Регрессионный анализ эффективности администрирования НДС по странам мира, Построение и анализ регрессионных моделей - Анализ факторов, влияющих на эффективность администрирования налога на добавленную стоимость
Построение и анализ регрессионных моделей
Регрессии (1) и (2) являются обычными сквозными, а (3) и (4) регрессиями с фиксированными эффектами. Регрессии со случайным эффектом автором даже не рассматриваются, в связи с тем, что случайности в определении качестве администрирования налога быть не может, а индивидуальные эффекты, заключающиеся в особенном дизайне налога, методе его сбора или в специфическом законодательстве той или иной страны имеют место быть. Модели (2) и (4) не содержат индекса коррупции, в связи с тем, что он сильно коррелирует с величиной ВВП на душу населения. По причине того, что в выборке участвуют в основном достаточно развитые страны Европы и Россия, ожидается, что влияние макроэкономических показателей будет примерно одинаковое, поэтому нет смысла строить общую модель.
На первом этапе, каждая переменная была протестирована на нормальность распределения для безопасной дальнейшей работы. Было сгенерировано несколько новых переменных для устранения гетероскедастичности: ln_age, ln_imp_cons.
Общая тенденция изменений показателя эффективности администрирования НДС представлена в Приложении 2. Карта сгруппирована по странам и отражает основные тренды. Следует отметить, что России больше чем другим странам свойственна нестабильность показателя эффективности НДС.
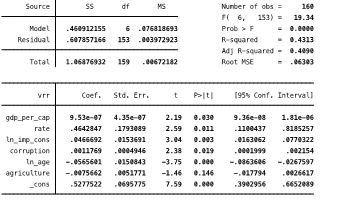
Рис. 3.1. Пул-регрессия
В целом, можно отметить, что практически все показатели оказались статистически значимыми и обычная сквозная регрессия получилась довольно успешной. Значение Фишера также указывает на значимость модели в целом. Незначимым оказался показатель сельского хозяйства, остальные переменные значимы на 5% уровне. Не будем останавливаться на интерпретации знаков при коэффициентах, отметим только то, что константа положительна - а, значит, у стран хорошие стартовые позиции по администрированию НДС. Не стоит забывать, что придавая значение 0 всем остальным регрессорам мы лишаем смысла данную модель.
Команда robust, умышленно была не использована: для проверки данных модели на гетероскедастичность проведем тест Бреуша-Пагана:

Рис. 3.2. Тест Бреуша-Пагана на гетероскедастичность
Значения полученные нами гетероскедастичны, а значит требуют робастную поправку.
Прежде чем построить исправленную модель (1), проверим данные на мультиколлинеарность:
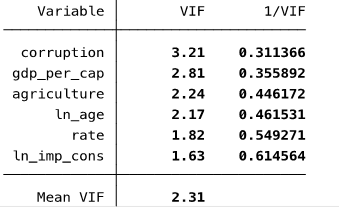
Рис. 3.3. Расчет VIF. Проверка на мультиколлинеарность.
Среднее значение VIF меньше 5, а следовательно полной мультиколлинеарности в регрессии не наблюдается.
Оценим распределение остатков регрессии для этого, чтобы элиминировать возможные последствия - построение неправильных доверительных интервалов, неэффективная оценка МНК - не соблюдение условий Гаусса-Маркова.
График распределения остатков отражает нормальность распределения последних. Следовательно, условия Гаусса-Маркова выполняются и можно считать модель самой оптимальной в классе всех несмещенных и эффективных оценок.
Построим аналогичную регрессию с учетом индивидуальных фиксированных оценок (3) и исправим регрессию (1) с учетом робастности:
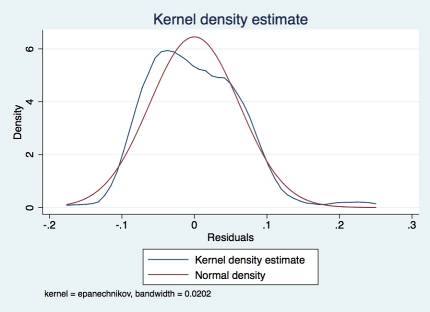
Рис. 3.4. Распределение остатков.

Рис. 3.5. Сравнением пул-регрессии с FE-регрессией.
Регрессия с индивидуальным фиксированным эффектом исключило две переменные из регрессии в силу коллинеарности. На основе сравнения моделей, без дополнительных корректировок модели (3), можно сделать вывод, что обычная сквозная регрессия лучше чем с фиксированным эффектами. Однако, значимость коэффициентов FE гораздо выше, чем у пул-регрессии, хоть эти данные и не отражены в таблице.
Построим соответственно регрессии для моделей (2) и (4). Для этого необходимо исключить переменную коррупция, которая сильнее остальных факторов проявляет корреляцию и приводит к проблемам при построении модели с фиксированными индивидуальными эффектами (3).
В модели (2) все регрессоры получились значимыми на 1% уровне, модель достаточно качественно отражает реальные связи.
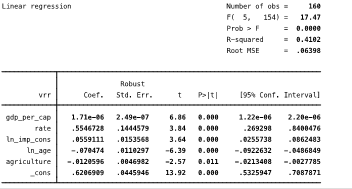
Рис. 3.6. Сквозная регрессия, модель 2
При относительно не высоком показателе R, модель получилась значима в целом.
Модель (4) с индивидуальным фиксированным эффектом оказалась значима в целом, все регрессоры значимы на 5% уровне, кроме ВВП на душу населения. Пропущена переменная rate. Наличие корреляции между ошибкой и регрессорами = -0.73, вполне естественное явление и не представляет никакой угрозы, в отличие от случая корреляции с остатками.
Все четыре модели оказались на удивление качественными и значимыми. Этому свидетельствует хорошее значение статистики Фишера, значение R2, значимость полученных регрессоров на 1% и 5 % уровнях. Более подробно сравнение моделей представлено на рис. 3.8.
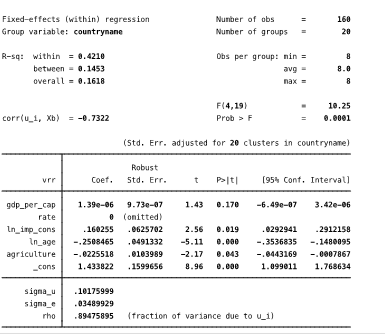
Рис. 3.7. Индивидуальные фиксированные эффекты. Модель 4.
Автором также проводилась попытка оценивания регрессии "between", однако, модель оказалось в целом не значима, так же как и регрессоры.
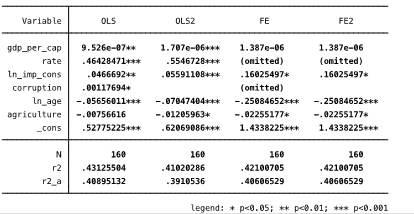
Рис. 3.8. Сравнение моделей 1-2-3-4.
Похожие статьи
-
Выборка включает в себя 22 страны: Австралия, Австрия, Бельгия, Великобритания, Венгрия, Германия, Греция, Дания, Ирландия, Исландия, Испания, Италия,...
-
Исследуемая тема была изучена во многих зарубежных работах и публикациях. Отечественной литературы, напротив, оказалось всего несколько. Общую...
-
Для перехода к НДС существовали различные причины, среди которых: 1. Тесная связь с эффективностью производства, а также возможность сохранения...
-
История НДС и его общая характеристика На сегодняшний день, использование налога на добавленную стоимость (НДС) государствами различных стран практически...
-
Для выявления взаимосвязей необходимо построить корреляционную матрицу переменных. Был применен метод расчета корреляции коэффициентом Пирсона....
-
В России НДС был введен 1 января 1992 года и с тех пор регулируется главой 21 Налогового кодекса РФ. Аппарат администрирования, а также основные правила...
-
Налог на добавленную стоимость - Анализ налоговых систем зарубежных стран
НДС взимается с поставок товаров и услуг, осуществляемых на территории Великобритании налогооблагаемыми лицами в связи с их деятельностью, включая...
-
Основным источником анализа финансового состояния предприятия является баланс. Он характеризует состояние собственности предприятия, использование...
-
Эмпирические оценки модели детерминант вероятности осуществления дивидендных выплат На первом этапе проводилось исследование детерминант вероятности...
-
Практическая часть данной работы состоит в разработке и дальнейшем тестировании эконометрических моделей, которые отразят влияние на российский...
-
Роль НДС и методика исчисления. - Налог на добавленную стоимость, характеристика
Изобретение налога принадлежит М. Лоре (Франция), который в 1954г. описал схему его действия, способного заменить налог с оборота, функционировавший в...
-
Управление затратами является одной из основных задач высшего менеджмента любой компании: необходимо не только корректно рассчитать себестоимость...
-
Операционный анализ финансового состояния заемщика Для характеристики активов, являющихся важнейшим элементом финансовой отчетности, изучается их...
-
АНАЛИЗ Указа Президента Республики Беларусь от 26 марта 2007г. №138 "О некоторых вопросах обложения налогам на добавленную стоимость" 26 марта 2007 г....
-
Анализ собранной базы данных - Анализ влияния сделок M&;amp;A на операционную эффективность компаний
Сбор данных производился на основании баз данных Bureau van Dijk. В частности, сделки M&;A были взяты из базы Zephyr, а детальная информация по каждой...
-
В настоящее время существует довольно много методик и методов для проведения финансово-экономического анализа. Как правило, все методики повторяют или...
-
Методология исследования - Анализ влияния сделок M&;amp;A на операционную эффективность компаний
На основании выводов предыдущей части, мы пришли к заключению, что использование метода анализа финансовой отчетности позволит получить более...
-
Описание переменных - Анализ влияния сделок M&;amp;A на операционную эффективность компаний
Прежде всего, определимся со способом расчета зависимой переменной. Выбор был осуществлен в пользу показателя рентабельности активов (ROA). Поскольку мы...
-
Налогообложение доходов физических лиц Налоги на доходы физических лиц чрезвычайно многообразны. Подоходное налогообложение получило наибольшее...
-
Анализ и прогноз расходов. - Модель Гордона
На данном этапе оценщик должен: Учесть ретроспективные зависимости и тенденции; Изучить структуру расходов, в особенности соотношение постоянных и...
-
Практика применения модели и рекомендации по ее внедрению - Анализ финансового состояния компании
Суть применения системы стандарт-костинга к учету затрат заключается в расчетах, основанных не на фактически произведенных услугах и ценах на них, а в...
-
Результирующим показателем модели может быть определен один из критериев эффективности: -- чистая приведенная стоимость проекта УРУ, -- внутренняя норма...
-
В соответствии с Законом о местном правительственном финансировании (Local Government Finance Act, 1987) система финансирования местных советов...
-
Совершенствование методики расчета налогового потенциала региона как фактор повышения эффективности механизма местного налогообложения В условиях...
-
Для определения причин неудовлетворительных результатов деятельности анализируемого предприятия проведем анализ прибыли. Значительное влияние на величину...
-
Заключение - Аспекты налога на добавленную стоимость как экономической категории
Налог на добавленную стоимость самый сложный для исчисления из всех налогов, входящих в налоговую систему РФ. Его традиционно относят к категории...
-
Налоги на переход права собственности на имущество - Анализ налоговых систем зарубежных стран
К налогам на переход права собственности относятся налоги на наследство, налоги на дарение, налоги на операции с ценными бумагами, а также сборы,...
-
Личный подоходный налог - Анализ налоговых систем зарубежных стран
Статус резидента зависит от количества дней, проведенных лицом в Великобритании. Применяются следующие основные правила: - при физическом отсутствии...
-
Налоги на потребление Основные виды налогов на потребление - это акцизы, налог с оборота, налог с продаж, налог на добавленную стоимость, пошлины и...
-
Муниципальный налог - Анализ налоговых систем зарубежных стран
Муниципальный налог был введен в 1993 г. Налог платится ежемесячно, исходя из рыночной стоимости недвижимости, находящийся в собственности или в аренде...
-
Современная налоговая система России с 1992 г. формируется с учетом норм и принципов налогообложения ведущих зарубежных стран, но несовершенство...
-
Оценку состояния с любой позиции, будь то оценка ликвидности, кредитоспособности или платежеспособности компаний следует начинать с построения...
-
Использование системного анализа в процессе создания системы бюджетирования
Аннотация Внедрение системы бюджетирования на предприятии - сложный и длительный процесс, а результаты его часто оказываются далеки от ожидаемых....
-
Дивидендный выплата капитал рынок Проанализировав существующие работы в области дивидендной политики компаний с развивающихся рынков капитала и приняв во...
-
Горизонтальный и вертикальный анализ активов организации Всю совокупность приемов анализа целесообразно рассматривать в разрезе трех основных направлений...
-
Dasgupta and Sengupta (2007) анализировали японские компании и нашли, что чувствительность инвестиций к изменениям денежных потоков не является...
-
Особенности планирования налога на доходы физических лиц
Особенности планирования налога на доходы физических лиц Особое положение в ряду налогов, уплачиваемых физическими лицами, занимает налог на доходы...
-
Методы диагностики вероятности банкротства - Анализ финансового состояния предприятия
Подход к оценке вероятности банкротства, положивший начало кредит-скоринговым моделям, предложил Эдвард Альтман в 1968 году, разработав индекс...
-
Из-за сложившейся трудной ситуации ЕС с миграцией беженцев и демографическим кризисом некоторых отдельных стран-участниц, не стоит забывать о том, что ЕС...
-
Анализ построенной модели по методу стандарт-костинг - Анализ финансового состояния компании
Методика стандарт-костинг предполагает сопоставление статей себестоимости и бюджета, при этом для точности анализа отклонений может быть использован...
Регрессионный анализ эффективности администрирования НДС по странам мира, Построение и анализ регрессионных моделей - Анализ факторов, влияющих на эффективность администрирования налога на добавленную стоимость