray) и добавил новый элемент - когерентный кэш, создав так называемую архитектуру cc-NUMA (Cache Coherent Non-Uniform Memory Access), которая расшифровывается как "неоднородный доступ к памяти с обеспечением когерентности кэшей". Он ее реализовал на системах типа Origin.
Организация когерентности многоуровневой иерархической памяти.
Понятие когерентности кэшей описывает тот факт, что все центральные процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Действительно, поскольку кэш-память принадлежит отдельному компьютеру, а не всей многопроцессорной системе в целом, данные, попадающие в кэш одного компьютера, могут быть недоступны другому. Чтобы избежать этого, следует провести синхронизацию информации, хранящейся в кэш-памяти процессоров. Для обеспечения подобной когерентности кэшей существуют несколько возможностей:
- * использовать механизм отслеживания шинных запросов (snoopy bus protocol), в котором кэши отслеживают переменные, передаваемые к любому из центральных процессоров и, при необходимости, модифицируют копии; * выделять специальную часть памяти, отвечающую за отслеживание достоверности всех используемых копий переменных.
Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях, SGI Origin3000, Sun HPC 15000, IBM/Sequent NUMA-Q 2000. На настоящий момент максимальное число процессоров в cc-NUMA-системах может превышать 1000. Обычно вся система работает под управлением единой ОС, как в SMP. Возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС. При работе NUMA-системами, также как с SMP, используют так называемую парадигму программирования с общей памятью (shared memory paradigm).
PVP архитектура
PVP (Parallel Vector Process) - параллельная архитектура с векторными процессорами. Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гб/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дороги, эти машины не будут являться общедоступными.
Кластерная архитектура
Кластер представляет собой два или больше компьютеров (часто называемых узлами), объединяемых при помощи сетевых технологий на базе шинной архитектуры или коммутатора и предстающих перед пользователями в качестве единого информационно-вычислительного ресурса. В качестве узлов кластера могут быть выбраны серверы, рабочие станции и даже обычные персональные компьютеры. Преимущество кластеризации для повышения работоспособности становится очевидным в случае сбоя какого-либо узла: при этом другой узел кластера может взять на себя нагрузку неисправного узла, и пользователи не заметят прерывания в доступе. Возможности масштабируемости кластеров позволяют многократно увеличивать производительность приложений для большего числа пользователей. технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. Такие суперкомпьютерные системы являются самыми дешевыми, поскольку собираются на базе стандартных комплектующих элементов ("off the shelf"), процессоров, коммутаторов, дисков и внешних устройств. Кластеризация может быть осуществлена на разных уровнях компьютерной системы, включая аппаратное обеспечение, операционные системы, программы-утилиты, системы управления и приложения. Чем больше уровней системы объединены кластерной технологией, тем выше надежность, масштабируемость и управляемость кластера.
Проблемы выполнения сети связи процессоров в кластерной системе.
Архитектура кластерной системы (способ соединения процессоров друг с другом) в большей степени определяет ее производительность, чем тип используемых в ней процессоров. Критическим параметром, влияющим на величину производительности такой системы, является расстояние между процессорами. Так, соединив вместе 10 персональных компьютеров, мы получим систему для проведения высокопроизводительных вычислений, проблема, однако, будет состоять в нахождении наиболее эффективного способа соединения стандартных средств друг с другом, поскольку при увеличении производительности каждого процессора в 10 раз производительность системы в целом в 10 раз не увеличится.
Рассмотрим для примера задачу построения симметричной 16-ти процессорной системы, в которой все процессоры были бы равноправны. Наиболее естественным представляется соединение в виде плоской решетки, где внешние концы используются для подсоединения внешних устройств.
Схема соединения процессоров в виде плоской решетки
При таком типе соединения максимальное расстояние между процессорами окажется равным 6 (количество связей между процессорами, отделяющих самый ближний процессор от самого дальнего). Теория же показывает, что если в системе максимальное расстояние между процессорами больше 4, то такая система не может работать эффективно. Поэтому, при соединении 16 процессоров друг с другом плоская схема является не эффективной. Для получения более компактной конфигурации необходимо решить задачу о нахождении фигуры, имеющей максимальный объем при минимальной площади поверхности. В трехмерном пространстве таким свойством обладает шар. Но поскольку нам необходимо построить узловую систему, то вместо шара приходится использовать куб (если число процессоров равно 8) или гиперкуб, если число процессоров больше 8. Размерность гиперкуба будет определяться в зависимости от числа процессоров, которые необходимо соединить. Так, для соединения 16 процессоров потребуется 4-х мерный гиперкуб. Для его построения следует взять обычный 3-х мерный куб, сдвинуть в еще одном направлении и, соединив вершины, получить гиперкуб размером 4.
Примеры гиперкубов
Архитектура гиперкуба является второй по эффективности, но самой наглядной. Используются и другие топологии сетей связи: трехмерный тор, "кольцо", "звезда" и другие.
Архитектура кольца с полной связью по хордам (Chordal Ring)
Наиболее эффективной является архитектура с топологией "толстого дерева" (fat-tree). Архитектура "fat-tree" (hypertree) предложена Лейзерсоном (Charles E. Leiserson) в 1985 году. Процессоры локализованы в листьях дерева, в то время как внутренние узлы дерева скомпонованы во внутреннюю сеть. Поддеревья могут общаться между собой, не затрагивая более высоких уровней сети.
Кластерная архитектура "Fat-tree"
Кластерная архитектура "Fat-tree" (вид сверху на предыдущую схему)
Поскольку способ соединения процессоров друг с другом больше влияет на производительность кластера, чем тип используемых в ней процессоров, то может оказаться более рентабельным создать систему из большего числа дешевых компьютеров, чем из меньшего числа дорогих. В кластерах, как правило, используются операционные системы, стандартные для рабочих станций, чаще всего, свободно распространяемые - Linux, FreeBSD, вместе со специальными средствами поддержки параллельного программирования и балансировки нагрузки. При работе с кластерами, также как и с MPP системами, используют так называемую Massive Passing Programming Paradigm - парадигму программирования с передачей данных (чаще всего - MPI). Дешевизна подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач.
Выводы
Классификация Флинна позволяет распределить параллельные вычисления по уровням архитектуры вычислительных систем.
Сравнивая между собой ММВС и МПВС, можно отметить, что в МПВС достигается более высокая скорость обмена информацией между элементами системы и поэтому более высокая производительность, более высокая живучесть и надежность.
ММВС на стандартных ОС значительно проще и дешевле.
Вопросы и задания
Привести примеры практической реализации архитектуры SISD, SIMD, MISD и MIMD.
Какая архитектура более пригодна для обработки мультимедийных задач?
Что из себя представляет архитектура MSIMD?
Лекция 14. Кластерные системы
В общих чертах мы уже познакомились с многопроцессорными и многомашинными вычислительными системами. Однако с некоторыми конкретными и, в тоже время. Практическими системами необходимо познакомиться более близко. К таким системам относятся кластерные системы.
Концепция кластерных систем
Впервые в классификации вычислительных систем термин "кластер" определила компания Digital Equipment Corporation (DEC). По определению DEC, кластер - это группа вычислительных машин, которые связаны между собою и функционируют как один узел обработки информации.
Кластер функционирует как единая система, то есть для пользователя или прикладной задачи вся совокупность вычислительной техники выглядит как один компьютер. Именно это и является самым важным при построении кластерной системы.
Первые кластеры компании Digital были построены на машинах VAX. Эти машины уже не производятся, но все еще работают на площадках, где были установлены много лет назад. И наверное самое важное то, что общие принципы, заложенные при их проектировании, остаются основой при построении кластерных систем и сегодня. К общим требованиям, предъявляемым к кластерным системам, относятся:
Высокая готовность
Высокое быстродействие
Масштабирование
Общий доступ к ресурсам
Удобство обслуживания
Естественно, что при частных реализациях одни из требований ставятся во главу угла, а другие отходят на второй план. Так, например, при реализации кластера, для которого самым важным является быстродействие, для экономии ресурсов меньше внимания придают высокой готовности. В общем случае кластер функционирует как мультипроцессорная система, поэтому, важно понимать классификацию таких систем в рамках распределения программно-аппаратных ресурсов.
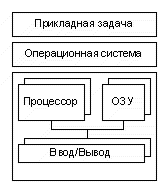
Рис.14.3 Умеренно связанная мультипроцессорная система
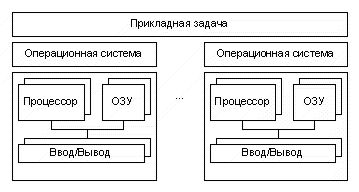
Рис.14.4 Слабо связанная мультипроцессорная система
Обычно на PC платформах, с которыми нам приходится работать, используются реализации кластерной системы в моделях тесно связанной и умеренно связанной мультипроцессорных архитектур.
Разделение на High Availability и High Performance системы
В функциональной классификации кластеры можно разделить на "Высокоскоростные" (High Performance, HP), "Системы Высокой Готовности" (High Availability, HA), а также "Смешанные Системы". Высокоскоростные кластеры используются для задач, которые требуют значительной вычислительной мощности. Классическими областями, в которых используются подобные системы, являются:
Обработка изображений: рендеринг, распознавание образов
Научные исследования: физика, биоинформатика, биохимия, биофизика
Промышленность (геоинформационные задачи, математическое моделирование)
И много других...
Кластеры, которые относятся к системам высокой готовности, используются везде, где стоимость возможного простоя превышает стоимость затрат, необходимых для построения кластерной системы, например:
Биллинговые системы
Банковские операции
Электронная коммерция
Управление предприятием, и т. п....
Смешанные системы объединяют в себе особенности как первых, так и вторых. Позиционируя их, следует отметить, что кластер, который обладает параметрами как High Performance, так и High Availability, обязательно проиграет в быстродействии системе, ориентированной на высокоскоростные вычисления, и в возможном времени простоя системе, ориентированной на работу в режиме высокой готовности.
Проблематика High Performance кластеров
Почти в любой ориентированной на параллельное вычисление задаче невозможно избегнуть необходимости передавать данные от одной подзадачи другой. Таким образом, быстродействие High Performance кластерной системы определяется быстродействием узлов и связей между ними. Причем влияние скоростных параметров этих связей на общую производительность системы зависит от характера выполняемой задачи. Если задача требует частого обмена данными с подзадачами, тогда быстродействию коммуникационного интерфейса следует уделять максимум внимания. Естественно, чем меньше взаимодействуют части параллельной задачи между собою, тем меньше времени потребуется для ее выполнения. Что диктует определенные требования также и на программирование параллельных задач.
Основные проблемы при необходимости обмена данными между подзадачами возникают в связи с тем, что быстродействие передачи данных между центральным процессором и оперативной памятью узла значительно превышает скоростные характеристики систем межкомпьютерного взаимодействия. Кроме того, сильно сказывается на изменении функционирования системы, по сравнению с привычными нам SMP системами, разница в быстродействии кэш памяти процессоров и межузловых коммуникаций.
Быстродействие интерфейсов характеризуется двумя параметрами: пропускной способностью непрерывного потока даных и максимальным количеством самых маленьких пакетов, которые можно передать за единицу времени. Варианты реализаций коммуникационных интерфейсов мы рассмотрим в разделе "Средства реализации High Performance кластеров".
Проблематика High Availability кластерных систем
Сегодня в мире распространены несколько типов систем высокой готовности. Среди них кластерная система является воплощением технологий, которые обеспечивают высокий уровень отказоустойчивости при самой низкой стоимости. Отказоустойчивость кластера обеспечивается дублированием всех жизненно важных компонент. Максимально отказоустойчивая система должна не иметь ни единой точки, то есть активного элемента, отказ которого может привести к потере функциональности системы. Такую характеристику как правило называют - NSPF (No Single Point of Failure, - англ., отсутствие единой точки отказа).
При построении систем высокой готовности, главная цель - обеспечить минимальное время простоя. Для того, чтобы система обладала высокими показатели готовности, необходимо:
Чтобы ее компоненты были максимально надежными;
Чтобы она была отказоустойчивая, желательно, чтобы не имела точек отказов;
А также важно, чтобы она была удобна в обслуживании и разрешала проводить замену компонент без останова.
Пренебрежение любым из указанных параметров, может привести к потере функциональности системы. Давайте коротко пройдемся по всем трем пунктам. Что касается обеспечения максимальной надежности, то она осуществляется путем использования электронных компонент высокой и сверхвысокой интеграции, поддержания нормальных режимов работы, в том числе тепловых.
Отказоустойчивость обеспечивается путем использования специализированных компонент (ECC, Chip Kill модули памяти, отказоустойчивые блоки питания, и т. п.), а также с помощью технологий кластеризации. Благодаря кластеризации достигается такая схема функционирования, когда при отказе одного из компьютеров задачи перераспределяются между другими узлами кластера, которые функционируют исправно. Причем одной из важнейших задач производителей кластерного программного обеспечения является обеспечение минимального времени восстановления системы в случае сбоя, так как отказоустойчивость системы нужна именно для минимизации так называемого внепланового простоя.
Много кто забывает, что удобство в обслуживании, которое служит уменьшению плановых простоев (например, замены вышедшего из строя оборудования) является одним из важнейших параметров систем высокой готовности. И если система не разрешает заменять компоненты без выключения всего комплекса, то ее коэффициент готовности уменьшается.
Смешанные архитектуры
Сегодня часто можно встретить смешанные кластерные архитектуры, которые одновременно являются как системами высокой готовности, так и высокоскоростными кластерными архитектурами, в которых прикладные задачи распределяются по узлам системы. Наличие отказоустойчивого комплекса, увеличение быстродействия которого осуществляется путем добавления нового узла, считается самым оптимальным решением при построении вычислительной системы. Но сама схема построения таких смешанных кластерных архитектур приводит к необходимости объединения большого количества дорогих компонент для обеспечения высокого быстродействия и резервирования одновременно. И так как в High Performance кластерной системе наиболее дорогим компонентом является система высокоскоростных коммуникаций, ее дублирование приведет к значительным финансовым затратам. Следует отметить, что системы высокой готовности часто используются для OLTP задач, которые оптимально функционируют на симметричных мультипроцессорных системах. Реализации таких кластерных систем часто ограничиваются 2-х узловыми вариантами, ориентированными в первую очередь на обеспечение высокой готовности. Но в последнее время использование недорогих систем количеством более двух в качестве компонент для построения смешанных HA/HP кластерных систем становится популярным решением.
В настоящее время широкое распространение получила также технология параллельных баз данных. Эта технология позволяет множеству процессоров разделять доступ к единственной базе данных. Распределение заданий по множеству процессорных ресурсов и параллельное их выполнение позволяет достичь более высокого уровня пропускной способности транзакций, поддерживать большее число одновременно работающих пользователей и ускорить выполнение сложных запросов. Существуют три различных типа архитектуры, которые поддерживают параллельные базы данных:
Симметричная многопроцессорная архитектура с общей памятью (Shared Memory SMP Architecture). Эта архитектура поддерживает единую базу данных, работающую на многопроцессорном сервере под управлением одной операционной системы. Увеличение производительности таких систем обеспечивается наращиванием числа процессоров, устройств оперативной и внешней памяти.
Архитектура с общими (разделяемыми) дисками (Shared Disk Architecture). Это типичный случай построения кластерной системы. Эта архитектура поддерживает единую базу данных при работе с несколькими компьютерами, объединенными в кластер (обычно такие компьютеры называются узлами кластера), каждый из которых работает под управлением своей копии операционной системы. В таких системах все узлы разделяют доступ к общим дискам, на которых собственно и располагается единая база данных. Производительность таких систем может увеличиваться как путем наращивания числа процессоров и объемов оперативной памяти в каждом узле кластера, так и посредством увеличения количества самих узлов.
Архитектура без разделения ресурсов (Shared Nothing Architecture). Как и в архитектуре с общими дисками, в этой архитектуре поддерживается единый образ базы данных при работе с несколькими компьютерами, работающими под управлением своих копий операционной системы. Однако в этой архитектуре каждый узел системы имеет собственную оперативную память и собственные диски, которые не разделяются между отдельными узлами системы. Практически в таких системах разделяется только общий коммуникационный канал между узлами системы. Производительность таких систем может увеличиваться путем добавления процессоров, объемов оперативной и внешней (дисковой) памяти в каждом узле, а также путем наращивания количества таких узлов.
Таким образом, среда для работы параллельной базы данных обладает двумя важными свойствами: высокой готовностью и высокой производительностью. В случае кластерной организации несколько компьютеров или узлов кластера работают с единой базой данных. В случае отказа одного из таких узлов, оставшиеся узлы могут взять на себя задания, выполнявшиеся на отказавшем узле, не останавливая общий процесс работы с базой данных. Поскольку логически в каждом узле системы имеется образ базы данных, доступ к базе данных будет обеспечиваться до тех пор, пока в системе имеется по крайней мере один исправный узел. Производительность системы легко масштабируется, т. е. добавление дополнительных процессоров, объемов оперативной и дисковой памяти, и новых узлов в системе может выполняться в любое время, когда это действительно требуется.
Параллельные базы данных находят широкое применение в системах обработки транзакций в режиме on-line, системах поддержки принятия решений и часто используются при работе с критически важными для работы предприятий и организаций приложениями, которые эксплуатируются по 24 часа в сутки.
Лекция 15. Многомашинные системы - вычислительные сети
Введение
Известно, что наибольшая эффективность и производительность компьютерной системы достигается при организации распределенной модели обработки информации.
Основным признаком распределенной вычислительной системы является наличие нескольких центров обработки данных, очевидно к распределенным системам относятся многомашинные вычислительные комплексы, мультипроцессорные системы и компьютерные сети. Мультипроцессорная система (мультипроцессор) представляет собой несколько процессоров, которые разделяют общую физическую память и работают под управлением единой ОС. Взаимодействие между процессорами организуется через единое виртуальное адресное пространство.
Многомашинная система (мультикомпьютер) - это вычислительный комплекс (ВК), включающий в себя несколько компьютеров (каждый из которых работает под управлением собственной ОС), а также программные и аппаратные средства связи компьютеров, которые обеспечивают передачу данных в транспортной системе ВК. Связь между компьютерами многомашинной системы менее тесная, чем между процессорами в мультипроцессоре.
Компьютерные сети, также могут быть отнесены к распределенным вычислительным системам, в которых программные и аппаратные связи являются еще более слабыми, а автономность процессов проявляется в наибольшей степени. Каждый компьютер (узел сети) работает под управлением собственной ОС, взаимодействие между компьютерами осуществляется за счет передачи сообщений через сетевые адаптеры (сетевые карты) и каналы связи, содержащие наряду с линиями связи коммутационное оборудование. С их помощью один компьютер обычно запрашивает доступ к ресурсам (аппаратным и программным) другого компьютера. Разделение локальных ресурсов каждого узла между всеми пользователями сети реализуется посредством сетевых технологий и является основной целью создания вычислительной сети.
Сетевая технология - это согласованный набор стандартных протоколов и реализующих их программно-аппаратных средств (например: сетевых карт, драйверов, кабелей и разъемов, коммуникационного оборудования и т. д.) достаточный для построения вычислительной сети.
Простейшие виды связи сети передачи данных
Разработка вычислительной сети, как и всякой сети передачи данных призвана решать множество самых разных задач как на физическом уровне (кодирование, синхронизация сигналов, конфигурация связей ...), так и на логическом уровне (адресация, коммутация, мультиплексирование, маршрутизация ...). Попытаемся вначале сформулировать эти задачи, а потом и решать их вместе с разработчиками сетевых технологий. Начнем с самого простого случая, на первый взгляд не относящегося к сети, непосредственного соединения двух устройств физическим каналом "точка-точка" (point-to-point).
Связь компьютера с периферийным устройством
Частным случаем связи "точка-точка" является соединение компьютера и периферийного устройства. Для обмена данными компьютер и периферийное устройство оснащены внешними интерфейсами или портами.
В данном случае к понятию интерфейс относятся:
Разъем;
Набор проводов;
Совокупность правил обмена данными по этим проводам.
Со стороны компьютера логикой передачи сигналов на внешний интерфейс управляют:
Контроллер ПУ - аппаратный блок, часто реализуемый в виде отдельной платы;
Драйвер ПУ - программа, управляющая контроллером периферийного устройства.
Со стороны ПУ интерфейс чаще всего реализуется аппаратным устройством управления ПУ, хотя встречаются и аппаратно-программные устройства.
Обмен данными между ПУ и компьютером является двунаправленным, таким образом по каналу связи передается следующая информация:
Данные с контроллера ПУ (например байты текста);
Команды управления;
Данные, возвращаемые устройством управления ПУ (например о готовности ПУ).
Рассмотрим последовательность действий, которые выполняются в том случае, когда некоторому приложению требуется напечатать текст на принтере. Со стороны компьютера в выполнении этой операции принимает участие, кроме уже названных контроллера, драйвера и приложения, еще один важнейший компонент -- операционная система. Поскольку все операции ввода-вывода являются привилегированными, все приложения при выполнении операций с периферийными устройствами используют ОС как арбитра. Итак, последовательность действий такова:
- 1. Приложение обращается с запросом на выполнение операции печати к операционной системе. В запросе указываются: адрес данных в оперативной памяти, идентифицирующая информация принтера и операция, которую требуется выполнить. 2. Получив запрос, операционная система анализирует его, решает, может ли он быть выполнен, и если решение положительное, то запускает соответствующий драйвер, передавая ему в качестве параметров адрес выводимых данных. Дальнейшие действия, относящиеся к операции ввода-вывода, со стороны компьютера реализуются совместно драйвером и контроллером принтера.
Драйвер по заданному адресу скачивает данные из ОП в свой буфер и затем передает команды и данные контроллеру, который помещает их в свой внутренний буфер. Контроллер перемещает данные из внутреннего буфера во внешний порт.
Контроллер начинает последовательно передавать биты в линию связи, представляя каждый бит соответствующим электрическим сигналом. Чтобы сообщить устройству управления принтера о том, что начинается передача байта, перед передачей первого бита данных контроллер формирует стартовый сигнал специфической формы, а после передачи последнего информационного бита -- столовый сигнал. Эти сигналы синхронизируют передачу байта. Кроме информационных бит, контроллер может передавать бит контроля четности для повышения достоверности обмена.
Устройство управления принтера, обнаружив на соответствующей линии стартовый бит, выполняет подготовительные действия и начинает принимать информационные биты, формируя из них байт в своем приемном буфере. Если передача сопровождается битом четности, то выполняется проверка корректности передачи: при правильно выполненной передаче в соответствующем регистре устройства управления принтера устанавливается признак завершения приема информации. Наконец, принятый байт обрабатывается принтером -- выполняется соответствующая команда или печатается символ. Обязанности между драйвером и контроллером могут распределяться по-разному, но чаще всего контроллер поддерживает набор простых команд, служащих для управления периферийным устройством, а на драйвер обычно возлагаются наиболее сложные функции реализации обмена. Например, контроллер принтера может поддерживать такие элементарные команды, как "Печать символа", "Перевод строки", "Возврат каретки" и т. п. Драйвер же принтера с помощью этих команд реализует печать строк символов, разделение документа на страницы и другие более высокоуровневые операции. Драйвер, задавая ту или иную последовательность команд, определяет тем самым логику работы периферийного устройства.
Связь двух компьютеров
А теперь предположим, что пользователь другого компьютера хотел бы распечатать текст. Сложность состоит в том, что к его компьютеру не подсоединен принтер, и требуется воспользоваться тем принтером, который связан с другим компьютером.
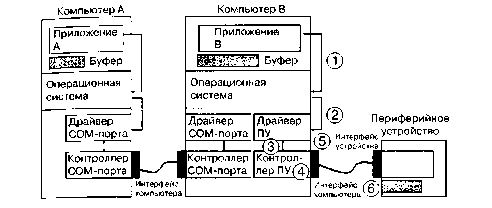
Рис. 15.2 Связь двух компьютеров
Программа, работающая на одном компьютере, не может получить непосредственный доступ к ресурсам другого компьютера -- его дискам, файлам, принтеру. Она может только "попросить" об этом другую программу, выполняемую на том компьютере, которому принадлежат эти ресурсы. Эти "просьбы" выражаются в виде сообщений, передаваемых по каналам связи между компьютерами. Такая организация печати называется удаленной.
Предположим, что мы связали компьютеры по кабелю через СОМ-порты, которые, как известно, реализуют интерфейс RS-232C (такое соединение часто называют нуль-модемным).
Полное название интерфейса RS-232 звучит так: "интерфейс между терминальным оборудованием и оборудованием передачи данных, обеспечивающий последовательную передачу данных", т. е. DTE-DCE. На текущий момент наиболее популярной версией интерфейса RS-232 является версия C, которая называется RS-232C. 25-ти контактный RS-232C обладает следующими недостатками: отсутствие функций по управлению потоком, ограничения по максимальной длине связи50 футов, ограничения связанные с заземлением. Новая версия RS-232E призвана вытеснить версии C и D.
Связь между компьютерами осуществляется аналогично связи компьютера с ПУ. Только теперь контроллеры и драйверы портов действуют с двух сторон. Вместе они обеспечивают передачу по кабелю между компьютерами одного байта информации. (В "настоящих" локальных сетях подобные функции передачи данных в линию связи выполняются сетевыми адаптерами и их драйверами.)
Итак, механизм обмена байтами между двумя компьютерами определен. Теперь нужно договориться о правилах обмена сообщениями между приложениями А и В. Приложение В должно "уметь" расшифровать получаемую от приложения А информацию. Для этого программисты, разрабатывавшие приложения А и В, строго оговаривают форматы сообщений, которыми будут обмениваться приложения, и их семантику. Например, они могут договориться о том, что любое выполнение удаленной операции печати начинается с передачи сообщения, запрашивающего информацию о готовности приложения В; что в начале сообщения идет число, определяющее длину данных, предназначенных для печати; что признаком срочного завершения печати является определенная кодовая комбинация и т. п. Тем самым, как будет показано дальше, определяется протокол взаимодействия приложений.
Вернемся к последовательности действий, которые необходимо выполнить для распечатки текста на принтере "чужого" компьютера.
Приложение А формирует очередное сообщение (содержащее, например, строку, которую необходимо вывести на принтер) приложению В, помещает его в буфер оперативной памяти и обращается к ОС с запросом на передачу содержимого буфера на компьютер В.
ОС компьютера А обращается к драйверу СОМ-порта, который инициирует работу контроллера.
Действующие с обеих сторон пары драйверов и контроллеров СОМ-порта последовательно, байт за байтом, передают сообщение на компьютер В.
Драйвер компьютера В периодически выполняет проверку на наличие признака завершения приема, устанавливаемого контроллером при правильно выполненной передаче данных, и при его появлении считывает принятый байт из буфера контроллера в оперативную память, тем самым делая его доступным для программ компьютера В. В некоторых случаях драйвер вызывается асинхронно, по прерываниям от контроллера. Аналогично реализуется и передача байта в другую сторону -- от компьютера В к компьютеру А.
Приложение В принимает сообщение, интерпретирует его, и в зависимости от того, что в нем содержится, формирует запрос к своей ОС на выполнение тех или иных действий с принтером. В нашем примере сообщение содержит указание на печать текста, поэтому ОС передает драйверу принтера запрос на печать строки. Далее выполняются все действия 1 -6, описывающие выполнение запроса приложения к ПУ в соответствии с рассмотренной ранее схемой "локальная ОС -- драйвер ПУ -- контроллер ПУ-- устройство управления ПУ" (см. предыдущий раздел). В результате строка будет напечатана.
Мы рассмотрели последовательность работы системы при передаче только одного сообщения от приложения А к приложению В. Однако порядок взаимодействия этих двух приложений может предполагать неоднократный обмен сообщениями разного типа. Например, после успешной печати строки (в предыдущем примере) согласно правилам, приложение В должно послать сообщение-подтверждение. Это ответное сообщение приложение В помещает в буферную область оперативной памяти, а далее с помощью драйвера СОМ-порта передает его по каналу связи в компьютер А, где оно и попадает к приложению А.
Многослойная модель сети
Даже поверхностно рассматривая работу сети, можно заключить, что вычислительная сеть -- это сложный комплекс взаимосвязанных и согласованно функционирующих программных и аппаратных компонентов. Изучение сети в целом предполагает знание принципов работы отдельных ее элементов, таких как:
Компьютеры;
Коммуникационное оборудование;
Операционные системы;
Сетевые приложения.
Весь комплекс программно-аппаратных средств сети может быть описан многослойной моделью. В основе любой сети лежит аппаратный слой стандартизированных компьютерных платформ. В настоящее время в сетях успешно применяются компьютеры различных классов -- от персональных компьютеров до мэйнфреймов и супер-ЭВМ. Набор компьютеров в сети должен соответствовать набору решаемых сетью задач.
Второй слой -- это коммуникационное оборудование. Хотя компьютеры и являются центральными элементами обработки данных в сетях, в последнее время не менее важную роль стали играть коммуникационные устройства. Кабельные системы, повторители, мосты, коммутаторы, маршрутизаторы и модульные концентраторы из вспомогательных компонентов сети превратились в основные наряду с компьютерами и системным программным обеспечением, как по влиянию на характеристики сети, так и по стоимости. Сегодня коммуникационное устройство может представлять собой сложный специализированный мультипроцессор, который нужно конфигурировать, оптимизировать и администрировать. Изучение принципов работы коммуникационного оборудования требует знакомства с большим количеством протоколов, используемых как в локальных, так и в глобальных сетях.

Рис. 15.3 Многослойная модель сети.
Третьим слоем, образующим программную платформу сети, являются операционные системы (ОС). От того, какие концепции управления локальными и распределенными ресурсами положены в основу сетевой ОС, зависит эффективность работы всей сети. При проектировании сети важно учитывать, насколько легко данная операционная система может взаимодействовать с другими ОС сети, какой она обеспечивает уровень безопасности и защищенности данных, до какой степени позволяет наращивать число пользователей, можно ли перенести ее на компьютер другого типа и многие другие соображения.
Самый верхний слой сетевых средств образуют различные сетевые приложения, такие как сетевые базы данных, почтовые системы, средства архивирования данных, системы автоматизации коллективной работы и т. д. Очень важно представлять диапазон возможностей, предоставляемых приложениями для различных областей применения, а также знать, насколько они совместимы с другими сетевыми приложениями и операционными системами.
Вычислительная сеть -- это многослойный комплекс взаимосвязанных и согласованно функционирующих программных и аппаратных компонентов: компьютеров, коммуникационного оборудования, операционных систем, сетевых приложений.
Функциональные роли компьютеров в сети
В зависимости от того, как распределены функции между компьютерами сети, они могут выступать в трех разных ролях:
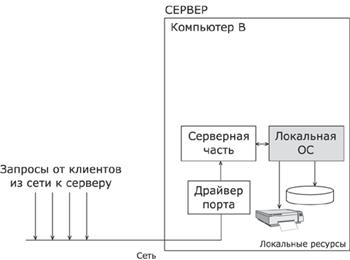
Рис.15.4 Компьютер, занимающийся исключительно обслуживанием запросов других компьютеров, играет роль выделенного сервера сети.
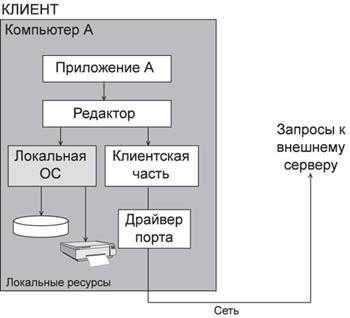
Рис. 15.5 Компьютер, обращающийся с запросами к ресурсам другой машины, играет роль узла-клиента.
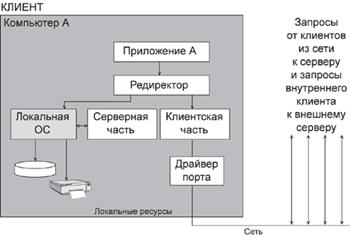
Рис. 15.6 Компьютер, совмещающий функции клиента и сервера, является одноранговым узлом.
Очевидно, что сеть не может состоять только из клиентских или только из серверных узлов. Сеть может быть построена по одной из трех схем:
Сеть на основе одноранговых узлов -- одноранговая сеть;
Сеть на основе клиентов и серверов -- сеть с выделенными серверами;
Сеть, включающая узлы всех типов -- гибридная сеть.
Каждая из этих схем имеет свои достоинства и недостатки, определяющие их области применения.
Одноранговые сети
В одноранговых сетях (рис. 7) все компьютеры равны в возможностях доступа к ресурсам друг друга. Каждый пользователь может по своему желанию объявить какой-либо ресурс своего компьютера разделяемым, после чего другие пользователи могут с ним работать. В одноранговых сетях на всех компьютерах устанавливается такая операционная система, которая предоставляет всем компьютерам в сети потенциально равные возможности. Сетевые операционные системы такого типа называются одноранговыми ОС. Очевидно, что одноранговые ОС должны включать как серверные, так и клиентские компоненты сетевых служб (на рисунке они обозначены буквами, соответственно, С и К). Примерами одноранговых ОС могут служить LANtastic, Personal Ware, Windows for Workgroups, Windows NT Workstation, Windows 95/98.
Рис. 15.7 Одноранговая сеть (здесь словом "Коммун." обозначены коммуникационные средства).
При потенциальном равноправии всех компьютеров в одноранговой сети часто возникает функциональная несимметричность. Обычно некоторые пользователи не желают предоставлять свои ресурсы для совместного доступа. В таком случае серверные возможности их операционных систем не активизируются, и компьютеры играют роль "чистых" клиентов (на рисунке неиспользуемые компоненты ОС изображены затемненными). В то же время администратор может закрепить за некоторыми компьютерами сети только функции, связанные с обслуживанием запросов от остальных компьютеров, превратив их таким образом в "чистые" серверы, за которыми пользователи не работают. В такой конфигурации одноранговые сети становятся похожими на сети с выделенными серверами, но это только внешнее сходство -- между этими двумя типами сетей остается существенное различие. Изначально в одноранговых сетях отсутствует специализация ОС в зависимости от того, какую роль играет компьютер -- клиента или сервера. Изменение роли компьютера в одноранговой сети достигается за счет того, что функции серверной или клиентской частей просто не используются.
Одноранговые сети проще в развертывании и эксплуатации; по этой схеме организуется работа в небольших сетях, в которых количество компьютеров не превышает 10-20. В этом случае нет необходимости в применении централизованных средств администрирования -- нескольким пользователям нетрудно договориться между собой о перечне разделяемых ресурсов и паролях доступа к ним. Однако в больших сетях средства централизованного администрирования, хранения и обработки данных, а особенно защиты данных необходимы. Такие возможности легче обеспечить в сетях с выделенными серверами.
Сети с выделенным сервером
В сетях с выделенными серверами (рис. 8) используются специальные варианты сетевых ОС, которые оптимизированы для работы в роли серверов и называются серверными ОС. Пользовательские компьютеры в таких сетях работают под управлением клиентских ОС.
Рис. 15.8 Сеть с выделенным сервером.
Специализация операционной системы для работы в роли сервера является естественным способом повышения эффективности серверных операций. А необходимость такого повышения часто ощущается весьма остро, особенно в большой сети. При существовании в сети сотен или даже тысяч пользователей интенсивность запросов к разделяемым ресурсам может быть очень значительной, и сервер должен справляться с этим потоком запросов без больших задержек. Очевидным решением этой проблемы является использование в качестве сервера компьютера с мощной аппаратной платформой и операционной системой, оптимизированной для серверных функций.
Чем меньше функций выполняет ОС, тем более эффективно можно их реализовать, поэтому для оптимизации серверных операций разработчики ОС вынуждены ущемлять некоторые другие ее функции, причем иногда даже полностью отказываться от них. Одним из ярких примеров такого подхода является серверная ОС NetWare. Ее разработчики поставили перед собой цель оптимизировать выполнение файлового сервиса и сервиса печати. Для этого они полностью исключили из системы многие элементы, важные для универсальной ОС, в частности, графический интерфейс пользователя, поддержку универсальных приложений, защиту приложений мультипрограммного режима друг от друга, механизм виртуальной памяти. Все это позволило добиться уникальной скорости файлового доступа и вывело NetWare в лидеры серверных ОС на долгое время.
Однако слишком узкая специализация некоторых серверных ОС является одновременно и их слабой стороной. Так, отсутствие в NetWare 4 универсального интерфейса программирования и средств защиты приложений, не позволившее использовать эту ОС в качестве среды для выполнения приложений, приводит к необходимости применения в сети других серверных ОС в тех случаях, когда требуется выполнение функций, отличных от файлового сервиса и сервиса печати. Поэтому разработчики многих серверных операционных систем отказываются от функциональной ограниченности и включают в состав серверных ОС все компоненты, позволяющие задействовать их в качестве универсальных серверов и даже клиентских ОС. Такие серверные ОС снабжаются развитым графическим пользовательским интерфейсом и поддерживают универсальный API. Это сближает их с одноранговыми операционными системами, но существует несколько отличий, которые позволяют отнести их именно к классу серверных ОС:
Поддержка мощных аппаратных платформ, в том числе мультипроцессорных;
Поддержка большого числа одновременно выполняемых процессов и сетевых соединений;
Включение в состав ОС компонентов централизованного администрирования сети (например, справочной службы или службы аутентификации и авторизации пользователей сети);
Более широкий набор сетевых служб.
В больших сетях выделенный сервер часто выполняет только одну определенную функцию и тогда различают:
Файл-сервер, узел сети, выполняющий централизованное хранение данных и обеспечивающий разделяемый доступ к ним, служащий для управления передачей, файлов и позволяющие пересылать информацию большого объема, (не обязательно текстовую, но и графическую);
Серверы печати (или принт-серверы), служащие для включения в состав сети принтера, доступного для использования пользователям со всех рабочих станций сети, в NetWare - служебная программа (или специализированный микроконтроллер) для вывода заданий из очередей на принтеры;
Коммуникационные (связные) серверы, предназначенные для управления и установления связи между компьютерами в сети, обеспечивает разделяемый доступ к коммуникационным средствам - модемам, портам Х.25 и т. д.;
Почтовые серверы в системе электронной почты, служащие для пересылки и приема электронных писем;
Архивные серверы, предназначенные для архивирования данных и резервного копирования информации в больших многосерверных сетях;
Web-серверы под управлением определенных ОС (для Microsoft Internet Information Server - Windows NT/2000, для Apache - Linux или Unix);
Серверы удаленного доступа, которые предоставляют коммутируемое соединение;
Прокси-серверы служат промежуточным звеном между рабочими станциями пользователей и Internet;
Факс-серверы, используемые для отправления пользователями факсимильных сообщений с рабочих станции, для приема и последующей рассылки сообщении в личные боксы пользователей и др.
В качестве сервера может быть использован либо обычный персональный компьютер, или же это может быть специализированное устройство - высокопроизводительный компьютер, возможно, с несколькими параллельно работающими процессорами, с винчестерами большой емкости, с высокоскоростной сетевой картой (100 Мбит/с и более), реализующий одну из указанных функций управления. В этом последнем случае специализированный сервер по своему внешнему виду может отличаться от обычного персонального компьютера и в зависимости от назначения иметь различные габариты - от бытового видеомагнитофона до видеокассеты (при этом в его состав, как правило, не входят ни монитор, ни клавиатура). Сервер в иерархических сетях - это постоянное хранилище разделяемых ресурсов. Сам сервер может быть клиентом только сервера более высокого уровня иерархии. Поэтому иерархические сети иногда называются сетями с выделенным сервером.
С точки зрения пользователей архитектура "клиент-сервер" предоставляет им быстрый и простой доступ с локальной рабочей станции к информации и функциям, содержащимся где-то в сети. Среди других достоинств, важных для пользователя, можно отметить: повышение производительности, возможность свободного выбора необходимого программного обеспечения, простоту в использовании инструментальных средств.
Похожие статьи
-
Базовые понятия информации - Компьютерные и сетевые технологии
Информация компьютер математический сеть Мы начинаем первое знакомство с величайшим достижением нашей цивилизации, стоящем в одном ряду с изобретением...
-
Сетевые технологии в работе секретаря - Компьютерные технологии в деятельности секретаря
Практически повсеместное подключение имеющихся в офисе компьютеров к сети Интернет делает возможным использование сетевых технологий для реализации...
-
Где может размещаться блок в кэш-памяти? - Компьютерные и сетевые технологии
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации: Если каждый блок основной памяти имеет только одно фиксированное...
-
У каждого блока в кэш-памяти имеется адресный тег, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти теги обычно...
-
Типы записей в базе данных DNS-сервера - Компьютерные сети
DNS-сервер, отвечающий за имена хостов в своей зоне, должен хранить информацию о хостах в базе данных и выдавать ее по запросу с удаленных компьютеров....
-
ДОУ представляет собой взаимосвязанную совокупность средств, методов и персонала, используемых для хранения, обработки данных и выдачи документов для...
-
Секретарь - под этим словом часто скрываются разные функции, должности, степень ответственности. Эта профессия уникальна, к ней можно предъявлять чисто...
-
Повторитель (repeater) Усиливает сигнал сетевого кабеля, который затухает на расстоянии более 100 м. Он работает на физическом уровне стека протоколов,...
-
История развития компьютерных технологий в России Компьютеры проникли во все сферы деятельности человека, начиная с начального образования и заканчивая...
-
Сетевая топология - Сеть абонентского доступа
Под сетевой топологией принято понимать способ описания конфигурации сети, схему расположения и соединения сетевых устройств. Существует множество...
-
Для компьютерного оборудования и данных (информации) существуют три основные угрозы: Физическое воровство, которое включает подключение к различным...
-
Многоуровневые сетевые модели, Сетевая модель - Компьютерные сети
Глобальные сети объединяют в себе огромное количество географически распределенных узлов. Множество вариантов программно-технической реализации передачи...
-
Выбор способа объединения подсетей на магистрали, например, с помощью маршрутизации, с помощью шлюзов или же с помощью транслирующих коммутаторов. При...
-
Использование информационных технологий в образовании создают предпосылки для перехода в перспективе к виртуальной форме обучения. Это значит, что...
-
Технология клиент-сервер. - Использование компьютерных сетей
Характер взаимодействия компьютеров в локальной сети принято связывать с их функциональным назначением. Как и в случае прямого соединения, в рамках...
-
Технологии распределенных вычислений (РВ) Современное производство требует высоких скоростей обработки информации, удобных форм ее хранения и передачи....
-
Настройка сетевого адаптера и трансивера - Сетевые адаптеры
Для работы ПК в сети надо правильно установить и настроить сетевой адаптер. Для адаптеров, отвечающих стандарту PnP, настройка производится...
-
Сервисы и протоколы. World Wide Web (WWW) - Интернет технологии
World Wide Web (WWW, Всемирная паутина) - это наиболее популярный вид информационных услуг Internet, основанный на архитектуре клиент-сервер. В конце...
-
SAP HANA - это гибкий многоцелевой и независимый от источника данных программный комплекс на базе технологии "in-memory", который объединяет компоненты...
-
Стандарты современных сетей, Эталонная модель OSI. - Сетевые стандарты и протоколы
Эталонная модель OSI. Перемещение информации между компьютерами различных схем является чрезвычайно сложной задачей. В начале 1980 гг. Международная...
-
Чернобыль - опасный компьютерный вирус - Компьютерные вирусы
Компьютерный вирус Чернобыль - относится к резидентным вирусам, поражающим системы Windows 95, Windows 98. Размер вируса ничтожен, всего 1 Кб. Внедряясь,...
-
Информационная система Lumesse ETWeb является системой, которая автоматизирует весь комплекс процессов управления персоналом. Важно отметить, что данная...
-
Устройства звукозаписи, Подключение устройств записи - Технология мультимедиа. Монтаж фильма
Устройство звукозаписи позволяет Записывать звук от внешнего источника на компьютер. Наиболее часто используемым типом устройства звукозаписи является...
-
Работа с текстовыми документами с помощью Word, Excel и др. В настоящее время практически все офисы оснащены средствами вычислительной техники,...
-
Полное наименование разрабатываемой системы - корпоративная информационная система "Бюджетное планирование и отчетность" группы компаний, занимающейся...
-
МЕТОДЫ ДОСТУПА К ПЕРЕДАЮЩЕЙ СРЕДЕ В ЛВС - Компьютерные сети и телекоммуникации
Несомненные преимущества обработки информации в сетях ЭВМ оборачиваются немалыми сложностями при организации их защиты. Отметим следующие основные...
-
В последнее время можно заметить стремительный рост значимости различных интернет-порталов, мобильных приложений, сервисов и IT-систем, существенно...
-
Геймификация Когда рестораны принимают решения встраивать инновационные услуги в свой бизнес для привлечения аудитории, следует учитывать не только...
-
После того, как был реализован процесс карьерного планирования в информационной системе, можно сделать выводы о том, что внедрение информационной системы...
-
Компьютерный вирус - это небольшая программа, написанная в машинных кодах, которая способна внедряться в другие программы, сама себя копировать и...
-
Сетевые протоколы, используемые в сети Интернет. - Использование компьютерных сетей
Иерархия протоколов TCP/IP 5 Application level 4 Transport level 3 Internet level 2 Network interface 1 Hardware level Протоколы TCP/IP широко...
-
Основные компоненты - Теоретические основы информационных технологий
Рассмотрим структуру системы поддержки принятия решений (рис. 2.4), а также функции составляющих ее блоков, которые определяют основные технологические...
-
Концентраторы вместе с сетевыми адаптерами, а также кабельной системой представляют тот минимум оборудования, с помощью которого можно создать локальную...
-
1 Характеристика технологий xDSL - Разработка корпоративной сети на основе технологий xDSL
HDSL (High-bit-rate DSL) , или технология высокоскоростной цифровой абонентской линии, - это первенец семейства xDSL, разработанный в конце 80-х гг....
-
По результатам данного исследования необходимо выявить недостатки и ограничения существующих технологий интеграции. Для проведения исследования...
-
Введение - Разработка корпоративной сети на основе технологий xDSL
Корпоративный сеть интерфейс Любая организация - это совокупность взаимодействующих структурных элементов (подразделений), каждый из которых может иметь...
-
Перспективной областью применения стандарта Zigbee являются беспроводные системы считывания показаний различных счетчиков. Данный сегмент рынка крайне...
-
Участникам ДО (слушателям и педагогам) необходимо иметь определенный уровень подготовки, чтобы уметь пользоваться методами, средствами и организационными...
-
Создание Internet-центра. Выбор подключения. Полное подключение - Интернет технологии
Такой способ подключения не нуждается в комментариях. Вы получаете полномасштабный Интернет, но и стоимость такого подключения достаточно высока в г....
-
Второй этап истории развития БД. - Технология создания и управления баз данных
Второй этап - эпоха персональных компьютеров Персональные компьютеры стремительно ворвались в нашу жизнь и буквально перевернули наше представление о...
Что происходит во время записи? - Компьютерные и сетевые технологии