Построение модели - Анализ поведения домашних хозяйств в современной России
Ориентируясь на результаты предварительного анализа и экономических соображений, была построена базовая регрессионная модель по данным, собранным в феврале-мае 2014. Зависимой переменной обозначается та доля дохода, которую домохозяйства готовы потратить на ценные бумаги, а регрессорами выступают различные факторы, влияющие на выбор величины этой доли. Были использованы все переменные, представленные в начале исследования.
Таблица 6
Регрессионная модель 1 (включающая все факторы)
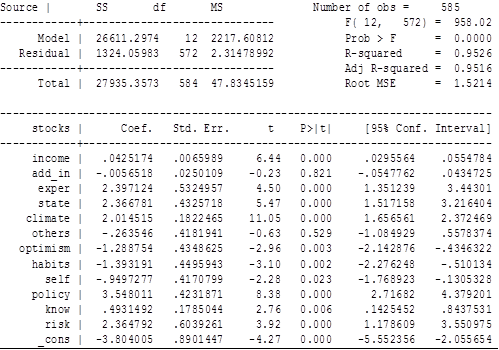
На основе этих факторов была построена следующая регрессия:
Stocks=3.804005+0.0425174*income-0.0056518*add_in+2.397124*exper
+2.366781*state+2.014515*climate+2.014515*climate-1.288754*optimism-1.393191*habits+3.548011*policy +0.4931492*know +2.364792*risk (1)
Переменные add_in, others, представленные в регрессии (1), в дальнейшем не будут использоваться, так как они не такие значимые, как остальные.
В модели (1) факторами, имеющими большее влияние, оказались:
- -опыт инвестирования, -оценка инвестиционного климата в стране, -оценка политической ситуации в стране, -рискованность, -доверие государству.
Другие факторы не так сильно влияют на формирование доли от дохода, которая пойдет на ценные бумаги. Исключив незначимые переменные, была построена новая модель.
Таблица 7
Регрессионная модель 2 (с исключением нескольких переменных)
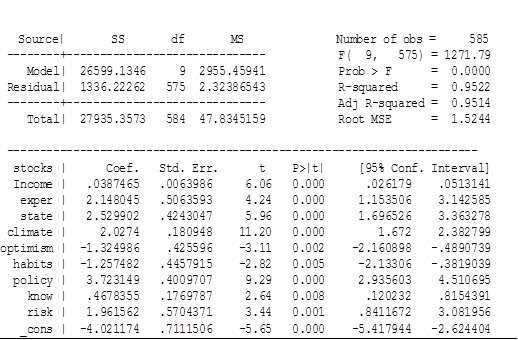
Новая модель без значимых переменных выглядит следующим образом:
Stocks= -4.021174 +0.0387465*income +2.148045*exper
+2.529902*state +2.0274*climate-1.324986*optimism-1.257482*habits +3.723149*policy +0.4678355*know+1.961562*risk (2)
Построив базовую модель, проверим ее на наличии выбросов с помощью разнообразных тестов. Если есть большие выбросы, то коэффициенты регрессий, построенных с учетом выбросов и без них, будут сильно отличаться друга от друга. В итоге, из-за наличия выбросов, мы исказим основные закономерности. Поэтому явные выбросы стоит удалить.
Таблица 8
Выявление выбросов на основе Studentized residuals:
|
. list id rstud stocks income exp state climate optimism habits policy know |
|
Risk if abs(rstud)>2.5 |
Пока не будем удалять выбросы, а рассмотрим все тесты.
Таблица 9
Выявление выбросов на основе расстояния Кука
|
Predict cooksd, cooksd |
|
. count if cooksd>1 |
|
0 |
Оказалось, что нет критических выбросов, для которых расстояние Кука превышает 1. Но если использовать эмпирическое правило и считать выбросами наблюдения, для которых Cook's distance>4/n, удалять нужно 38 наблюдений:
Таблица 10
Выявление выбросов на основе расстояния Кука (эмпирическое правило)
|
. count if (cooksd>4/585) |
|
38 |
Согласно же показателю DFITS необходимо удалить 16 наблюдений, что не так существенно для 585 наблюдений.
Таблица 11
Выявление выбросов на основе показателя DFITS
|
. predict dfits, dfits |
|
. count if dfits>2*sqrt(8/585) |
|
16 |
Для выявления наблюдений, которые могут искажать оценки отдельных коэффициентов регрессии, следует рассчитать показатели dfbeta для коэффициентов перед каждой из объясняющих переменных.
Таблица 12
Выявление выбросов, искажающих отдельные оценки коэффициентов
. list id _dfbeta_2 if _dfbeta_2>2/sqrt(585)
+----------------+
| id _dfbe~_2 |
|----------------|
24. | 24 .2567899 |
- 123. | 123 .1113937 | 222. | 222 .2567899 | 320. | 320 .1113937 | 418. | 418 .2567899 |
|----------------|
513. | 513 .1113937 |
+----------------+
. . list id _dfbeta_5 if _dfbeta_5>2/sqrt(585)
+----------------+
| id _dfbe~_5 |
|----------------|
62. | 62 .1151937 |
124.| 124 .0933014 |
259.| 259 .1151937 |
321.| 321 .0933014 |
454.| 454 .1151937 |
|----------------|
514.| 514 .0933014 |
+----------------+
Рассчитав данные показатели для каждого регрессора, выявили, что выбросов не так много, и пока можно их не удалять.
Окончательный список выбросов сформируем таким образом, чтобы он включал только наблюдения, признанные выбросами по всем трем критериям.
Таблица 13
Выбросы по 3-м критериям
. list id if (dfits>2*sqrt(8/585)) &; (cooksd>4/585) &; (abs(rstud)>2.5)
+-----+
| id |
|-----|
1. | 1 |
4. | 4 |
- 183. | 183 | 199. | 199 | 202. | 202 |
|-----|
- 379. | 379 | 396. | 396 | 399. | 399 | 572. | 572 | 581. | 581 |
Проверим, сильно ли изменятся оценки коэффициентов без этих наблюдений. (1) модель - базовая, а (2) - это модель без выбросов.
Таблица 14
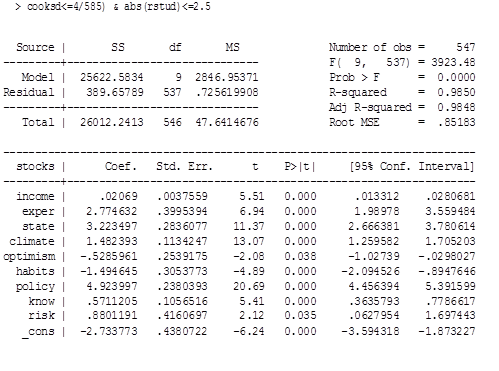
На основании полученных данных была выведена следующая регрессия:
Stocks=-2.733773+0.02069*income+2.774632*exper +3.223497*state+1.482393*climate-0.5285961*optimism
-1.494645*habits +4.923997*policy+0.5711205*know
+0.8801191*risk (3)
Проверим, сильно ли изменились значения коэффициентов без некоторых наблюдений. В таблице (15) коэффициенты модели без выбросов обозначаются, как coef(2), а коэффициенты базовой модели - coef(1).
Таблица 15
Сравнение коэффициентов базовой модели и модели без выбросов
|
Coef(2) |
Coef(1) | |
|
Income |
0.02069 |
0.0387465 |
|
Exper |
2.774632 |
2.148045 |
|
State |
3.223497 |
2.529901 |
|
Climate |
1.482393 |
2.0274 |
|
Optimism |
-0,53 |
-1,32 |
|
Habits |
-1,49 |
-1,26 |
|
Policy |
4.923997 |
3.723149 |
|
Know |
0.5711205 |
0.4678355 |
|
Risk |
0.8801191 |
1.961562 |
|
_cons |
-2,73 |
-4,02 |
Знаки регрессоров остались прежними, но величины коэффициентов, как видно из таблицы, изменились.
Уровень дохода теперь оказывает меньшее влияние, а вот такие факторы, как доверие государству, оценка политической ситуации в стране, оценка своих знаний теперь стали решающими.
Для наилучшей спецификации модели удалим эти подозрительные наблюдения, которые были признанными выбросами по трем критериям: dfits, cooksd и rstud. Тогда базовая регрессионная модель будет выглядеть следующим образом:
Stocks=-2.733773+0.02069*income+2.774632*exper+3.223497*state
+1.482393*climate-0.5285961*optimism-1.494645*habits+4.923997*policy
+0.5711205*know+0.8801191*risk (4)
Теперь коэффициент детерминации равен 0,985 (0,9522) и все переменные значимы на 5% уровне значимости. Необходимо провести диагностику этой модели.
Таблица 16

Все тесты также показали, что распределение остатков не является нормальным. Таким образом, можно сделать вывод, что спецификация выбрана неверно и/или имеет место гетероскедастичность. Теперь перейдем к формальным тестам на функциональную форму и гетероскедастичность.
Таблица 17
Тест Бреуша-Пагана
|
. hettest |
|
Breusch-Pagan / Cook-Weisberg test for heteroskedasticity |
|
Ho: Constant variance |
|
Variables: fitted values of stocks |
|
Chi2(1) = 399.34 |
|
Prob > chi2 = 0.0000 |
|
. . ottest, rhs |
|
Breusch-Pagan / Cook-Weisberg test for heteroskedasticity |
|
Ho: Constant variance |
|
Variables: income exper state climate optimism habits policy know risk |
|
Chi2(9) = 441.36 |
|
Prob > chi2 = 0.0000 |
Таблица 18
Тест Уайта
|
. imtest, white |
|
White's test for Ho: homoskedasticity |
|
Against Ha: unrestricted heteroskedasticity |
|
Chi2(30) = 323.78 |
|
Prob > chi2 = 0.0000 |
|
Cameron &; Trivedi's decomposition of IM-test |
|
Source | chi2 df p |
|
Heteroskedasticity | 323.78 30 0.0000 |
|
Skewness | 51.23 9 0.0000 |
|
Kurtosis | 43.90 1 0.0000 |
|
Total | 418.91 40 0.0000 |
Оба теста: и тест Бреуша-Пагана, и тест Уайта указывают на наличие гетероскедастичности (p-value<0,05). Существует несколько методов борьбы с гетероскедастичностью: использование робастных ошибок, изменение спецификации, взвешенный МНК.
Если рассматривать функциональную форму, то проведем linktest и Ramsey RESET-test.
Таблица 19
Linktest
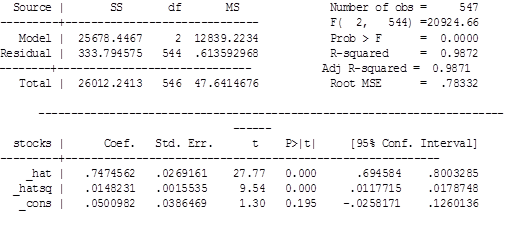
Таблица 20
Ramsey Test
|
Ho: model has no omitted variables |
|
F(3, 534) = 136.68 |
|
Prob > F = 0.0000 |
Гипотеза о том, что квадрат, куб и четвертая степень предсказанных значений незначимы, не отвергается. Cледовательно, функциональная форма выбрана правильно.
При построении таблицы парных корреляция из регрессии были удалены переменные оптимизм и привычки, так как оптимизм был коррелирован с опытом, а привычки с несколькими переменными.
Таблица 21
Матрица корреляции
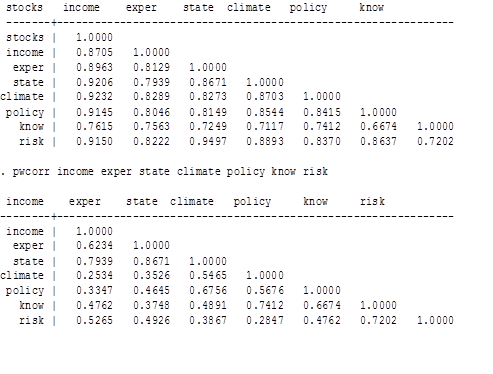
Мультиколлинеарность не выявлена, так как все VIF<5. Это означает, что наши объясняющие переменные не дублируют друг друга по смыслу, а измеряют разные, более или менее независимые аспекты.
Проведя оценку базовой модели, можно сказать, что спецификация модели является удачной, и нет проблемы мультиколлинеарности, но существует проблема гетероскедастичности и распределение остатков не нормальное. В следующем разделе мы попытаемся устранить данные проблемы.
Таблица 22
Логлинейная модель
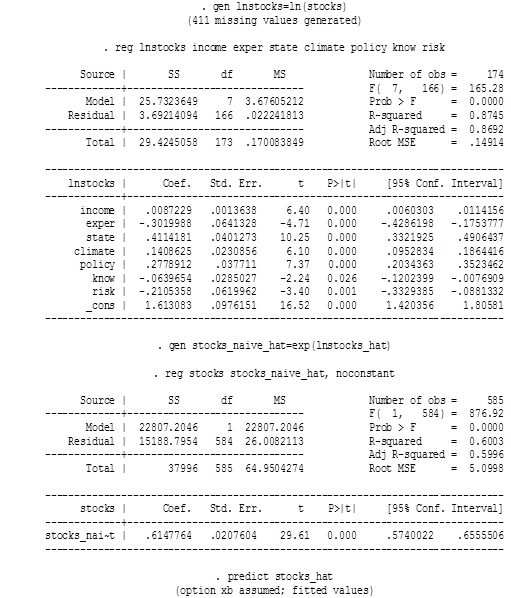
Можно попробовать изменить функциональную форму модели. Базовая модель была линейная, а третья модель будет логлинейной (log-linear). Можно также рассмотреть также модели с добавлением квадрата регрессора или куба, но это сложнее интерпретировать.
Таблица 23
Сравнение коэффициентов 3-х моделей
|
Coef(2) |
Coef(1) |
Ln_stocks | |
|
Income |
0.02069 |
0.038746 |
0.0338615 |
|
Exper |
2.774632 |
2.14804 |
1.816237 |
|
State |
3.223497 |
2.529901 |
3.198085 |
|
Climate |
1.482393 |
2.0274 |
1.881893 |
|
Policy |
4.923997 |
3.723149 |
4.278034 |
|
Know |
0.5711205 |
0.467835 |
0.4039867 |
|
Risk |
0.8801191 |
1.961562 |
1.351987 |
|
_cons |
-2,73 |
-4,02 |
-4,7285 |
У первых двух моделей одинаковая зависимая переменная, а третья зависимая переменная отличается от них. Первые 2 модели можно сравнить между собой на основе R2-adjusted и информационных критериев, а третью модель с ними нельзя сравнивать, так как у них разные TSS.
Если сравнивать 1 и 2 модель по информационным критериям и по R2-adjusted, то вторая модель, однозначно, лучше, чем первая. AIC и BIC меньше, а R2-adjusted больше, следовательно, отдаем предпочтение второй модели.
Так как в третьей модели у нас ln_stock, нам надо предсказать stock, чтобы сравнить с предыдущими моделями. Для этого:
1. Создаем предсказанное значение логарифма цены планшета под названием ln_stock
. predict ln_stock_hat
2. Делаем наивное предсказание Y путем возведения числа e в степень, равную предсказанному логарифму цены
. gen stock_naive_hat=exp(ln_stock_hat)
3. Строим регрессию (без константы) для получения правильного предсказания
. reg stock stock_naive_hat, noconstant
*4. Предсказание по этой регрессии и есть правильное предсказание stock
. predict stock_hat
После получения предсказания можно оценить псевдо R2 модели.
Таблица 24
Оценка псевдо R2модели
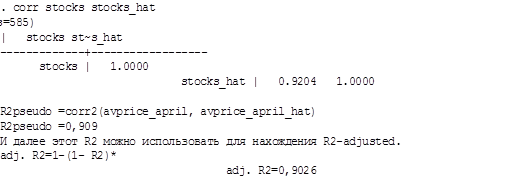
Теперь проведем несколько тестов, чтобы выбрать основную модель между 2-ой и 3-ей моделями.
Таблица 25
Формальные тесты на нормальность распределения
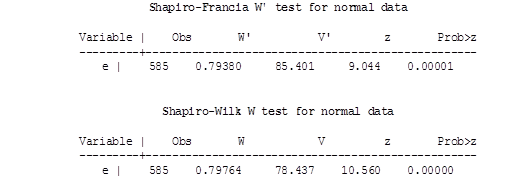
Все тесты также показывают, что распределение остатков не является нормальным. Теперь перейдем к формальным тестам на функциональную форму и гетероскедастичность.
Таблица 25
Формальные тесты на функциональную форму
. hettest, rhs
Breusch-Pagan / Cook-Weisberg test for heteroskedasticity
Ho: Constant variance
Variables: stocks_naive_hat income exper state climate policy risk know
chi2(8) = 263.35
Prob > chi2 = 0.0000
. imtest, white
White's test for Ho: homoskedasticity
against Ha: unrestricted heteroskedasticity
chi2(33) = 102.57
Prob > chi2 = 0.0000
Cameron &; Trivedi's decomposition of IM-test
---------------------------------------------------
Source | chi2 df p
---------------------+-----------------------------
Heteroskedasticity | 102.57 33 0.0000
Skewness | 25.23 8 0.0014
Kurtosis | 8.41 1 0.0037
---------------------+-----------------------------
Total | 136.20 42 0.0000
. linktest
Source | SS df MS Number of obs = 585
-------------+----------------------------- F( 2, 582) = 5797.28
Model | 26600.137 2 13300.0685 Prob > F = 0.0000
Residual | 1335.22029 582 2.29419294 R-squared = 0.9522
-------------+----------------------------- Adj R-squared = 0.9520
Total | 27935.3573 584 47.8345159 Root MSE = 1.5147
-----------------------------------------------------------------------------
stocks | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+---------------------------------------------------------------
_hat | .8397595 .0430926 19.49 0.000 .7551236 .9243954
_hatsq | .0096415 .0025318 3.81 0.000 .0046689 .0146141
_cons | .0608553 .0752475 0.81 0.419 -.0869344 .208645
-----------------------------------------------------------------------------
. . ovtest
Ramsey RESET test using powers of the fitted values of stocks
Ho: model has no omitted variables
F(3, 573) = 40.69
Prob > F = 0.0000
Формально, проблемы со спецификацией есть, так как Ramsey RESET-test выявил ошибку спецификации, причем этот тест более строгий, чем linktest. Также следует проверить нашу модель на мультиколлинеарность.
Мультиколлинеарность не выявлена, так как все VIF<5. Это означает, что наши объясняющие переменные не дублируют друг друга по смыслу, а измеряют разные, более или менее независимые аспекты.
Следующим шагом будет диагностика третьей модели. Из графиков, полученных с помощью "Stata"можно заметить, что распределение остатков очень близко к нормальному. На графике квантиль - квантиль отчетливо видно, что точки лежат близко к прямой, следовательно, распределение остатков слабо отличается от нормального. Удостоверимся в этом с помощью тестов:
Таблица 26
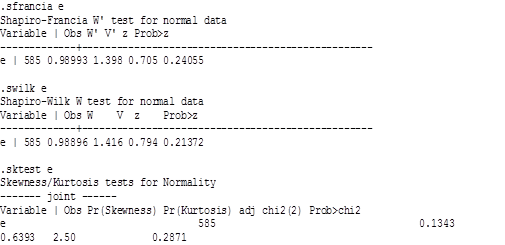
Все тесты указывают на то, что распределение остатков является нормальным. Теперь перейдем к формальным тестам на гетероскедастичность.
Таблица 27
Формальные тесты на гетероскедастичность
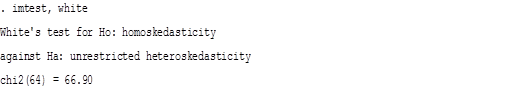
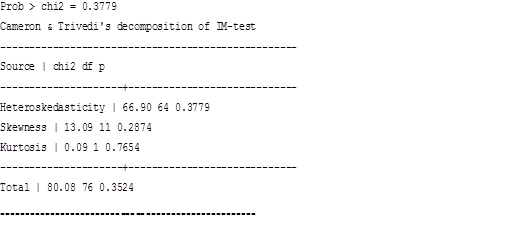
Оба теста: и тест Бреуша-Пагана, и тест Уайта указывают на отсутствие гетероскедастичности. Если рассматривать функциональную форму, то проведем linktest и Ramsey RESET-test.
Исходя из подробного анализа моделей, можно сделать сравнительную таблицу по основным критериям.
Таблица 28
Сравнение 3-х возможных моделей
|
Базовая модель(1) |
Модель без выбросов(2) |
Логлинейная модель(3) | |
|
Нормальность остатков |
- |
- |
+ |
|
Гомоскедастичность |
- |
+ |
+ |
|
Отсутствие мультиколлинеарности |
+ |
+ |
+ |
|
Функциональная форма |
+ |
- |
- |
|
R2-adj |
0.9526 |
0.9850 |
0.9522 |
Как мы решили ранее, выбирать будем между моделями 2 и 3. Вероятно, за основную возьмем логлинейную модель (3), так как по результатам эконометрических тестов она оказалась лучше модели (2). А что касается функциональной формы, то и (2) и (3) модели не очень удачны.
Так как основная модель является не линейной, то изменяется интерпретация оценок коэффициентов. Теперь оценки коэффициентов показывают, насколько процентов изменится доля дохода на ценные бумаги при изменении соответствующей переменной на единицу.
Если какой-либо регрессор в (не фиктивный) увеличивается на 1, то зависимая переменная увеличивается на (ев-1)*100%. При малых в (-0,2<в<0,2) зависимая переменная увеличивается примерно на в*100%. Поскольку |в|?0,2, важно использовать именно точную формулу. В таблице 4 представлена подробная интерпретация каждого коэффициента итоговой модели.
Таблица 29
Интерпретация коэффициентов итоговой модели
|
Переменная |
Значение коэффициента |
|
Income |
0.0338615 |
|
Exper |
0.1816237 |
|
State |
0.3198085 |
|
Climate |
0.1881893 |
|
Policy |
0.4278034 |
|
Know |
0.04039867 |
|
Risk |
0.351987 |
Полученная модель (3) свидетельствует о том, что:
- -при увеличении дохода на 1 тыс. рублей, доля вложения денежных средств в акции возрастает на 3,4%, -если у домохозяйства раньше имелся опыт инвестирования, то доля вложенных средств в акции увеличивается на 18,2%, -если домохозяйство доверяет государству (31,9%), -если инвестиционный климат позволяет думать о благоприятной тенденции (18,8%), -если политическая ситуация устраивает домохозяйство (42,7%), -с увеличением оценки своих знаний о финансовых активах и способах вложениях, доля увеличивается на 4%, -если домохозяйство оценивает себя, как рискованное, то доля вложенных в акции средств будет больше на 35%.
Похожие статьи
-
Статистический анализ и обработка данных - Анализ поведения домашних хозяйств в современной России
Прежде чем приступить к построению модели, необходимо знать, какого рода домохозяйства принимали участие в опросе. Коэффициент вариации доходов...
-
В данной главе перейдем к анализу модели в-конвергенции по панельным данным. Для начала оценим модель безусловной конвергенции, в основе которой лежит...
-
Несмотря на то, что сегодня нет единого мнения относительно наличия в-конвергенции среди регионов России в 1992-2000 годах, большинство авторов полагают,...
-
Анализ статических моделей панельных данных имеет ряд недостатков. Во-первых, при условии корреляции между лагом зависимой эндогенной зависимой...
-
Формирование фондового рынка России Российский фондовый рынок имеет свои особенности, поэтому прежде чем рассуждать о поведении домохозяйств, необходимо...
-
ВВЕДЕНИЕ - Анализ поведения домашних хозяйств в современной России
Долгосрочный экономический рост является одной из главных макроэкономических целей для любой страны. Обеспечением его являются инвестиции в различные...
-
Итак, модели, которые будут дальше анализироваться, и получены с помощью первого метода - проведения теста для выделения наиболее дескриптивных...
-
Отбор и классификация объясняющих переменных Для всесторонней оценки строительной компании в ходе анализа будут использоваться финансовые,...
-
2.1 Выбор факторов, влияющих на движение индекса Проблема выявления факторов, влияющих на фондовые индексы, неоднократно поднималась в исследованиях...
-
Спецификация модели для США и интерпретация результатов В этой главе будет приведено два исследования, задачами которых будет выяснение ключевых...
-
В 2005 году был проведен опрос среди жителей Ростовской области на тему использования своих денежных средств.[3] Выяснилось, что большинство участников...
-
Анализ результатов моделирования в-конвергенции Во второй главе были описаны результаты построения моделей в-конвергенции для 76 регионов России. Анализ...
-
Уровень риска домохозяйств - Анализ поведения домашних хозяйств в современной России
По уровню риска домохозяйства можно разделить на три группы.[2] Первую группу составляют те, кто считают, что их благосостояние никак не меняется при...
-
ЗАКЛЮЧЕНИЕ - Анализ поведения домашних хозяйств в современной России
Проведенное исследование позволяет узнать, как различия в характеристиках домашних хозяйств России влияют на портфельный выбор, а именно на то, какую...
-
Поведение домохозяйств имеет большое значение для экономического роста. Своими действиями домашние хозяйства способны создать базу для финансирования...
-
В целях оценки значимости каждой из уже используемых переменных экономисты обычно используют метод "Shapley R-squared decomposition". Данный метод...
-
Регрессионные модели В теории пространственной экономики выделяют пространственные связи двух типов: пространственная автокорреляция и пространственная...
-
При добавлении в панельную модель безусловной в-конвергенции факторов, влияющих на экономический рост, модель преобразуется в "условную". Большинство...
-
Для анализа был выбран временной диапазон с 2004 года по 2014 год. В целях построения прогнозной модели собранные годовые данные были разделены на две...
-
Способы измерения теневой экономики Прямые методы оценки теневой экономики Методы оценивания теневой экономики делятся па прямые и косвенные. Прямые...
-
Первостепенные факторы, влияющие на поведение домохозяйств Фондовый рынок домохозяйство риск В данной главе будут рассмотрены различные факторы, которые...
-
Корреляционный анализ факторов экономического роста В третьей главе приведены результаты оценки условной модели в-конвергенции, в которую входят ряд...
-
Теперь, когда в рамках данного исследования была получена модель с наилучшими характеристиками для непубличных строительных компаний, полученные...
-
Итак, будем тестировать модель с наилучшими характеристиками. Прогноз вне выборки проводился на основе тестовой выборки с 805 наблюдениями. В ней...
-
После того, как была составлена и проинтерпретирована регрессионная модель для США, можно перейти к аналогичному составлению модели для российского...
-
В своей работе я проанализировала состав экономических районов (по субъектам Федерации) (табл.4.) Главные принципы выделения экономических зон - уровень...
-
Состав и структура населения в Российской Федерации Население - это совокупность лиц, проживающих на определенной территории. В данном случаи в...
-
Построение аналитической группировки по уровню производительности труда работников в отрасли животноводства по хозяйствам Южной лесостепной зоны На этапе...
-
Анализ безработицы в России - Рынок труда и его особенности в современной России
В России, как и в других странах, современный рынок труда определяет уровень социального положения населения. Главной составляющей, которой является...
-
Анализ состояния занятости населения РФ - Рынок труда и его особенности в современной России
Занятость является одной из категорий экономически активного населения. Занятость населения -- деятельность граждан, связанная с удовлетворением их...
-
Мировой финансовый кризис, процессы глобализации выдвигают определенные требования к развитию национальных хозяйственных систем. Конкурентоспособность,...
-
Как отмечалось в ходе исследования, logit-модель может характеризоваться сильной зависимостью от обучающей выборки. Поэтому чтобы быть уверенным в...
-
На уровне домашних хозяйств потребление изучается на основе выборочного обследования их бюджетов. Программой обследования предусмотрен сбор информации,...
-
В виде статистических таблиц оформляются результаты сводки и группировки материалов наблюдения. Статистическая таблица - это особый способ краткой и...
-
2.1 Код для построения модели Кривая производственных возможностей помогает найти оптимальный вариант, при котором альтернативные издержки минимальны, а...
-
Описание базы данных Главным источником формирования базы статистических данных, используемых в данной работе, выступил сайт Госкомстата. Для анализа...
-
Сравнительный анализ нейросетевых и регрессионных моделей прогноза без учета пространственного лага Приведем результаты оценки прогноза за период...
-
Линейные авторегрессионные модели Стоит отметить, что построение линейных моделей так же будет осуществлено по данным спецификациям. Общий вид линейной...
-
Сделав критический обзор методологии рейтинга "Doing Business" и введя термин "объективный рейтинг", мы предлагаем рассмотреть используемые для проверки...
-
Дальнейшим этапом в анализе складского хозяйства ОДО "Тут и Там Логистикс" является расчет показателей эффективности работы складов организации. Для...
Построение модели - Анализ поведения домашних хозяйств в современной России